More Related Content

PDF
銀行の融資業務における人工知能を利用したデータマイニング活用例 
PDF
MapReduceによる大規模データを利用した機械学習 
PDF

PDF

PPTX
Introduction of network analysis with Google Colaboratory -- Network Metrics 
PPTX

PDF

PDF
Randomforestで高次元の変数重要度を見る #japanr LT Viewers also liked

PPTX

PPTX
Kataluniako haur eskolak II 
PPTX
Besançoneko haur eskolak II 
PDF
Influencia de las nuevas tecnologías en la educación 
PPT

PPTX
Kataluniako haur eskolak I 
PPTX
Tecnologías de la actualidad 
PDF
Keynote derivatives daily report for 121112 
PPTX

PPTX

PDF
Innovate, Learn, Deliver: Staying ahead in turbulent times 
PPTX

PPTX

DOCX
Б.Гэрэлжаргал Б.Анхзаяа О.Номуужин - ДИЗАЙНЫ МЕНЕЖМЕНТИЙН ОРЧИН ҮЕИЙН ЧИГ ХАН... 
PDF
![[HUBFORUM Paris] BuzzFeed Presents the native truth - Will Hayward](https://cdn.slidesharecdn.com/ss_thumbnails/06-buzzfeed-141027035748-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[HUBFORUM Paris] BuzzFeed Presents the native truth - Will Hayward 
PPTX

PPTX
Sistem harga pokok proses 
PDF
Staying Ahead of Your Napster 
PPT
Reggio Emiliako haur eskolak Similar to Overview and Roadmap

PDF

PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム 
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平 
PDF
Jubatusの紹介@第6回さくさくテキストマイニング 
PDF

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17 
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9 
PDF

PDF

PDF

PDF
Jubatusにおける大規模分散オンライン機械学習@先端金融テクノロジー研究会 
PDF

PPT

PPTX
1028 TECH & BRIDGE MEETING 
PDF

PDF

PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太 
PDF
Oracle Cloud Developers Meetup@東京 
PPTX
リクルートを支える横断データ基盤と機械学習の適用事例 More from JubatusOfficial

PPTX

PDF

PDF

PDF

PPTX

PDF

PPTX

PPTX

PDF

PPTX

ODP

PPTX

PPTX

PPTX

PDF
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用 
PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化 
PDF

PDF

PDF

PDF
Overview and Roadmap
- 1.
- 2.
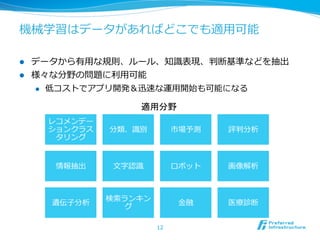
Big Data !
l データはこれからも増加し続ける
l 多いことより増えていくということが重要
データ量量の変化に対応できるスケーラブルなシステムが求められる
l データの種類は多様化
l 定形データのみならず、⾮非定形データも増加
l テキスト、⾏行行動履履歴、⾳音声、映像、信号
l ⽣生成される分野も多様化
l PC、モバイル、センサー、⾞車車、⼯工場、EC、病院
2
- 3.
- 4.
現状の背景
l 既存システムは次の3つの⽬目標を同時に達成することが困難
l 1)リアルタイム性の確保
l 2)データを⽔水平分散処理理
l 3)⾼高度度な解析
l 分散並列列処理理 (MapReduceなど)
l スケールアウト構成による性能向上、耐障害性
l 基本的にバッチ処理理、解析結果はすぐ返ってこない
l 計算モデルの⾃自由度度が⾼高い分オーバーヘッドも⼤大きい
l オンライン / ストリーム処理理 (CEPなど)
l 到着したデータをその場で処理理して解析し、結果を出⼒力力する
l 多くは単純な処理理しか⾏行行えない
4
- 5.
- 6.
Jubatus
l NTT PF研とPreferred Infrastructureによる共同開発
10/27よりOSSで公開 http://jubat.us/
リアルタイム
ストリーム 分散並列列 深い解析
6
- 7.
特徴1: リアルタイム /ストリーム処理理
l 解析結果は、データ投⼊入後すぐ返って来る
l 多クラス分類などの学習/分類も⼀一瞬で処理理
l twitterの内容を分析して分類するのは6000QPS
l (将来的には)データを投⼊入し、結果が⾮非同期で返って来るよう
にしたい。
l 分類、集計、統計分析、回帰、クラスタリングなど様々な処理理を
リアルタイム、ストリームで処理理したい
l 現状分類だけですがそれだけでも強⼒力力です
7
- 8.
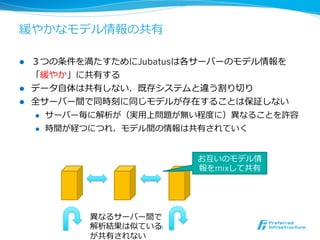
特徴2: 分散並列列処理理
l スケールアウト:ノードを追加することで、性能向上ができる
l 処理理量量に応じてシステムの⼤大きさを柔軟に変更更可能
l ⼩小さいデータから⼤大きなデータの処理理まで同じシステムで処理理
l 耐故障性も確保
l 各ノードが完全に独⽴立立な処理理なら簡単だが、それぞれが情報を蓄
積し、それらを共有して処理理するのは⼤大変
⇒ モデルの緩やかな共有で解決(後述)
8
- 9.
特徴3:深い解析
l 単純な集計、統計処理理だけではなく、⾃自動分類をはじめとした様
々な機械学習⼿手法をサポート
l 難しいことはやっておきますので使ってください
l ⾮非定形データを扱えるように、データからの特徴抽出もサポート
l 多くの機械学習ライブラリはこれがないので使えない
l 特徴抽出はプラグイン化され、今後サポートを増やしていく
9
- 10.
- 11.
- 12.
- 13.
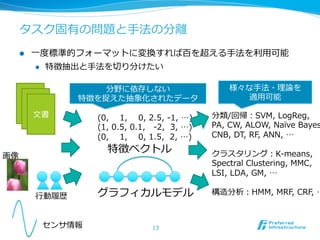
タスク固有の問題と⼿手法の分離離
l ⼀一度度標準的フォーマットに変換すれば百を超える⼿手法を利利⽤用可能
l 特徴抽出と⼿手法を切切り分けたい
分野に依存しない 様々な⼿手法・理理論論を
特徴を捉えた抽象化されたデータ 適⽤用可能
⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …) 分類/回帰:SVM, LogReg,
(1, 0.5, 0.1, -‐‑‒2, 3, …) PA, CW, ALOW, Naïve Bayes
(0, 1, 0, 1.5, 2, …) CNB, DT, RF, ANN, …
特徴ベクトル クラスタリング:K-‐‑‒means,
画像
Spectral Clustering, MMC,
LSI, LDA, GM, …
⾏行行動履履歴 グラフィカルモデル 構造分析:HMM, MRF, CRF, …
センサ情報 13
- 14.
機械学習の例例(1/3)
教師有学習
l ⼊入⼒力力xから出⼒力力yへのマッピングを学習する
l 分類:⼊入⼒力力データxからカテゴリ値yを予想する
l ⽂文書分類、ユーザー推定
l 回帰:⼊入⼒力力データxから数値yを予測する
l コンバージョン率率率予測、アクセス数予測、株価予測など
l リスク分析なども
l 問題の特性、予測性能に応じて様々な⼿手法が存在
l Jubatusはこれらの⼿手法をオンライン、分散並列列化しサポートする
14
- 15.
機械学習の例例(2/3)
レコメンド
l 近傍探索索:クエリデータと似た登録データを返す
l この商品データと良良く似た商品データリストを⾼高速に返す
l 属性補完:データ中の無い属性値を補完する
l これらの商品を買った⼈人にはこの商品がお薦め
l レコメンドに必要な情報を抽出し、データ⾃自体は共有せずに、
全データをレコメンドできるようにする
l 並列列分散、ストリーム化はチャレンジングなタスク
l 有⼒力力技術:
l anchor graph [Liu+ ICML 11]
l b-bit minwise hashing [Li+ WWW 10] [Li+ NIPS 11]
l coresets [Feldman+ NIPS 11]
15
- 16.
機械学習の例例(3/3)
マイニング、統計
l 統計分析
l max, min, avg, stddev, n次モーメント、エントロピー
l 相関があるかを分析する
l 外れ値を分析
l 盛り上がり検出
l 隠れた構造分析
l Hidden Markov Model
l Latent Dirichlet Allocation
l ⾏行行列列分解
16
- 17.
統⼀一的な計算モデル案
l 3つの操作だけを定義して様々な機械学習を実現したい
l Update, Analyze, Mix
l Update, Analyzeはローカルな操作、Mixはサーバー間の操作
l Update (例例:Train, Register)
l ⼊入⼒力力と現在のモデルを受け取り、モデルを更更新
l Analyze (例例:Classify, 近傍探索索、属性補完)
l ⼊入⼒力力と現在のモデルを受け取り、出⼒力力を返す
l Mix
l 複数のモデルをうけとり、新しくモデルを返す
l 交換可能なオペレーター
17
- 18.
統⼀一的な計算フレームワーク(続)
l モデル情報はKVSで表現できそう
l map<string, T>
l データ移動については記述しない
l Mix操作を利利⽤用してどのようにデータ交換するかはJubatusが管理理
l c.f. MapReduceの場合も、Shuffle操作のみ定義
l 容易易に冗⻑⾧長化、スケールアウトについてはJubatusが担当
l 分類、レコメンド多くの統計処理理はこの枠組で実現できそう
18
- 19.
ロードマップ
l 2012/1 機能を拡充
l レコメンド
l 回帰
l 統計
l 2012/4 Jubatusフレームワーク化
l 各種操作の抽象化⽬目標
l ストリーム化
l 予定が確定次第、連絡します
19
- 20.
- 21.










![機械学習の例例(2/3)
レコメンド
l 近傍探索索:クエリデータと似た登録データを返す
l この商品データと良良く似た商品データリストを⾼高速に返す
l 属性補完:データ中の無い属性値を補完する
l これらの商品を買った⼈人にはこの商品がお薦め
l レコメンドに必要な情報を抽出し、データ⾃自体は共有せずに、
全データをレコメンドできるようにする
l 並列列分散、ストリーム化はチャレンジングなタスク
l 有⼒力力技術:
l anchor graph [Liu+ ICML 11]
l b-bit minwise hashing [Li+ WWW 10] [Li+ NIPS 11]
l coresets [Feldman+ NIPS 11]
15](https://image.slidesharecdn.com/okanoharaserious-111108010816-phpapp02/85/Overview-and-Roadmap-15-320.jpg)





