Downloaded 127 times













































The document provides an overview of the Hadoop platform at Yahoo over the past year. It discusses the evolution of the platform infrastructure and metrics including growth in storage from 12PB to 65PB and compute capacity from 23TB to 240TB. It highlights new technologies added to the platform like CaffeOnSpark for distributed deep learning, Apache Storm for streaming analytics, and data sketches algorithms. It also discusses enhancements to existing technologies like HBase for transactions with Omid and improvements to Oozie for data pipelines. The document aims to provide insights on how the Hadoop platform at Yahoo has scaled to support growing analytics needs through consolidation, new services, and ease of use features.
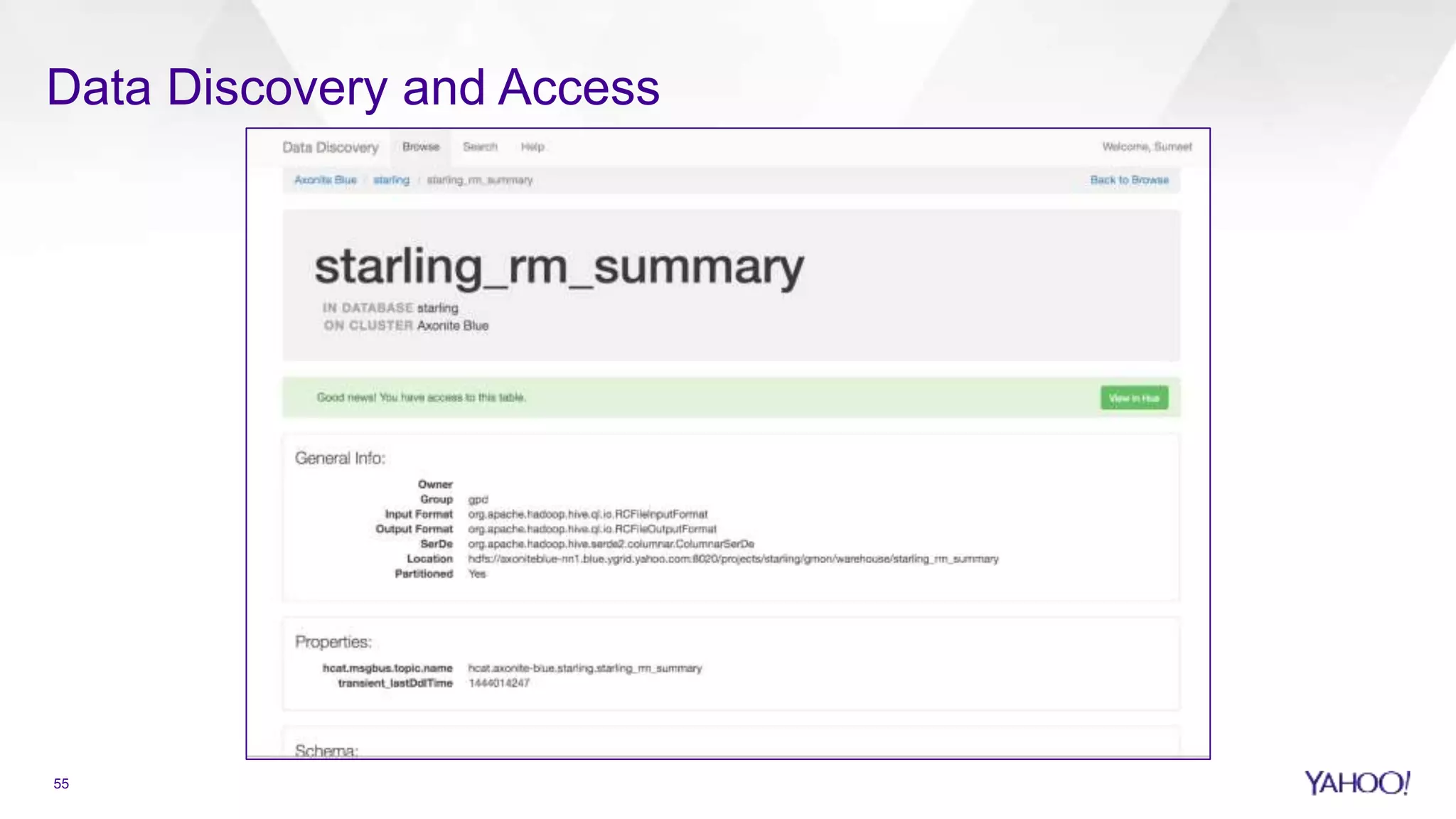
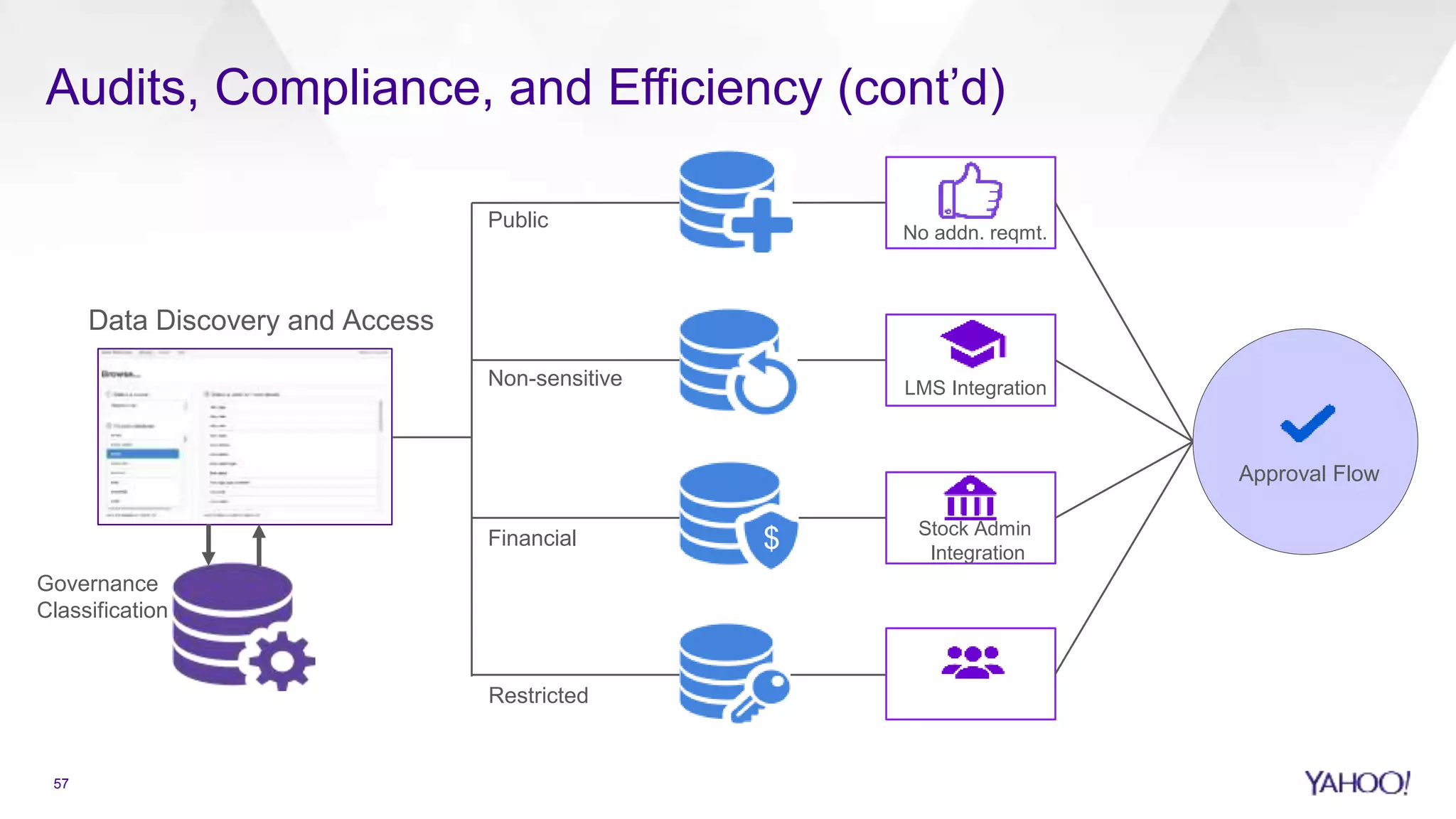
Introduction to Hadoop at Yahoo and its yearly review agenda.
Scaling Hadoop for production use with growing storage capacity and deployment models.
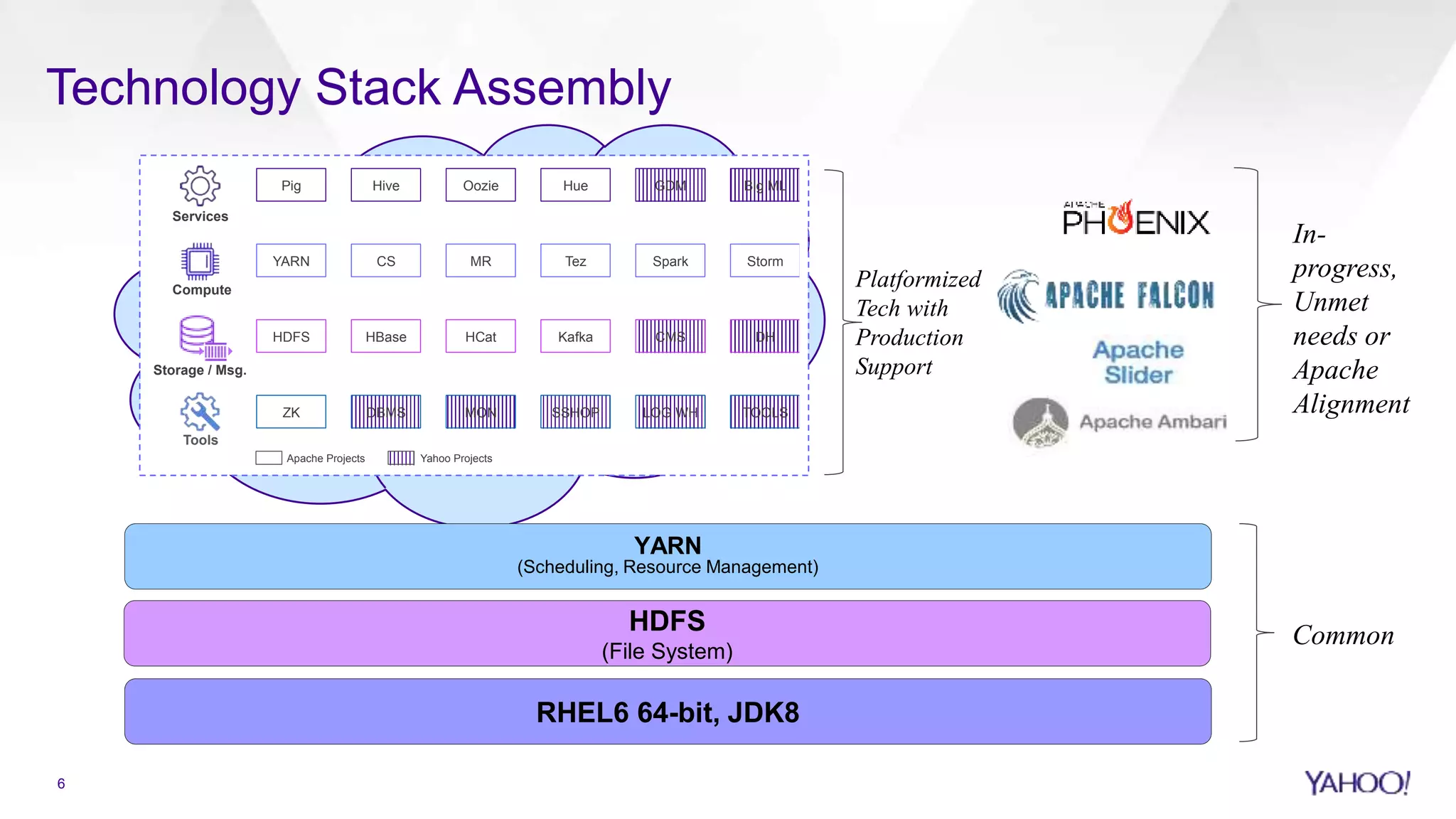
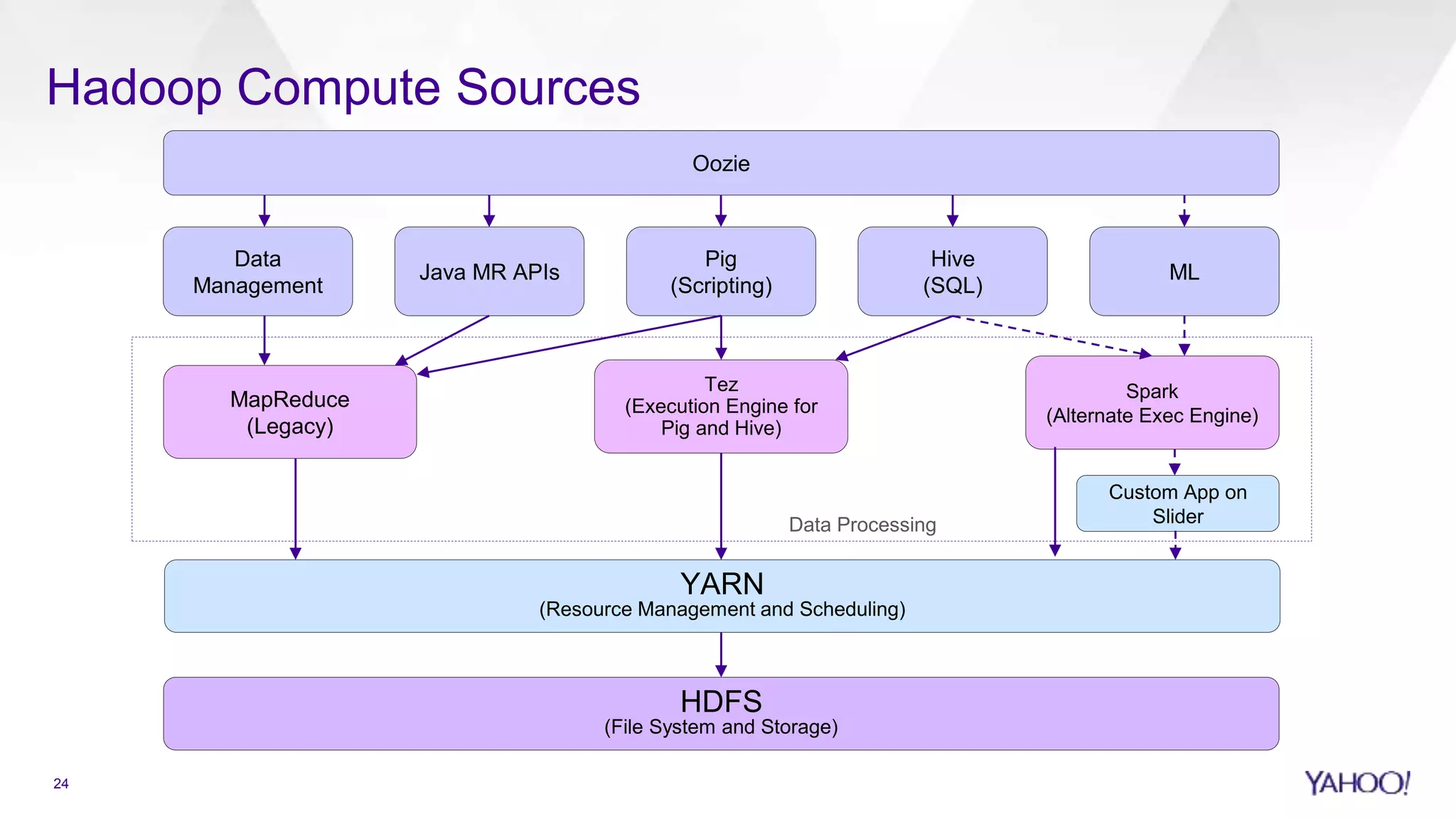
Overview of Yahoo's Hadoop platform components and technology stack including: HDFS, YARN, and proprietary services.
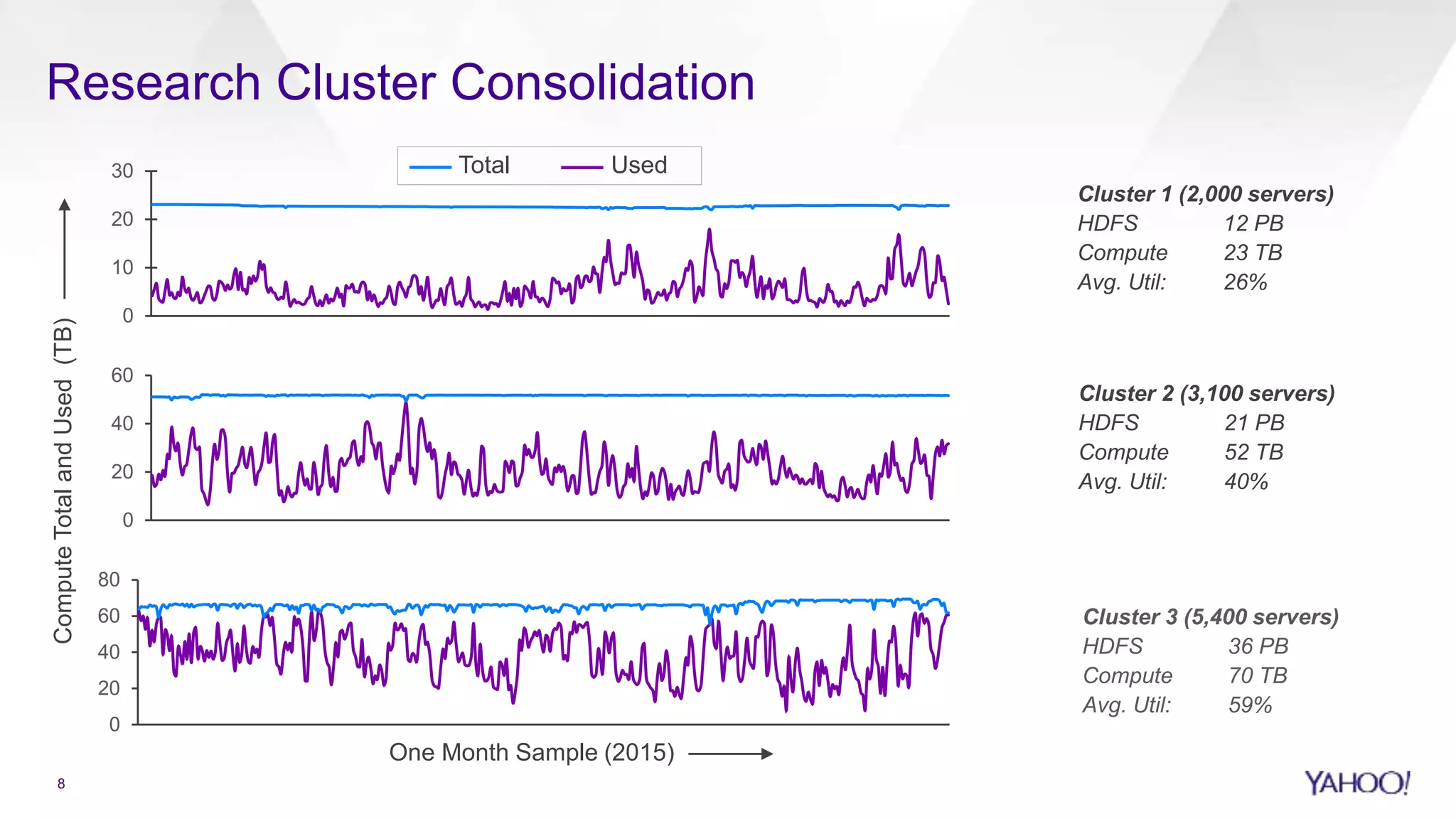
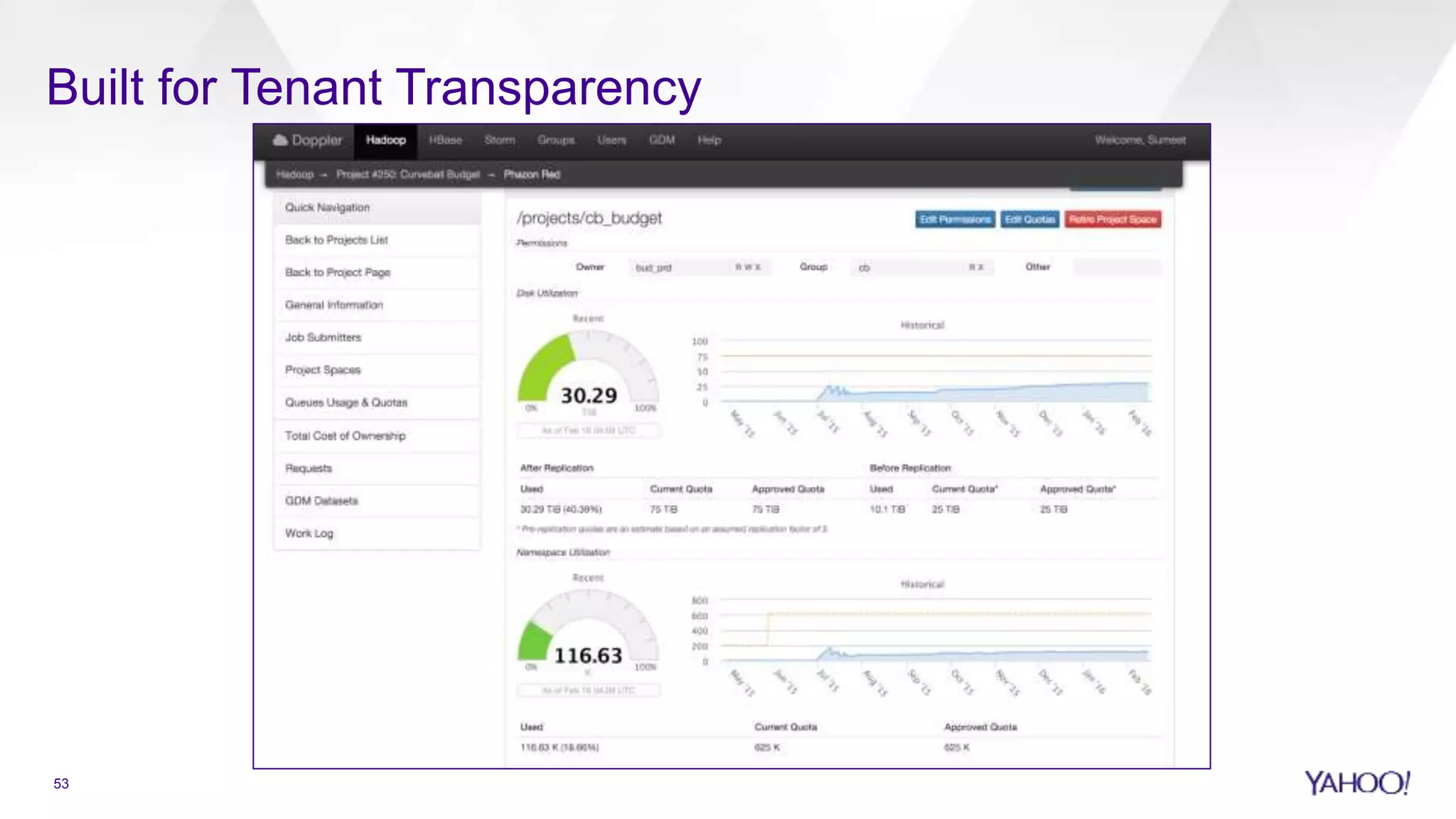
Research cluster consolidation statistics showing utilization metrics and TCO reduction.
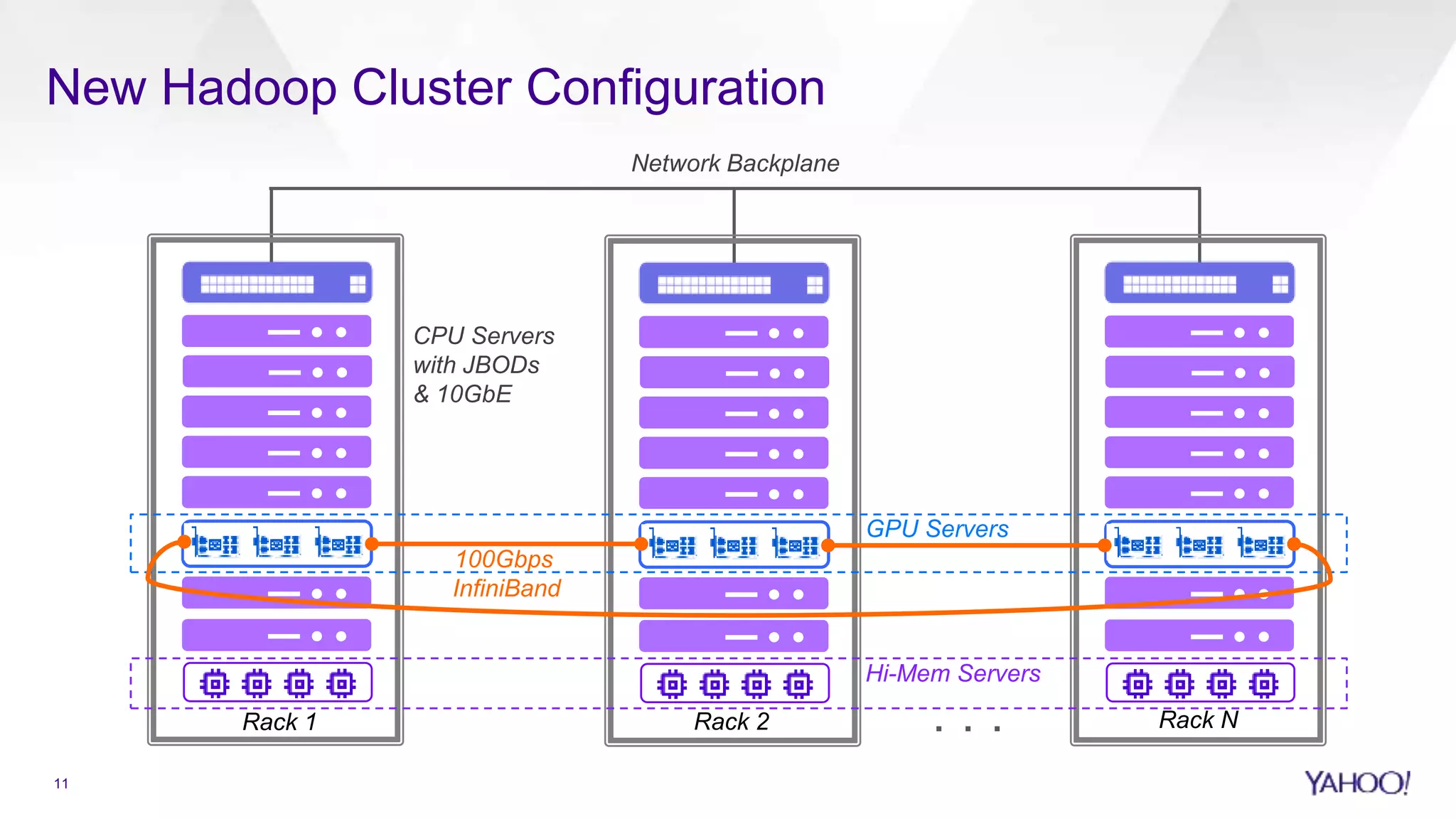
Configuration details of Hadoop clusters focusing on networking and hardware capabilities.
YARN node labels and how resource management works for Hadoop clusters.
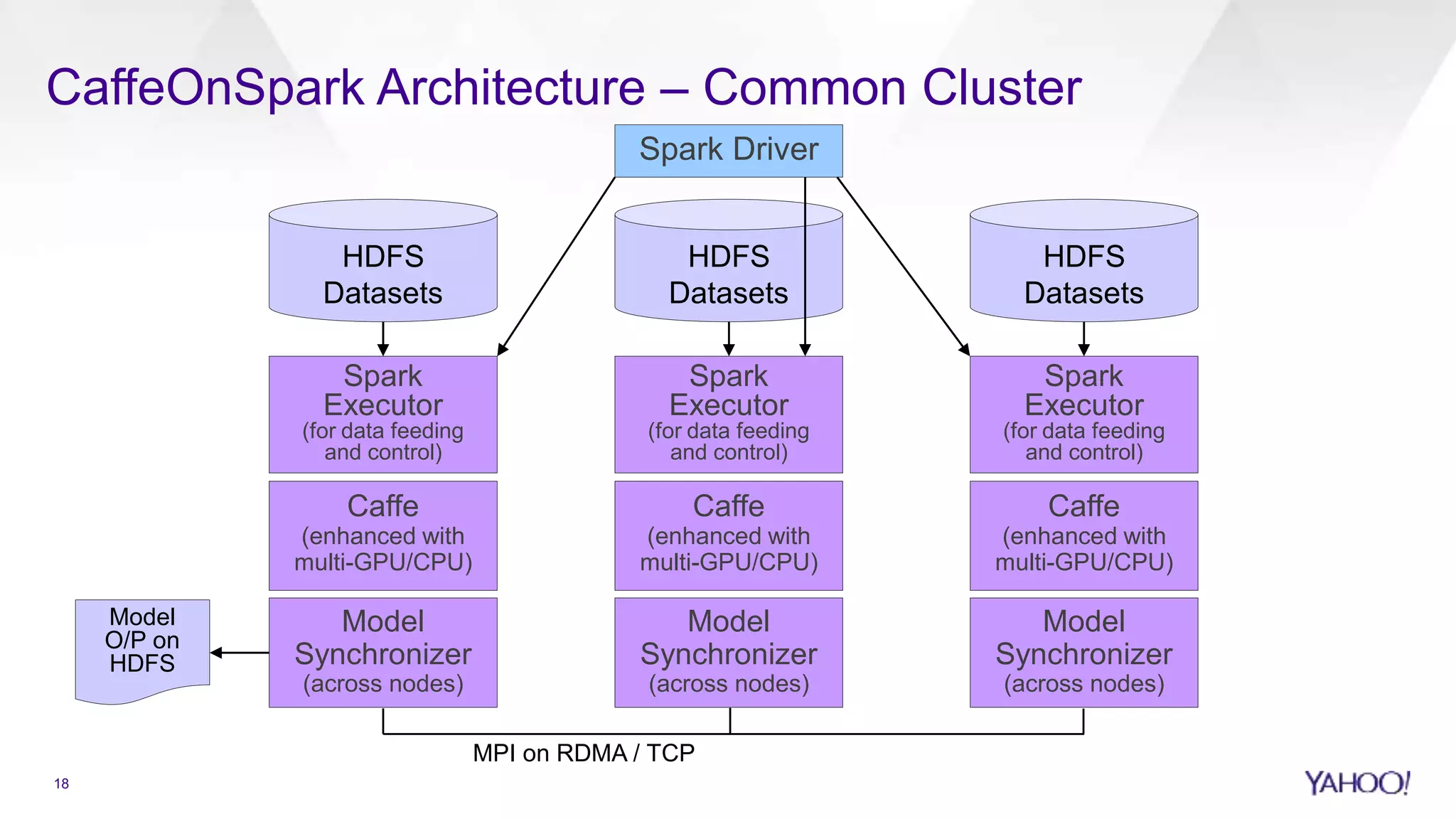
Infrastructure and architecture of CaffeOnSpark for distributed deep learning projects.
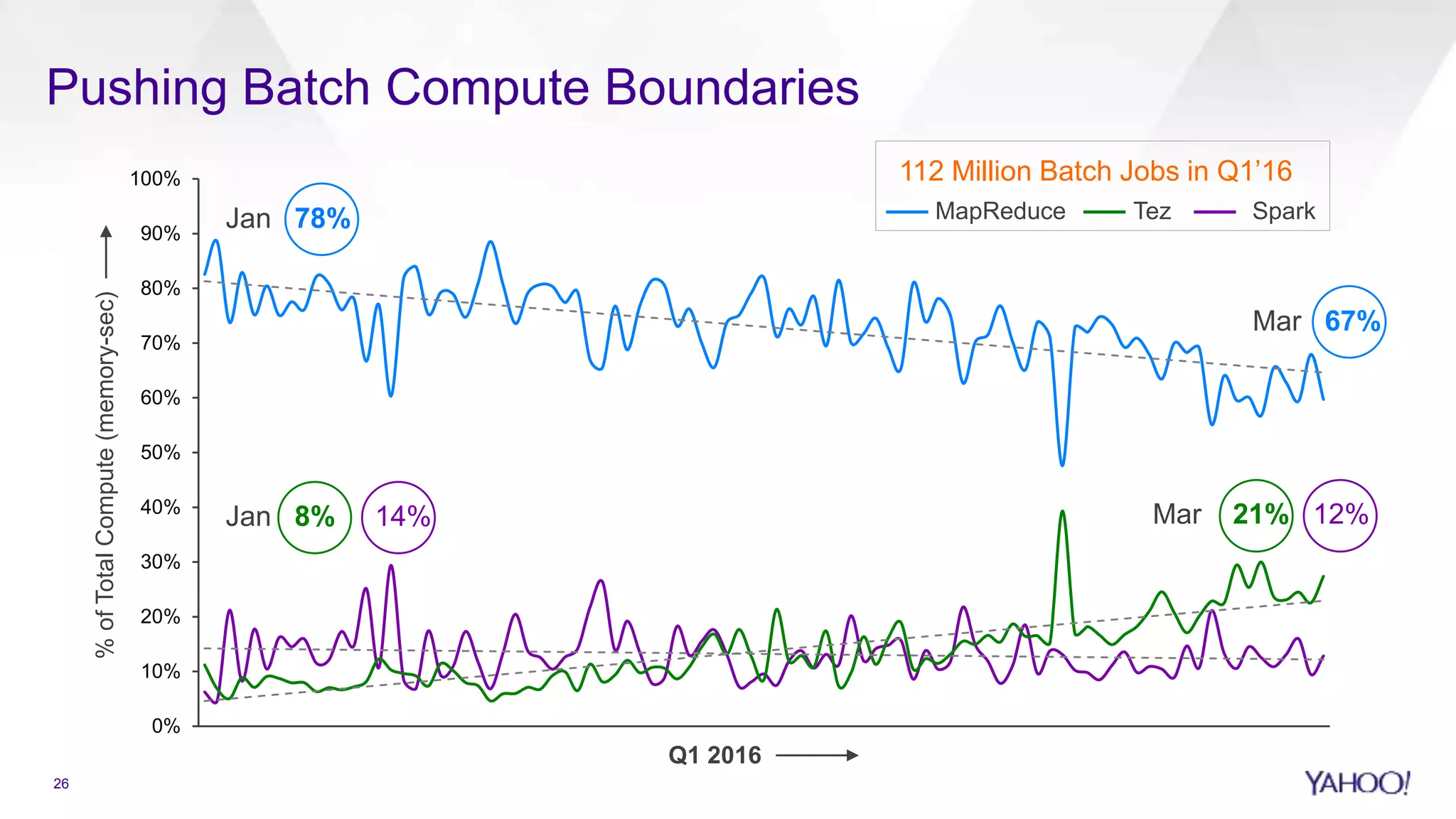
Overview of data processing sources in Hadoop, compute growth trends, and batch job management.
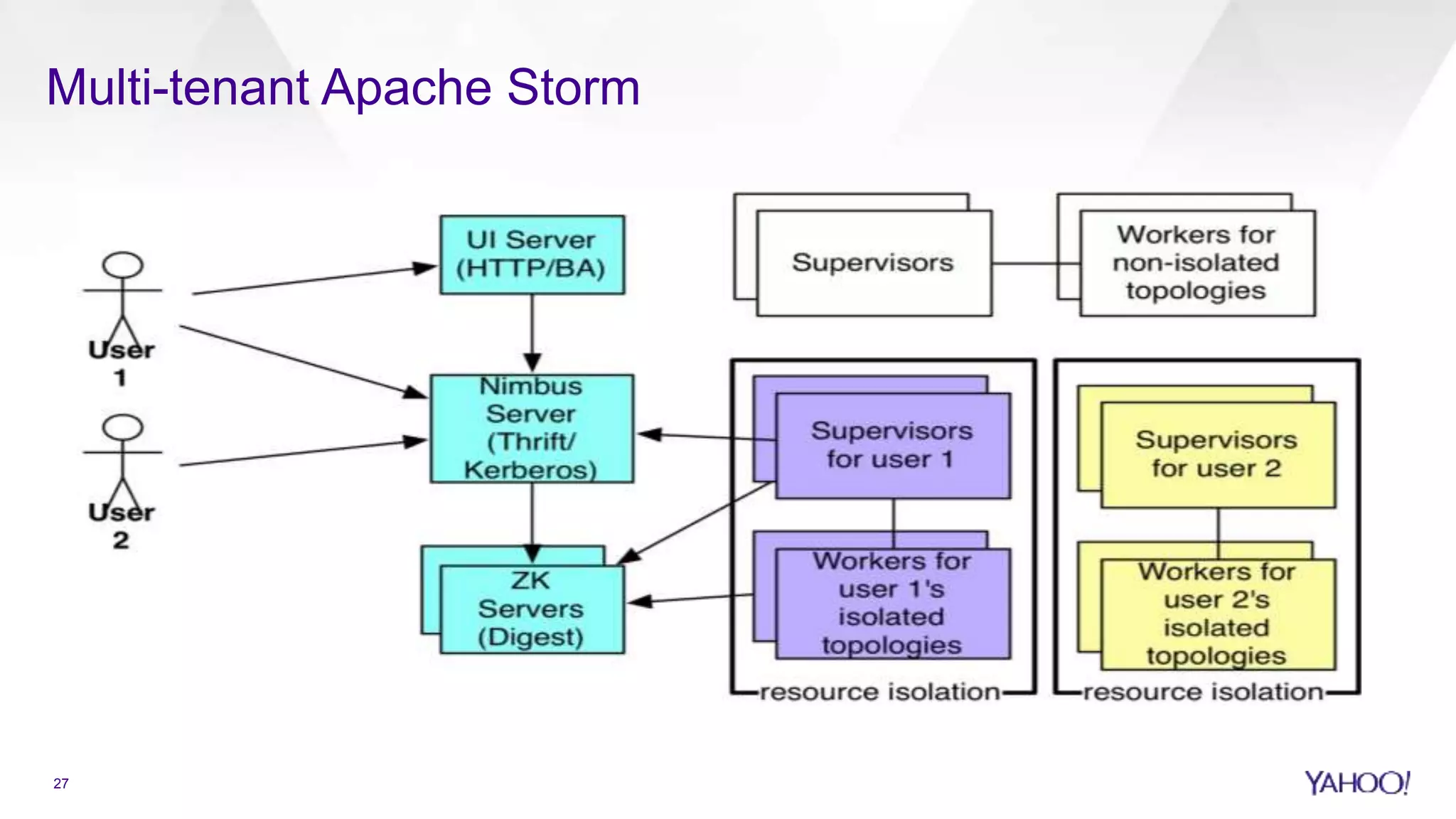
Recent advancements in Apache Storm for real-time processing and pipeline efficiency.
Introduction to the Data Sketches library for efficient processing and estimation on big data.
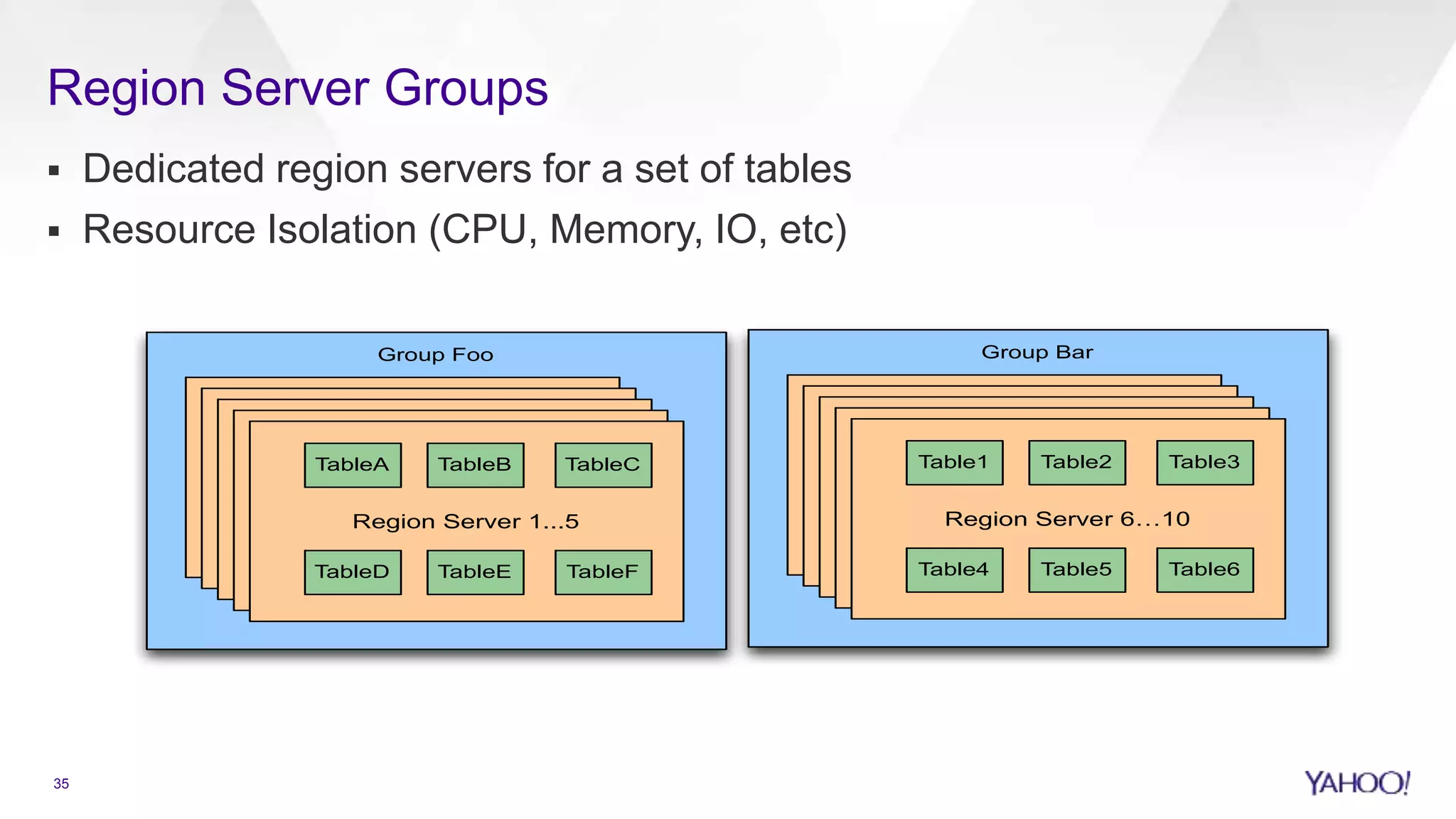
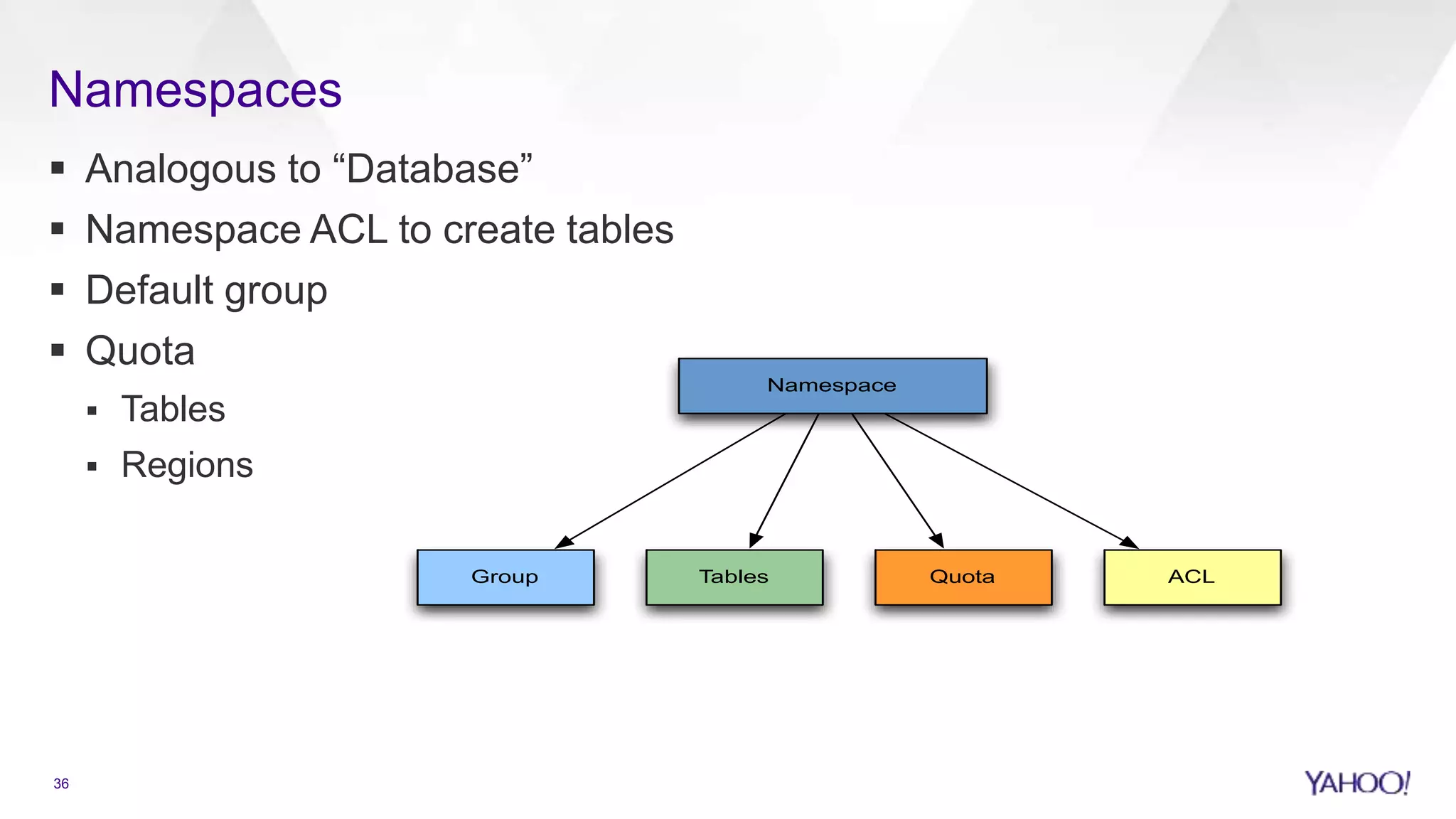
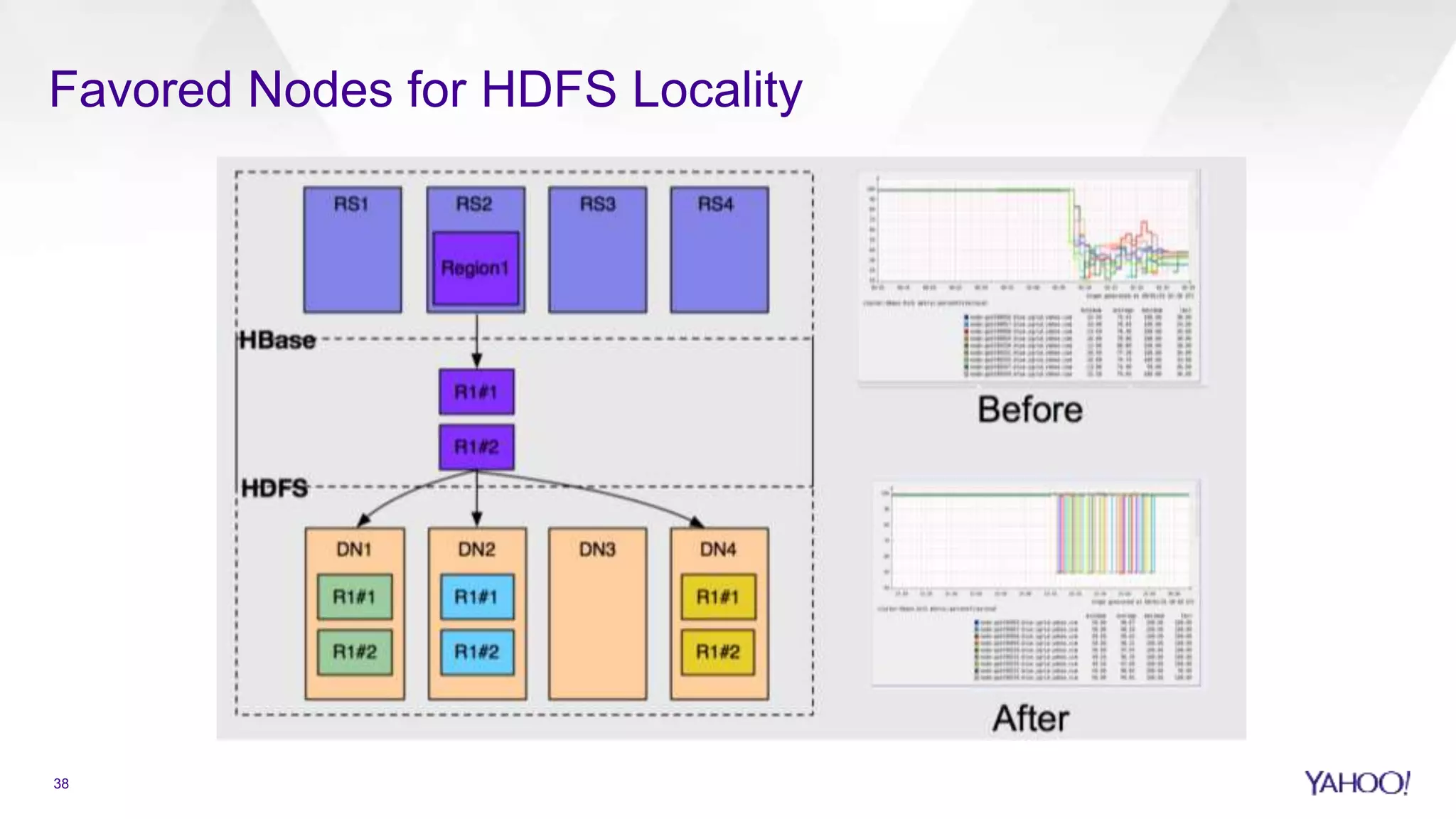
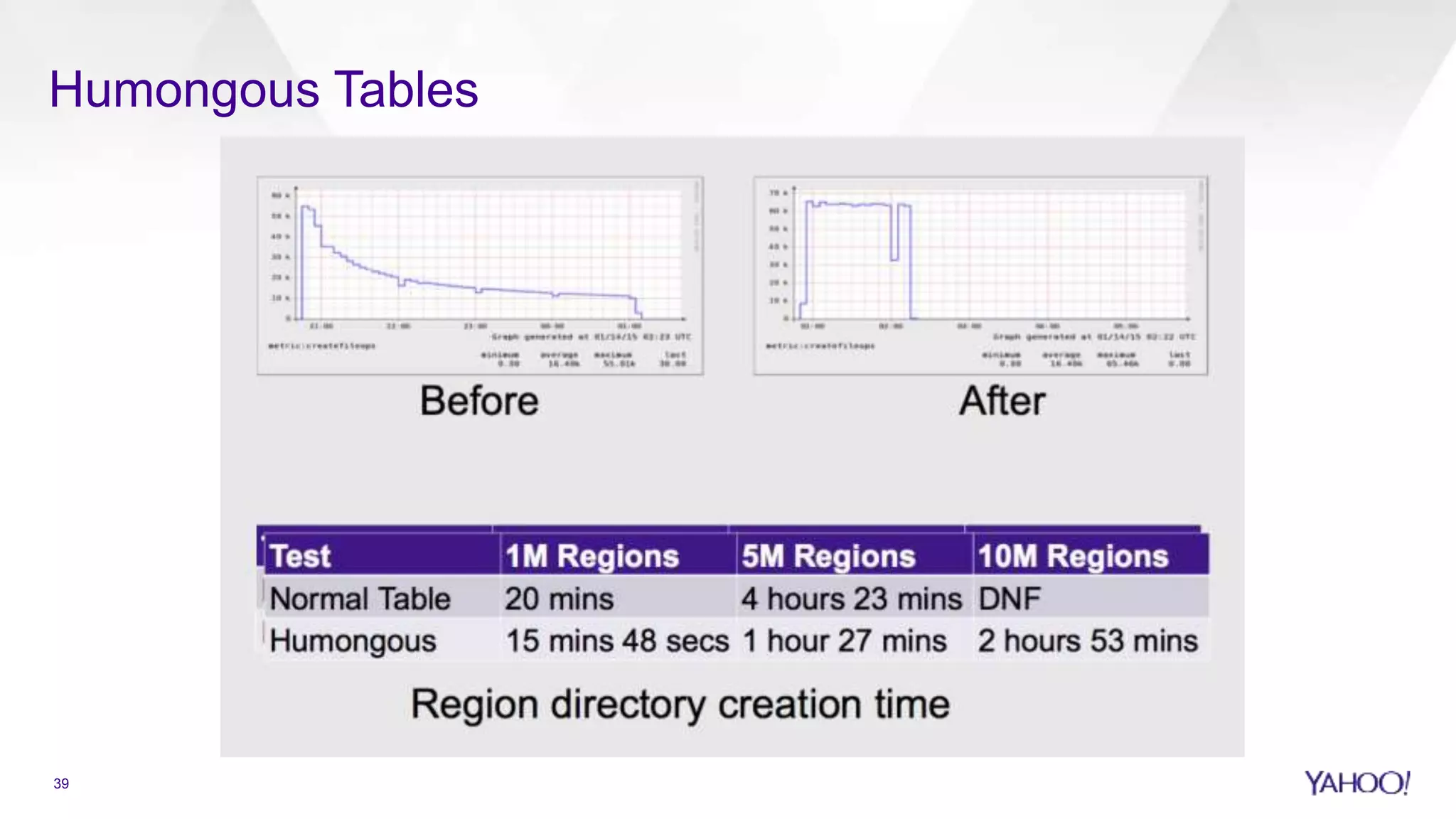
Overview of HBase including security, scalability, and handling large datasets.
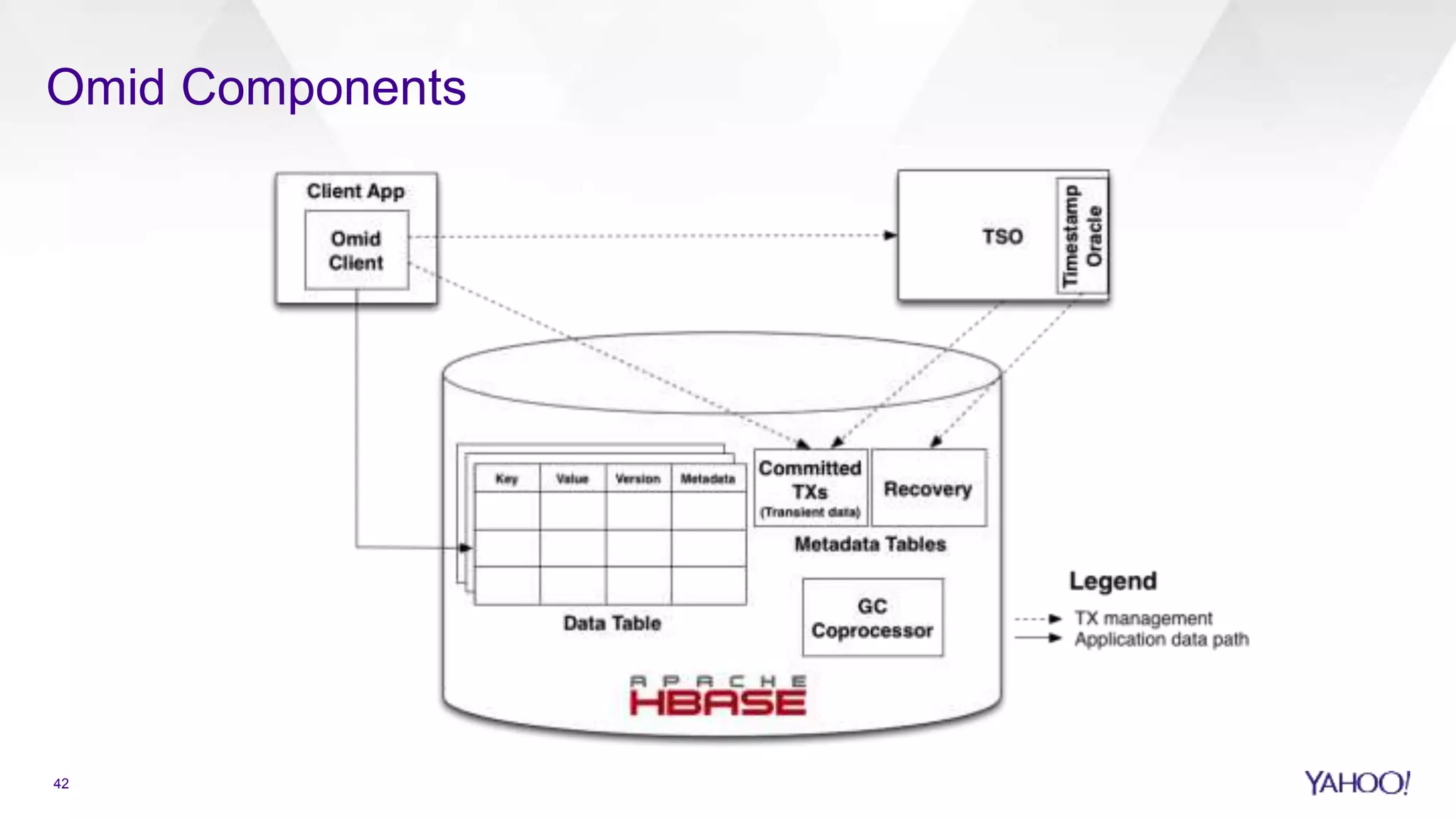
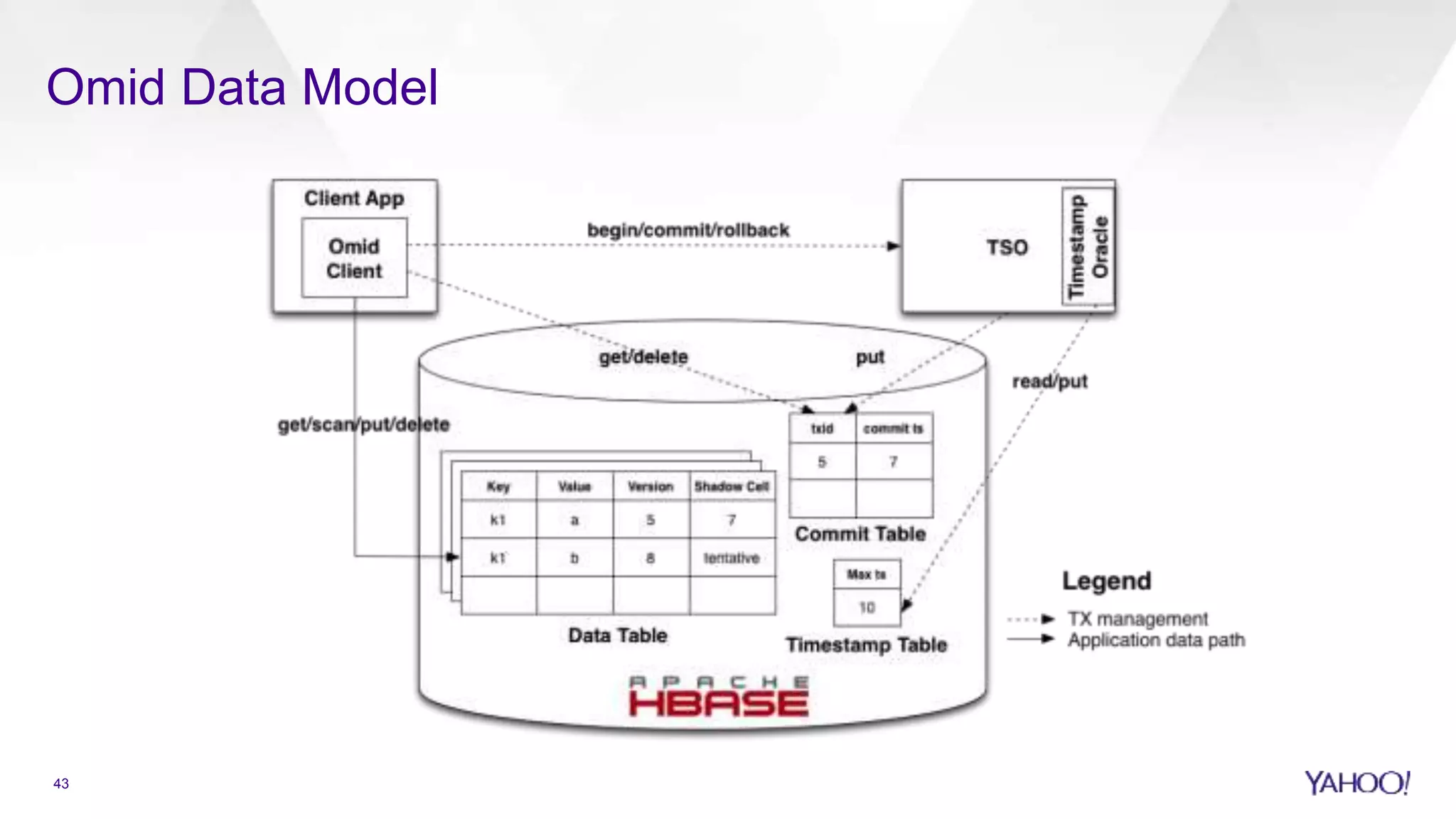
Introduction to Omid project for ACID transactions in HBase for search and personalization.
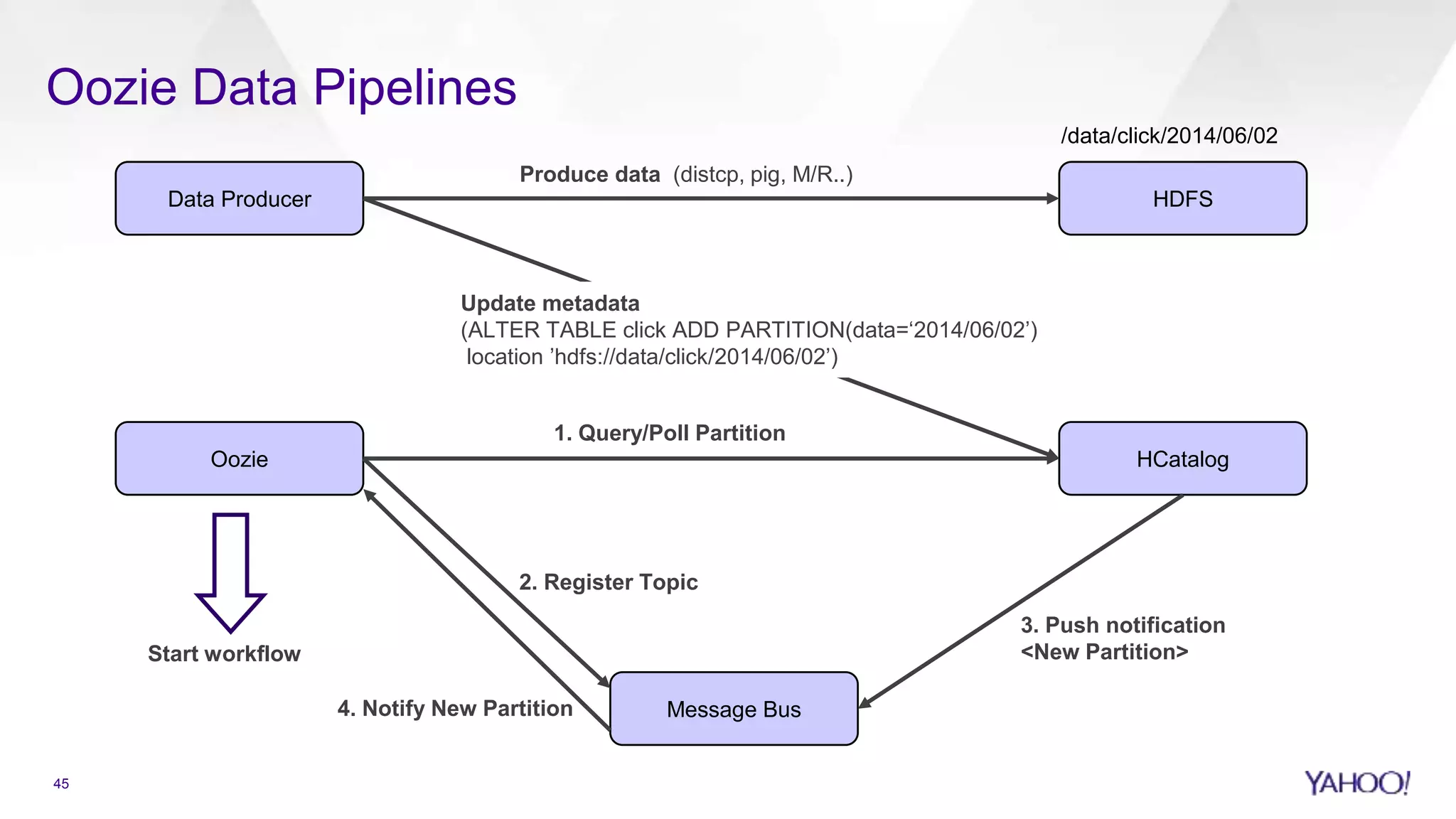
Oozie's role in managing data pipelines and the requirements for large-scale operations.
Future enhancements in intelligence, speed, efficiency, and user adoption at Yahoo Hadoop.





























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













