Downloaded 11 times



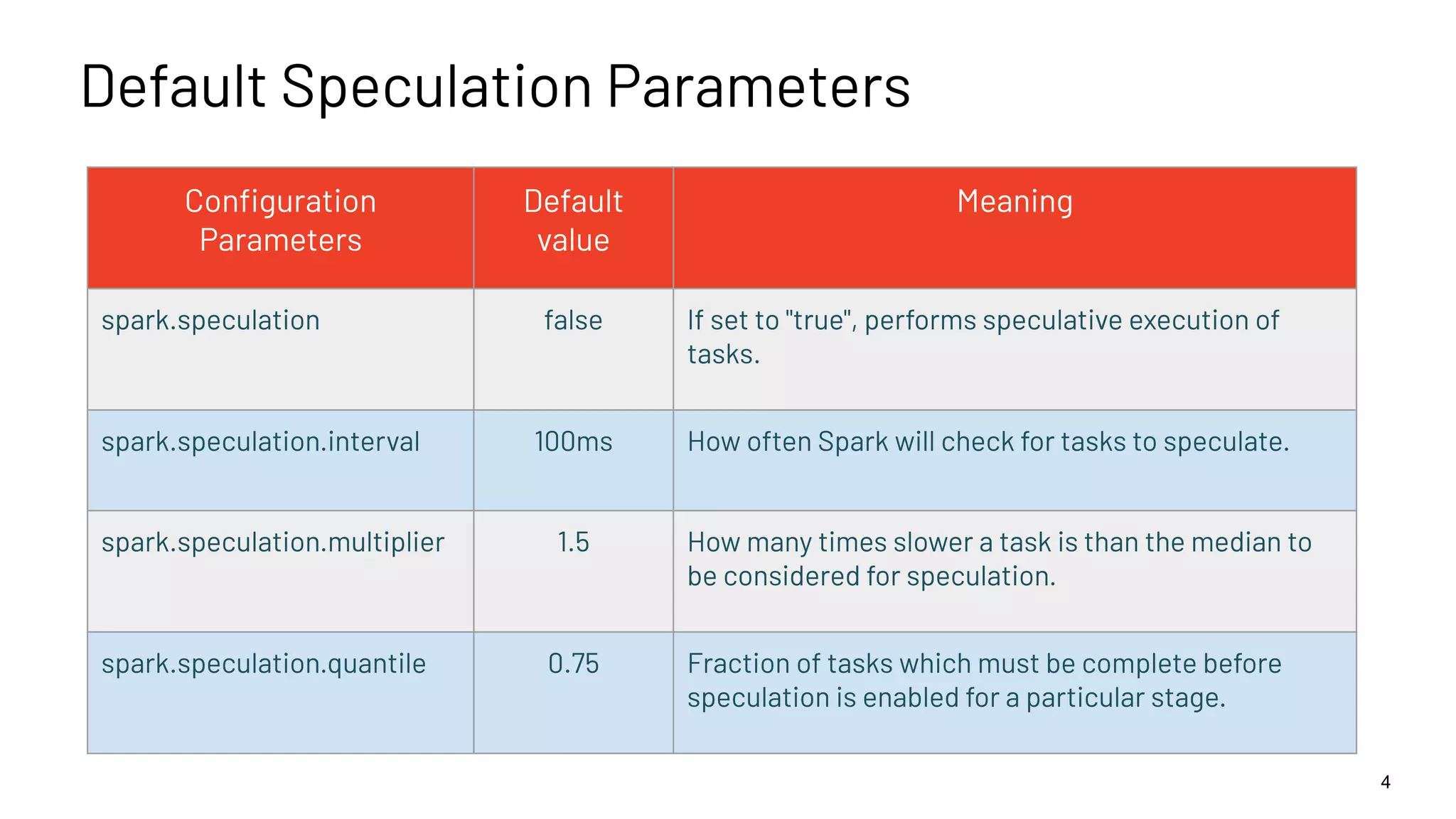




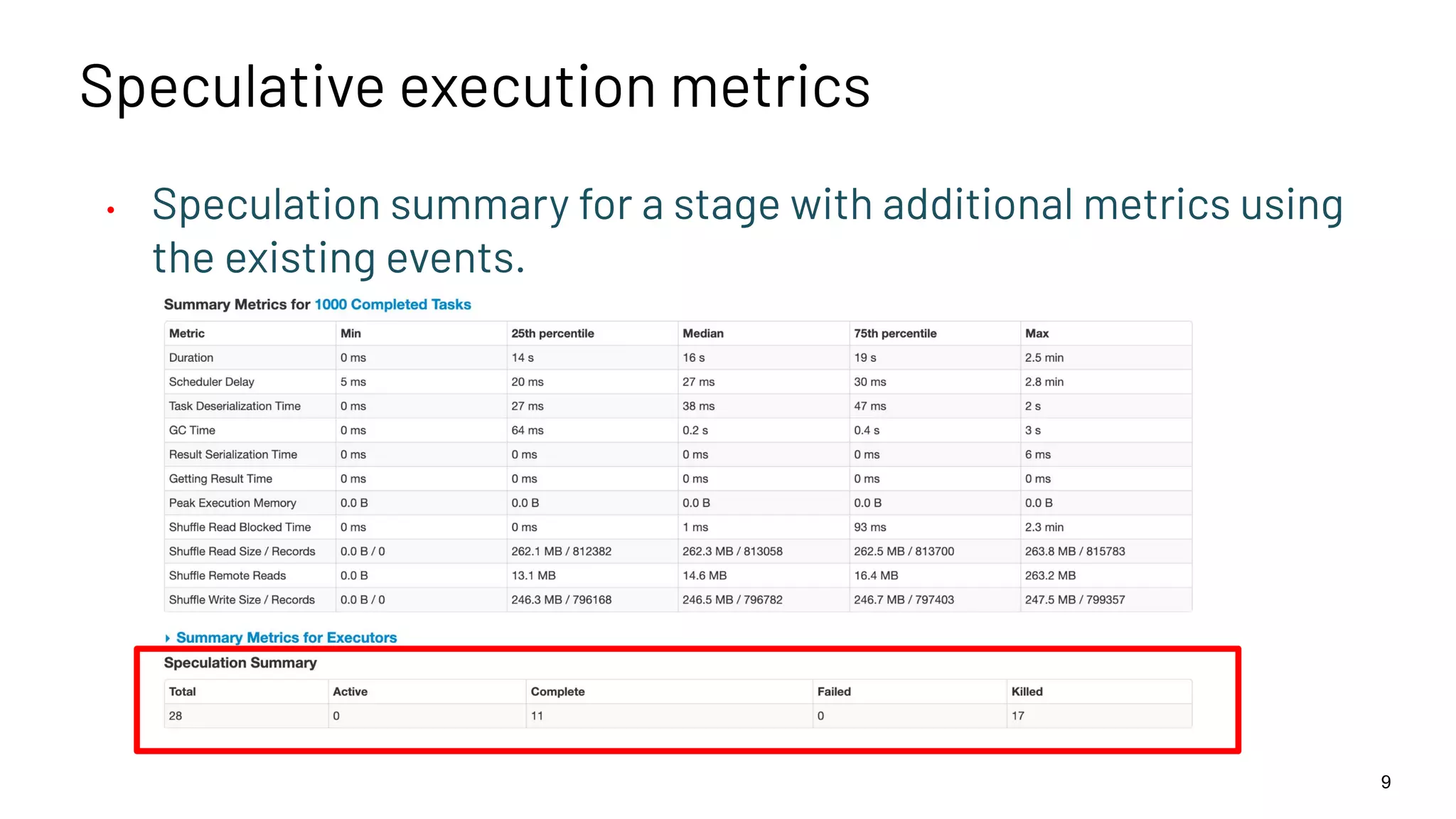
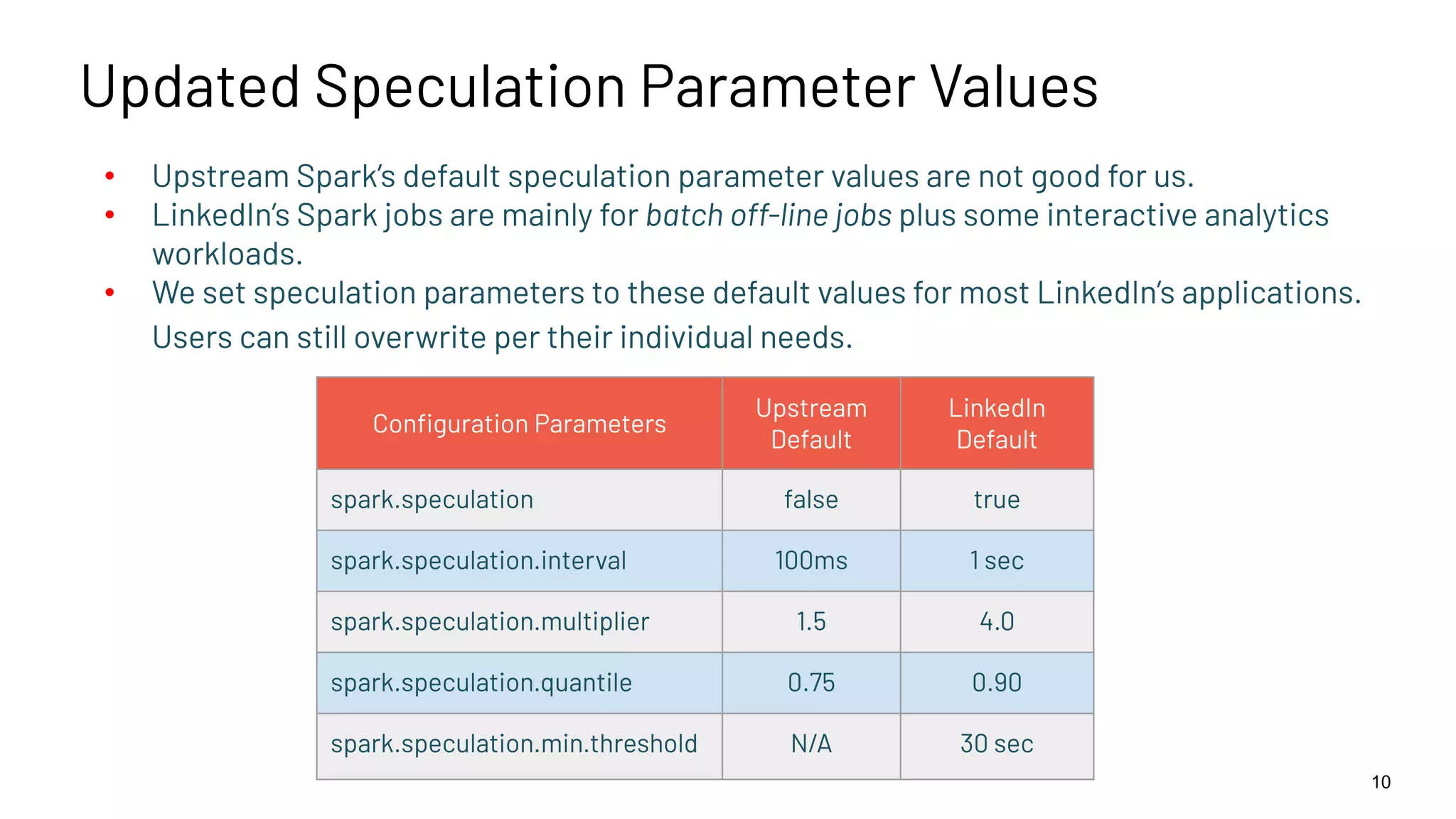


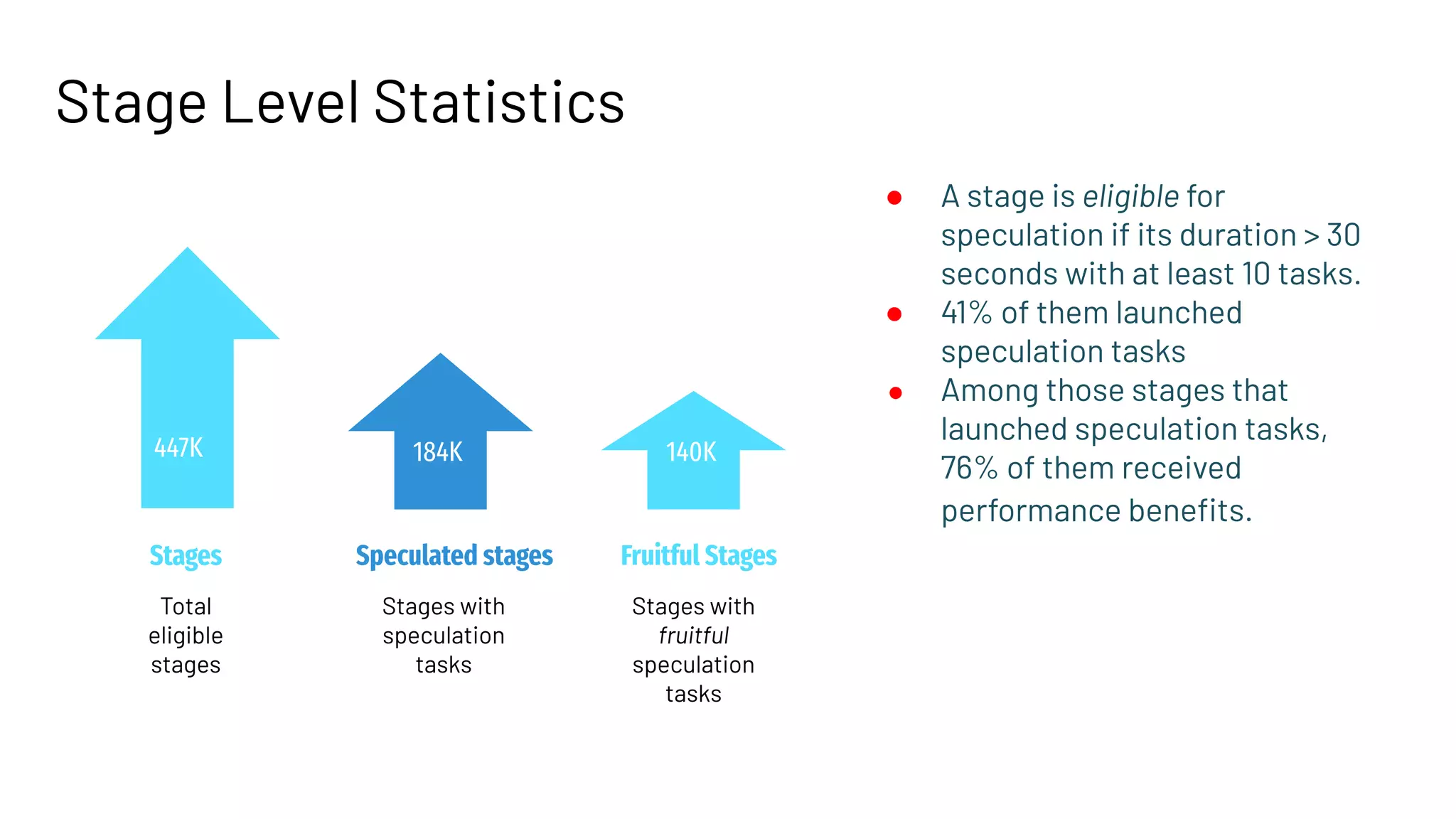


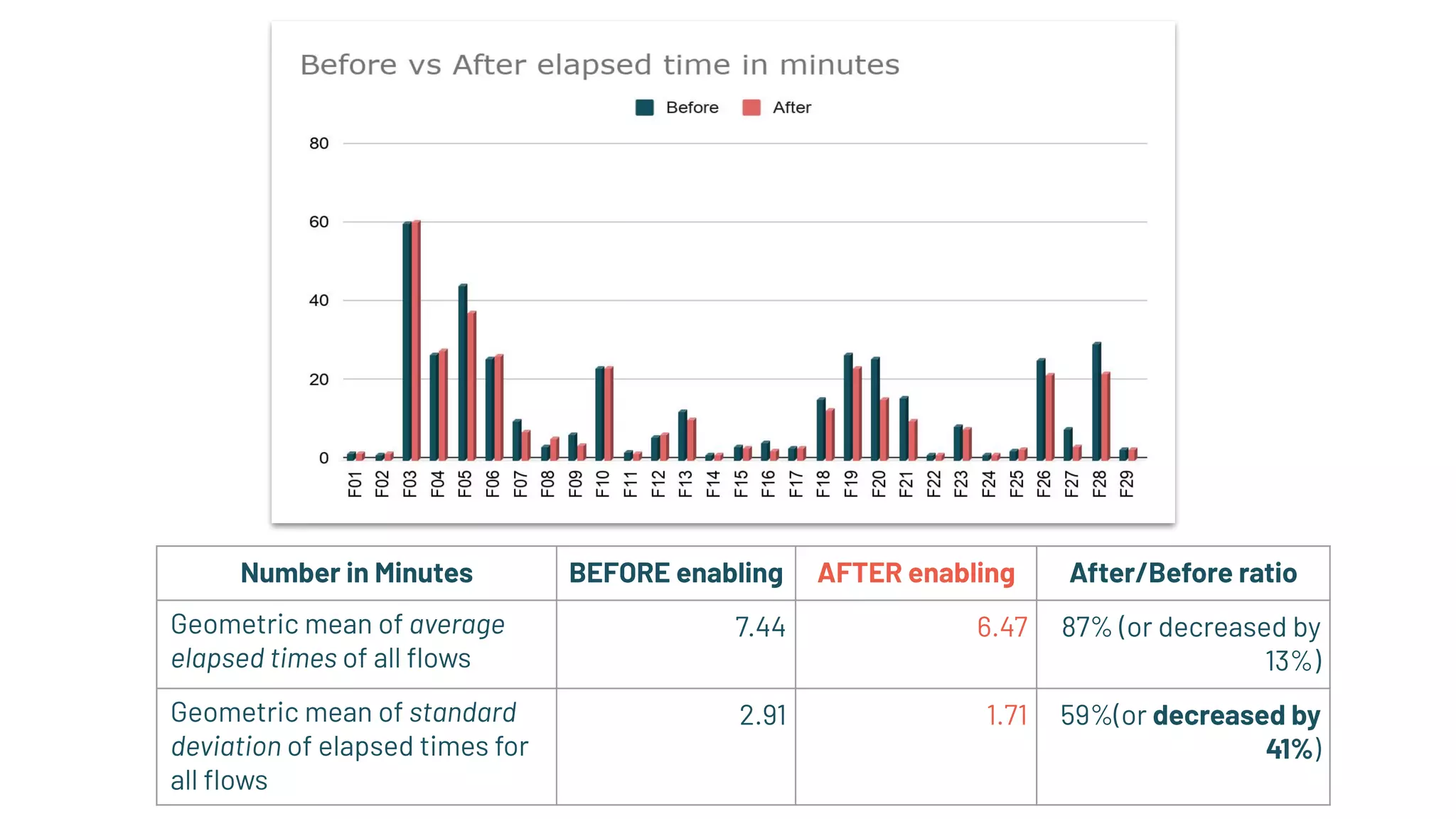
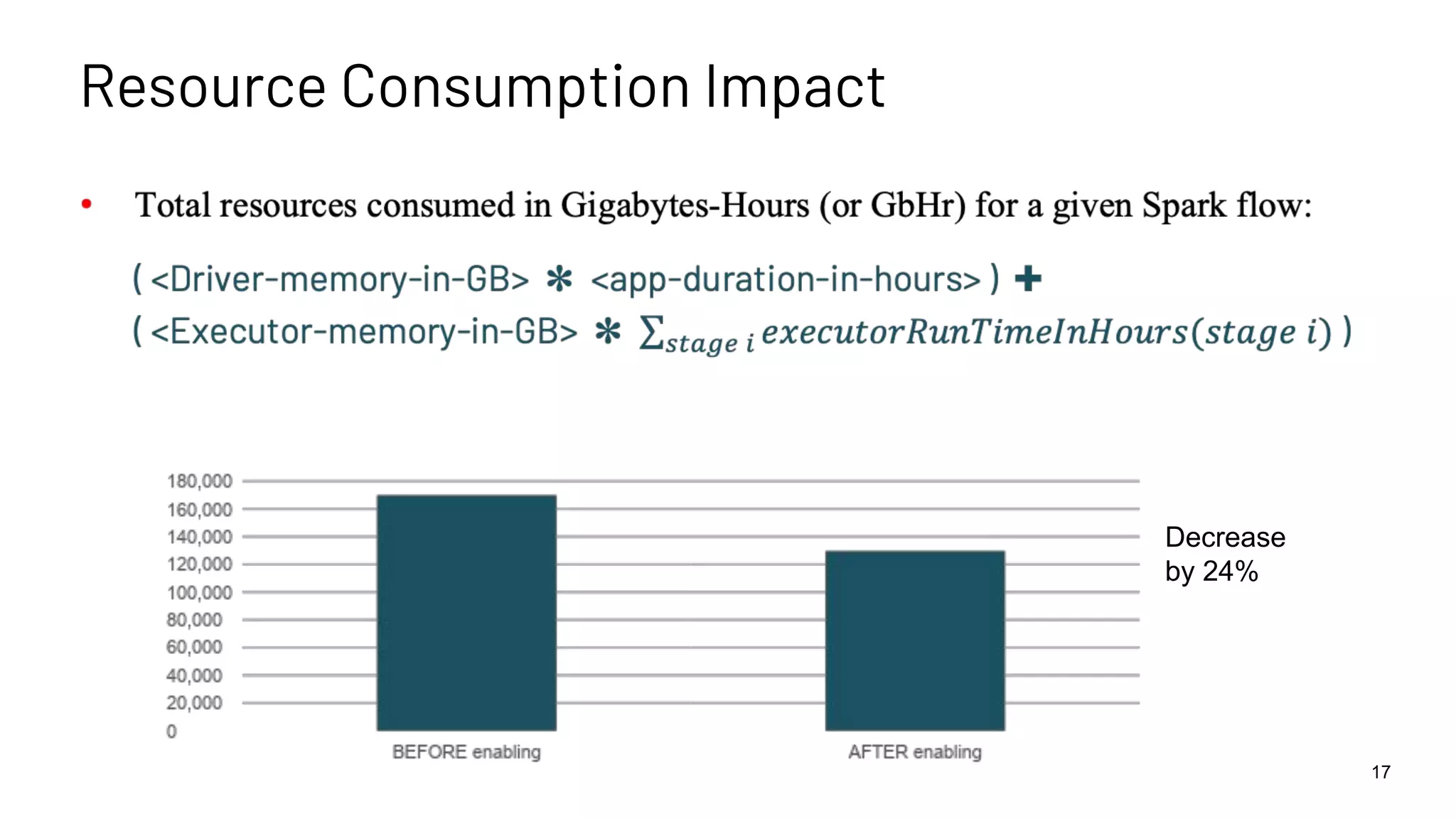







The document discusses best practices for enabling speculative execution in large-scale platforms, particularly in the context of Apache Spark at LinkedIn. It outlines configuration parameters, motivation for improvements, and metrics for analyzing speculative execution's impact on task performance and resource utilization. The findings indicate that tailored speculative execution parameters can enhance performance, reduce job completion times, and lead to more predictable system behavior.



















































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)



