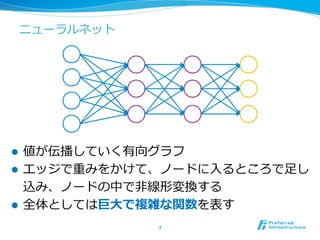
Chainer はニューラルネットのフレームワーク
l 機能
l ニューラルネットを記述する
l ニューラルネットの順伝播・逆伝播を実⾏する
l 勾配法を実⾏してパラメータを最適化する
l Chainer の特徴
l 順伝播は単純に Python のスクリプトとして書ける
l そのスクリプトの実⾏結果は計算⼿順を記憶してい
て、逆伝播を⼿で書く必要はない
13
14.
Chainer のインストール
l 環境はLinux(特に Ubuntu)がおすすめ
l インストール⽅法
l 新しめの Python 環境を⽤意(CPython 2.7+, 3.4+, 3.5+)
l pip も⽤意
l コマンドを実⾏: pip install chainer
l chainer パッケージが import できれば完了です
l Python スタックの環境構築は、Anaconda がお
すすめ
l Python のバージョン管理は pyenv がおすすめ
l pyenv からコマンド⼀つで Anaconda もインストールできます
14
15.
順伝播
l 今まで「変数」と呼んでいたものは、Chainer
では Variableオブジェクト
l Variable を Function に⼊れると、順伝搬後の
Variable が返ってくる
l Variable が計算グラフを保持している
l Function は、四則演算以外に
chainer.functions に⽤意されている
15
Variable オブジェクト
l 計算グラフの(データ)ノード
l NumPy または CuPy(後述)の配列を保持する
l 初期化時に配列を渡す
l data 属性に保存される
l 多くの Function は配列の最初の軸をミニバッチとして
使うので注意
l 下の x は、20 次元ベクトルが 10 個⼊ったミニバッチとみなす
l 現状、Chainer は多くの場所で float32 配列を要求する
ので注意
17
x = Variable(np.zeros((10, 20),
dtype=np.float32))
x.data
18.
Function オブジェクト
l 計算グラフの「演算」ノード
l chainer.functions (以降 F) にいろいろ定義され
ている
l F.relu, F.max_pooling_2d, F.lstm, ...
l Functionの呼び出し結果が、再びVariableになる
l v1.5からパラメータはLinkとして分離された
18
x = Variable(...)
y = F.relu(x) # yもVariable
19.
Link オブジェクト
l パラメータ付きの関数
l 最適化の対象となる
l save/loadができる(v1.5からsave/loadをサポート)
l chainer.links(以降L)に⾊々⽤意されている
l L.Linear, L.Convolution2D, L.EmbedID, ...
l Linkの呼び出し結果が、再びVariableになる
l v1.5からFunctionとパラメータは分離され、パラメータ
付きの関数はLinkオブジェクトになった
19
v1.5~
Optimizer の設定
l 勾配が計算できたら、あとは勾配法をまわす
l 勾配法のアルゴリズムは Optimizer クラスの⼦クラス
l chainer.optimizers に定義されている
l 実装されている最適化⼿法:SGD, MomentumSGD, AdaGrad,
RMSprop, RMSpropGraves, AdaDelta, Adam
l 最適化対象をsetup メソッドに渡す
l 正則化はhook関数として登録する
optimizer = optimizers.SGD()
optimizer.setup(model)
optimizer.add_hook(optimizer.WeightDecay())
22
CuPyとNumPyの⽐較
import numpy
x =numpy.array([1,2,3], numpy.float32)
y = x * x
s = numpy.sum(y)
print(s)
import cupy
x = cupy.array([1,2,3], cupy.float32)
y = x * x
s = cupy.sum(y)
print(s)
28
29.
CuPyはどのくらい早いの?
l 状況しだいですが、最⼤数⼗倍程度速くなります
def test(xp):
a= xp.arange(1000000).reshape(1000, -1)
return a.T * 2
test(numpy)
t1 = datetime.datetime.now()
for i in range(1000):
test(numpy)
t2 = datetime.datetime.now()
print(t2 -t1)
test(cupy)
t1 = datetime.datetime.now()
for i in range(1000):
test(cupy)
t2 = datetime.datetime.now()
print(t2 -t1)
29
時間
[ms]
倍率
NumPy 2929 1.0
CuPy 585 5.0
CuPy +
Memory Pool
123 23.8
Intel Core i7-4790 @3.60GHz,
32GB, GeForce GTX 970



























![CuPyとNumPyの⽐較
import numpy
x = numpy.array([1,2,3], numpy.float32)
y = x * x
s = numpy.sum(y)
print(s)
import cupy
x = cupy.array([1,2,3], cupy.float32)
y = x * x
s = cupy.sum(y)
print(s)
28](https://image.slidesharecdn.com/20160702chainerintro-160702085422/85/Chainer-Cupy-28-320.jpg)
![CuPyはどのくらい早いの?
l 状況しだいですが、最⼤数⼗倍程度速くなります
def test(xp):
a = xp.arange(1000000).reshape(1000, -1)
return a.T * 2
test(numpy)
t1 = datetime.datetime.now()
for i in range(1000):
test(numpy)
t2 = datetime.datetime.now()
print(t2 -t1)
test(cupy)
t1 = datetime.datetime.now()
for i in range(1000):
test(cupy)
t2 = datetime.datetime.now()
print(t2 -t1)
29
時間
[ms]
倍率
NumPy 2929 1.0
CuPy 585 5.0
CuPy +
Memory Pool
123 23.8
Intel Core i7-4790 @3.60GHz,
32GB, GeForce GTX 970](https://image.slidesharecdn.com/20160702chainerintro-160702085422/85/Chainer-Cupy-29-320.jpg)


![⾃分でコードを書きたい時
例:z[i] = x[i] + 2 * y[i] を書きたい
32
引数の型: “float32 x, float32 y”
戻り値の型: “float32 z”
処理: “z = x + 2 * y;”
ループやインデックスの処理は
⾃動で埋めてくれる
これだけ書け
ば良い](https://image.slidesharecdn.com/20160702chainerintro-160702085422/85/Chainer-Cupy-32-320.jpg)






![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)


![[MIRU2018] Global Average Poolingの特性を用いたAttention Branch Network](https://cdn.slidesharecdn.com/ss_thumbnails/miru2018longorl-v3-180810062528-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Train longer, generalize better: closing the generalization gap in lar...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170721-170721035045-thumbnail.jpg?width=640&height=640&fit=bounds)













































![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)






































