Downloaded 10 times














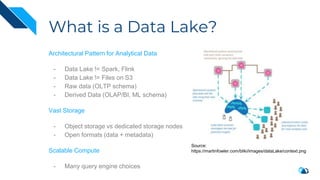
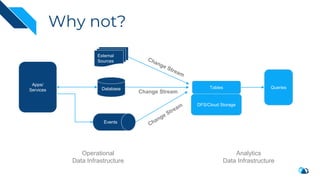


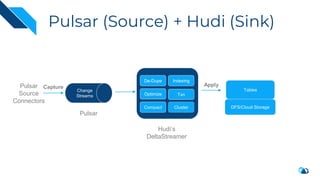
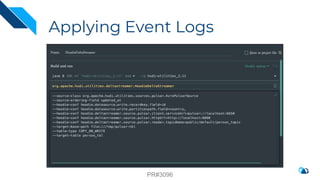
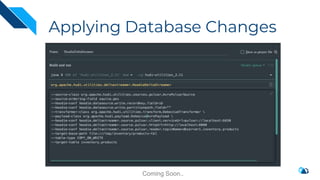


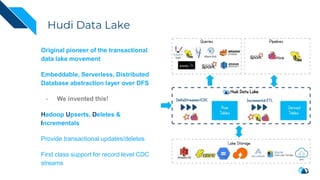
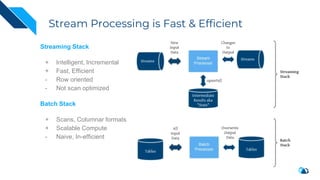
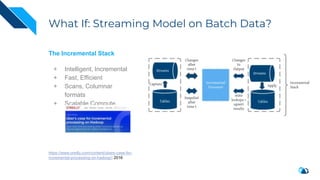


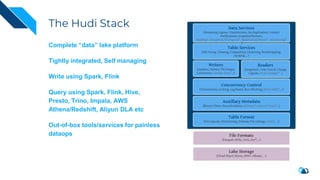
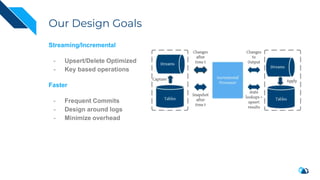
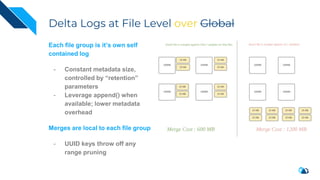
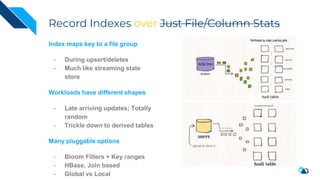
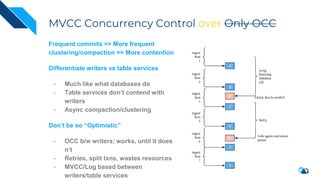

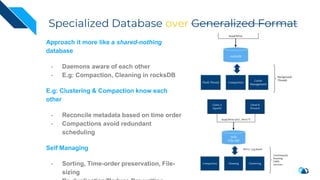
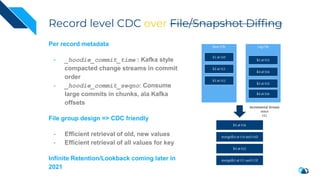







The document discusses the integration of Change Data Capture (CDC) with data lakes using Apache Pulsar and Apache Hudi, detailing the advantages of CDC for real-time data processing. It outlines the challenges of traditional data lakes and presents Hudi's transactional capabilities and architectural benefits. The speaker, an expert in data infrastructure, aims to explain the practical applications and ongoing developments in streaming ETL using these technologies.










































































