Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hidetoshi Matsui
PDF, PPTX
10,712 views
関数データ解析の概要とその方法
関数データ解析とはどういうものか、どのような場面で用いられるかについてまとめてみました。
Education
◦
Read more
16
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 156
2
/ 156
3
/ 156
4
/ 156
5
/ 156
6
/ 156
7
/ 156
8
/ 156
9
/ 156
10
/ 156
11
/ 156
Most read
12
/ 156
13
/ 156
14
/ 156
Most read
15
/ 156
16
/ 156
17
/ 156
18
/ 156
19
/ 156
20
/ 156
21
/ 156
22
/ 156
23
/ 156
24
/ 156
25
/ 156
Most read
26
/ 156
27
/ 156
28
/ 156
29
/ 156
30
/ 156
31
/ 156
32
/ 156
33
/ 156
34
/ 156
35
/ 156
36
/ 156
37
/ 156
38
/ 156
39
/ 156
40
/ 156
41
/ 156
42
/ 156
43
/ 156
44
/ 156
45
/ 156
46
/ 156
47
/ 156
48
/ 156
49
/ 156
50
/ 156
51
/ 156
52
/ 156
53
/ 156
54
/ 156
55
/ 156
56
/ 156
57
/ 156
58
/ 156
59
/ 156
60
/ 156
61
/ 156
62
/ 156
63
/ 156
64
/ 156
65
/ 156
66
/ 156
67
/ 156
68
/ 156
69
/ 156
70
/ 156
71
/ 156
72
/ 156
73
/ 156
74
/ 156
75
/ 156
76
/ 156
77
/ 156
78
/ 156
79
/ 156
80
/ 156
81
/ 156
82
/ 156
83
/ 156
84
/ 156
85
/ 156
86
/ 156
87
/ 156
88
/ 156
89
/ 156
90
/ 156
91
/ 156
92
/ 156
93
/ 156
94
/ 156
95
/ 156
96
/ 156
97
/ 156
98
/ 156
99
/ 156
100
/ 156
101
/ 156
102
/ 156
103
/ 156
104
/ 156
105
/ 156
106
/ 156
107
/ 156
108
/ 156
109
/ 156
110
/ 156
111
/ 156
112
/ 156
113
/ 156
114
/ 156
115
/ 156
116
/ 156
117
/ 156
118
/ 156
119
/ 156
120
/ 156
121
/ 156
122
/ 156
123
/ 156
124
/ 156
125
/ 156
126
/ 156
127
/ 156
128
/ 156
129
/ 156
130
/ 156
131
/ 156
132
/ 156
133
/ 156
134
/ 156
135
/ 156
136
/ 156
137
/ 156
138
/ 156
139
/ 156
140
/ 156
141
/ 156
142
/ 156
143
/ 156
144
/ 156
145
/ 156
146
/ 156
147
/ 156
148
/ 156
149
/ 156
150
/ 156
151
/ 156
152
/ 156
153
/ 156
154
/ 156
155
/ 156
156
/ 156
More Related Content
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
MIRU2016 チュートリアル
by
Shunsuke Ono
PDF
【博士論文発表会】パラメータ制約付き特異モデルの統計的学習理論
by
Naoki Hayashi
PDF
PRML Chapter 14
by
Masahito Ohue
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
変分ベイズ法の説明
by
Haruka Ozaki
機械学習のためのベイズ最適化入門
by
hoxo_m
MIRU2016 チュートリアル
by
Shunsuke Ono
【博士論文発表会】パラメータ制約付き特異モデルの統計的学習理論
by
Naoki Hayashi
PRML Chapter 14
by
Masahito Ohue
What's hot
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PPTX
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
PDF
最適輸送の解き方
by
joisino
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
因果推論の基礎
by
Hatsuru Morita
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
リプシッツ連続性に基づく勾配法・ニュートン型手法の計算量解析
by
京都大学大学院情報学研究科数理工学専攻
PDF
工学系大学4年生のための論文の読み方
by
ychtanaka
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
ベイズ統計学の概論的紹介
by
Naoki Hayashi
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
最適輸送の解き方
by
joisino
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
劣モジュラ最適化と機械学習1章
by
Hakky St
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
因果推論の基礎
by
Hatsuru Morita
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
EMアルゴリズム
by
Sotetsu KOYAMADA(小山田創哲)
生成モデルの Deep Learning
by
Seiya Tokui
ベイズファクターとモデル選択
by
kazutantan
機械学習モデルの判断根拠の説明
by
Satoshi Hara
リプシッツ連続性に基づく勾配法・ニュートン型手法の計算量解析
by
京都大学大学院情報学研究科数理工学専攻
工学系大学4年生のための論文の読み方
by
ychtanaka
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
Similar to 関数データ解析の概要とその方法
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
データ解析6 重回帰分析
by
Hirotaka Hachiya
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PDF
行列計算を利用したデータ解析技術
by
Yoshihiro Mizoguchi
PDF
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
PDF
Tokyo r12 - R言語による回帰分析入門
by
Yohei Sato
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
by
hirokazutanaka
PDF
PRML 5.2.1-5.3.3 ニューラルネットワークの学習 (誤差逆伝播) / Training Neural Networks (Backpropa...
by
Akihiro Nitta
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PPTX
第7回 KAIM 金沢人工知能勉強会 回帰分析と使う上での注意事項
by
tomitomi3 tomitomi3
PDF
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
PPTX
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
PDF
回帰
by
Shin Asakawa
PDF
C06
by
anonymousouj
PRML第6章「カーネル法」
by
Keisuke Sugawara
データ解析6 重回帰分析
by
Hirotaka Hachiya
W8PRML5.1-5.3
by
Masahito Ohue
行列計算を利用したデータ解析技術
by
Yoshihiro Mizoguchi
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
Tokyo r12 - R言語による回帰分析入門
by
Yohei Sato
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
by
hirokazutanaka
PRML 5.2.1-5.3.3 ニューラルネットワークの学習 (誤差逆伝播) / Training Neural Networks (Backpropa...
by
Akihiro Nitta
パターン認識02 k平均法ver2.0
by
sleipnir002
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PRML10-draft1002
by
Toshiyuki Shimono
第7回 KAIM 金沢人工知能勉強会 回帰分析と使う上での注意事項
by
tomitomi3 tomitomi3
TokyoWebmining統計学部 第1回
by
Issei Kurahashi
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
回帰
by
Shin Asakawa
C06
by
anonymousouj
関数データ解析の概要とその方法
1.
関数データ解析の概要とその方法 滋賀大学データサイエンス学系 松井 秀俊 Last update:
2020/09/18
2.
本資料について • 本資料は2020年度大阪大学集中講義「データ科学特論II」の講義資料を ベースに作成したものです • 関数データ解析とはどのようなものか,何ができるのか,そして どのようなデータに対してどのような目的で用いられるものなのかを, 具体的な手法や適用例を通して知ってもらうことを目的に 作成しています •
と言いつつ,本資料では関数データ解析を網羅できておらず 内容に偏りがあります. 本資料は「関数回帰分析」に重点を置いて構成されています • 理論的背景についてはあまり触れません 2
3.
目次 • 関数データ解析の概要 • 関数回帰分析 •
その他の関数データ解析手法と応用 3
4.
目次 • 関数データ解析の概要 ̶ 関数データ解析って何? ̶
データの関数化(基底関数展開・混合効果モデル) ̶ 関数データの要約統計量 ̶ 関数データならではの分析 • 関数回帰分析 • その他の関数データ解析手法と応用 4
5.
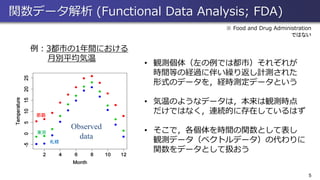
5 • 観測個体(左の例では都市)それぞれが 時間等の経過に伴い繰り返し計測された 形式のデータを,経時測定データという • 気温のようなデータは,本来は観測時点 だけではなく,連続的に存在しているはず •
そこで,各個体を時間の関数として表し 観測データ(ベクトルデータ)の代わりに 関数をデータとして扱おう Observed data 那覇 東京 札幌 例:3都市の1年間における 月別平均気温 関数データ解析 (Functional Data Analysis; FDA) ※ Food and Drug Administration ではない
6.
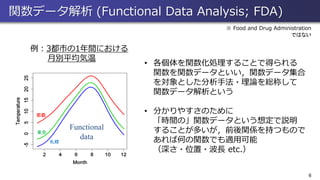
6 • 各個体を関数化処理することで得られる 関数を関数データといい,関数データ集合 を対象とした分析手法・理論を総称して 関数データ解析という • 分かりやすさのために 「時間の」関数データという想定で説明 することが多いが,前後関係を持つもので あれば何の関数でも適用可能 (深さ・位置・波長
etc.) Observed data 例:3都市の1年間における 月別平均気温 Functional data 那覇 東京 札幌 関数データ解析 (Functional Data Analysis; FDA) ※ Food and Drug Administration ではない
7.
経時測定データの例1 子供の身長の推移 • 数人の子供の身長を 1歳から18歳まで毎年計測したデータ • 計測時点数は1歳~2歳は年4回, 2~8歳までは年1回 ⇒計測時間が不均一 •
計測時間の情報を 取り入れた解析をするには? 7 年齢 子 供 “growth” by R package “fda”
8.
経時測定データの例1 子供の身長の推移 • 数人の子供の身長を 1歳から18歳まで毎年計測したデータ • 計測時点数は1歳~2歳は年4回, 2~8歳までは年1回 ⇒計測時間が不均一 •
計測時間の情報を 取り入れた解析をするには? 8 年齢 子 供 “growth” by R package “fda”
9.
経時測定データの例2 病状の経時変化 • ある細胞が破壊される病気の患者数名に対して 数回に渡り通院してもらい 細胞の血中濃度を測定 • 患者ごとに通院時点や通院回数が異なるため 古典的な多変量解析を直接適用することは困難 •
喫煙や性別などの情報と 細胞濃度との関係性を表すモデルは? 9 患者 時点 喫煙 性別 濃度 1 0 無 0 45 1 1 無 0 37 : : : : : 1 10 無 0 20 2 0 有 1 38 : : : : : 2 9 有 1 12 : : : : : n 13 無 0 12 “cd4” by R package “timereg”
10.
経時測定データの例2 病状の経時変化 • ある細胞が破壊される病気の患者数名に対して 数回に渡り通院してもらい 細胞の血中濃度を測定 • 患者ごとに通院時点や通院回数が異なるため 古典的な多変量解析を直接適用することは困難 •
喫煙や性別などの情報と 細胞濃度との関係性を表すモデルは? 10 患者 時点 喫煙 性別 濃度 1 0 無 0 45 1 1 無 0 37 : : : : : 1 10 無 0 20 2 0 有 1 38 : : : : : 2 9 有 1 12 : : : : : n 13 無 0 12 “cd4” by R package “timereg”
11.
経時測定データの例3 骨密度の推移データ • 48名の女性に対して脊柱の骨密度を 経時的に測定したデータ • 1人1人の計測時点数が2~4時点と 非常に少ないため,個々のデータを 独立して関数化することは困難 •
このような「まばら」なデータは スパース経時測定データとよばれる • 全員分のデータを時系列的に並べれば 全観測時点内でのトレンドは見える • 平均曲線をどのように推定する? 11 James et al. (2000, Biometrika)
12.
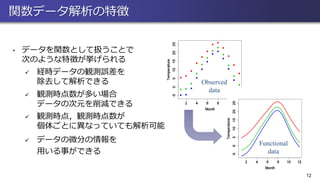
Observed data 12 Observed data • データを関数として扱うことで 次のような特徴が挙げられる ✓ 経時データの観測誤差を 除去して解析できる ✓
観測時点数が多い場合 データの次元を削減できる ✓ 観測時点,観測時点数が 個体ごとに異なっていても解析可能 ✓ データの微分の情報を 用いる事ができる Functional data 関数データ解析の特徴
13.
関数データ解析手法 • 関数データ解析では,古典的な統計手法を関数データの枠組みへ拡張した ものが多く研究されている • 関数の特性を利用した,関数データならではの分析手法もある 13 ✓
主成分分析 ✓ 回帰分析 ✓ 仮説検定 ✓ クラスター分析 ✓ 判別分析 ✓ 空間データ解析 ✓ 時系列解析 ✓ 曲線アライメント ✓ 主微分分析 ✓ 微分方程式モデル
14.
day 応用事例1:関数回帰分析 イネの収量データ • さまざまな地域の水田における単位面積あたり イネの収穫量と,イネの生育期間中における 気温との関係をモデル化 • 気温を関数データとして扱い回帰モデル構築 •
関数回帰モデルの係数関数から, 田植えから収穫までの気温の収量への寄与を 定量化 14 説明変数:気温の関数データ 目的変数:イネの収穫量 気温の係数関数推定値 (破線は95%各点信頼区間) (田植え) (収穫)
15.
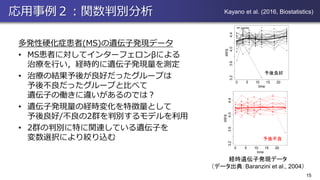
応用事例2:関数判別分析 多発性硬化症患者(MS)の遺伝子発現データ • MS患者に対してインターフェロンβによる 治療を行い,経時的に遺伝子発現量を測定 • 治療の結果予後が良好だったグループは 予後不良だったグループと比べて 遺伝子の働きに違いがあるのでは? •
遺伝子発現量の経時変化を特徴量として 予後良好/不良の2群を判別するモデルを利用 • 2群の判別に特に関連している遺伝子を 変数選択により絞り込む 15 0 5 10 15 20 3.23.64.04.4 time IRF8 0 5 10 15 20 3.23.64.04.4 time IRF8 p= 0.0059 経時遺伝子発現データ (データ出典:Baranzini et al., 2004) 予後良好 予後不良 Kayano et al. (2016, Biostatistics)
16.
応用事例3:関数クラスター分析 タンパク質立体構造データ • タンパク質はアミノ酸配列のペプチド結合に より直鎖状に繋がっており,右図のように タンパク質の種類に応じた立体構造をもつ • 1つのアミノ酸に1つだけ存在するα炭素原子 の3次元座標を結合順に計測することで, 右図下のようなデータが得られる •
タンパク質は生物学的観点からグループ分け されているが,そのグループを立体構造でも 分けられないか? • 端的に言うと「曲線の仲間分け」 16 Kayano et al. (2010, J. Classification) タンパク質立体構造と α炭素原子の座標の推移(XYZ座標)
17.
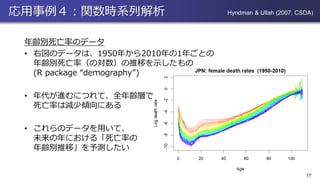
応用事例4:関数時系列解析 年齢別死亡率のデータ • 右図のデータは、1950年から2010年の1年ごとの 年齢別死亡率(の対数)の推移を示したもの (R package
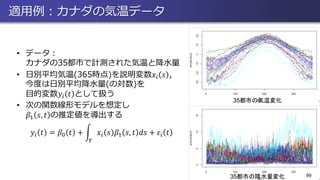
“demography”) • 年代が進むにつれて、全年齢層で 死亡率は減少傾向にある • これらのデータを用いて、 未来の年における「死亡率の 年齢別推移」を予測したい 17 Hyndman & Ullah (2007, CSDA)
18.
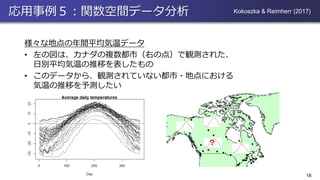
応用事例5:関数空間データ分析 様々な地点の年間平均気温データ • 左の図は、カナダの複数都市(右の点)で観測された、 日別平均気温の推移を表したもの • このデータから、観測されていない都市・地点における 気温の推移を予測したい 18 Kokoszka
& Reimherr (2017) ?
19.
Ramsay & Silverman (1997,
2005) 提唱者らによる書籍 実践的な方法論を 多く掲載 参考書など • 和文では次の書籍の一部に記述あり – 福水 (2010). カーネル法入門: 10.1節,朝倉書店. – 辻谷,竹澤 (2015). マシンラーニング 第2版 (Rで学ぶデータサイエンス): 3章,共立出版. • 関数データ解析のサーベイ論文 – 松井(2019) .関数データに基づく統計的モデリング,統計数理 67 (1) 73-96. 19 Kokoszka & Reimherr (2017) 関数データ解析の 基本的な方法を掲載 Rのコードあり Hsing & Eubank (2015) 関数データ解析に 関する理論的性質を 詳しく紹介 Ramsay, Hooker & Graves (2009) RやMatlabコード掲載 手を動かしながら 勉強できる Horvath & Kokoszka (2013) 関数データの検定や 時系列・空間データ 等の分析法を掲載 本資料は主に こちらを参照
20.
ライブラリ • fda:データの関数化や関数回帰分析,関数主成分分析を実装 • fda.pace:スパース経時測定データに対して用いられる 関数主成分分析を実装 •
refund:多様な種類の関数回帰モデルを実装 • scikit-fda:関数データ解析に関する手法を網羅的に実装 その他,MATLABやSASにも実装されている 20
21.
目次 • 関数データ解析の概要 ̶ 関数データ解析って何? ̶
データの関数化(基底関数展開・混合効果モデル) ̶ 関数データの要約統計量 ̶ 関数データならではの分析 • 関数回帰分析 • その他の関数データ解析手法と応用 21
22.
離散時点観測から関数データへ • 経時測定データを,次のように表現する 𝑡𝑖𝛼, 𝑥𝑖𝛼
; 𝑖 = 1, … , 𝑛, 𝛼 = 1, … , 𝑛𝑖 • 左の例に当てはめると, 𝑖:都市番号, 𝛼:時点番号, 𝑛:都市の数, 𝑛𝑖:第𝑖番目の都市の観測時点数 𝑡𝑖𝛼:月, 𝑥𝑖𝛼:気温 • 時点 𝑡𝑖𝛼 やその数は,観測 𝑖 ごとに 異なっていてもよい 22 𝑡14, 𝑥14 𝑡24, 𝑥24 𝑡34, 𝑥34 例:3都市の1年間における 月別平均気温
23.
データの関数化 • 観測されているデータは,本来存在する連続的な変動にノイズが伴って 得られていると仮定 • そこで,気温𝑥𝑖𝛼は,次のように時間の未知の関数𝑢𝑖
𝑡 に誤差𝜀が加わった形 で与えられると仮定 𝑥𝑖𝛼 = 𝑢𝑖 𝑡𝑖𝛼 + 𝜀𝑖𝛼, 𝜀𝑖𝛼~𝑖.𝑖.𝑑 𝑁 0, 𝜎2 • これは説明変数を𝑡𝑖𝛼,目的変数を𝑥𝑖𝛼とみなした回帰モデルに対応 • 関数𝑢𝑖 𝑡 を推定することで,関数データ𝑥𝑖 𝑡 を得る • 𝑢𝑖 𝑡 を推定する方法としては基底関数展開や局所平滑化などを用いた 方法が考えられているが,ここでは基底関数展開に基づく平滑化を紹介 23
24.
(その前に)統計モデリングの一般的な流れ • モデルを仮定する (例. 線形回帰モデル・ロジスティック回帰モデル) •
モデルの推定方法を決める(≒目的関数を決める) (例. 最小2乗法・最尤法・正則化法(ridge・lasso)) • 推定アルゴリズムを適用する (例. 解析計算・勾配法) • 推定されたモデルを評価する (例. 交差検証法・AIC・BIC) 24 これら4つの区別を意識した上で説明を聞くと,流れを整理しやすいかもしれません
25.
基底関数展開 • 関数𝑢 𝑡
は,基底関数とよばれる既知の関数系の線形結合で表されると仮定 𝑢 𝑡 = 𝑤1 𝜙1 𝑡 + ⋯ + 𝑤 𝑚 𝜙 𝑚 𝑡 = 𝒘 𝑇 𝝓 𝑡 𝒘 = 𝑤1, … , 𝑤 𝑚 𝑇, 𝝓 𝑡 = 𝜙1 𝑡 , … , 𝜙 𝑚 𝑡 𝑇 • 𝒘は未知のパラメータ, 𝝓 𝑡 は基底関数からなるベクトル • 基底関数の個数𝑚の決め方については後述 • 𝝓 𝑡 の種類としてはさまざまなものが考えられている ̶ 多項式 ̶ Fourier級数 ̶ B-スプライン ̶ ウェーブレット ̶ 動径基底関数 25 このあたりの詳細を勉強したい方向けの本: Green & Silverman (1994); 小西 (2010)
26.
Fourier級数 • 三角関数からなる基底関数 𝜙𝑗 𝑡
= 0 𝑗 = 0 sin 𝑗𝜔𝑡 / 2 𝑗 = 2𝑙 − 1 cos 𝑗𝜔𝑡 / 2 𝑗 = 2𝑙 𝜔 = 2𝜋 𝑇 , 𝑇: 周期 • 周期性をもつデータの変動を 捉えやすい • 逆に,周期性を持たないデータに 対しては当てはまりがあまりよくない • 基底関数は直交性を持つ • 微分の計算が容易 26 Fourier基底関数 (𝑚 = 5)
27.
B-スプライン • 特定の区間における多項式がその 端点(節点という)で,隣り合う 区間の多項式と接続するように 構築された関数はスプライン関数と よばれる • スプラインの1種であるB-スプライ ン(𝑟次)は,次の式で逐次的に構築さ れる(de
Boorのアルゴリズム) 27 𝜙𝑗 𝑡; 0 = ൝ 1 𝑠𝑗 ≤ 𝑡 < 𝑠𝑗+1 0 その他 (𝑠𝑗:節点) 𝜙𝑗 𝑡; 𝑟 = 𝑡 − 𝑠𝑗 𝑠𝑗+𝑟 − 𝑠𝑗 𝜙𝑗 𝑡; 𝑟 − 1 + 𝑠𝑗+𝑟+1 − 𝑡 𝑠𝑗+𝑟+1 − 𝑠𝑗+1 𝜙𝑗+1 𝑡; 𝑟 − 1 B-スプライン基底関数 (𝑚 = 9) (0次) (1次) (2次) (赤の縦破線が節点の位置)
28.
動径基底関数 • 𝑡 をスカラーというより𝑑次元ベクトル
𝒕 と 考えたとき,𝒕と𝝁とのユークリッド距離に 基づく基底関数𝜙𝑗 𝒕 = 𝜙𝑗 𝒕 − 𝝁 を 動径基底関数という • 曲線だけでなく(超)曲面の当てはめも容易 • 代表的な基底関数として次が挙げられる – ガウス基底関数 𝜙𝑗 𝒕 = exp − 𝒕 − 𝝁 𝑗 2 2𝜎𝑗 2 – Thin plate (薄板) spline 基底関数 𝜙𝑗 𝒕 = 𝒕 − 𝝁 𝑗 2 log 𝒕 − 𝝁 𝑗 28 動径基底関数(上から1次元,2次元)
29.
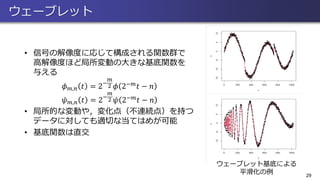
ウェーブレット • 信号の解像度に応じて構成される関数群で 高解像度ほど局所変動の大きな基底関数を 与える 𝜙 𝑚,𝑛
𝑡 = 2− 𝑚 2 𝜙 2−𝑚 𝑡 − 𝑛 𝜓 𝑚,𝑛 𝑡 = 2− 𝑚 2 𝜓 2−𝑚 𝑡 − 𝑛 • 局所的な変動や,変化点(不連続点)を持つ データに対しても適切な当てはめが可能 • 基底関数は直交 29 ウェーブレット基底による 平滑化の例
30.
関数データの構築 • 基底関数展開に基づく回帰モデル 𝑥𝑖𝛼 =
𝒘𝑖 𝑇 𝝓 𝑡𝑖𝛼 + 𝜀𝑖𝛼, 𝜀𝑖𝛼~𝑖.𝑖.𝑑 𝑁 0, 𝜎𝑖 2 の回帰係数𝒘𝑖を推定することで得られる関数 𝑥𝑖 𝑡 = ො𝑢𝑖 𝑡 = ෝ𝒘𝑖 𝑇 𝝓 𝑡 (𝑖 = 1, … , 𝑛) を,関数データとして扱う • 基底関数𝝓 𝑡 は各𝑖で共通とする • 回帰係数𝒘𝑖の推定方法として,ここでは 正則化法について紹介 30 0 0.2 0.4 0.6 0.8 1 0 20 40 60 -140 -90 -40 10 0 20 40 60 -140 -90 -40 10 0 20 40 60
31.
最尤法 • 誤差𝜀𝑖𝛼は互いに独立に正規分布𝑁 0,
𝜎2 に従うことから, 𝑥𝑖𝛼は確率密度関数 𝑓(𝑥𝑖𝛼; 𝒘𝑖, 𝜎2) = 1 2𝜋𝜎2 exp − 1 2𝜎2 𝑥𝑖𝛼 − 𝒘𝑖 𝑇 𝝓 𝑡𝑖𝛼 2 をもつ • 対数尤度関数は次で与えられる ℓ 𝒘𝑖, 𝜎2 = − 𝑛 2 log 2𝜋𝜎2 − 1 2𝜎2 𝛼=1 𝑛 𝑖 𝑥𝑖𝛼 − 𝒘𝑖 𝑇 𝝓 𝑡𝑖𝛼 2 • 最尤法では,対数尤度関数ℓ 𝒘𝑖, 𝜎2 を最大とするパラメータ𝒘𝑖, 𝜎2を 推定値とみなす • 回帰係数𝒘𝑖の推定量は最小2乗推定量に一致 31
32.
正則化法 • 最尤法(最小2乗法)では,基底関数の数を増やせば増やすほど 曲線の変動が大きくなり,観測データへの当てはまりがよいモデルが 得られる(過適合) • そこで,対数尤度関数ℓ
𝒘𝑖, 𝜎2 の代わりに,曲線の変動に対する罰則を 表す関数𝑃 𝒘 課した正則化(罰則付き)対数尤度関数の最大化により パラメータを推定 ℓ 𝜆 𝒘𝑖, 𝜎2 = ℓ 𝒘𝑖, 𝜎2 − 𝑛𝜆 2 𝑃 𝒘𝑖 (𝜆 > 0:正則化(平滑化)パラメータ) • 正則化対数尤度関数ℓ 𝜆 𝒘𝑖, 𝜎2 最大化にパラメータの推定値を得る方法を 正則化法(正則化最尤法)という 32
33.
正則化項 • 正則化項𝑃 𝒘
としては,次のようなものが挙げられる – 𝑃 𝒘𝑖 = 𝑢𝑖 ′′ 𝑡 2 𝑑𝑡:曲率に対する罰則 – 𝑃 𝒘𝑖 = 𝒘𝑖 𝑇 𝐷 𝑘 𝑇 𝐷 𝑘 𝒘𝑖:𝒘𝑖の𝑘次差分に対する罰則(𝐷 𝑘:差分行列) – 𝑃 𝒘𝑖 = 𝒘𝑖 𝑇 𝒘𝑖:𝒘𝑖の𝐿2ノルムに対する罰則(ridge) – 𝑃 𝒘𝑖 = σ 𝑗=1 𝑚 |𝑤𝑖𝑗| :𝒘𝑖の𝐿1ノルムに対する罰則(lasso) • 本講義では2次差分に対する罰則𝑃 𝒘𝑖 = 𝒘𝑖 𝑇 𝐷2 𝑇 𝐷2 𝒘𝑖を想定 33
34.
正則化推定量 • 正則化対数尤度関数ℓ 𝜆
𝒘𝑖, 𝜎2 を𝒘𝑖, 𝜎2についてそれぞれ偏微分することで 得られる次の正規方程式を解くことで,正則化推定量を得る 𝜕 𝜕𝒘𝑖 ℓ 𝜆 𝒘𝑖, 𝜎2 = 1 𝜎2 𝐵𝑖 T 𝒙𝑖 − 𝐵𝑖 𝑇 Φ𝑖 𝒘𝑖 − 𝑛𝜆𝐾𝒘𝑖 = 0 𝜕 𝜕𝜎2 ℓ 𝜆 𝒘𝑖, 𝜎2 = − 𝑛 2𝜎4 + 1 2𝜎2 𝒙𝑖 − Φ𝑖 𝒘𝑖 𝑇 𝒙𝑖 − Φ𝑖 𝒘𝑖 = 0 𝐵𝑖 = 𝜙1 𝑡𝑖1 ⋯ 𝜙 𝑚 𝑡𝑖1 ⋮ ⋱ ⋮ 𝜙1 𝑡𝑖𝑛 𝑖 ⋯ 𝜙 𝑚 𝑡𝑖𝑛 𝑖 , 𝒙𝑖 = 𝑥𝑖1 ⋮ 𝑥𝑖𝑛 𝑖 , 𝐾 = 𝐷2 𝑇 𝐷2 • 正則化最尤推定量: ෝ𝒘𝑖 = 𝐵𝑖 𝑇 𝐵𝑖 + 𝑛𝜆 ො𝜎2 𝐾 −1 Φ𝑖 𝒙𝑖, ො𝜎𝑖 2 = 1 𝑛𝑖 𝒙𝑖 − 𝐵𝑖 ෝ𝒘𝑖 𝑇 𝒙𝑖 − 𝐵𝑖 ෝ𝒘𝑖 34
35.
調整パラメータの選択 • 正則化パラメータ𝜆や基底関数の個数𝑚といった調整パラメータの値に 応じて,モデルの推定結果は大きく変わる • これらの値を選択するために,情報量規準などさまざまな基準(後述)が モデル選択基準として用いられる •
モデル評価基準を利用した調整パラメータ選択の手順は次の通り: 1. 調整パラメータの値の候補を決める 2. 調整パラメータの候補値の中から1パターンを選び,それに基づいて モデルパラメータ(𝑤𝑖, 𝜎𝑖 2 )を推定 3. モデルパラメータの推定値に基づき,後述のモデル評価基準を計算 4. 2., 3.の処理を,候補値を変えて繰り返す 5. 得られた複数のモデル評価基準の値の中から最小(最大)のものを探し, 対応する調整パラメータの値を最適なものとみなす 35
36.
Modified AIC • 最尤法によって推定されたモデルを評価するために用いられるAIC AIC
= −2ℓ 𝜽𝑖 + 2𝑚 𝜽𝑖 = ෝ𝒘𝑖, ෝ𝜎𝑖 2 では,正則化法によって推定されたモデルを適切に評価できない • AIC第2項の𝑚(モデルパラメータ数)を,有効自由度𝑒𝑑𝑓で置き換えた 次の基準を用いる mAIC = −2ℓ 𝜽𝑖 + 2𝑒𝑑𝑓𝑖 – 𝑒𝑑𝑓𝑖は次で与えられる 𝑒𝑑𝑓𝑖 = 𝑡𝑟 𝑆𝑖 , 𝑆𝑖 = 𝐵𝑖 𝐵𝑖 𝑇 𝐵𝑖 + 𝑛𝜆 ෝ𝜎𝑖 2 𝐾 −1 Φ𝑖 – 𝑆𝑖は平滑化行列とよばれるもので, 𝒙𝑖の予測値ෝ𝒙𝑖への線形変換 ෝ𝒙𝑖 = 𝐵𝑖 ෝ𝒘𝑖 = 𝐵𝑖 𝐵𝑖 𝑇 𝐵𝑖 + 𝑛𝜆 ෝ𝜎𝑖 2 𝐾 −1 𝐵𝑖 𝒙𝑖 = 𝑆𝑖 𝒙𝑖 36
37.
GCV:一般化交差検証法 • 基底関数展開に基づく回帰モデル&正則化最尤推定(最小2乗推定)では, 1個抜き交差検証法は次の式と等価 CV = 1 𝑛 𝛼=1 𝑛
𝑖 𝑥𝑖𝛼 − 𝑢 𝑡𝑖𝛼 1 − 𝑆 𝛼𝛼 2 𝑆 𝛼𝛼:𝑆𝑖の第𝛼𝛼成分 • 分母の1 − 𝑆 𝛼𝛼を,その期待値1 − 𝑡𝑟 𝑆𝑖 /𝑛で置き換えたものは 一般化交差検証法(Generalized Cross-Validation; GCV)とよばれる GCV = 1 𝑛 𝛼=1 𝑛 𝑖 𝑥𝑖𝛼 − 𝑢 𝑡𝑖𝛼 1 − 𝑡𝑟 𝑆𝑖 /𝑛 2 • GCVは,モデルに依存しない定数項を除いて 修正AICに(1次近似の意味で)近似的に等しい 37
38.
GIC:一般化情報量規準 • AICは本来,最尤法によって推定されたモデルを評価する基準として 導出されたもので,正則化法は含まれていない • 正則化最尤推定を含むM-推定の枠組みで推定されたモデルを評価する 基準として,一般化情報量規準GIC
(Generalized Information Criterion) が導出された GIC = −2ℓ 𝜽𝑖 + 2𝑡𝑟 𝑅 𝜽𝑖 −1 𝑄 𝜽𝑖 𝑅 𝜽𝑖 = − 1 𝑛 𝛼=1 𝑛 𝑖 ቤ 𝜕 𝜕𝜽𝑖 𝜓 𝑥𝑖𝛼, 𝜽𝑖 𝑇 𝜽 𝑖=𝜽 𝑖 , 𝑄 𝜽𝑖 = − 1 𝑛 𝛼=1 𝑛 𝑖 อ𝜓 𝑥𝑖𝛼, 𝜽𝑖 𝜕 𝜕𝜽𝑖 𝑇 log 𝑓 𝑥𝑖𝛼, 𝜽𝑖 𝜽 𝑖=𝜽 𝑖 𝜓 𝑥𝑖𝛼, 𝜽𝑖 = 𝜕 𝜕𝜽𝑖 log 𝑓 𝑥𝑖𝛼, 𝜽𝑖 − 𝑛𝑖 𝜆 2 𝒘𝑖 𝑇 𝐾𝒘𝑖 • 𝜆 = 0のとき,つまり正則化最尤法が最尤法に帰着されるとき GICはAICに帰着される 38 Konishi & Kitagawa (1996, Biometrika) 小西, 北川 (2004)
39.
GBIC:一般化ベイズ型モデル評価基準 • ベイズアプローチの観点から導出されたモデル評価基準BICもAICと同様 最尤法によって推定されたモデルを評価するために用いられるもので 正則化法は含まれていない • BICの考え方を応用し,正則化法によって推定されたモデルを評価するため のモデル評価基準として,一般化ベイズ型モデル評価基準GBIC (Generalized
Bayesian Information Criterion)が導出された GBIC = −2ℓ 𝜽𝑖 + 𝑛𝜆ෝ𝒘𝑖 𝑇 𝐾ෝ𝒘𝑖 + 𝑚log 𝑛 + log 𝐽 𝜽𝑖 −log 𝐾 + − 𝑚 log 2𝜋 − 𝑚 − 𝑘 log𝜆 𝐽 𝜽𝑖 = − 1 𝑛𝑖 𝜕 𝜕𝜽𝑖 𝜕𝜽𝑖 𝑇 log 𝑓 𝒙𝑖, 𝜽𝑖 + 𝜆𝐾, 𝑘 = 𝑚 − rank 𝐾 𝐾 +: 𝐾の非零固有値の積 39 Konishi et al. (2004, Biometrika) 小西, 北川 (2004)
40.
その他の関数化方法 • ここまでで述べた方法は1観測の関数化に適用される もので,これを𝑛回独立に繰り返すことで関数データ集合が得られる • 1観測あたりの観測時点数が十分多ければ問題ないが そうでない場合,特にスパース経時測定データに対しては 全観測データを利用して関数化する方法も考えられている ✓
個体ごとの曲線のばらつきを変量効果とみなして 混合効果モデルを適用することで関数化 (James, et al., 2000, Biometrika; 松井他, 2016, 応用統計学) ・・・次からのスライドで紹介 ✓ 経時データの共分散関数(曲面)を局所平滑化により推定し 固有値と固有関数を求めることで関数化 (Yao et al., 2003, Biometrics; 2005, JASA) 40
41.
基底関数展開に基づく混合効果モデル(1) • 経時測定データ: {(𝑡𝑖𝛼,
𝑥𝑖𝛼); 𝑖 = 1, … , 𝑛, 𝛼 = 1, … , 𝑛𝑖} 𝑡𝑖𝛼:第 𝑖 観測,第 𝛼 の時点 𝑥𝑖𝛼:𝑡𝑖𝛼における観測値 • 基底関数展開に基づく混合効果モデル (Rice & Wu, 2001, Biometrics) 𝑥𝑖𝛼 = 𝑘=1 𝑚 𝑓 𝑤 𝑘 𝜙 𝑘 𝑓 𝑡𝑖𝛼 + 𝑙=1 𝑚 𝑟 𝑣𝑖𝑙 𝜙𝑙 𝑟 𝑡𝑖𝛼 + 𝜀𝑖𝛼 = 𝒘 𝑇 𝝓 𝑓 𝑡𝑖𝛼 + 𝒗𝑖 𝑇 𝝓 𝑟 𝑡𝑖𝛼 + 𝜀𝑖𝛼 𝝓 𝑓 𝑡 = 𝜙1 𝑓 𝑡 , … , 𝜙 𝑚 𝑓 𝑓 𝑡 𝑇 , 𝝓 𝑟 𝑡 = 𝜙1 𝑟 𝑡 , … , 𝜙 𝑚 𝑟 𝑟 𝑡 𝑇 :基底関数 𝒘 = 𝑤1, … , 𝑤 𝑚 𝑓 𝑇 :固定効果係数, 𝒗𝑖 = 𝑣𝑖1, … , 𝑣𝑖𝑚 𝑟 𝑇 ~𝑁 𝑚 𝑟 𝟎, Γ :変量効果係数(確率変数) 𝜺𝑖 = 𝜀𝑖1, … , 𝜀1𝑛 𝑖 𝑇 ~𝑁 𝑛 𝑖 𝟎, 𝜎2 𝐼 𝑛 𝑖 :誤差 41 固定効果項 変量効果項
42.
パラメータの推定 • 混合効果モデル 𝑥𝑖𝛼 =
𝒘 𝑇 𝝓 𝑓 𝑡𝑖𝛼 + 𝒗𝑖 𝑇 𝝓 𝑟 𝑡𝑖𝛼 + 𝜀𝑖𝛼 を,𝛼 = 1, … , 𝑛𝑖についてまとめて表記することで 𝒙𝑖 = 𝐵𝑖 (𝑓) 𝒘 + 𝐵𝑖 (𝑟) 𝒗𝑖 + 𝜺𝑖 𝒙𝑖 = 𝑥𝑖1, … , 𝑥𝑖𝑛 𝑖 𝑇 𝐵𝑖 (𝑓) = 𝝓 𝑓 𝑡𝑖1 , … , 𝝓 𝑓 𝑡𝑖𝑛 𝑖 , 𝐵𝑖 (𝑟) = 𝝓 𝑟 𝑡𝑖1 , … , 𝝓 𝑟 𝑡𝑖𝑛 𝑖 • 𝒗𝑖~𝑁 𝑚 𝑟 𝟎, Γ , 𝜺𝑖~𝑁 𝑛 𝑖 𝟎, 𝜎2 𝐼 𝑛 𝑖 より, 𝒙𝑖~𝑁 𝑛 𝑖 𝐵𝑖 (𝑓) 𝒘, 𝜎2 𝐼 𝑛 𝑖 + 𝐵𝑖 (𝑟) Γ𝐵𝑖 𝑟 𝑇 𝒙𝑖の同時密度関数𝑓 𝒙𝑖; 𝜽 に基づく尤度関数𝐿 𝜽 の最大化によって パラメータ𝜽 = 𝜎2, 𝒘, Γ を推定したい(最尤法) 42
43.
EMアルゴリズム • 対数尤度関数は log 𝑓
𝒙𝑖; 𝜽 = − 1 2 𝑖=1 𝑛 𝑛𝑖 log 2𝜋 − 𝑛 2 log 𝜎2 𝐼 𝑛 𝑖 + 𝐵𝑖 𝑟 Γ𝐵𝑖 𝑟 𝑇 − 1 2 𝑖=1 𝑛 𝒙𝑖 − 𝐵𝑖 𝑓 𝒘 𝑇 𝜎2 𝐼 𝑛 𝑖 + 𝐵𝑖 𝑟 Γ𝐵𝑖 𝑟 𝑇 −1 𝒙𝑖 − 𝐵𝑖 𝑓 𝒘 • 混合効果モデルのパラメータ 𝜽 の最尤推定量を解析的に求めることは困難 • その代わりにEM(Expectation-Maximization)アルゴリズムを用いる • 次のE-stepとM-stepを,パラメータの更新値が収束するまで繰り返す – 確率変数 𝒗𝑖 の代わりに,その条件付期待値 ෝ𝒗𝑖= 𝐸[𝒗𝑖 𝒙𝑖 を求める (E-step) – 条件付期待値ෝ𝒗𝑖を元にして,パラメータ𝜽の推定値を対数尤度関数の期待値 𝐸 log 𝑓 𝒙𝑖; 𝜽 |𝒙𝑖 の最大化により求める (M-step) 43
44.
パラメータの更新値 • 確率変数𝒗𝑖およびパラメータ𝜎2, 𝒘,
Γは,次で更新される (アルゴリズムの詳細は松井他, 2016参照) ෝ𝒗𝑖 = ො𝜎2 Γ−1 + 𝐵𝑖 𝑟 𝑇 𝐵𝑖 𝑟 −1 𝐵𝑖 𝑟 𝑇 𝒙𝑖 − 𝐵𝑖 𝑟 ෝ𝒘 ො𝜎2 = 1 σ𝑖=1 𝑛 𝑛𝑖 𝑖=1 𝑛 𝒙𝑖 − 𝐵𝑖 𝑓 ෝ𝒘 − 𝐵𝑖 𝑟 ෝ𝒗𝑖 𝑇 𝒙𝑖 − 𝐵𝑖 𝑓 ෝ𝒘 − 𝐵𝑖 𝑟 ෝ𝒗𝑖 + ൩tr 𝐵𝑖 𝑟 Γ−1 + 1 ො𝜎2 𝐵𝑖 𝑟 𝑇 𝐵𝑖 𝑟 −1 𝐵𝑖 𝑟 𝑇 Γ = 1 𝑛 ෝ𝒗𝑖 𝑇 ෝ𝒗𝑖 + Γ−1 + 1 ො𝜎2 𝐵𝑖 𝑟 𝑇 𝐵𝑖 𝑟 −1 ෝ𝒘 = 𝑖=1 𝑛 𝐵𝑖 𝑟 𝑇 𝐵𝑖 𝑟 −1 𝑖=1 𝑛 𝐵𝑖 𝑓 𝑇 𝒙𝑖 − 𝐵𝑖 𝑟 ෝ𝒗𝑖 44
45.
混合効果モデルによる関数化 • 確率変数の予測値ෝ𝒗𝑖およびパラメータ推定値ෝ𝒘を 混合効果モデルに代入することで 関数データが得られる 𝑥𝑖 𝑡
= ෝ𝒘 𝑇 𝝓 𝑓 𝑡 + ෝ𝒗𝑖 𝑇 𝝓 𝑟 𝑡 • 右図上のようなスパース経時測定データに 対しても,混合効果モデルを用いることで 右図下のように関数データを構成できる 45 スパース経時測定データ(上)と 混合効果モデルにより得られる曲線(下)
46.
関数化についての補足 • 誤差iid,等分散の仮定で平滑化してもいいの? – データの背景から自己相関や不等分散性等の仮定が無視できない場合は これらの仮定の下でモデルを推定すべき –
仮定を弱めることでパラメータ数が増えると計算コストが大きくなる また,推定結果が不安定になりiid仮定の場合と精度が大差なくなる場合もある (Ramsay & Silverman, 2005, §3.2.4) • 関数化と,その後の分析を切り分けていいの? – 関数化のための関数化と,関数データ解析のための関数化は違うのでは? – 多くの関数データ解析手法では,一旦データを関数化し,得られた関数データ集合に 対して回帰分析や判別分析を行う2段階法が用いられている – 関数化と関数回帰モデルの推定を同時に行う1段階法も考えられており 2段階法に比べて推定値のバイアスを減らすことができる場合があるが, 2段階法よりも計算コストが大きく,また推定結果に劇的な差はないと考えられている (Crainiceanu et al., 2009, JASA) 46
47.
目次 • 関数データ解析の概要 ̶ 関数データ解析って何? ̶
データの関数化(基底関数展開・混合効果モデル) ̶ 関数データの要約統計量 ̶ 関数データならではの分析 • 関数回帰分析 • その他の関数データ解析手法と応用 47
48.
ランダム関数(概要) • 多変量データは,何らかの確率分布に従う確率変数 (random
variable) の実現値として与えられた • 関数データ𝑥𝑖 𝑡 も同様に「ランダム関数」𝑋 𝑡 の実現値とみなす • ランダム関数は2乗可積分とする.すなわち, 𝑋 2 = න 𝑋 𝑡 2 𝑑𝑡 < ∞ • ランダム関数の平均関数と共分散関数は,それぞれ次で与えられる 𝜇 𝑡 = 𝐸 𝑋 𝑡 𝐾 𝑡, 𝑠 = 𝐸 𝑋 𝑡 − 𝜇 𝑡 𝑋 𝑠 − 𝜇 𝑠 48
49.
Karhunen-Loéve展開(関数主成分) • 2乗可積分なランダム関数𝑋 𝑡
とその共分散関数𝐾 𝑡, 𝑠 に対して, න𝐾 𝑡, 𝑠 𝑢 𝑠 𝑑𝑠 = 𝜆𝑢 𝑡 をみたす𝜆, 𝑢(𝑡)をそれぞれ 𝑋 𝑡 の固有値,固有関数という • 上式の解の組を 𝜆1, 𝑢1(𝑡) , 𝜆2, 𝑢2(𝑡) , …とする(一般的に 𝜆1 ≥ 𝜆2 ≥ ⋯)と, 任意の2乗可積分なランダム関数𝑋 𝑡 は次で表される( 𝜇 𝑡 :平均関数) 𝑋 𝑡 = 𝜇 𝑡 + 𝑗=1 ∞ 𝜉𝑗 𝑢𝑗 𝑡 • これは 𝑋 𝑡 のKarhunen-Loéve展開とよばれる • 基底関数展開の1つとみなすこともできる (実際の分析では有限和にtruncateしたものを用いる) • 固有関数𝑢𝑗 𝑡 は𝑋 𝑡 の正規直交基底を構成するもので,関数主成分とよばれる 49
50.
関数データの要約統計量(1) • 関数データ𝑥𝑖 𝑡
に対しては, 𝑥𝑖 𝑡 の各点𝑡に対して スカラーデータと同様に要約統計量が与えられる – 標本平均 ҧ𝑥 𝑡 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 𝑡 – 標本不偏分散 𝑣 𝑋 𝑡 = 1 𝑛 − 1 𝑖=1 𝑛 𝑥𝑖 𝑡 − ҧ𝑥 𝑡 2 – 標本標準偏差 𝑠𝑑 𝑋 𝑡 = 𝑣 𝑋 𝑡 50 カナダの35都市の気温変化の データに対する平均曲線(赤実線)と 標準偏差曲線(赤破線)
51.
関数データの要約統計量(2) • 1標本データに対しても,異なる時点間で 標本不偏共分散・相関係数が定義される 𝑐 𝑋
𝑠, 𝑡 = 1 𝑛 − 1 𝑖=1 𝑛 𝑥𝑖 𝑡 − ҧ𝑥 𝑡 𝑥𝑖 𝑠 − ҧ𝑥 𝑠 𝑐𝑜𝑟𝑋 𝑠, 𝑡 = 𝑐 𝑋 𝑠, 𝑡 𝑐 𝑋 𝑠, 𝑠 𝑐 𝑋 𝑡, 𝑡 • 2標本関数データ 𝑥𝑖 𝑡 , 𝑦𝑖 𝑡 に対しては クロス共分散・クロス相関が用いられる 𝑐 𝑋,𝑌 𝑠, 𝑡 = 1 𝑛 − 1 𝑖=1 𝑛 𝑥𝑖 𝑡 − ҧ𝑥 𝑡 𝑦𝑖 𝑠 − ത𝑦 𝑠 𝑐𝑜𝑟𝑋,𝑌 𝑠, 𝑡 = 𝑐 𝑋,𝑌 𝑠, 𝑡 𝑐 𝑋,𝑋 𝑠, 𝑠 𝑐 𝑌,𝑌 𝑡, 𝑡 51 𝑐 𝑋 𝑠, 𝑡 𝑐𝑜𝑟𝑋 𝑠, 𝑡 気温データに対する共分散・相関係数
52.
目次 • 関数データ解析の概要 ̶ 関数データ解析って何? ̶
データの関数化(基底関数展開・混合効果モデル) ̶ 関数データの要約統計量 ̶ 関数データならではの分析 • 関数回帰分析 • その他の関数データ解析手法と応用 52
53.
関数データの微分 • データを関数として扱うことで,その微分を扱うことができる • 基底関数展開の仮定を用いれば,関数データの微分は 基底関数の微分として計算可能 •
関数データ𝑥𝑖 𝑡 の𝑘階微分は次で与えられる 𝑥𝑖 𝑘 𝑡 = ෝ𝒘𝑖 𝑇 𝝓 𝑘 𝑡 • Fourier級数やガウス型動径基底関数は無限回微分可能である一方で B-スプライン(𝑟次)は𝑟 − 1階までのみ微分可能 • 𝑘階微分の関数データ𝑥𝑖 𝑘 𝑡 を分析に用いる場合は, 元の関数データ𝑥𝑖 𝑡 を平滑化により推定する際に𝑘 + 2階微分の制約 𝑃 𝒘𝑖 = 𝑢𝑖 𝑘+2 𝑡 2 𝑑𝑡を用いるべきとされる ( 𝑘 + 2 階までの滑らかさを保証するため) 53
54.
成長データに対する微分 • 1歳から18歳までの子供の身長の推移のデータ に対して2階微分(加速度)を計算 – 関数化には6次B-スプラインを適用 (2階微分が2次の滑らかさを保証) •
10~15歳あたりの加速度の変化は 第2次性徴に対応 – 男子よりも女子の方が早いタイミングで 第2次性徴を迎えていることがわかる – 男子はこの時期に身長の伸びが加速する一方 で女子の伸びの加速は小さく,この時期を 過ぎると身長の伸びは止まる 54 黒:男子 赤:女子 男子の加速度 女子の加速度
55.
曲線アライメント(概要) • 身長の加速度のように,観測(曲線)によって そのピーク位置が異なることが多く,その場合 データの特徴を捉えることが困難 • 関数データの変動の傾向を捉え,その位置を 曲線間で揃える処理のことをアライメント (またはレジストレーション)という •
基準となる時点を1つ定め,データがよく揃うよう 関数データ𝑥𝑖 𝑡 の時点 𝑡 を変換する関数ℎ𝑖 𝑡 (time-warping関数)を推定する 55 アライメント前(上)と後(下)の曲線 Kneip & Ramsay (2008, JASA) Ramsay, Hooker & Graves (2009)
56.
ここまでのまとめ • 関数データ解析は,1つの観測が時間等の経過とともに繰り返して 計測されたデータを関数化し,関数化データ集合を対象とした 分析手法と理論の総称 • 関数データ解析には,古典的な多変量解析手法を関数データの枠組みへ 拡張したものが多く含まれる •
データの微分を利用した分析や曲線アライメントなど 関数データ解析ならではの手法もある • データの関数化には,基底関数展開や局所回帰に基づく平滑化などが 用いられる 56
57.
目次 • 関数データ解析の概要 • 関数回帰分析 –
スカラー-関数型回帰モデル – 関数-スカラー型回帰モデル – 関数-関数型回帰モデルその1 – 関数-関数型回帰モデルその2 • その他の関数データ解析手法と応用 57
58.
関数回帰分析の応用例1 カナダの気象データ • カナダの35都市で計測された日別平均気温 と降水量 • 日別平均気温(365時点)が年間総降水量 (に対数をとったもの)とどのように関連 しているかを,回帰モデルで推定したい •
1月から12月までの気温の,降水量への 寄与の「経時変化」はどのようになって いる? • 降水量が気温と同様に「日別」降水量とし て与えられた場合はどうなる? 58 35都市の気温変化(関数化後) log(年間総降水量)のヒストグラム “CanadianWeather” by R package “fda” Ramsay & Silverman (2005)
59.
関数回帰分析の応用例2 肉標本の近赤外スペクトルデータ • 近赤外線吸収率の波長毎の変動は 肉標本の成分含有量に依存 • 波長毎の吸収率を波長の関数データ とみなし成分含有量との関連を見る 59 水分
脂質 蛋白質 肉標本が吸収する近赤外線の 100チャンネル毎の吸収率 成分含有量 データ出典:Borggaard & Thodberg, 1992 R package “caret”から取得可能 https://www.tomra.com/en/sorting/food/food-technology Matsui et al. (2008, J. Data Sci.)
60.
関数回帰分析の応用例3 手書き文字データ • 指先の時間経過に伴う軌跡を時間の関数データとして扱い 何の文字が書かれたかを判別 60 指の軌跡を計測 Time YcoordinateXcoordinate Time 関数 ロジスティック 回帰モデル Matsui et
al. (2011, J. Classification)
61.
関数回帰モデル • 説明変数と目的変数に対応するデータのいずれか,または両方が 関数データとして与えられたとき,これらの関係をモデル化するもの • 説明変数と目的変数がスカラーであるか関数であるかに応じて 用いるモデルも異なる •
関数回帰モデルは,次のように大別できる 61 目的変数 説明変数 スカラー 関数 スカラー 一般的な回帰モデル ① 関数 ② ③・ ④
62.
関数回帰モデル ① スカラー-関数型回帰モデル ② 関数-スカラー型回帰モデル ③
関数-関数型回帰モデルその1 ④ 関数-関数型回帰モデルその2 62 𝑌 𝑋 スカラー 関数 スカラー ① 関数 ② ③・ ④ 今 こ こ
63.
①スカラー-関数型線形モデル • 説明変数が関数データ、目的変数がスカラーで与えられたモデル • 𝑖番目の観測における説明変数のデータを𝑥𝑖
𝑡 ,目的変数のデータを𝑦𝑖とおくと 関数線形モデルは次で与えられる 𝑦𝑖 = 𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + 𝜀𝑖 𝛽0:切片, 𝛽1 𝑡 :回帰係数関数, 𝜀𝑖~𝑁 0, 𝜎2 :誤差 • 経時測定データ 𝑥𝑖𝛼; 𝛼 = 1, … , 𝑛𝑖 を説明変数,𝛽 𝛼を係数とした線形重回帰モデル 𝑦𝑖 = 𝛽0 + 𝛼=1 𝑛 𝑖 𝑥𝑖𝛼 𝛽 𝛼 + 𝜀𝑖 において,𝑛𝑖 → ∞として時点間隔を0へ極限を取ったものが,上のモデルに対応 63 Ramsay & Silverman (2005)
64.
関数線形モデルの特徴 𝑦𝑖 = 𝛽0
+ න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + 𝜀𝑖 𝛽0:切片, 𝛽1 𝑡 :回帰係数関数, 𝜀𝑖~𝑁 0, 𝜎2 :誤差 • 説明変数𝑥𝑖 𝑡 が𝑡の関数として与えられているため その係数𝛽1 𝑡 も関数(曲線)で与えられる • 回帰係数関数𝛽1 𝑡 は,任意の点𝑡における 𝑥𝑖 𝑡 の𝑦𝑖への「影響度」の変動を 表している 64
65.
基底関数展開(1) • 係数関数𝛽1 𝑡
を直接推定することは難しいので 推定のためにいくつか仮定をおく • 説明変数のデータ𝑥𝑖 𝑡 は,基底関数展開によって表されると仮定 𝑥𝑖 𝑡 = 𝒘𝑖 𝑇 𝝓 𝑡 𝒘𝑖 = 𝑤𝑖1, … , 𝑤𝑖𝑚 𝑇, 𝝓 𝑡 = 𝜙1 𝑡 , … , 𝜙 𝑚 𝑡 𝑇 • この展開は,データの関数化によって得られるもの したがって,ここでは係数𝒘𝑖は既知とする • 基底関数𝝓 𝑡 は各𝑖で共通である必要がある • 関数主成分分析によって得られる 主成分得点と固有関数によって構成することもできる (Karhunen-Loéve展開) 65
66.
基底関数展開(2) • 係数関数𝛽1 𝑡
も𝑥𝑖 𝑡 と同様,基底関数展開によって表されると仮定 𝛽1 𝑡 = 𝑘=1 𝑚 𝛾 𝑘 𝜙 𝑘 𝑡 = 𝜸 𝑇 𝝓 𝑡 𝜸 = 𝛾1, … , 𝛾 𝑚 𝑇, 𝝓 𝑡 = 𝜙1 𝑡 , … , 𝜙 𝑚 𝑡 𝑇 • 係数関数𝛽1 𝑡 を基底関数展開した係数𝜸は未知とする • 基底関数𝜙 𝑘 𝑡 の種類や数は𝑥𝑖 𝑡 のものと異なっていてもよい 66
67.
関数線形モデルの変形 • 基底関数展開の仮定より,関数線形モデルは次のように変形できる 𝑦𝑖 =
𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + 𝜀𝑖 = 𝛽0 + 𝒘𝑖 𝑇 න 𝑇 𝝓 𝑡 𝝓 𝑡 𝑇 𝑑𝑡 ⋅ 𝜸 + 𝜀𝑖 = 𝛽0 + 𝒘𝑖 𝑇 Φ𝜸 + 𝜀𝑖 = 𝛽0 + 𝒛𝑖 𝑇 𝜸 + 𝜀𝑖 Φ = න 𝑇 𝝓 𝑡 𝝓 𝑡 𝑇 𝑑𝑡, 𝒛𝑖 = Φ𝒘𝑖 67
68.
パラメータの推定 𝑦𝑖 = 𝛽0
+ 𝒛𝑖 𝑇 𝜸 + 𝜀𝑖 • 𝒛𝑖は(ここでは)既知のため,このモデルは古典的な線形回帰モデルと 同じ形とみなせる • そのため,線形回帰モデルに対する一般的な推定方法を 関数線形モデルでも適用できる • 行列Φ = 𝑇 𝝓 𝑡 𝝓 𝑡 𝑇 𝑑𝑡は,基底関数𝝓 𝑡 が既知なので計算可能 特に𝝓 𝑡 が正規直交基底の場合, Φは単位行列になる (Fourier級数やウェーブレット基底,固有関数など) 68
69.
関数線形モデルの推定(最小2乗法) • パラメータの最小2乗推定量は次の最小化により求められる 1 𝑛 𝑖=1 𝑛 𝑦𝑖 −
𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 2 = 1 𝑛 𝑖=1 𝑛 𝑦𝑖 − (𝛽0+𝒛𝑖 𝑇 𝜸) 2 • パラメータ𝜷 = 𝛽0, 𝜸 𝑇 𝑇 の最小2乗推定量: 𝜷 = 𝑍 𝑇 𝑍 −1 𝑍 𝑇 𝒚 𝑍 = 1 𝒛1 ⋯ ⋯ 1 𝒛 𝑛 𝑇 , 𝒚 = 𝑦1, … , 𝑦𝑛 𝑇 • 𝜸の推定値ෝ𝜸を𝛽1 𝑡 = 𝜸 𝑇 𝝓 𝑡 に代入することで, 回帰係数の推定値 መ𝛽1 𝑡 が得られる 69
70.
関数線形モデルの推定(正則化法) • パラメータ𝜸(ひいては係数関数𝛽1 𝑡
)の推定量の変動を抑えるために 正則化法が用いられる • 正則化最小2乗推定量は,次の最小化によって求められる 1 𝑛 𝑖=1 𝑛 𝑦𝑖 − (𝛽0+𝒛𝑖 𝑇 𝜸) 2 + 𝜆𝜸 𝑇 𝐾𝜸 (𝜆:正則化パラメータ, 𝐾:非負値定符号行列) • 𝜷 = 𝜷0, 𝜸 𝑇 𝑇の正則化最小2乗推定量は次で与えられる 𝜷 = 𝑍 𝑇 𝑍 + 𝑛𝜆𝐾0 −1 𝑍 𝑇 𝒚 (𝐾0:𝐾の1行目・1列目に0ベクトルを挿入したもの) • 正則化パラメータ𝜆の値は,交差検証法(CV)などを用いて選択される 正則化最尤法の枠組みの場合はGICやGBICを用いることもできる 70
71.
各点信頼区間 • パラメータ推定量𝜷の分散共分散行列を 利用して,係数関数𝛽1 𝑡
の 各点信頼区間を求めることができる • 仮説検定の考え方を利用すると, 信頼区間が𝛽1 𝑡 = 0を含む時点𝑡では 説明変数𝑥𝑖 𝑡 は目的変数𝑦𝑖に影響を 与えていないと解釈することもできる 71 係数関数𝛽1 𝑡 の推定値(実線)と 各点信頼区間(破線)
72.
各点信頼区間の導出 • パラメータ推定量𝜷の分散共分散行列は次で与えられる 𝑉𝑎𝑟 𝜷
= ො𝜎2 𝑍 𝑇 𝑍 + 𝑛𝜆𝐾0 −1 𝑍 𝑇 𝑍 𝑍 𝑇 𝑍 + 𝑛𝜆𝐾0 −1 ො𝜎2 = 1 𝑛 − 𝑑𝑓 𝑖=1 𝑛 𝑦𝑖 − ො𝑦𝑖 2 , 𝑑𝑓 = 𝑡𝑟 𝑍 𝑍 𝑇 𝑍 + 𝑛𝜆𝐾0 −1 𝑍 𝑇 • これを用いて, 𝛽1 𝑡 の95%各点信頼上限/下限は次で与えられる 𝝓 𝑡 𝑇ෝ𝜸 ± 𝑡0.025 𝑛 − 𝑑𝑓 𝝓 𝑡 𝑇 𝑉𝑎𝑟 ෝ𝜸 𝝓 𝑡 𝑡0.025 𝑚 :自由度𝑚の𝑡分布の上側2.5%点 72
73.
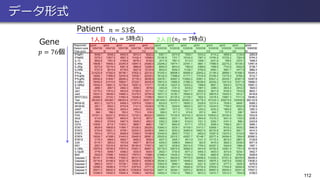
適用例:カナダの気象データ • データ: カナダの35都市で計測された気温と降水量 (”CanadianWeather” by
R package “fda”) • ここでは日別平均気温(365時点)を説明変数, 年間総降水量(に対数をとったもの)を 目的変数として扱う • 気温を時間の関数データ𝑥𝑖 𝑡 ,総降水量を スカラー𝑦𝑖として関数線形モデルを仮定 73 35都市の気温変化(関数化後) 年間総降水量のヒストグラム 𝑦𝑖 = 𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + 𝜀𝑖
74.
結果(1) • 図右下:回帰係数曲線𝛽 𝑡
の最小2乗推定値 (𝛽 𝑡 の基底関数の個数=5) • መ𝛽 𝑡 は「いつの気温がどのように年間降水量 に関係しているか」を表している • 例えば መ𝛽 𝑡 > 0となる期間は 「気温が高いほど降水量も増加する期間」 を表し መ𝛽 𝑡 < 0となる期間は 「気温が低いほど降水量は増加する期間」 を表す • 実際に右図を考察してみると・・・? 74 係数関数の推定値 መ𝛽 𝑡
75.
結果(2) • 図右下:𝛽 𝑡
の正則化最小2乗推定量 ( 𝛽 𝑡 の基底関数の個数=35) • 最小2乗推定量に比べて曲線の変動が 抑えられている • 各点信頼区間を求めることで,特に どの時点での気温が降水量に 寄与しているかを見ることができる • 11月あたりの気温が高い都市ほど 年間総降水量が多いと解釈できる 75係数関数の推定値 መ𝛽 𝑡 (正則化)
76.
関数ロジスティック回帰モデル • 目的変数は一般的な回帰モデルと同じスカラーなので,スカラーデータ に対する回帰モデルの多くはそのまま関数回帰モデルへ適用できる • 関数データ𝑥𝑖
𝑡 を説明変数, 𝑥𝑖 𝑡 の属性を表す2値ラベル𝑦𝑖(= 0,1)を目 的変数とし, 𝑥𝑖 𝑡 が𝑦𝑖 = 1である確率を𝜋𝑖 = Pr 𝑦𝑖 = 1|𝑥𝑖 とする • このとき,関数データ版のロジスティック回帰モデルは次で与えられる log 𝜋𝑖 1 − 𝜋𝑖 = 𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 • 回帰係数𝛽0, 𝛽1 𝑡 を推定しさらに確率𝜋𝑖を推定することで, 関数データ𝑥𝑖 𝑡 が𝑦𝑖 = 1である群への判別に用いることができる • R package “refund”の”pfr”関数で実行可能 76 James (2002, JRSSB) Araki et al. (2009, AISM)
77.
関数ロジスティック回帰モデル(2) • 前頁の関数ロジスティック回帰モデルは2群の判別に用いられるが, これを拡張して3群以上(多群)の判別にも適用できる • 𝐿群の判別問題を考えたとき,
𝑥𝑖 𝑡 の群ラベル𝑔𝑖が𝑙群である確率を 𝜋𝑖𝑙 = Pr 𝑔𝑖 = 𝑙|𝑥𝑖 (𝑙 = 1, … , 𝐿)とおくと, 関数多項ロジスティック回帰モデルは次で与えられる log 𝜋𝑖𝑙 𝜋𝑖𝐿 = 𝛽0𝑙 + න 𝑇 𝑥𝑖 𝑡 𝛽1𝑙 𝑡 𝑑𝑡 𝑙 = 1, … , 𝐿 − 1 • 𝜋𝑖1, … , 𝜋𝑖𝐿の推定値を比較することで 関数データ𝑥𝑖 𝑡 が𝐿群のうちどの群に属するかの判別に用いることができる 77
78.
関数一般化線形モデル • より一般的に,目的変数𝑦𝑖が指数型分布族に従う場合でも 𝑥𝑖 𝑡
と𝑦𝑖との関係を一般化線形モデルの枠組みで表現できる(Araki et al., 2009) 𝜂𝑖 = 𝑔 𝜇𝑖 = 𝛽0𝑙 + න 𝑇 𝑥𝑖 𝑡 𝛽1𝑙 𝑡 𝑑𝑡 𝜇𝑖 = 𝐸 𝑦𝑖 , 𝜂𝑖:線形予測子, 𝑔 ⋅ :連結関数 • 関数ロジスティック回帰モデルもこの枠組みに含まれる 関数ポアソン回帰,関数ガンマ回帰等も適用可能 78
79.
適用例:身長データの判別 • 94名(男子39名,女子54名)の1歳から 18歳までの身長の推移を計測したデータ (“growth” by
R package “fda”) • 計測された時点間隔が,2歳~8歳と それ以外とで異なる • 身長のデータから,性別を判別するための モデルを構築することを考える • 身長の推移𝑥𝑖 𝑡 を関数データの説明変数, 性別を2値(男子=0,女子=1)の目的変数 としてロジスティック回帰モデルを構築 log 𝜋𝑖 1 − 𝜋𝑖 = 𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 79 年齢 子 供
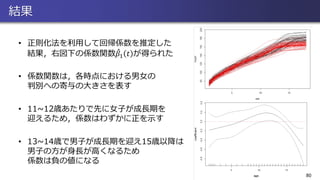
80.
結果 • 正則化法を利用して回帰係数を推定した 結果,右図下の係数関数 መ𝛽1
𝑡 が得られた • 係数関数は,各時点における男女の 判別への寄与の大きさを表す • 11~12歳あたりで先に女子が成長期を 迎えるため,係数はわずかに正を示す • 13~14歳で男子が成長期を迎え15歳以降は 男子の方が身長が高くなるため 係数は負の値になる 80
81.
関数線形モデルの拡張:重回帰モデル • 先程紹介した関数線形モデルでは,説明変数は「気温」1種類だけだった • 「気温・湿度・日照時間」のように,説明変数が複数の場合へは 和をとることで容易に拡張できる 𝑦𝑖
= 𝛽0 + 𝑗=1 𝑝 න 𝑇 𝑥𝑖𝑗 𝑡 𝛽𝑗 𝑡 𝑑𝑡 + 𝜀𝑖 • 関数化(基底関数展開)は変数ごとに行う必要があるが 説明変数が1つのときと全く同様に,古典的な線形回帰モデルと 同様の形に変形できる 81
82.
関数線形モデルの変数選択 • 関数線形(重回帰)モデル 𝑦𝑖 =
𝛽0 + 𝑗=1 𝑝 න 𝑇 𝑥𝑖𝑗 𝑡 𝛽𝑗 𝑡 𝑑𝑡 + 𝜀𝑖 において,目的変数𝑦𝑖に実際に関連する説明変数の組み合わせを 𝑋1 𝑡 , … , 𝑋 𝑝 𝑡 から選択したい • 説明変数の数𝑝が少なければ,ステップワイズ法など 古典的な変数選択法を適用すればよい • スパース推定(川野他, 2018)を利用して 係数関数を 𝛽𝑗(𝑡) ≡ 0と推定することで 対応する変数を選択できる 82 𝑋1(𝑡) 𝑋2(𝑡) 𝑋3(𝑡) 𝑌 Matsui & Konishi (2011, CSDA) Gertheiss et al., (2013, Stat)
83.
関数線形モデルに対するスパース推定 • 𝑝組の説明変数と係数関数がそれぞれ基底関数展開で表されると仮定 𝑥𝑖𝑗 𝑡
= 𝒘𝑖𝑗 𝑇 𝝓 𝑗 𝑡 , 𝛽𝑗 𝑡 = 𝜸 𝑗 𝑇 𝝓 𝑗 𝑡 • 関数線形モデルは次のように変形される 𝑦𝑖 = 𝛽0 + 𝑗=1 𝑝 න 𝑇 𝑥𝑖𝑗 𝑡 𝛽𝑗 𝑡 𝑑𝑡 + 𝜀𝑖 = 𝛽0 + 𝒛𝑖 𝑇 𝜸 + 𝜀𝑖 𝒛𝑖 = 𝒘𝑖1 𝑇 Φ1, … , 𝒘𝑖𝑝 𝑇 Φ 𝑝 𝑇 , Φ𝑗 = න 𝑇 𝝓 𝑗 𝑡 𝝓 𝑗 𝑡 𝑇 𝑑𝑡, 𝜸 = 𝜸1 𝑇 , … , 𝜸 𝑝 𝑇 𝑇 • 第 𝑗 説明変数に関連するベクトル𝒘𝑖𝑗 𝑇 Φ𝑗に対応する係数はベクトル𝜸 𝑗 • スパース推定で変数選択を行う( 𝛽𝑗(𝑡) ≡ 0 と推定する)ためには ベクトル𝜸 𝑗のすべての要素を0に縮小する必要がある 83
84.
関数線形モデルに対するスパース推定 • 次の正則化誤差2乗和の最小化によりパラメータを推定 1 𝑛 𝑖=1 𝑛 𝑦𝑖 −
(𝛽0+𝒛𝑖 𝑇 𝜸) 2 + 𝜆 𝑗=1 𝑝 𝜸 𝑗 2 ⋅ 2:𝐿2ノルム • 第2項はGroup lasso制約(Yuan & Lin, 2006, JRSSB)に対応 各 𝑗 に対して,𝜸 𝑗のすべての要素が0か非0と推定される ⇒ 変数選択 • スパース制約に基づく正則化推定量を解析的に導出することは 一般的には困難なので,反復計算が用いられる – 局所2次近似 (LQA) – 座標降下法 (CD) – 交互方向乗数法 (ADMM) 84
85.
関数線形モデルのドメイン選択 • 関数データの説明変数が1つだけの場合でもスパース推定は用いられる • 目的変数𝑌に影響を与えている説明変数𝑋(𝑡)は一部の時点のみと 考えられている場合,その時点を選択する問題を考える(ドメイン選択) •
スパース推定等を適用して 𝛽(𝑡)の一部の区間を0と推定することで ドメイン選択が行われる • 関数線形モデル 𝑦𝑖 = 𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + 𝜀𝑖 に対して係数関数が右図下のように 推定された場合,気温(𝑋(𝑡))が𝑌に 影響を与えているのは4月と11月だけと 解釈できる 85 𝑋(𝑡) 𝛽1(𝑡)(最小2乗) 𝛽1(𝑡)(James et al., 2009) James et al. (2009, Ann. Statist) Picheny et al. (2018, Stat. Comput.)
86.
関数線形モデルの拡張:交互作用モデル • 関数線形モデルを2次回帰モデルへ拡張することもできる 𝑦𝑖 =
𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + ඵ 𝑇 𝑥𝑖 𝑠 𝑥𝑖 𝑡 𝛽2 𝑠, 𝑡 𝑑𝑠𝑑𝑡 + 𝜀𝑖 • 関数データの場合,単なる2次の項ではなく 2時点間の交互作用まで考慮に入れたモデルを構築できる • これにより,回帰係数𝛽2は𝑠, 𝑡の2変数関数(曲面)となる • 説明変数が複数の場合や,高次の多項式(交互作用)まで含めたモデルも 同様の枠組みで構築可能 86 Yao & Müller (2010, Biometrika) 𝑦𝑖 = 𝛽0 + 𝑗=1 𝑝 න 𝑇 𝑥𝑖𝑗 𝑡 𝛽𝑗 𝑡 𝑑𝑡 + 𝑗,𝑘 ඵ 𝑇 𝑥𝑖𝑗 𝑠 𝑥𝑖𝑘 𝑡 𝛽𝑗𝑘 𝑠, 𝑡 𝑑𝑠𝑑𝑡 + 𝑗,𝑘,𝑙 ම 𝑇 𝑥𝑖𝑗 𝑠 𝑥𝑖𝑘 𝑡 𝑥𝑖𝑙 𝑢 𝛽𝑗𝑘𝑙 𝑠, 𝑡, 𝑢 𝑑𝑠𝑑𝑡𝑑𝑢 + 𝜀𝑖
87.
関数線形モデルの拡張:関数加法モデル • 関数線形モデル 𝑦𝑖 =
𝛽0 + න 𝑇 𝑥𝑖 𝑡 𝛽1 𝑡 𝑑𝑡 + 𝜀𝑖 は 𝑡 の各点ではあくまで線形モデル • 基底関数展開𝑥𝑖 𝑡 = 𝒘𝑖 𝑇 𝝓 𝑡 の係数ベクトル𝒘𝑖 = 𝑤𝑖1, … , 𝑤𝑖𝑚 𝑇の要素 それぞれに対して非線形関数 𝑓𝑘 を施すことで より柔軟な関数加法モデルが構築できる 𝑦𝑖 = 𝛽0 + 𝑘=1 𝑚 𝑓𝑘 𝑤𝑖𝑘 + 𝜀𝑖 • 𝑓𝑘は基底関数展開やノンパラメトリック法などにより推定 87 Müller & Yao (2008, JASA)
88.
関数回帰モデル ① スカラー-関数型回帰モデル ② 関数-スカラー型回帰モデル ③
関数-関数型回帰モデルその1 ④ 関数-関数型回帰モデルその2 88 𝑌 𝑋 スカラー 関数 スカラー ① 関数 ② ③・ ④ 今ここ
89.
②関数-スカラー線形モデル • 説明変数がスカラーデータ,目的変数が関数データで与えられたモデル • 説明変数のデータを𝑥𝑖,目的変数のデータを𝑦𝑖
𝑡 とおくと 関数線形モデルは次で与えられる 𝑦𝑖 𝑡 = 𝑥𝑖 𝛽1 𝑡 + 𝜀𝑖 𝑡 𝛽1 𝑡 :回帰係数関数, 𝜀𝑖:誤差 • ここでは簡単のため, 𝑦𝑖 𝑡 は中心化されていると仮定( σ𝑖=1 𝑛 𝑦𝑖 𝑡 = 0 ) (こうすることで,切片に対応する項を除外) • 目的変数𝑦𝑖 𝑡 の𝑡による変動を,係数関数𝛽1 𝑡 で定量化する • R package ”fda”の”fRegress”関数,”refund”の”fosr”関数で実行可能 89 Ramsay & Silverman (2005) Kokoszka & Reimherr (2017)
90.
基底関数展開 • スカラー-関数型線形モデルの推定と同様,𝑦𝑖 𝑡
は基底関数展開によって 表されると仮定 𝑦𝑖 𝑡 = 𝑙=1 𝑚 𝑦 𝑣𝑖𝑙 𝜓𝑙 𝑡 = 𝒗𝑖 𝑇 𝝍 𝑡 𝒗𝑖 = 𝑣𝑖1, … , 𝑣𝑖𝑚 𝑦 𝑇 , 𝝍 𝑡 = 𝜓1 𝑡 , … , 𝜓 𝑚 𝑦 𝑡 𝑇 • さらに,𝛽1 𝑡 も基底関数展開によって表されると仮定 𝛽1 𝑡 = 𝑙=1 𝑚 𝑦 𝑏𝑙 𝜓𝑙 𝑡 = 𝒃 𝑇 𝝍 𝑡 𝒃 = 𝑏1, … , 𝑏 𝑚 𝑦 𝑇 90
91.
回帰係数の推定 • 次の積分2乗誤差の最小化によって,パラメータベクトル𝒃を推定 min 𝛽1 𝑖=1 𝑛 න 𝑦𝑖
𝑡 − 𝑥𝑖 𝛽1 𝑡 2 𝑑𝑡 = min 𝒃 න 𝑉𝝍 𝑡 − 𝒙𝒃 𝑇 𝝍 𝑡 2 𝑑𝑡 𝑉 = 𝑣𝑖𝑙 𝑖𝑙, 𝒙 = 𝑥1, … , 𝑥 𝑛 𝑇 • これを𝒃について解くことで,次の推定量を得る 𝒃 = 𝒙 𝑇 𝒙𝛹 −1 𝛹𝑉 𝑇 𝒙 = 𝑍 𝑇 𝑍 −1 𝑍 𝑇 vec𝑉 𝑇 𝑍 = 𝒙 ⊗ 𝛹 1 2, ⊗ :クロネッカー積, 𝛹 = න𝝍 𝑡 𝝍 𝑡 𝑇 𝑑𝑡 𝛹 1 2 𝛹 1 2 = 𝛹, vec𝑉 𝑇 = 𝑣11, 𝑣12, … , 𝑣 𝑛𝑚 𝑦 𝑇 91
92.
適用例 • 気温が計測されているカナダの都市は 4つの地域に分類されている (Arctic, Atlantic,
Continental, Pacific) • 4地域を示す2値変数を説明変数𝑥𝑖𝑗 𝑗 = 1,2,3,4 , 気温の関数データを目的変数𝑦𝑖 𝑡 として 次の関数線形モデルを仮定 𝑦𝑖 𝑡 = 𝑗=1 4 𝑥𝑖𝑗 𝛽𝑗 𝑡 + 𝜀𝑖 𝑡 • 推定曲線 መ𝛽𝑗 𝑡 は,全都市の平均気温と比べて その地域がどの程度暖かいか/涼しいかを 定量化している 92 地域ごとに色分けされた気温データ 𝛽𝑗 𝑡 の推定値
93.
一般化線形モデルへの拡張 • 目的変数に対応する経時データが2値や計数の 場合,目的変数を直接基底関数展開で表現する ことは不適切 • 1つの方法として,𝑡
の離散時点で モデル化するものが考えられている • 𝑡の各点それぞれに対して,スカラーデータに 対する一般化線形モデルを仮定 𝜂𝑖 𝑡 = 𝑔 𝐸 𝑌𝑖 𝑡 = 𝛽0 𝑡 + 𝑥𝑖 𝛽1 𝑡 • 𝛽0 𝑡 や𝛽1 𝑡 の推定時に,これらは 𝑡 に関して 滑らかという制約をおく • R package “refund”のpffr関数で実行可能 93 2値経時データ(目的変数)の例 Ivanescu et al. (2015, Comput. Statist.) Kokoszka & Reimherr (2017)
94.
数値例 • 次の関係により経時2値変数である目的変数𝑦𝑖を生成 𝑧𝑖 𝑡𝑖𝛼
= 𝛽0 𝑡𝑖𝛼 + 𝑥𝑖 𝛽1 𝑡𝑖𝛼 + 𝜀𝑖 𝑡𝑖𝛼 , 𝑦𝑖 𝑡𝑖𝛼 = 𝐼 𝑧 𝑡𝑖𝛼 > 0 , 𝛽0 𝑡 = cos 𝜋𝑡 + 𝜋 , 𝛽1 𝑡 = 2𝑡 𝜺𝑖 𝒕𝑖 = 𝜀𝑖 𝑡𝑖1 , … , 𝜀𝑖 𝑡𝑖,50 𝑇 ∼ 𝑁 0, 𝐾 • 𝑦𝑖 𝑡𝑖𝛼 と𝑥𝑖に対して関数一般化線形モデル (logit link) 𝑔 𝐸 𝑦𝑖 𝑡 = 𝛽0 𝑡 + 𝑥𝑖 𝛽1 𝑡 を仮定することで, 𝛽0 𝑡 と𝛽1 𝑡 を右図のように 推定できる 94 𝑖 = 1, … , 200 𝛼 = 1, … , 50 𝐾:Matern kernel መ𝛽0 𝑡 መ𝛽1 𝑡 𝛽0 𝑡 と𝛽1 𝑡 の推定値(実線)と その各点信頼区間 1点鎖線は真の曲線を表す
95.
関数回帰モデル ① スカラー-関数型回帰モデル ② 関数-スカラー型回帰モデル ③
関数-関数型回帰モデルその1 ④ 関数-関数型回帰モデルその2 95 𝑌 𝑋 スカラー 関数 スカラー ① 関数 ② ③・ ④ 今ここ
96.
③ 関数-関数線形モデルその1 • 説明変数と目的変数が共に関数データで与えられたモデル •
説明変数のデータを𝑥𝑖 𝑠 ,目的変数のデータを𝑦𝑖 𝑡 とおく これらは中心化されているとする (σ𝑖=1 𝑛 𝑥𝑖 𝑠 = 0, σ𝑖=1 𝑛 𝑦𝑖 𝑡 = 0) • 𝑥𝑖 𝑠 と𝑦𝑖 𝑡 との関係を表す関数線形モデルは次で与えられる 𝑦𝑖 𝑡 = න 𝑇 𝑥𝑖 𝑠 𝛽1 𝑠, 𝑡 𝑑𝑠 + 𝜀𝑖 𝑡 𝛽1 𝑠, 𝑡 :回帰係数関数, 𝜀𝑖 𝑡 :誤差関数 • 𝑥𝑖 𝑠 と𝑦𝑖 𝑡 の異なる時点𝑠, 𝑡における関係をモデル化しており 係数関数は2変数関数(曲面)で与えられる 96 Ramsay & Dalzell (1991) Ramsay & Silverman (2005)
97.
基底関数展開 • 𝑥𝑖 𝑠
と𝑦𝑖 𝑡 はそれぞれ基底関数展開で表されると仮定 𝑥𝑖 𝑠 = 𝑘=1 𝑚 𝑥 𝑤𝑖𝑘 𝜙 𝑘 𝑠 = 𝒘𝑖 𝑇 𝝓 𝑠 , 𝑦𝑖 𝑡 = 𝑙=1 𝑚 𝑦 𝑣𝑖𝑙 𝜓𝑙 𝑡 = 𝒗𝑖 𝑇 𝝍 𝑡 𝒘𝑖 = 𝑤𝑖1, … , 𝑤𝑖𝑚 𝑥 𝑇 , 𝝓 𝑠 = 𝜙1 𝑠 , … , 𝜙 𝑚 𝑦 𝑠 𝑇 𝒗𝑖 = 𝑣𝑖1, … , 𝑣𝑖𝑚 𝑦 𝑇 , 𝝍 𝑡 = 𝜓1 𝑡 , … , 𝜓 𝑚 𝑦 𝑡 𝑇 • さらに, 𝛽1 𝑠, 𝑡 は次のように表されると仮定 𝛽1 𝑠, 𝑡 = 𝑘=1 𝑚 𝑥 𝑙=1 𝑚 𝑦 𝑏 𝑘𝑙 𝜙 𝑘 𝑠 𝜓𝑙 𝑡 = 𝝓 𝑠 𝑇 𝐵𝝍 𝑡 (𝐵 = 𝑏 𝑘𝑙 𝑘𝑙:パラメータ) 97
98.
回帰係数の推定 • 次の積分2乗誤差の最小化によってパラメータベクトル𝒃を推定 min 𝛽1 𝑖=1 𝑛 න 𝑦𝑖
𝑡 − න 𝑇 𝑥𝑖 𝑠 𝛽1 𝑠, 𝑡 𝑑𝑠 2 𝑑𝑡 = min 𝐵 𝑖=1 𝑛 න 𝒗𝑖 𝑇 − 𝒘𝑖 𝑇 Φ𝐵 𝜓 𝑡 𝜓 𝑡 𝑇 𝒗𝑖 𝑇 − 𝒘𝑖 𝑇 Φ𝐵 𝑑𝑡 = tr 𝑉 − 𝑍𝐵 Ψ 𝑉 − 𝑍𝐵 𝑇 𝑉 = 𝑣𝑖𝑙 𝑖𝑙, 𝑍 = 𝒛1, … , 𝒛 𝑛 𝑇, 𝑧𝑖 = Φ𝒘𝑖 Φ = 𝝓 𝑠 𝝓 𝑠 𝑇 𝑑𝑠, Ψ = 𝝍 𝑡 𝝍 𝑡 𝑇 𝑑𝑡 • これを𝐵について解くことで,次の推定量を得る vec 𝐵 = Ψ ⊗ 𝑍 𝑇 𝑍 −1vec(𝑍 𝑇 𝑉Ψ) 98
99.
適用例:カナダの気温データ • データ: カナダの35都市で計測された気温と降水量 • 日別平均気温(365時点)を説明変数𝑥𝑖
𝑠 , 今度は日別平均降水量(の対数)を 目的変数𝑦𝑖 𝑡 として扱う • 次の関数線形モデルを想定し 𝛽1 𝑠, 𝑡 の推定値を導出する 𝑦𝑖 𝑡 = 𝛽0 𝑡 + න 𝑇 𝑥𝑖 𝑠 𝛽1 𝑠, 𝑡 𝑑𝑠 + 𝜀𝑖 𝑡 99 35都市の気温変化 35都市の降水量変化
100.
結果 • 係数曲面𝛽1 𝑠,
𝑡 の推定値より 「異なる時点𝑠, 𝑡における」 𝑥𝑖 𝑠 の𝑦𝑖 𝑡 への寄与を見ることができる • 右下の図の場合,ほぼ1年を通して気温は 12月頃の降水量に正の影響を与えており, 逆に10月頃の降水量に負の影響を与えて いると解釈できる 100 𝛽0 𝑡 (定数関数)の推定値 𝛽1 𝑠, 𝑡 の推定値
101.
関数-関数線形モデル使用の注意点 𝑦𝑖 𝑡 =
න 𝑇 𝑥𝑖 𝑠 𝛽1 𝑠, 𝑡 𝑑𝑠 + 𝜀𝑖 𝑡 • このモデルは「時点𝑠での説明変数の,時点𝑡での 目的変数への寄与」を表したものだった • 時間の関数データを扱う場合, 𝑠 > 𝑡だと「未来の 説明変数が過去の目的変数に寄与している」という 矛盾した関係を説明してしまうことになる – 例外として周期的なデータであればOK 「12月の気温→翌1月の降水量」のような 解釈が可能なため – 時間以外の関数データであればOK 101 𝑡 𝑠𝛽1 𝑠, 𝑡 の定義域
102.
Historical functional linear
model • 目的変数𝑦𝑖 𝑡 と,そこから一定期間遡った時点での 説明変数𝑥𝑖 𝑠 との関係を表した次のモデルが 用いられる 𝑦𝑖 𝑡 = න 𝑡−𝛿 𝑡 𝑥𝑖 𝑠 𝛽1 𝑠, 𝑡 𝑑𝑠 + 𝜀𝑖 𝑡 • 𝛿 > 0 は,どこまで遡るかを規定するパラメータ • 𝛽1 𝑠, 𝑡 の定義域が複雑になるため前述の推定法を 直接適用することは困難で,さまざまなアプローチ が考えられている – 有限要素法 (Malfait & Ramsay, 2003) – 変化係数モデル (Şentürk & Müller, 2010, JASA) – Boosting (Brockhaus et al., 2017, Statist. Comput.) 102 Malfait & Ramsay (2003, Canad. J. Statist) 𝛿 𝑡 𝑠𝛽1 𝑠, 𝑡 の定義域
103.
関数回帰モデル ① スカラー-関数型回帰モデル ② 関数-スカラー型回帰モデル ③
関数-関数型回帰モデルその1 ④ 関数-関数型回帰モデルその2 103 𝑌 𝑋 スカラー 関数 スカラー ① 関数 ② ③・ ④ 今ここ
104.
④ 関数-関数線形モデルその2 • 説明変数と目的変数が共に関数データで与えられたモデル •
説明変数のデータを𝑥𝑖 𝑡 ,目的変数のデータを𝑦𝑖 𝑡 とおくと 関数線形モデルは次で与えられる 𝑦𝑖 𝑡 = 𝑥𝑖 𝑡 𝛽1 𝑡 + 𝜀𝑖 𝑡 𝛽1 𝑡 :回帰係数関数, 𝜀𝑖:誤差 • 説明変数𝑥𝑖 𝑡 の時点𝑡における「その時点のみの」目的変数𝑦𝑖 𝑡 への 影響の仕方をモデル化していることから,関数同時モデル (Functional concurrent model)とよばれている 104 Ramsay & Silverman (2005)
105.
回帰係数の推定 • 回帰係数𝛽1 𝑡
は基底関数展開により表されると仮定 𝛽1 𝑡 = 𝒃 𝑇 𝝍 𝑡 𝒃 = 𝑏1, … , 𝑏 𝑚 𝑇, 𝝍 𝑡 = 𝜓1 𝑡 , … , 𝜓 𝑚 𝑡 • 関数-スカラー型モデルと同様に,次の積分2乗誤差の最小化によって パラメータベクトル𝒃を推定 𝑖=1 𝑛 න 𝑦𝑖 𝑡 − 𝑥𝑖 𝑡 𝛽1 𝑡 2 𝑑𝑡 = න 𝒚 𝑡 − 𝒙 𝑡 𝝍 𝑇 𝑡 𝒃 2 𝑑𝑡 𝒚 𝑡 = 𝑦1 𝑡 , … , 𝑦𝑛 𝑡 𝑇 , 𝒙 𝑡 = 𝑥1 𝑡 , … , 𝑥 𝑛 𝑡 𝑇 105
106.
回帰係数の推定 min 𝒃 න 𝒚 𝑡
− 𝒙 𝑡 𝝍 𝑇 𝑡 𝒃 2 𝑑𝑡 • この最小解は,次の正規方程式を解くことで得られる න𝝍 𝑡 𝒙 𝑇 𝑡 𝒙 𝑡 𝝍 𝑇 𝑡 𝑑𝑡 𝒃 = න𝝍 𝑡 𝒙 𝑇 𝑡 𝒚 𝑡 𝑑𝑡 • 説明変数や目的変数に対して基底関数展開の仮定をおいても 係数の推定量を解析的に導出することは困難 • 積分を数値的に計算することで近似的に推定量を得る方法が 用いられている • R package ”fda”の”fRegress”関数で実行可能 106
107.
(少し脱線)変化係数モデル • ②と④のモデル 𝑦𝑖 𝑡
= 𝑥𝑖 𝛽1 𝑡 + 𝜀𝑖 𝑡 𝑦𝑖 𝑡 = 𝑥𝑖 𝑡 𝛽1 𝑡 + 𝜀𝑖 𝑡 について,ここでは𝑦𝑖 𝑡 や𝑥𝑖 𝑡 を関数データとして扱ったが 経時測定データを直接分析対象とする方法も考えられている.例えば, – 混合効果モデル (Mixed-effect model) – 変化係数モデル (Varying-coefficient model) • 経時測定データからなる説明変数,目的変数間の関係を表す変化係数モデル は次で与えられる(Hastie & Tibshirani, 1993, JRSSB; Hoover et al., 1998, Biometrika) 𝑦𝑖𝑗 = 𝑥𝑖𝑗 𝛽1 𝑡𝑖𝑗 + 𝜀𝑖𝑗 𝑖 = 1, … , 𝑛:個体番号; 𝑗 = 1, … , 𝑛𝑖:時点番号; 𝜀𝑖𝑗 ∼𝑖𝑖𝑑 𝑁 0, 𝜎2 107
108.
変化係数モデルの推定 𝑦𝑖𝑗 = 𝑥𝑖𝑗
𝛽1 𝑡𝑖𝑗 + 𝜀𝑖𝑗 • 回帰係数𝛽1 𝑡 は,基底関数展開により表されると仮定 𝛽1 𝑡 = 𝜸 𝑇 𝝓 𝑡 𝜸 = 𝛾1, … , 𝛾 𝑚 𝑇, 𝝓 𝑡 = 𝜙1 𝑡 , … , 𝜙 𝑚 𝑡 𝑇 • これにより変化係数モデルは次で表される 𝑦𝑖𝑗 = 𝑥𝑖𝑗 𝝓 𝑡𝑖𝑗 𝑇 𝜸 + 𝜀𝑖𝑗 • パラメータベクトル 𝜸 を最小2乗法や正則化法等で推定することで 回帰係数関数の推定値 መ𝛽1 𝑡 = ෝ𝜸 𝑇 𝝓 𝑡 を得る • 時点数 𝑛𝑖 が多い場合は高次元データになる 説明変数が複数ある場合は,backfitting algorithmを用いて推定される 108
109.
ここまでのまとめ • 説明変数と目的変数のいずれか,または両方が関数データとして与えられた 回帰モデルと,その推定方法を紹介 • 回帰係数も関数として与えられ,影響度の経時的な変化を定量化できる •
目的変数がスカラーの場合は,様々なモデルへの拡張が容易 • 目的変数が関数の場合は,積分2乗誤差最小化に基づく推定法が多い 109 目的変数 説明変数 スカラー 関数 スカラー 𝑌 = 𝑋𝛽 + 𝜀 𝑌 = 𝑋 𝑡 𝛽 𝑡 𝑑𝑡 + 𝜀 関数 𝑌 𝑡 = 𝑋𝛽 𝑡 + 𝜀 t 𝑌 𝑡 = 𝑋 𝑡 𝛽 𝑡 + 𝜀 𝑡 𝑌 𝑡 = 𝑋 𝑠 𝛽 𝑠, 𝑡 𝑑𝑠 + 𝜀 𝑡
110.
目次 • 関数データ解析の概要 • 関数回帰分析 •
適用例とその他の関数データ解析手法 – 関数データ判別に基づく遺伝子データ解析 – 関数クラスタリング – 関数時系列解析 – 関数空間データ分析 110
111.
Motivating example • 経時測定遺伝子発現データ: 多発性硬化症患者に対してInterferon
β治療を 行った際の遺伝子発現量の推移を測定したデータ (Baranzini et al., 2004, PLoS Biology) 個体:53名の多発性硬化症患者 うち33名:Interferon βに対する予後良好群(黒) 20名: 〃 予後不良群(赤) 変数:免疫系に関わる76遺伝子 時点:4~7時点/患者 (治療開始後 0,3,6,9,12,18,24ヶ月後) • 目的: 予後良好群および予後不良群とで 発現量の経時変化に差異がある遺伝子を選択 遺伝子データの一例 3 Kayano, Matsui et al. (2016, Biostatistics)
112.
データ形式 112 Gene Patient 𝑝 = 76個 𝑛
= 53名 1人目 2人目(𝑛1 = 5時点) (𝑛2 = 7時点)
113.
データの関数化(1) • 遺伝子発現データの計測時点数は4~7のため,患者それぞれに対して関数化を 行っても適切な曲線が得られない可能性が高い • 各遺伝子・各群に対してランク縮小混合効果モデル (reduced-rank
mixed effects model)を用いて関数化を行う (R package “fpca”) • このモデルを推定することで,全患者の情報を利用して関数データ 𝑥1 𝑡 , … , 𝑥 𝑛 𝑡 を得ることができる 113 James et al., (2000, Biometrika) Peng & Paul (2009, J. Comput. Graph. Stat.) 𝑖 = 1, … , 𝑛 :個体 𝛼 = 1, … , 𝑛𝑖 :時点 𝑥𝑖𝑘 = 𝜇 𝑡𝑖𝑘 + 𝑟=1 𝑞 𝜉 𝑟 𝑡𝑖𝑘 𝛼𝑖𝑟 + 𝜀𝑖𝑘 𝜀𝑖𝑘 ∼𝑖𝑖𝑑 𝑁(0, 𝜎2) න𝜉 𝑟 𝑡 𝜉𝑠 𝑡 𝑑𝑡 = 𝛿 𝑟𝑠, 𝛼𝑖𝑟 ∼𝑖𝑖𝑑 𝑁 0, 𝑑 𝑟 , 𝑑1 ≥ ⋯ ≥ 𝑑 𝑞 ≥ 0
114.
データの関数化(2) • ランク縮小混合効果モデル 𝑥𝑖𝑘 =
𝜇 𝑡𝑖𝑘 + 𝑟=1 𝑞 𝜉 𝑟 𝑡𝑖𝑘 𝛼𝑖𝑟 + 𝜀𝑖𝑘 の𝜇 𝑡 ,𝜉 𝑟 𝑡 に対してそれぞれ基底関数の仮定をおき パラメータを推定することで,関数データが得られる 114 𝑟 = 1, … , 𝑞 𝜙1 𝑡 , … , 𝜙 𝑀 𝑡 : 正規直交基底 関数データ 𝜃𝑟𝑚 (𝜇) , 𝜃𝑟𝑚, 𝑑 𝑟, 𝜎2を推定 𝜇 𝑡 = 𝑚=1 𝑀 𝜃 𝑚 𝜇 𝜙 𝑚 𝑡 𝜉 𝑟 𝑡 = 𝑚=1 𝑀 𝜃𝑟𝑚 𝜙 𝑚 𝑡 𝑥𝑖 𝑡 = 𝑚=1 𝑀 𝑤𝑖𝑚 𝜙 𝑚 𝑡 James et al., (2000, Biometrika) Peng & Paul (2009, J. Comput. Graph. Stat.)
115.
関数判別モデル • 関数ロジスティック回帰モデル (James, 2002,
JRSSB; Matsui et al., 2011, J. Classification.) 115 𝛽0𝑙:定数項 𝛽𝑗𝑙 𝑡 :係数関数 Pr 𝑔𝑖 = 𝑙 𝒙𝑖 :データ𝒙𝑖が𝑙群に判別される確率 • データ ・・・𝑙群と𝐿群への判別確率の対数オッズを関数線形モデルで表現 𝑝:変数(遺伝子)数𝒙𝑖(𝑡) = 𝑥𝑖1 𝑡 , … , 𝑥𝑖𝑝 𝑡 𝑇 :特徴量 𝑔𝑖 ∈ 1, … , 𝐿 :データ𝒙𝑖のクラスラベル log Pr 𝑔𝑖 = 𝑙 𝒙𝑖 Pr 𝑔𝑖 = 𝐿 𝒙𝑖 = 𝛽0𝑙 + 𝑗=1 𝑝 න𝑥𝑖𝑗 𝑡 𝛽𝑗𝑙 𝑡 𝑑𝑡
116.
基底関数展開によるモデル変形 • 説明変数と係数関数を基底関数展開により表現 116 パラメータ: :基底関数 :既知
:未知パラメータ 𝑥𝑖𝑗 𝑡 = 𝒘𝑖𝑗 𝑇 𝝓 𝑗 𝑡 𝛽𝑗𝑙 𝑡 = 𝒃𝑗𝑙 𝑇 𝝓 𝑗 𝑡 log 𝜋𝑙 𝒙𝑖; 𝒃 𝜋 𝐿 𝒙𝑖; 𝒃 = 𝛽0𝑙 + 𝑗=1 𝑝 𝑤𝑖𝑗 𝑇 Φ𝑗 𝒃𝑗𝑙 = 𝑗=1 𝑝 𝒛𝑖𝑗 𝑇 𝒃𝑗𝑙 𝜋𝑙 𝒙𝑖; 𝒃 = Pr 𝑔𝑖 = 𝑙 𝒙𝑖 , Φ𝑗 = න𝝓 𝑗 𝑡 𝝓 𝑗 𝑇 𝑡 𝑑𝑡, 𝒛𝑖𝑗 = Φ𝑗 𝒘𝑖𝑗
117.
推定方式 • ラベル変数を次で定義 117 • 確率関数(多項分布モデル) •
正則化最尤推定 𝑓 𝒚𝑖 𝒙𝑖; 𝒃 = ෑ 𝑙=1 𝐿−1 𝜋𝑙 𝒙𝑖; 𝑏 𝑦 𝑖𝑙 𝜋 𝐿 𝒙𝑖; 𝑏 1−σℎ=1 𝐿−1 𝑦 𝑖ℎ 𝒚𝑖 = 𝑦𝑖1, … , 𝑦𝑖,𝐿−1 𝑇 = ൝ 0, … , 0,1,0, … , 0 𝑇 𝑖𝑓 𝑔𝑖 = 𝑙 𝑙 = 1, … , 𝐿 − 1 0, … , 0 𝑇 𝑖𝑓 𝑔𝑖 = 𝐿 𝒃 = argmax 𝒃 ℓ 𝜆 𝒃 ℓ 𝜆 𝒃 = 𝑖=1 𝑛 𝑓 𝒚𝑖 𝒙𝑖; 𝒃 − 𝑛𝑃 𝜆,𝛼 𝒃
118.
スパース正則化 (Sparse regularization) •
Group elastic net型制約 (Zou & Hastie, 2005; Yuan & Lin, 2006) 13 :調整パラメータ :正則化パラメータ • Elastic netは互いの相関が高い変数同士をまとめて取捨選択する性質を持つ • 変数選択を行うには のパラメータをまとめて0に縮小する必要がある Group lasso を適用 𝑃 𝜆,𝛼 𝒃 = 1 2 1 − 𝛼 𝑗=1 𝑝 𝜆𝑗 𝑙=1 𝐿−1 𝒃𝑗𝑙 2 2 + 𝛼 𝑗=1 𝑝 𝜆𝑗 𝑙=1 𝐿−1 𝒃𝑗𝑙 2 2 1/2
119.
遺伝子発現データ解析への適用 • データ(再掲): 多発性硬化症患者に対してInterferon β治療を 行った際の遺伝子発現量の推移を測定したデータ (Baranzini
et al., 2004, PLoS Biology) 個体:53名の多発性硬化症患者 うち33名:Interferon βに対する予後良好群(黒) 20名: 〃 予後不良群(赤) 変数:免疫系に関わる76遺伝子 時点:4~7時点/患者 (治療開始後 0,3,6,9,12,18,24ヶ月後) • 目的: 予後良好群および予後不良群とで 発現量の経時変化に差異がある遺伝子を選択 14 遺伝子データの一例
120.
分析の流れ • ランク縮小混合効果モデルを用いて 予後良好群、予後不良群それぞれに対して 経時測定データを関数化 • 得られた関数データに基づき関数ロジスティック回帰モデルを適用 正則化項に含まれる正則化パラメータ・調整パラメータの値は CVで選択 •
係数が非零と推定された遺伝子を選択 120
121.
選択結果 • 76個中48個が選択された • 係数のノルムが大きい順にランキング(下表) 121 Gene:遺伝子名 ||𝒃𝑗1 ∗ ||:ロジスティック回帰係数のノルム 𝑝-value:関数ANOVAのp値 (Minas
et al., 2011,Bioinformatics) ||𝒃𝑗1 ∗ ||
122.
遺伝子の考察 • 解析に用いた76遺伝子中、48遺伝子が選択 • 28遺伝子は係数関数が
と推定 • IRF8:係数のノルムでは4番目にランク 先行研究(関数ANOVA)では有意でなかった (選択されなかった) • 予後良好群でのみ半年後,2年後で 平均曲線がわずかに高発現している • IRF8は生物学的観点から 多発性硬化症に関する 新しいターゲットとして報告されている (de Jager et al., 2009, Nature genetics) 122 0 5 10 15 20 3.23.64.04.4 time IRF8 0 5 10 15 20 3.23.64.04.4 time IRF8 p= 0.0059 係数関数の推定量 IRF8の発現量 Good responder Poor responder (28遺伝子)(IRF8)
123.
目次 • 関数データ解析の概要 • 関数回帰分析 •
適用例とその他の関数データ解析手法 – 関数データ判別に基づく遺伝子データ解析 – 関数クラスタリング – 関数時系列解析 – 関数空間データ分析 123
124.
Motivating example 世界の気象データ • 1年間で経時的に測定された 世界の96都市の気象データ (気象庁から取得可能) •
気温や降水量の年間推移は さまざまなパターンをもつ (熱帯・亜熱帯・温帯・亜寒帯・寒帯) • 気象パターンに基づいて 都市を分類したい 124
125.
関数データクラスタリング • 関数データを,各観測間の距離に応じてクラスタリングするための方法 • 関数データ間の距離は関数空間上のノルムによって定められる 特に,𝐿2距離が用いられることが多い 𝑥𝑖
𝑡 − 𝑥𝑗 𝑡 𝐿2 2 = න 𝑇 𝑥𝑖 𝑡 − 𝑥𝑗 𝑡 2 𝑑𝑡 • 距離を求めることができれば,多変量データに対するものと同様の方法で クラスタリングを行うことができる 125
126.
関数データの距離(1) • 関数データが基底関数展開によって𝑥𝑖 𝑡
= 𝒘𝑖 𝑇 𝝓 𝑡 と表されると仮定すると, 𝐿2距離は次で表される 𝑥𝑖 𝑡 − 𝑥𝑗 𝑡 𝐿2 2 = න 𝑇 𝑥𝑖 𝑡 − 𝑥𝑗 𝑡 2 𝑑𝑡 = 𝒘𝑖 − 𝒘𝑗 𝑇 න 𝑇 𝝓 𝑡 𝝓 𝑡 𝑇 𝑑𝑡 𝒘𝑖 − 𝒘𝑗 = 𝒘𝑖 − 𝒘𝑗 𝑇 Φ 𝒘𝑖 − 𝒘𝑗 Φ = න 𝑇 𝝓 𝑡 𝝓 𝑡 𝑇 𝑑𝑡 • 関数データ𝑥𝑖 𝑡 の代わりに,基底関数展開の係数𝒘𝑖をクラスタリングの 対象とすれば,多変量データに対するクラスタリングを適用すればよい • しかし, Φのために,一般的に 𝑥𝑖 𝑡 − 𝑥𝑗 𝑡 𝐿2 ≠ 𝒘𝑖 − 𝒘𝑗 2 つまり距離が保持されず, 𝒘𝑖を直接クラスタリング対象にすることは不適切 (基底関数𝝓 𝑡 が正規直交ならば,𝒘𝑖を直接用いてよい) 126
127.
関数データの距離(2) • 行列Φは(ほとんどの基底関数に対して)正定値対称行列なので, 正則な上三角行列𝑈を用いてコレスキー分解Φ =
𝑈 𝑇 𝑈を適用できる • この行列𝑈を用いて𝒘𝑖 = 𝑈𝒘𝑖とおくと 𝑥𝑖 𝑡 − 𝑥𝑗 𝑡 𝐿2 2 = 𝒘𝑖 − 𝒘𝑗 𝑇 Φ 𝒘𝑖 − 𝒘𝑗 = 𝒘𝑖 − 𝒘𝑗 𝑇 𝑈 𝑇 𝑈 𝒘𝑖 − 𝒘𝑗 = 𝒘𝑖 − 𝒘𝑗 𝑇 𝒘𝑖 − 𝒘𝑗 = 𝒘𝑖 − 𝒘𝑗 2 2 となるため, 𝒘𝑖を用いれば関数空間上の距離が保持できる (Kayano et al., 2010, J. Classification) • ベクトル 𝒘𝑖 𝑖 = 1, … , 𝑛 に対して,クラスタリングを適用する 127
128.
多変数関数データのクラスタリング • 気温,降水量のような,複数の(多変数の)関数データに対して クラスタリングを行うこともできる • 𝑝変数の関数データ
𝑥𝑖1 𝑡 , … , 𝑥𝑖𝑝 𝑡 が与えられたとき, それぞれを基底関数展開することで得られる係数 𝒘𝑖1, … , 𝒘𝑖𝑝 を考える • 1変量の場合と同様に,基底関数の積の積分行列Φのコレスキー分解を 用いて, 𝒘𝑖1, … , 𝒘𝑖𝑝 𝑖 = 1, … , 𝑛 をクラスタリング対象とする 128
129.
気象データへの適用 129 • 96都市の気温(𝑋1 𝑡
)・ 降水量(𝑋2 𝑡 )の経時測定 データに対して関数データ クラスタリングを適用 • 係数 𝒘𝑖1, 𝒘𝑖2 𝑖 = 1, … , 𝑛 のクラスタリングには 自己組織化マップを適用 • クラスター数5として実行 – 上図:クラスタリングの結果 – 下図:ケッペンの気候区分
130.
階層型クラスタリング • 𝒘𝑖1, 𝒘𝑖2
𝑖 = 1, … , 𝑛 に対して階層型クラスタリングを適用することで 下図のデンドログラムを描画できる • 5クラスターはおおよそ熱帯・亜熱帯・温帯・亜寒帯・寒帯に 分類されている 130
131.
目次 • 関数データ解析の概要 • 関数回帰分析 •
適用例とその他の関数データ解析手法 – 関数データ判別に基づく遺伝子データ解析 – 関数クラスタリング – 関数時系列解析 – 関数空間データ分析 131
132.
Motivating example 年別・年齢別の死亡率データ • 1時点(1年)それぞれにおいて 年齢ごとに経時的に計測されているデータ •
年代が進むにつれて、全年齢層で 死亡率は減少傾向にある • これらのデータを用いて、 未来の年における「死亡率の 年齢別推移」を予測したい 132 時代別年齢別死亡率(の対数) 赤から紫にかけて1950年~2010年のデータを表す (R package “demography”)
133.
関数時系列解析 (Functional time
series analysis) • 一般的な時系列解析では、これまでに観測された時系列データの 特徴を捉えたうえで、次の時刻の「点」の予測を行った • 関数時系列解析では、各時点でのデータ自身が経時測定データとして与えられ たとき、これら1つ1つを関数データとして扱い、 次の時点での「関数(曲線)」の予測を行う 133 𝑥1 𝑥2 𝑥3 𝑥4 𝑥5 𝑥1(𝑡) 𝑥2(𝑡) 𝑥3(𝑡) 時系列解析(左)と関数時系列解析(右)のイメージ 𝑥6 𝑥4(𝑡)
134.
関数自己回帰モデル • 平均0のランダム関数 𝑋
𝑛, −∞ < 𝑛 < ∞ に対して, 1次の関数自己回帰 (Functional AutoRegressive; FAR(1))モデルは 次で与えられる 𝑋 𝑛 = Φ 𝑋 𝑛−1 + 𝜀 𝑛 Φ:作用素,𝜀 𝑛:誤差関数 • 作用素Φとしては,主に次の積分作用素が用いられる Φ 𝑥 𝑡 = න𝜑 𝑠, 𝑡 𝑥 𝑠 𝑑𝑠 , 𝑥 ∈ 𝐿2 • これを用いると,FAR(1)モデルは次で与えられる 𝑋 𝑛 𝑡 = න𝜑 𝑠, 𝑡 𝑋 𝑛−1 𝑠 𝑑𝑠 + 𝜀 𝑛 𝑡 𝜑 𝑠, 𝑡 :係数関数, ∬ 𝜑2 𝑠, 𝑡 𝑑𝑡𝑑𝑠 < ∞ 134 Bosq (2000) Horvath & Kokoszka (2012)
135.
関数時系列解析のためのアプローチ • ARモデル以外にもARMAモデルなど,ベクトルデータに対して用いられる 時系列解析のためのモデルを,関数データの枠組みへ拡張したモデルが いくつか提唱されている (Hörmann et
al., 2013, Econom. Theory; van Delft and Eichler, 2018, Electron. J. Statist.) • FAR(1)モデルの理論的な性質については多くの研究がある(Bosq, 2000; Horvath & Kokoszka, 2012)が,実装が容易でないほか,𝑝次の関数自己回帰モデル FAR(𝑝)に関しては拡張が容易でなく研究は少ない • ここでは,データをKL展開により関数化し,その係数(主成分得点)に対して 通常の時系列解析を適用する方法(Hyndman & Ullah, 2007, CSDA)を紹介 • 元々は人口動態の分析のために提案された方法だが,広範なデータに対して 適用可能で,Rでの実装も容易に行うことができる 135
136.
Hyndman-Ullah (HU) 法 •
関数時系列データ 𝑥 𝑛 𝑡 を,次のようにKL展開表現する 𝑥 𝑛 𝑡 = Ƹ𝜇 𝑡 + 𝑙=1 𝐿 መ𝜉 𝑛𝑙 Ƹ𝜈𝑙 𝑡 ( መ𝜉 𝑛1, … , መ𝜉 𝑛𝐿:関数主成分得点, Ƹ𝜈1 𝑡 , … , Ƹ𝜈 𝐿 𝑡 :固有関数) • 係数(関数主成分得点) መ𝜉 𝑛𝑙 に対して通常の時系列解析を適用し 第 𝑛 期に対する ℎ 期先の係数 𝜉 𝑛+ℎ,𝑙 の予測値 መ𝜉 𝑛+ℎ,𝑙|𝑛,𝑙 を得る これを 𝑙 = 1, … , 𝐿 について繰り返し行う • この予測値を用いて,第 𝑛 期に対する ℎ 期先の関数データ 𝑥 𝑛+ℎ 𝑡 の 予測値 ො𝑥 𝑛+ℎ|𝑛 𝑡 を,次で与える ො𝑥 𝑛+ℎ|𝑛 𝑡 = Ƹ𝜇 𝑡 + 𝑙=1 𝐿 መ𝜉 𝑛+ℎ|𝑛,𝑙 Ƹ𝜈𝑙 𝑡 136 Hyndmann & Ullah (2007, CSDA)
137.
適用例 • 日本の年代別死亡率のデータに対して HU法を適用し,将来の死亡率を予測 • R
package “demography” “MortalitySmooth” を使用 • 各主成分得点 መ𝜉 𝑛1, … , መ𝜉 𝑛𝐿の予測には “forecast”関数使用 • KL展開を利用していることから, 各主成分の傾向(予測結果)を 見ることができる 137
138.
分析結果の図(1) • 実行の結果,次のようなグラフが得られる 138
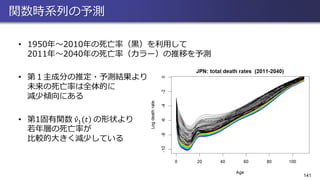
139.
分析結果の図(2) • 上図は,全関数時系列の平均関数 Ƹ𝜇
𝑡 と固有関数 Ƹ𝜈𝑙 𝑡 𝑙 = 1,2,3 を表す • 例えば第1主成分の固有関数 Ƹ𝜈1 𝑡 は,全世代における死亡率の高さ (特に若年層)を表す • 寄与率は第1~3主成分の順に96.6%,1.58%,0.82%であり 第1主成分で年ごとの変動をほぼすべて説明できている 139
140.
分析結果の図(3) • 下図は係数の推定値 መ𝜉
𝑛𝑙 と,それを時系列解析によって予測した ℎ = 30 期まで先の予測値 መ𝜉 𝑛+1|𝑛,𝑙, … , መ𝜉 𝑛+30|𝑛,𝑙を表す • 黄色は各点における95%信頼区間を表す • 第1主成分の係数は単調減少の傾向にあることから 全年代において死亡率は徐々に減少すると予測される 140 መ𝜉 𝑛+1|𝑛,1, … , መ𝜉 𝑛+30|𝑛,1 መ𝜉 𝑛+1|𝑛,2, … , መ𝜉 𝑛+30|𝑛,2 መ𝜉 𝑛+1|𝑛,3, … , መ𝜉 𝑛+30|𝑛,3
141.
関数時系列の予測 • 1950年~2010年の死亡率(黒)を利用して 2011年~2040年の死亡率(カラー)の推移を予測 • 第1主成分の推定・予測結果より 未来の死亡率は全体的に 減少傾向にある •
第1固有関数 Ƹ𝜈1 𝑡 の形状より 若年層の死亡率が 比較的大きく減少している 141
142.
HU法に関する補足 • HU法は,主成分得点(スカラー)に対して古典的な時系列解析手法を 適用できるため,容易に実装ができる上計算コストも小 • 一方で,理論的な性質は証明されていなかった •
HU法では መ𝜉 𝑛1, … , መ𝜉 𝑛𝐿 それぞれに対して独立して単変量の時系列解析手法を 適用した.つまりこれらのクロス相関を無視している • መ𝜉 𝑛1, … , መ𝜉 𝑛𝐿に対して多変量時系列解析手法を適用することで,その予測値は FAR(1)の予測値と漸近同等であることが示されている (Aue et al., 2015, JASA) 142
143.
目次 • 関数データ解析の概要 • 関数回帰分析 •
適用例とその他の関数データ解析手法 – 関数データ判別に基づく遺伝子データ解析 – 関数クラスタリング – 関数時系列解析 – 関数空間データ分析 143
144.
Motivating example カナダの各都市の気温データ • 左の図は,カナダの複数都市(右の点)で観測された,日別平均気温の 推移を表したもの •
このデータから,観測されていない都市・地点における気温の推移を 予測したい 144カナダの各都市の気温データの推移 観測地点 (赤点が未観測で,予測したい地点と想定)
145.
空間関数データ解析 (Spatial functional
data analysis) • 気温の傾向は,観測された都市の「位置」に依存していると仮定 • データが観測された地点の位置情報を利用して,別の地点での「値」ではなく 「曲線」を予測する 145 ?
146.
空間関数データ解析の方法 • 空間関数データ解析のための方法としては, クリギングといった多変量データに対する空間データ解析手法 (間瀬, 2010;
瀬谷・堤, 2014)を関数データの枠組みへ 拡張したものが主に提案されている • ここでは, Giraldo et al. (2011)による関数データに対するクリギング (関数クリギング)を紹介 • 時点𝑡および 𝑑 次元空間上の点 𝒔 で観測されたランダム関数を 𝑋 𝒔; 𝑡 ; 𝒔 ∈ 𝐷 ⊂ ℝ 𝑑, 𝑡 ∈ 𝑇 ⊂ ℝ とおく • 𝑛個の観測地点𝒔𝑖 (𝑖 = 1, … , 𝑛)それぞれにおいてデータが経時的に 観測されたとき,これを関数データ化したものを 𝑥 𝒔𝑖; 𝑡 とおく 146 Delicado et al. (2010, Environmetrics) Giraldo et al. (2011, Envi. Ecol. Statist.)
147.
空間関数データ解析のための仮定 • 関数クリギングの適用にあたって,ランダム関数𝑋 𝒔;
𝑡 に次の仮定をおく 𝐸 𝑋 𝒔; 𝑡 = 𝜇 𝑡 , 𝑉 𝑋 𝒔; 𝑡 = 𝜎2 𝑡 𝐶𝑜𝑣 𝑋 𝒔 + 𝒉; 𝑡 , 𝑋 𝒔; 𝑢 = 𝐶 𝒉; 𝑡, 𝑢 , 𝒉 ∈ 𝐷 – 平均関数と分散関数は 𝑡 のみに依存(2次定常性) – 任意の2地点間の共分散関数は𝑡, 𝑢とその距離 𝑟 = 𝒉 にのみ依存(等方性) • 2次定常性の仮定より 𝛾 𝑟; 𝑡 = 1 2 𝐸 𝑋 𝒔 + 𝒉; 𝑡 − 𝑋 𝒔; 𝑡 2 も𝒔に依存せず𝑟 = 𝒉 と 𝑡 のみに依存した関数になる これを(セミ)バリオグラムという 147
148.
関数クリギング(1) • 新たな地点 𝒔0
における関数データ 𝑥 𝒔0; 𝑡 を,次の形で予測する ただし未知パラメータ 𝜆𝑖 𝑖 = 1, … , 𝑛 は制約 𝜆1+ ⋯ + 𝜆 𝑛 = 1 を満たす ො𝑥 𝒔0; 𝑡 = 𝑖=1 𝑛 𝜆𝑖 𝑥 𝒔𝑖; 𝑡 • 未知パラメータ𝜆𝑖は,次の制約付き誤差2乗和の最小化問題によって 推定される min 𝜆1,…,𝜆 𝑛,𝜇 න𝐸 𝑥 𝑠0; 𝑡 − ො𝑥 𝑠0; 𝑡 2 𝑑𝑡 + 𝜇 𝑖=1 𝑛 𝜆𝑖 − 1 • 定常性の仮定を用い, 𝑥 𝑠𝑖; 𝑡 を基底関数展開で表現することで 𝜆𝑖の推定値が得られる 148
149.
パラメータの推定(1) • 2次定常性・等方性・σ𝑖 𝜆𝑖
= 1の仮定を利用すると,正規方程式は 次で行列表現される 𝛾 𝒔1 − 𝒔1 ⋯ ⋮ ⋱ 𝛾 𝒔1 − 𝒔 𝑛 −1 ⋮ ⋮ 𝛾 𝒔 𝑛 − 𝒔1 ⋯ −1 ⋯ 𝛾 𝒔 𝑛 − 𝒔 𝑛 −1 −1 0 𝜆1 ⋮ 𝜆 𝑛 𝜇 = 𝛾 𝒔0 − 𝒔1 ⋮ 𝛾 𝒔0 − 𝒔 𝑛 −1 • 𝛾 𝑟 = 𝛾 𝑟; 𝑡 𝑑𝑡 = 1 2 𝐸 𝑋 𝒔 + 𝒉; 𝑡 − 𝑋 𝒔; 𝑡 2 𝑑𝑡 は トレースバリオグラムとよばれる 149
150.
パラメータの推定(2) • 𝛾 𝑟
は未知である上,互いの距離がちょうど 𝑟 = 𝒉 であるようなデータは まずないため,次の方法で推定値を与える • 2点間の距離が 𝑟 に近い点の集合を 𝑁𝑟 = 𝒔𝑖, 𝒔𝑗 : 𝒔𝑖 − 𝒔𝑗 ≈ 𝑟 として 次でトレースバリオグラム𝛾 𝑟 を推定 ො𝛾 𝑟 = 1 2 𝑁𝑟 𝑖,𝑗∈𝑁 𝑟 න 𝑥 𝒔𝑖; 𝑡 − 𝑥 𝒔𝑗; 𝑡 2 𝑑𝑡 𝑁𝑟 :𝑁𝑟の要素数 • 関数データ𝑥 𝒔𝑖; 𝑡 は基底関数展開 𝑥 𝒔𝑖; 𝑡 = 𝒘𝑖 𝑇 𝝓 𝑡 によって表されると仮定 これにより,積分パートを次で表す න 𝑥 𝒔𝑖; 𝑡 − 𝑥 𝒔𝑗; 𝑡 2 𝑑𝑡 = 𝒘𝒊 − 𝒘𝑗 𝑡 Φ 𝒘𝒊 − 𝒘𝑗 , Φ = න𝝓 𝑡 𝝓 𝑡 𝑇 𝑑𝑡 150
151.
交差検証法による調整パラメータの選択 • 関数化の段階で選択する平滑化パラメータや基底関数の個数を 関数クリギングの段階で選択する方法 • 𝑛地点のデータのうち第
𝑖 地点のものを抜き取った 𝑛 − 1 地点のデータを 用いて,関数クリギングにより第 𝑖 地点 𝒔0 の経時変化を予測したものを ො𝑥 𝒔𝑖; 𝑡 −𝑖 とする • 平滑化パラメータや基底関数の個数を選択するための交差検証法 (Functional Cross-Validation; FCV)は,次で与えられる 𝐹𝐶𝑉 = 𝑖=1 𝑛 𝛼=1 𝑛 𝑖 𝑥 𝒔𝑖; 𝑡𝑖𝛼 − ො𝑥 𝒔𝑖; 𝑡𝑖𝛼 −𝑖 2 • 関数回帰分析や関数時系列解析では,「関数化→モデル推定」を2段階で 切り分けて行っていたが,ここでは関数化とモデル推定を一体化して 1段階で行っている 151
152.
適用例 • カナダの気象データに対して 関数クリギングを適用 • 各地点の日別平均気温を関数化することで 関数データ
𝑥 𝒔𝑖; 𝑡 を得る (𝒔𝑖:緯度経度,𝑡:年間の時間) • このデータから,下図の赤地点の 年間気温推移 ො𝑥 𝒔0; 𝑡 を予測 • R package ”geofd”使用 152
153.
結果(トレースバリオグラム・パラメータ) • 右図上は,トレースバリオグラムの推定値と それを曲線で当てはめたもの • 灰点は全ての2点間に対して 𝑥
𝒔𝑖; 𝑡 − 𝑥 𝒔𝑗; 𝑡 2 を計算したもの • 一定距離離れた地点間の分散は一定とわかる • 右図下は, 𝜆𝑖 𝑖 = 1, … , 𝑛 の推定値を 予測地点𝑠0からの距離に応じて示したもの • 灰線は全地点による重みの平均(1/𝑛) • 近い地点ほど大きな重みが かかっており, 近隣の3都市の 気温だけでほぼ推定されていることがわかる 153 トレースバリオグラムの推定値 クリギングによる重み推定値
154.
結果(予測値) • 右図の破線は,地点𝑠0の気温推移を 関数データ化したもの(答え) • 赤実線は,関数クリギングによる 地点𝑠0の気温曲線の予測値
ො𝑥 𝑠0; 𝑡 • 黒実線は,全地点の気温曲線の 平均関数 • 平均関数と比べると, 関数クリギングによる予測値のほうが 𝑠0における気温の推移を 適切に予測できている 154 クリギングによる気温の推移の予測
155.
関数クリギングに関する補足 • 経時データに対するクリギングとしては,古くはGoulard &
Voltz (1993) により提案されているが,この研究では少ない観測時点を仮定していた 関数データとして扱うことでその仮定は不要になる • 新たな地点 𝒔0 における関数データを ො𝑥 𝒔0; 𝑡 = σ𝑖=1 𝑛 𝜆𝑖 𝑥 𝒔𝑖; 𝑡 と 仮定することで,推定における計算コストがスカラーデータに対するものと ほぼ同等となる ( 𝜆𝑖 も時間依存する 𝜆𝑖 𝑡 と仮定した方法も考えられている) • 今回紹介した関数クリギングでは2次定常性を仮定したが これを満たす状況は限定的と考えられる(仮定が強い) 155
156.
ここまでのまとめ • 関数ロジスティック回帰モデルに対するスパース推定を遺伝子発現データの 分析に適用することで,病気の治療に関連すると考えられる遺伝子を選択した • 関数データ間の距離をベクトルの距離に置き換え,多変量データに対する クラスタリングを適用することで,関数データのクラスタリングが行われる •
関数時系列解析は,各時点のデータが関数として与えられたとき 将来の時点の関数を予測するために用いられる • 関数空間データ解析は,各地点のデータが関数として与えられたとき 未観測地点の関数を予測するために用いられる 156
Download