Recommended
PDF
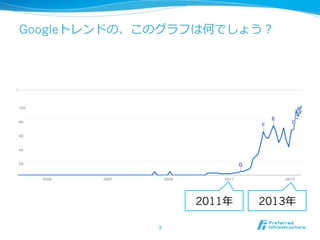
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
PPTX
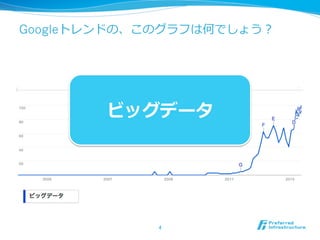
Counterfaual Machine Learning(CFML)のサーベイ
PDF
PDF
PDF
PDF
PDF
PPTX
Curriculum Learning (関東CV勉強会)
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
PDF
PDF
PDF
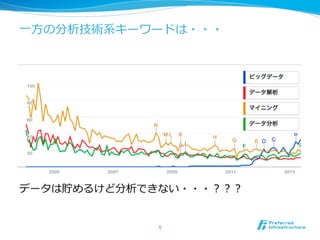
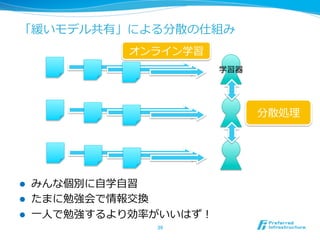
分散学習のあれこれ~データパラレルからモデルパラレルまで~
PDF
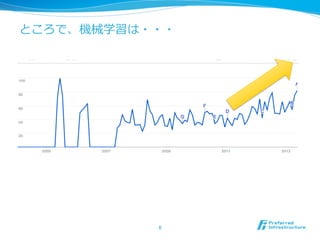
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
PDF
PPTX
PDF
Jubatus Casual Talks #2 異常検知入門
PDF
PDF
PPTX
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
PDF
PDF
深層学習と確率プログラミングを融合したEdwardについて
PDF
PDF
cvpaper.challenge 研究効率化 Tips
PDF
Anomaly detection 系の論文を一言でまとめた
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
PDF
More Related Content
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
PPTX
Counterfaual Machine Learning(CFML)のサーベイ
PDF
PDF
PDF
PDF
PDF
PPTX
Curriculum Learning (関東CV勉強会)
What's hot
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
PDF
PDF
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
PDF
PPTX
PDF
Jubatus Casual Talks #2 異常検知入門
PDF
PDF
PPTX
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
PDF
PDF
深層学習と確率プログラミングを融合したEdwardについて
PDF
PDF
cvpaper.challenge 研究効率化 Tips
PDF
Anomaly detection 系の論文を一言でまとめた
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
Viewers also liked
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
PDF
PDF
はじめてでもわかるベイズ分類器 -基礎からMahout実装まで-
PDF
PDF
PDF
PDF
PDF
トピックモデルを用いた 潜在ファッション嗜好の推定
PDF
PPTX
PDF
PPTX
PDF
ロジスティック回帰の考え方・使い方 - TokyoR #33
PDF
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
PPTX
Pythonとdeep learningで手書き文字認識
PDF
scikit-learnを用いた機械学習チュートリアル
PDF
TensorFlow を使った�機械学習ことはじめ (GDG京都 機械学習勉強会)
PDF
PDF
Chainerチュートリアル -v1.5向け- ViEW2015
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
Similar to 機械学習チュートリアル@Jubatus Casual Talks
PDF
PDF
Jubatusにおける大規模分散オンライン機械学習
PDF
PDF
Hands on-ml section1-1st-half-20210317
PDF
PDF
PPTX
PDF
PDF
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
PDF
PDF
Jubatusの紹介@第6回さくさくテキストマイニング
PPTX
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
PDF
PDF
深層学習(ディープラーニング)入門勉強会資料(浅川)
PPTX
1028 TECH & BRIDGE MEETING
PDF
深層強化学習 Pydata.Okinawa Meetup #22
PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
PDF
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
More from Yuya Unno
PDF
PDF
PDF
ベンチャー企業で言葉を扱うロボットの研究開発をする
PDF
PDF
PDF
PDF
PDF
最先端NLP勉強会�“Learning Language Games through Interaction”�Sida I. Wang, Percy L...
PDF
PDF
Chainerのテスト環境とDockerでのCUDAの利用
PDF
PDF
PDF
NIP2015読み会「End-To-End Memory Networks」
PDF
PDF
PDF
PDF
PDF
PDF
PDF
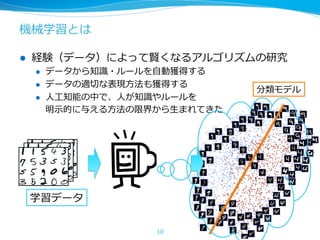
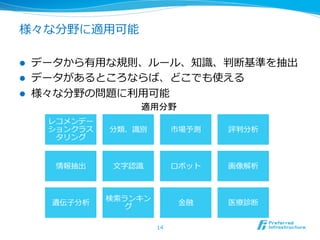
機械学習チュートリアル@Jubatus Casual Talks 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. まとめ:機械学習 vs ⼈人間 vs ルール
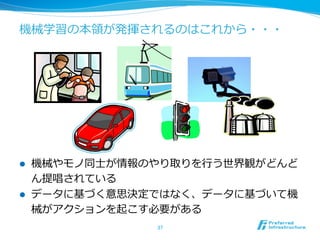
l 機械学習は速度度、量量、精度度、メンテナンス性のバランス
がとれている
l ⼈人間に⽐比べて・・
l 量量と速度度に優る
l 疲れない、ぶれない、スケールする
l ルールに⽐比べて
l 精度度に優る
l メンテナンスできる、引き継げる、データの変化に強い
22
23. 24. 機械学習の世界の分類
l 問題設定に基づく分類
l 教師有学習 / 教師無学習 / 半教師有学習 / 強化学習 など ..
l 戦うドメインの違い
l 特徴設計屋(各ドメイン毎に, NLP, Image, Bio, Music)
l 学習アルゴリズム屋(SVM, xx Bayes, CW, …)
l 理理論論屋(統計的学習理理論論、経験過程、Regret最⼩小化)
l 最適化実装屋
l 好みの違い
l Bayesian / Frequentist / Connectionist
l [Non-|Semi-]Parametric
24
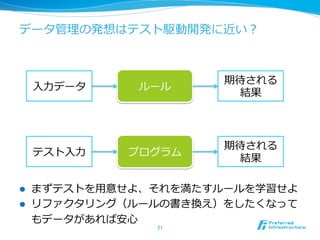
この⼆二つの問題設定だけは
知っておいてほしいので説明
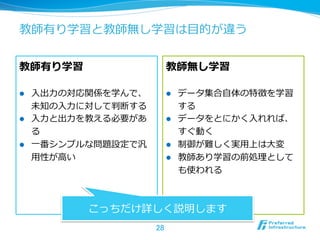
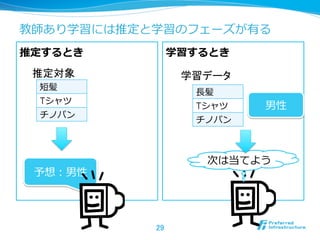
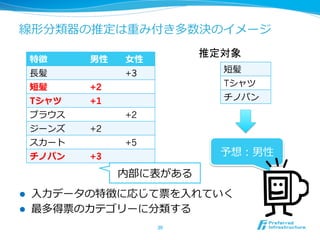
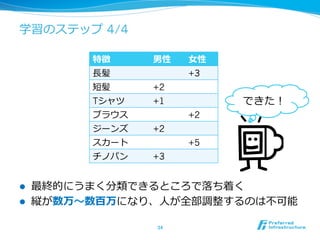
25. 教師有り学習
l ⼊入⼒力力 x に対して期待される出⼒力力 y を教える
l 分析時には未知の x に対応する y を予測する
l 分類
l y がカテゴリの場合
l スパム判定、記事分類、属性推定、etc.
l 回帰
l y が実数値の場合
l 電⼒力力消費予測、年年収予測、株価予測、etc.
25
x y
26. 教師無し学習
l ⼊入⼒力力 x をたくさん与えると、⼊入⼒力力情報⾃自体の性質に関し
て何かしらの結果を返す
l クラスタリング
l 与えられたデータをまとめあげる
l 異異常検知
l ⼊入⼒力力データが異異常かどうかを判定する
26
x
27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. l NTT SIC*とPreferred Infrastructureによる共同開発
l 2011年年10⽉月よりOSSで公開 http://jubat.us/
Jubatus
38
リアルタイム
ストリーム 分散並列列 深い解析
* NTT研究所 サイバーコミュニケーション研究所
ソフトウェアイノベーションセンタ
39. 40. 41.















![機械学習の世界の分類
l 問題設定に基づく分類
l 教師有学習 / 教師無学習 / 半教師有学習 / 強化学習 など ..
l 戦うドメインの違い
l 特徴設計屋(各ドメイン毎に, NLP, Image, Bio, Music)
l 学習アルゴリズム屋(SVM, xx Bayes, CW, …)
l 理理論論屋(統計的学習理理論論、経験過程、Regret最⼩小化)
l 最適化実装屋
l 好みの違い
l Bayesian / Frequentist / Connectionist
l [Non-|Semi-]Parametric
24
この⼆二つの問題設定だけは
知っておいてほしいので説明](https://image.slidesharecdn.com/20130602jubatusmltutorial-130601232741-phpapp01/85/Jubatus-Casual-Talks-24-320.jpg)

















![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)




























































