長岡技術科学大学
2015年度先端GPGPUシミュレーション工学特論(全15回,大学院生対象講義)
第9回偏微分方程式の差分計算�(移流方程式)
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
・第1回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180326
・第2回 GPUによる並列計算の概念とメモリアクセス
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59180382
・第3回 GPUプログラム構造の詳細(threadとwarp)
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59180483
・第4回 GPUのメモリ階層の詳細(共有メモリ)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59180572
・第5回 GPUのメモリ階層の詳細(様々なメモリの利用)
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59180652
・第6回 プログラムの性能評価指針(Flop/Byte,計算律速,メモリ律速)
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59180736
・第7回 総和計算(Atomic演算)
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59180844
・第8回 偏微分方程式の差分計算(拡散方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59180918
・第9回 偏微分方程式の差分計算(移流方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59180982
・第10回 Poisson方程式の求解(線形連立一次方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59181031
・第11回 数値流体力学への応用(支配方程式,CPUプログラム)
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59181134
・第12回 数値流体力学への応用(GPUへの移植)
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59181230
・第13回 数値流体力学への応用(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59181316
・第14回 複数GPUの利用
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59181367
・第15回 CPUとGPUの協調
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59181450
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3










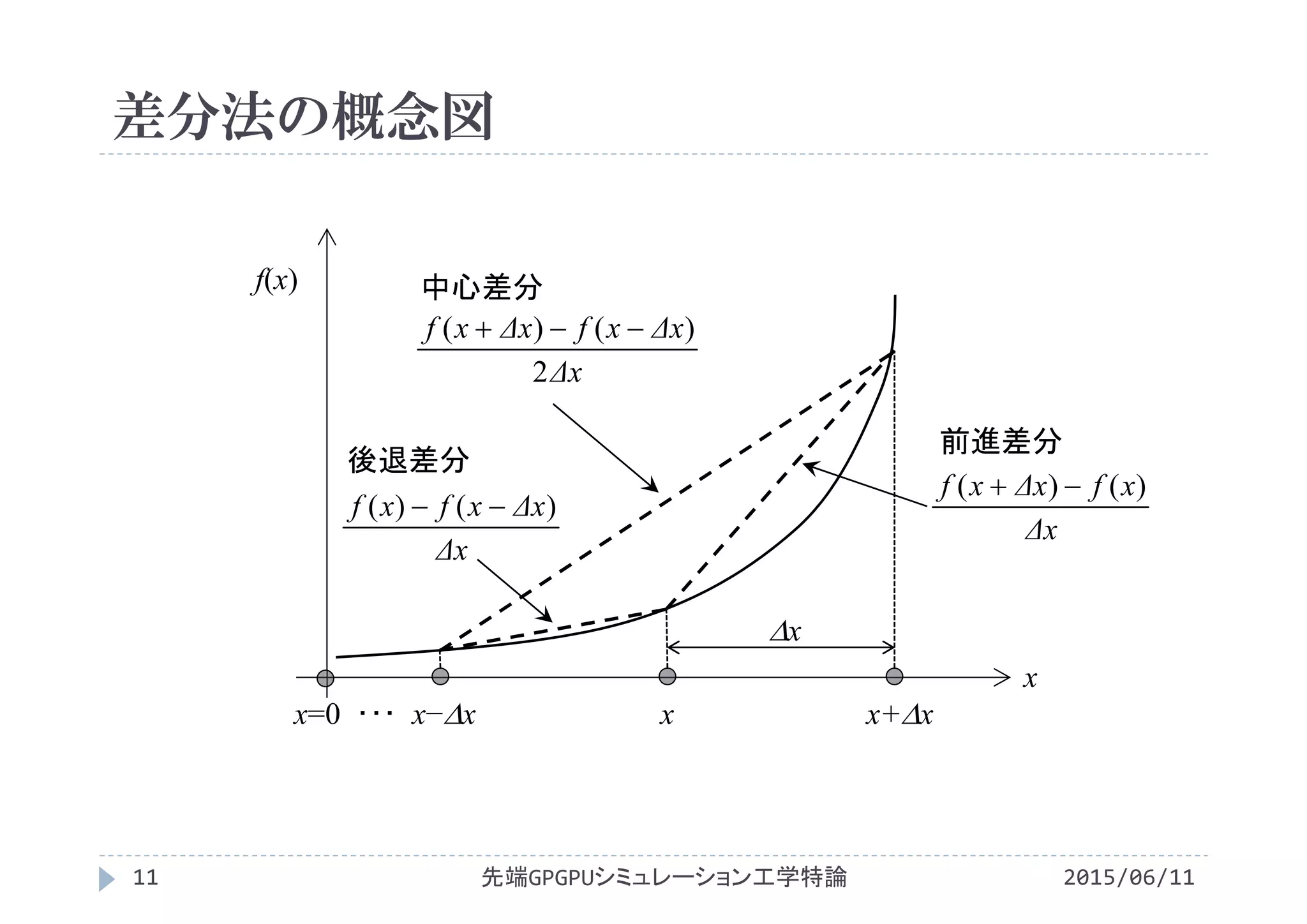
![差分法の概念図
2015/06/11先端GPGPUシミュレーション工学特論12
f(x)
x
i=0 ・・・ i−1 i i+1
x=0 ・・・ (i−1)x ix (i+1)x
x
サンプリングされた関数値
を配列f[]で保持](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-12-2048.jpg)
![差分法の概念図
2015/06/11先端GPGPUシミュレーション工学特論13
f[i]
i
i=0 ・・・ i−1 i i+1
dx
サンプリングされた関数値
を配列f[]で保持
f[i]
f[i‐1]
f[i+1]
中心差分
(f[i+1]‐f[i‐1])/(2*dx)](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-13-2048.jpg)
![差分法の実装
1階微分の中心差分近似
dfdx[i]
f[i]
+ + + + + +
2015/06/11先端GPGPUシミュレーション工学特論14
Δx
ff
Δx
ΔxxfΔxxf
dx
df ii
x 22
)()( 11
Δx2
1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-14-2048.jpg)
![差分法の実装
計算領域内部
dfdx[i]=(f[i+1]‐f[i‐1])/(2.0*dx);
dfdx[i]
f[i]
+ + + +
2015/06/11先端GPGPUシミュレーション工学特論15
Δx2
1
×−1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-15-2048.jpg)
![差分法の実装
境界条件(関数値が無いため処理を変更)
dfdx[0 ]=(‐3*f[0 ]+4*f[0+1]‐f[0+2])/(2*dx);
dfdx[N‐1]=( 3*f[N‐1]‐4*f[N‐2]+f[N‐3])/(2*dx);
2階微分値が一定と仮定して関数を補外した事に相当
dfdx[i]
f[i]
+
2015/06/11先端GPGPUシミュレーション工学特論16
Δx2
1
×−3 ×4 ×−1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-16-2048.jpg)
![差分法の実装
境界条件(関数値が無いため処理を変更)
dfdx[0 ]=(‐3*f[0 ]+4*f[0+1]‐f[0+2])/(2*dx);
dfdx[N‐1]=( 3*f[N‐1]‐4*f[N‐2]+f[N‐3])/(2*dx);
2階微分値が一定と仮定して関数を補外した事に相当
dfdx[i]
f[i]
+
2015/06/11先端GPGPUシミュレーション工学特論17
Δx2
1
×−4 ×3](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-17-2048.jpg)
![差分法の実装
境界条件(境界で微分値が0と規定)
dfdx[0 ]=0.0;
dfdx[N‐1]=0.0;
そのまま値を代入すればよい
0.0 0.0dfdx[i]
f[i]
+
2015/06/11先端GPGPUシミュレーション工学特論18
Δx2
1
×−4 ×3
+
Δx2
1
×−3 ×4 ×−1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-18-2048.jpg)
![#include<stdlib.h>
#include<math.h>/*‐lmオプションが必要*/
#define Lx (2.0*M_PI)
#define Nx (256)
#define dx (Lx/(Nx‐1))
#define Nbytes (Nx*sizeof(double))
void init(double *f){
int i;
for(i=0; i<Nx; i++){
f[i] = sin(i*dx);
}
}
void differentiate(double *f,
double *dfdx){
int i;
dfdx[0] = (‐3*f[0]
+4*f[1]
‐ f[2])/(2*dx);
for(i=1; i<Nx‐1; i++)
dfdx[i] = ( f[i+1]
‐f[i‐1])/(2*dx);
dfdx[Nx‐1]=( f[Nx‐3]
‐4*f[Nx‐2]
+3*f[Nx‐1])/(2*dx);
}
int main(void){
double *f,*dfdx;
f = (double *)malloc(Nbytes);
dfdx = (double *)malloc(Nbytes);
init(f);
differentiate(f,dfdx);
return 0;
}
CPUプログラム
2015/06/11先端GPGPUシミュレーション工学特論19
differentiate.c](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-19-2048.jpg)


![GPUへの移植
計算領域内部を計算するスレッド
dfdx[i]=(f[i+1]‐f[i‐1])/(2.0*dx);
境界を計算するスレッド
dfdx[0 ]=(‐3*f[0 ]+4*f[0+1]‐f[0+2])/(2*dx);
dfdx[N‐1]=( 3*f[N‐1]‐4*f[N‐2]+f[N‐3])/(2*dx);
dfdx[i]
f[i]
+ + + + + +
2015/06/11先端GPGPUシミュレーション工学特論22
Δx2
1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-22-2048.jpg)
![#include<stdlib.h>
#include<math.h>/*‐lmオプションが必要*/
#define Lx (2.0*M_PI)
#define Nx (1024*1024)
#define dx (Lx/(Nx‐1))
#define Nbytes (Nx*sizeof(double))
#define NT (256)
#define NB (Nx/NT)
void init(double *f){
int i;
for(i=0; i<Nx; i++){
f[i] = sin(i*dx);
}
}
__global__ void differentiate
(double *f, double *dfdx){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
if(i==0)
dfdx[i]=(‐3.0*f[i ]
+4.0*f[i+1]
‐ f[i+2])/(2.0*dx);
if(0<i && i<Nx‐1)
dfdx[i] = ( f[i+1]
‐f[i‐1])/(2.0*dx);
if(i==Nx‐1)
dfdx[i]=( f[i‐2]
‐4.0*f[i‐1]
+3.0*f[i ])/(2.0*dx);
}
GPUプログラム
2015/06/11先端GPGPUシミュレーション工学特論23
differentiate.cu
2階微分からの変更箇所](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-23-2048.jpg)

![共有メモリの典型的な使い方
2015/06/11先端GPGPUシミュレーション工学特論25
差分法
あるスレッドが中心差分を計算するために配列の要素i‐1,
i, i+1を参照
配列要素は複数回参照される
Fermi世代以降はキャッシュが利用可能
1 1 2 2 1 1
dfdx[i]
f[i]
+ + + +
Δx2
1
参照される回数](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-25-2048.jpg)
![共有メモリの典型的な使い方
境界で異なる処理を行うためにif分岐が必要
キャッシュを搭載していてもグローバルメモリへのアクセス
を伴うif分岐は高負荷
データの再利用とif文の排除に共有メモリを利用
2 2 3 3 2 2
dfdx[i]
f[i]
+ + + + + +
2015/06/11先端GPGPUシミュレーション工学特論26
Δx2
1
参照される回数](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-26-2048.jpg)
![共有メモリによる明示的なキャッシュ
2015/06/11先端GPGPUシミュレーション工学特論27
グローバルメモリから共有メモリにデータをキャッシュ
共有メモリ上で境界条件を処理
中心差分の計算からifを排除
dfdx[i]
f[i]
共有メモリ
blockIdx.x=0 blockIdx.x=1
計算のために必要になる余分な領域(袖領域)](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-27-2048.jpg)
![共有メモリによる明示的なキャッシュ
2015/06/11先端GPGPUシミュレーション工学特論28
グローバルメモリから共有メモリにデータをキャッシュ
共有メモリ上で境界条件を処理
中心差分の計算からifを排除
dfdx[i]
f[i]
共有メモリ
blockIdx.x=0 blockIdx.x=1
何らかの方法で
境界条件を反映
何らかの方法で
境界条件を反映](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-28-2048.jpg)
![共有メモリによる明示的なキャッシュ
2015/06/11先端GPGPUシミュレーション工学特論29
グローバルメモリから共有メモリにデータをキャッシュ
共有メモリ上で境界条件を処理
中心差分の計算からifを排除
dfdx[i]
f[i]
共有メモリ
++ + + + +
blockIdx.x=0 blockIdx.x=1
全スレッドが同じ式
で中心差分を計算](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-29-2048.jpg)
![__global__ void differentiate(double *f, double *dfdx){
int i = blockIdx.x*blockDim.x + threadIdx.x;
__shared__ double sf[1+NT+1];
int tx = threadIdx.x+1;
sf[tx] = f[i];
__syncthreads();
if(blockIdx.x> 0 && threadIdx.x==0 ) sf[tx‐1] = f[i‐1];
if(blockIdx.x< gridDim.x‐1 && threadIdx.x==blockDim.x‐1) sf[tx+1] = f[i+1];
if(blockIdx.x==0 && threadIdx.x==0 )
sf[tx‐1] = 3.0*sf[tx]‐3.0*sf[tx+1]+sf[tx+2];
//sf[tx‐1] = sf[tx+1];
if(blockIdx.x==gridDim.x‐1 && threadIdx.x==blockDim.x‐1)
sf[tx+1] = 3.0*sf[tx]‐3.0*sf[tx‐1]+sf[tx‐2];
//sf[tx+1] = sf[tx‐1];
__syncthreads();
dfdx[i] = ( sf[tx+1]‐sf[tx‐1])/(2.0*dx);
}
共有メモリを用いた書き換え
2015/06/11先端GPGPUシミュレーション工学特論30
differentiate_shared.cu](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-30-2048.jpg)
![共有メモリの宣言と代入
int i = blockIdx.x*blockDim.x + threadIdx.x;
__shared__ double sf[1+NT+1]; //右と左の袖領域を追加して宣言
int tx = threadIdx.x+1;
sf[tx] = f[i];
__syncthreads();
2015/06/11先端GPGPUシミュレーション工学特論31
f[i]
sf[NT+2]
i= 0 1 2 3 4 5
threadIdx.x= 0 1 2 0 1 2
tx= 0 1 2 3 4 0 1 2 3 4
NT=3NT=3
f[0] f[1] f[2] f[3] f[4] f[5]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-31-2048.jpg)
![袖領域の処理
if(blockIdx.x> 0 && threadIdx.x==0 ) sf[tx‐1] = f[i‐1];
if(blockIdx.x< gridDim.x‐1 && threadIdx.x==blockDim.x‐1) sf[tx+1] = f[i+1];
2015/06/11先端GPGPUシミュレーション工学特論32
f[i]
sf[NT+2]
i= 0 1 2 3 4 5
0 1 2=threadIdx.x
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[4] f[5]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-32-2048.jpg)
![袖領域の処理
if(blockIdx.x> 0 && threadIdx.x==0 ) sf[tx‐1] = f[i‐1];
if(blockIdx.x< gridDim.x‐1 && threadIdx.x==blockDim.x‐1) sf[tx+1] = f[i+1];
2015/06/11先端GPGPUシミュレーション工学特論33
f[i]
sf[NT+2]
i= 0 1 2 3 4 5
0=threadIdx.x
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[2] f[3] f[4] f[5]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-33-2048.jpg)
![袖領域の処理
if(blockIdx.x> 0 && threadIdx.x==0 ) sf[tx‐1] = f[i‐1];
if(blockIdx.x< gridDim.x‐1 && threadIdx.x==blockDim.x‐1) sf[tx+1] = f[i+1];
2015/06/11先端GPGPUシミュレーション工学特論34
f[i]
sf[NT+2]
i= 0 1 2 3 4 5
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[2] f[3] f[4] f[5]
threadIdx.x= 0 1 2](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-34-2048.jpg)
![袖領域の処理
if(blockIdx.x> 0 && threadIdx.x==0 ) sf[tx‐1] = f[i‐1];
if(blockIdx.x< gridDim.x‐1 && threadIdx.x==blockDim.x‐1) sf[tx+1] = f[i+1];
2015/06/11先端GPGPUシミュレーション工学特論35
f[i]
sf[NT+2]
i= 0 1 2 3 4 5
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[2] f[3] f[4] f[5]
threadIdx.x=2](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-35-2048.jpg)
![境界条件の処理(差分式で計算)
if(blockIdx.x==0 && threadIdx.x==0 )
sf[tx‐1] = 3.0*sf[tx]‐3.0*sf[tx+1]+sf[tx+2];
if(blockIdx.x==gridDim.x‐1 && threadIdx.x==blockDim.x‐1)
sf[tx+1] = 3.0*sf[tx]‐3.0*sf[tx‐1]+sf[tx‐2];
2015/06/11先端GPGPUシミュレーション工学特論36
sf[NT+2]
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[2] f[3] f[4] f[5]
2101 33 ffff
Δx
ff
Δx
fff
dx
df
i 22
43 11210
0
境界での差分式と中心差分式が一致するようにf−1を決定
f[‐1]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-36-2048.jpg)
![境界条件の処理(差分式で計算)
if(blockIdx.x==0 && threadIdx.x==0 )
sf[tx‐1] = 3.0*sf[tx]‐3.0*sf[tx+1]+sf[tx+2];
if(blockIdx.x==gridDim.x‐1 && threadIdx.x==blockDim.x‐1)
sf[tx+1] = 3.0*sf[tx]‐3.0*sf[tx‐1]+sf[tx‐2];
2015/06/11先端GPGPUシミュレーション工学特論37
sf[NT+2]
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[2] f[3] f[4] f[5]
321 33 NNNN ffff
Δx
ff
Δx
fff
dx
df NNNNN
Ni 22
43 2321
1
境界での差分式と中心差分式が一致するようにfNを決定
f[‐1] f[6]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-37-2048.jpg)
![境界条件の処理(勾配が0)
if(blockIdx.x==0 && threadIdx.x==0 )sf[tx‐1] = sf[tx+1];
if(blockIdx.x==gridDim.x‐1 && threadIdx.x==blockDim.x‐1)sf[tx+1] = sf[tx‐1];
2015/06/11先端GPGPUシミュレーション工学特論38
sf[NT+2]
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[2] f[3] f[4] f[5]
11 ff
0
2
11
0
Δx
ff
dx
df
i
境界での中心差分式が0となるようにf−1を決定
f[‐1]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-38-2048.jpg)
![境界条件の処理(勾配が0)
if(blockIdx.x==0 && threadIdx.x==0 )sf[tx‐1] = sf[tx+1];
if(blockIdx.x==gridDim.x‐1 && threadIdx.x==blockDim.x‐1)sf[tx+1] = sf[tx‐1];
2015/06/11先端GPGPUシミュレーション工学特論39
sf[NT+2]
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[2] f[3] f[4] f[5]
2 NN ff
0
2
2
1
Δx
ff
dx
df NN
Ni
境界での中心差分式が0となるようにfNを決定
f[‐1] f[6]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-39-2048.jpg)
![中心差分の計算
__syncthreads();
dfdx[i] = ( sf[tx+1]‐sf[tx‐1])/(2.0*dx);
2015/06/11先端GPGPUシミュレーション工学特論40
sf[NT+2]
tx= 0 1 2 3 4 0 1 2 3 4
blockIdx.x=0 blockIdx.x=1
f[0] f[1] f[2] f[3] f[2] f[3] f[4] f[5]
dfdx[i]
++ + + + + 全スレッドが同じ式
で中心差分を計算Δx2
1
f[‐1] f[6]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-40-2048.jpg)









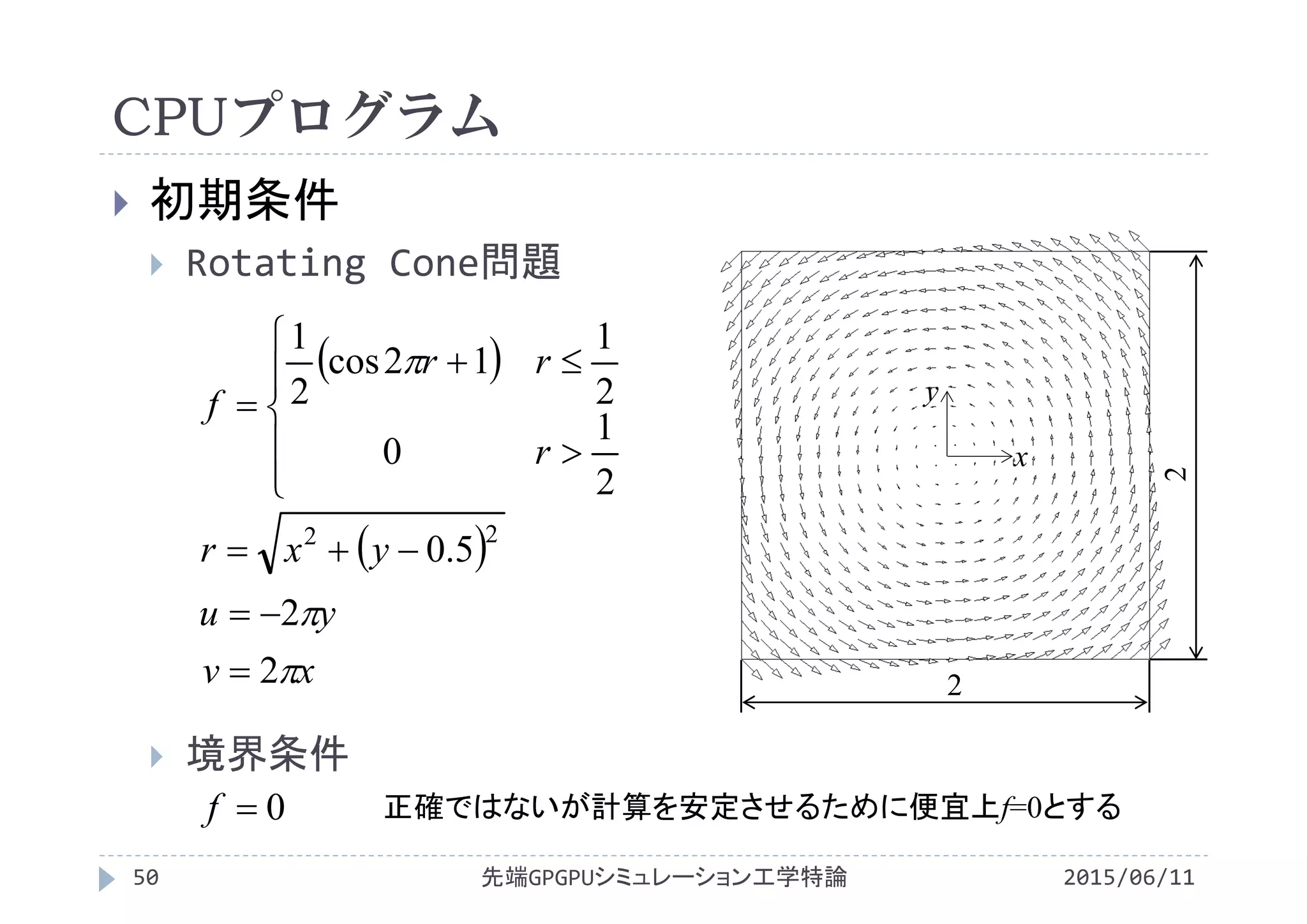

![void init(double *f,double *d_f_dx,double *d_f_dy,
double *u, double *v){
int i,j;
double x,y,r;
for(i=0;i<Nx;i++){
for(j=0;j<Ny;j++){
x = (double)i*dx ‐ 1.0;
y = (double)j*dy ‐ 1.0;
r = sqrt(x*x + (y‐0.5)*(y‐0.5));
f[i+Nx*j] = 0.0;
if(r<0.5)
f[i+Nx*j] = 0.5*(cos(2.0*M_PI*r)+1.0);
d_f_dx[i+Nx*j] = 0.0;
d_f_dy[i+Nx*j] = 0.0;
u[i+Nx*j] = ‐(2.0*M_PI*y);
v[i+Nx*j] = (2.0*M_PI*x);
}
}
}
void differentiate(double *f,double *d_f_dx,
double *d_f_dy){
int i,j;
for(i=1;i<Nx‐1;i++){
for(j=1;j<Ny‐1;j++){
d_f_dx[i+Nx*j]
= (f[(i+1)+Nx*j]‐f[(i‐1)+Nx*j])/(2.0*dx);
}
}
for(i=1;i<Nx‐1;i++){
for(j=1;j<Ny‐1;j++){
d_f_dy[i+Nx*j]
= (f[i+Nx*(j+1)]‐f[i+Nx*(j‐1)])/(2.0*dy);
}
}
}
CPUプログラム
2015/06/11先端GPGPUシミュレーション工学特論52
rotating_cone.c](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-52-2048.jpg)
![void integrate(double *f,double *d_f_dx,
double *d_f_dy, double *u, double *v,double *fnew){
int i,j;
for(i=0;i<Nx;i++){
for(j=0;j<Ny;j++){
fnew[i+Nx*j] = f[i+Nx*j]
‐ dt*( u[i+Nx*j]*d_f_dx[i+Nx*j]
+ v[i+Nx*j]*d_f_dy[i+Nx*j]);
}
}
}
void update(double *f,double *fnew){
int i,j;
for(i=0;i<Nx;i++){
for(j=0;j<Ny;j++){
f[i+Nx*j] = fnew[i+Nx*j];
}
}
}
CPUプログラム
2015/06/11先端GPGPUシミュレーション工学特論53
rotating_cone.c](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-53-2048.jpg)
![CPUプログラム
差分計算
x方向,y方向偏微分を個別に計算
先端GPGPUシミュレーション工学特論54 2015/06/11
void differentiate(double *f, double *d_f_dx, double *d_f_dy){
int i,j;
for(i=1;i<Nx‐1;i++){
for(j=1;j<Ny‐1;j++){
d_f_dx[i+Nx*j] = (f[(i+1)+Nx*j]‐f[(i‐1)+Nx*j])/(2.0*dx);
}
}
for(i=1;i<Nx‐1;i++){
for(j=1;j<Ny‐1;j++){
d_f_dy[i+Nx*j] = (f[i+Nx*(j+1)]‐f[i+Nx*(j‐1)])/(2.0*dy);
}
}
}](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-54-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのx方向差分を計算するためにx(i)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論55 2015/06/11
f[] d_f_dx[]
i−1 i i+1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-55-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのx方向差分を計算するためにx(i)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論56 2015/06/11
f[] d_f_dx[]
i−1 i i+1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-56-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのx方向差分を計算するためにx(i)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論57 2015/06/11
f[] d_f_dx[]
i−1 i i+1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-57-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのy方向差分を計算するためにy(j)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論58 2015/06/11
j−1jj+1
f[] d_f_dy[]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-58-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのy方向差分を計算するためにy(j)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論59 2015/06/11
f[] d_f_dy[]
j−1jj+1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-59-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのy方向差分を計算するためにy(j)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論60 2015/06/11
f[] d_f_dy[]
j−1jj+1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-60-2048.jpg)
![差分計算のメモリ参照
ある1点i,jのy方向差分を計算するためにy(j)方
向に2点のfを参照
先端GPGPUシミュレーション工学特論61 2015/06/11
f[] d_f_dy[]
j−1jj+1](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-61-2048.jpg)

![CPUプログラム
fの積分
先端GPGPUシミュレーション工学特論63 2015/06/11
Δy
ff
v
Δx
ff
uΔtff
n
ji
n
jin
ji
n
ji
n
jin
ji
n
ji
n
ji
22
1,1,
,
,1,1
,,
1
,
void integrate(double *f,double *d_f_dx,double *d_f_dy,
double *u, double *v,double *f_new){
int i,j,ij;
for(i=0;i<Nx;i++){
for(j=0;j<Ny;j++){
ij = i+Nx*j;
f_new[ij]=f[ij] ‐ dt*(u[ij]*d_f_dx[ij]+v[ij]*d_f_dy[ij]);
}
}
}](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-63-2048.jpg)
![CPUプログラム
fの更新
fnからfn+1を計算
fn+1からfn+2を計算
今の時刻から次の時刻を求める
求められた次の時刻を今の時刻と見なし,次の時刻を求める
先端GPGPUシミュレーション工学特論64 2015/06/11
同じアルゴリズム
void update(double *f,double *f_new){
int i,j,ij;
for(i=0;i<Nx;i++){
for(j=0;j<Ny;j++){
ij = i+Nx*j;
f[ij] = f_new[ij];
}
}
}](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-64-2048.jpg)


![#define THREADX 16
#define THREADY 16
#define BLOCKX (Nx/THREADX)
#define BLOCKY (Ny/THREADY)
__global__ void init(double *f,double *d_f_dx,
double *d_f_dy, double *u, double *v){
int i,j,ij;
double x,y,r;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
x = (double)i*dx ‐ 1.0;
y = (double)j*dy ‐ 1.0;
r = sqrt(x*x + (y‐0.5)*(y‐0.5));
f[ij] = 0.0;
if(r<0.5) f[ij] = 0.5*(cos(2.0*M_PI*r)+1.0);
d_f_dx[ij] = 0.0;
d_f_dy[ij] = 0.0;
u[ij] = ‐(2.0*M_PI*y);
v[ij] = (2.0*M_PI*x);
}
__global__ void differentiate(double *f,
double *d_f_dx,double *d_f_dy){
int i,j,ij,ip1,im1,jp1,jm1;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
if( (0<i && i<Nx‐1) && (0<j && j<Ny‐1) ){
ij = i +Nx* j;
ip1 = (i+1)+Nx* j;
im1 = (i‐1)+Nx* j;
jp1 = i +Nx*(j+1);
jm1 = i +Nx*(j‐1);
d_f_dx[ij] = (f[ip1]‐f[im1])/(2.0*dx);
d_f_dy[ij] = (f[jp1]‐f[jm1])/(2.0*dy);
}
}
GPUプログラム(1スレッドが1点を計算)
2015/06/11先端GPGPUシミュレーション工学特論67
conv1.cu](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-67-2048.jpg)
![__global__ void integrate(double *f,double *d_f_dx,
double *d_f_dy, double *u, double *v,double *fnew){
int i,j,ij;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
fnew[ij] = f[ij] ‐ dt*
(u[ij]*d_f_dx[ij] + v[ij]*d_f_dy[ij]);
}
__global__ void update(double *f, double *fnew){
int i,j,ij;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
f[ij] = fnew[ij];
}
GPUプログラム(1スレッドが1点を計算)
2015/06/11先端GPGPUシミュレーション工学特論68
conv1.cu](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-68-2048.jpg)



![gnuplotによる結果の表示
2015/06/11先端GPGPUシミュレーション工学特論72
スクリプトanim.gplの内容
set xrange [‐1:1] x軸の表示範囲を‐1~1に固定
set yrange [‐1:1] y軸の表示範囲を‐1~1に固定
set zrange [‐0.2:1.2] z軸の表示範囲を‐0.2~1.2に固定
set ticslevel 0 xy平面とz軸の最小値表示位置の差
set hidden3d 隠線消去をする
set view 45,30 視点をx方向45°,y方向30°に設定
set size 1,0.75 グラフの縦横比を1:0.75
unset contour 2次元等高線は表示しない
set surface 3次元で等値面を表示
unset pm3d カラー表示はしない
以下でファイルを読み込み,3次元表示
splot 'f0.00.txt' using 1:2:3 with line title "t=0.00s"
...
splot 'f1.00.txt' using 1:2:3 with line title "t=1.00s"](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-72-2048.jpg)
![gnuplotによる結果の表示
2015/06/11先端GPGPUシミュレーション工学特論74
スクリプトanim_color.gplの内容
set xrange [‐1:1] x軸の表示範囲を‐1~1に固定
set yrange [‐1:1] y軸の表示範囲を‐1~1に固定
set zrange [‐0.2:1.2] z軸の表示範囲を‐0.2~1.2に固定
set ticslevel 0 xy平面とz軸の最小値表示位置の差
set hidden3d 隠線消去をする
set view 45,30 視点をx方向45°,y方向30°に設定
set size 1,0.75 グラフの縦横比を1:0.75
unset contour 2次元等高線は表示しない
set surface 3次元で等値面を表示
set pm3d カラー表示する
以下でファイルを読み込み,3次元表示
splot 'f0.00.txt' using 1:2:3 with line title "t=0.00s"
...
splot 'f1.00.txt' using 1:2:3 with line title "t=1.00s"](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-74-2048.jpg)

![gnuplotによる結果の表示
2015/06/11先端GPGPUシミュレーション工学特論76
スクリプトanim_2d.gplの内容
set xrange [‐1:1] x軸の表示範囲を‐1~1に固定
set yrange [‐1:1] y軸の表示範囲を‐1~1に固定
set zrange [‐0.2:1.2] z軸の表示範囲を‐0.2~1.2に固定
set view 0,0 真上から見下ろす
set size 1,1 グラフの縦横比を1:1
set contour 2次元等高線を表示
unset surface 3次元で等値面を表示しない
unset pm3d カラー表示しない
set cntrparam levels incremental 0,0.1,1
等高線を0から1まで0.1刻みに設定
以下でファイルを読み込み,3次元表示
splot 'f0.00.txt' using 1:2:3 with line title "t=0.00s"
...
splot 'f1.00.txt' using 1:2:3 with line title "t=1.00s"](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-76-2048.jpg)

![int a,b;
int *ptr[2];
int curr, next;
curr = 0; next = 1;
ptr[curr]=&a;
prt[next]=&b;
アドレスを格納する配列を用いる方法
2015/06/11先端GPGPUシミュレーション工学特論79
時刻n,時刻n+1の変数を用意せず,ポインタ変数を
取り扱う配列を利用
時刻n用とするか時刻n+1用途するかを配列添字で区別
int型変数curr(currentの略), nextを利用
配列添字にcurrを用いると時刻n用
配列添字にnextを用いると時刻n+1用
a
1
2
b
ptr[curr]
aのア
ドレス
bのア
ドレス
ptr[next]
結合
ポインタ変数が矢印先端
の変数のアドレスを保持
しており,間接参照演算
子*を利用してその変数
の値にアクセスできる
値
アド
レス
変数
ポインタ
変数](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-79-2048.jpg)
![‐‐‐
ptr[curr]はaのアドレスを参照
ptr[next]はbのアドレスを参照
‐‐‐
curr=next; //currは1
next=1‐curr; //nextは1‐1=0
ptr[curr]はbのアドレスを参照
ptr[next]はaのアドレスを参照
‐‐‐
curr=next; //currは0
next=1‐curr; //nextは1‐0=1
アドレスを格納する配列を用いる方法
2015/06/11先端GPGPUシミュレーション工学特論80
以下の2式で配列添字curr, nextの値を切替
curr = next;
next = 1‐curr;
a
1
2
b
ptr[next(=0)]aのア
ドレス
bのア
ドレス
ptr[curr(=1)]](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-80-2048.jpg)
![アドレスを格納する配列を用いる方法
2015/06/11先端GPGPUシミュレーション工学特論81
無駄がない
時刻n+1の値をnとすることを表現(curr=next)
double *f[2];
int curr=0,next=1;
f[curr(=0)] = (double *)malloc(...);
f[next(=1)] = (double *)malloc(...);
differentiate(f[curr(=0)]);
integrate(f[curr(=0)],f[next(=1)]);
//添字を変更
curr = next;
next = 1‐curr;
//時刻nと時刻n+1を交換して関数を実行
differentiate(f[curr(=1)]);
integrate(f[curr(=1)],f[next(=0)]);](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-81-2048.jpg)
![アドレスを格納する配列を用いる方法
2015/06/11先端GPGPUシミュレーション工学特論82
関数integrateの実行
実行後,時刻nの値は不要
f[0]
時刻n
f[1]
時刻n+1
integrate(f[curr(=0)],...,f[next(=1)]);](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-82-2048.jpg)
![アドレスを格納する配列を用いる方法
2015/06/11先端GPGPUシミュレーション工学特論83
関数integrateの実行
実行後,時刻nの値は不要
f[0]
時刻n+1
f[1]
時刻n
integrate(f[curr(=1)],...,f[next(=0)]);](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-83-2048.jpg)
![#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#define Lx 2.0
#define Ly Lx
#define Nx 64
#define Ny Nx
#define dx (Lx/(Nx‐1))
#define dy dx
#define Nbytes (Nx*Ny*sizeof(double))
#define CFL 0.01
#define CONV (2.0*M_PI)
#define Lt 1.0
#define dt (CFL*dx/CONV)
#define Nt ((int)(Lt/(dt)))
#include "conv1.cu"
int main(void){
double *dev_d_f_dx, *dev_d_f_dy;
double *dev_u,*dev_v;
dim3 Thread, Block;
int n;
double *dev_f[2];
int curr=0,next=1;
cudaMalloc( (void **)&dev_d_f_dx, Nbytes );
cudaMalloc( (void **)&dev_d_f_dy, Nbytes );
cudaMalloc( (void **)&dev_u , Nbytes );
cudaMalloc( (void **)&dev_v , Nbytes );
cudaMalloc( (void **)&dev_f[curr], Nbytes );
cudaMalloc( (void **)&dev_f[next], Nbytes );
Thread = dim3(THREADX,THREADY,1);
Block = dim3(BLOCKX ,BLOCKY, 1);
init<<<Block, Thread>>>(dev_f[curr],
dev_d_f_dx,dev_d_f_dy,dev_u,dev_v);
GPUプログラム(CPU処理用共通部分)
2015/06/11先端GPGPUシミュレーション工学特論84
rotating_cone2.cu](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-84-2048.jpg)
![for(n=1;n<=Nt;n++){
printf("%d/%d¥n",n,Nt);
differentiate<<<Block,Thread>>>
(dev_f[curr],dev_d_f_dx,dev_d_f_dy);
integrate<<<Block,Thread>>>
(dev_f[curr],dev_d_f_dx,dev_d_f_dy,
dev_u, dev_v, dev_f[next]);
curr = next; next = 1‐curr;
}
cudaFree(dev_f[curr]);
cudaFree(dev_f[next]);
cudaFree(dev_d_f_dx);
cudaFree(dev_d_f_dy);
cudaFree(dev_u);
cudaFree(dev_v);
return 0;
}
GPUプログラム(CPU処理用共通部分)
2015/06/11先端GPGPUシミュレーション工学特論85
rotating_cone2.cu](https://image.slidesharecdn.com/advancedgpgpu09-160307060541/75/2015-GPGPU-9-85-2048.jpg)















![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)








![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)






























































