Downloaded 20 times





![• 配列の和
• 素朴なasmコード
単純ループ
float sum(const float *x, size_t n) {
float r = 0;
for (size_t i = 0; i < n; i++) r += x[i];
return r;
}
xorps r, r // r = 0
test n, n
jz .exit
xor i, i // i = 0
.lp:
addss r, [x + i * 4] // r += x[i]
add i, 1 // i++
cmp i, n // if (i < n)
jne .lp // goto lp
.exit:
7 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-7-320.jpg)
![• ループアンロールすると77行(clang -Ofast)
• 32個単位で処理するループと端数処理と
• n = 2や3と分かっているならとても簡単なのに
ループアンロールと冗長なコード
...
movups xmm2, [rdi+rdx*4]
addps xmm2,xmm0
movups xmm0, [rdi+rdx*4+0x10]
addps xmm0,xmm1
movups xmm1, [rdi+rdx*4+0x20]
movups xmm3, [rdi+rdx*4+0x30]
movups xmm4, [rdi+rdx*4+0x40]
addps xmm4,xmm1
addps xmm4,xmm2
movups xmm2, [rdi+rdx*4+0x50]
addps xmm2,xmm3
addps xmm2,xmm0
movups xmm0, [rdi+rdx*4+0x60]
addps xmm0,xmm4
movups xmm1, [rdi+rdx*4+0x70]
addps xmm1,xmm2
add rdx,0x20
add rcx,0x4
...
// n = 2
movss r, [x + 0]
addss r, [x + 4]
ret
// n = 3
movss r, [x + 0]
addss r, [x + 4]
addss r, [x + 8]
ret
8 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-8-320.jpg)
![• iN x jN x kN個からなる3次元配列の(i, j, k)番目は
iN*jN*k+iN*j+i番目のアドレス
• アドレス計算にはコストがかかる
• addr = (jN * k + j) * iN + i
多次元配列の添え字の計算
iN
jN
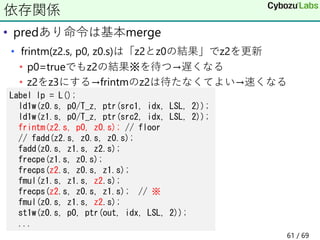
kN
i
j
k
mov rdx, jN
imul rdx, k // jN * k
add rdx, j // jN * k + j
imul rdx, iN // (jN * k + j) * iN
add rdx, i // (jN * k + j) * iN + i
movss r, [x + rdx * 4]
9 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-9-320.jpg)
![• 多数のループの畳み込み
• ループの順序を入れ換えても計算結果は同じ
• キャッシュの影響で実行時間は異なる
• パラメータやCPUによって最適な順序が異なる
• 事前に多数のパターンを用意しておくのは組み合わせが大変
多重ループの順序
for oh
for ow
for oc
for ic
for kh
for kw
dst[oc, ow, oh] += ker[oc, ic, kw, kh] * src[ic, ow+kw, oh+kh]
10 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-10-320.jpg)

![• 基本的にIntelのアセンブラ形式
• C++の文法を使った名前づけ
• ラベルクラス
• 前方参照 後方参照
XbyakのDSL概略
auto src = rsi;
auto i = rcx;
auto x = rax;
mov(x, ptr[src+i*4]);
アセンブラ Xbyak
add rax, rcx add(rax, rcx); // rax += rcx
mov eax, dword [rbx+rcx*8+4] mov(eax, ptr[rbx+rcx*8+4]);
auto lp = L();
...
sub(n, 1);
jnz(lp);
Label exitL;
jmp(exitL);
...
L(exitL);
14 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-14-320.jpg)
![• uint32_t src[n];の要素の和を求める関数を生成
• (nが小さいとき)
• 実行時に決まる様々なパラメータに応じた
コード生成と実行するプログラムを記述可能
コード生成の例
struct Code : Xbyak::CodeGenerator {
Code(int n) {
mov(eax, ptr[src]);
for (int i = 1; i < n; i++) {
add(eax, ptr[src + i * n]);
}
}
};
mov eax, ptr[rcx]
mov eax, ptr[rcx]
add eax, ptr[rcx+4]
mov eax, ptr[rcx]
add eax, ptr[rcx+4]
add eax, ptr[rcx+8]
Code c(1); Code c(2); Code c(3);
15 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-15-320.jpg)




![• Intelの512bit SIMD命令セット
• 512bitのレジスタ32個zmm0, ..., zmm31
• 64bit整数x8, 32bit整数x16, 16bit整数x32, 8bit整数x64
• 64bit double x 8, 32bit float x 16
• 基本的に
• 「≪命令≫ dst, src1, src2」の形 ; dst←「src1とsrc2で計算」
• 例
• vaddps z, x, y ; z = x + y as float
• vpaddd z, x, y ; z = x + y as int
• 𝑥 = [𝑥0: … : 𝑥15], 𝑦 = [𝑦0: … 𝑦15]
AVX-512
𝒙 𝒙𝟎 𝒙𝟏 ... 𝒙𝟏𝟓
𝑦 𝑦0 𝑦1 ... 𝑦15
𝑧 𝑥0 + 𝑦0 𝑥1 + 𝑦1 ... 𝑥15 + 𝑦15
21 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-21-320.jpg)



![• vpdpbusd dst, u, s
• 今まではvpmaddubsw+vpmaddwd+vpadddを使っていた
8bit整数の積和演算
void vpdpbusdC(int dst[16], const uint8_t u[64], const int8_t s[64])
{
dst[ 0]+=u[ 0]*s[ 0]+u[ 1]*s[ 1]+u[ 2]*s[ 2]+u[ 3]*s[ 3];
dst[ 1]+=u[ 4]*s[ 4]+u[ 5]*s[ 5]+u[ 6]*s[ 6]+u[ 7]*s[ 7];
dst[ 2]+=u[ 8]*s[ 8]+u[ 9]*s[ 9]+u[10]*s[10]+u[11]*s[11];
...
dst[15]+=u[60]*s[60]+u[61]*s[61]+u[62]*s[62]+u[63]*s[63];
}
if (support_vnni) { // 実行時にCPU判別して命令の切り換え
vpdpbusd(dst, src1, src2); // dst += src1 * src2
} else {
vpmaddubsw(tmp, src1, src2);// [a0 b0+a1 b1:a2 b2+a3 b3:...] 8->16
vpmaddwd(tmp, ones, tmp); // [a0 b0+a1 b1+a2 b2+a3 b3:...]16->32
vpaddd(dst, dst, tmp);
}
25 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-25-320.jpg)

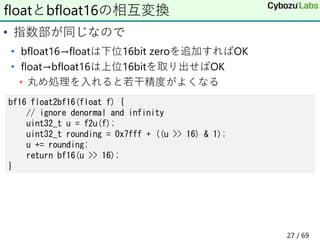
![• vcvtne2ps2bf16 dst, src1, src2
• src1, src2のfloatをbfloat16にして連結してdstに
• vdpbf16ps dst, src1, src2 ; 積和命令(結果はfloat)
• これらの命令をサポートしていれば利用
AVX-512のbloat16関連命令
void vcvtne2ps2bf16(
bf16 dst[32], const float src1[16], const float src2[16]) {
for (int i = 0; i < 16; i++) {
dst[i] = float2bf16(src1[i]);
dst[i+16] = float2bf16(src2[i]);
} }
void vdpbf16ps(
float dst[16], const bf16 src1[32], const bf16 src2[32]){
for (int i = 0; i < 16; i++) {
dst[i] += bf16_to_float(src1[i*2+0])*bf16_to_float(src2[i*2+0]);
dst[i] += bf16_to_float(src1[i*2+1])*bf16_to_float(src2[i*2+1]);
} }
28 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-28-320.jpg)



![• floatとintのbit表現の入れ換え
• tbl[i] = 1/(i+1) for i = 0, ..., 8を事前計算
• s=0, e=127なら𝑦 = −1 𝑠2𝑒−127 1 +
𝑓
224 = 1 + 𝑓/224
Cでの実装例
float log(float x) {
uint32_t u = f2u(x);
float n = int(u - (127 << 23)) >> 23; // x = y 2^n のnを取り出す
u = (u & 0x7fffff) | (127 << 23);
float y = u2f(u); // yを取り出す
float a = (2/3) * y - 1
n = n * log2 + log(1.5);
x = tbl[8];
for (int i = 7; i >= 0; i--) x = x * a + tbl[i];
return x * a + n;
}
float f2u(uint32_t x) { float y; memcpy(&y, &x, 4); return y; }
uint32_t u2f(float x) { uint32_t y; memcpy(&y, &x, 4); return y; }
32 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-32-320.jpg)
![• 各種定数は事前にレジスタに設定しておく
• 分かりやすさのため下記コードは定数はそのまま表記({}つき)
• 実際はその値を代入したレジスタ
• input/output : zm0
• zm1, zm2を利用
AVX-512を使った実装例
vpsubd(zm1, zm0, {127 << 23}); // u32として127 << 23を引く
vpsrad(zm1, zm1, 23); // 右23bitシフトしてnを取り出す
vcvtdq2ps(zm1, zm1); // nをfloatに変換
vpandd(zm0, zm0, {0x7fffff});
vpord(zm0, zm0, {127 << 23}); // x=y 2^nのyを取り出す
vfmsub213ps(zm0, {2/3}, {1}); // a = y * (2/3) - 1
vfmadd213ps(zm1, {log2}, {log(1.5)}); // n = n * log2 - log(1.5)
vmovaps(zm2, tbl[8]); // x = 1.0
for (int i = 7; i >= 0; i--) vfmadd213ps(zm2, zm0, tbl[i]);
vfmadd213ps(zm0, zm2, zm1); // x * a + n
33 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-33-320.jpg)
![• n個のfloat配列に対する処理方法
• まず16個ずつSIMD処理する
• ループアンロール(後述)するときは16の倍数
• 端数処理の前にマスクレジスタについて説明する
ループ処理
// n, src, dstはレジスタのalias
mov(ecx, n);
and_(n, ~15u); // nを超えない最大の16の倍数
jz(mod16); // nが0になれば端数処理へ
Label lp = L();
vmovups(zmm0, ptr[src]); // 16個読み込む
add(src, 64); // srcレジスタを64byte増やす
// log一つ分の処理をここで行う
vmovups(ptr[dst], zmm0); // 結果を書き込む
add(dst, 64); // dstレジスタを64byte増やす
sub(n, 16); // カウンタを16減らす
jnz(lp); // 0になるまでループ
34 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-34-320.jpg)

![• vmovdqu8(byte単位のレジスタコピー)
• k1レジスタのビットが立っているところだけコピー
マスクの例
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]
xmm0
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 Y4 Y3 Y2 Y1 Y0]
xmm1
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]
k1
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 X4 Y3 Y2 X1 Y0]
xmm1
vmovdqu8 xmm1{k1}, xmm0
36 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-36-320.jpg)
![• vmovdqu8(byte単位のレジスタコピー)
• k1レジスタのビットが立っているところだけコピー
• それ以外は0クリア
• XbyakではT_zで指定する
ゼロ化マスクの例
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]
xmm0
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 Y4 Y3 Y2 Y1 Y0]
xmm1
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]
k1
[00 00 00 00 00 00 00 00 00 00 00 X4 00 00 X1 00]
xmm1
vmovdqu8 xmm1{k1}{z}, xmm0
37 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-37-320.jpg)

![• 先程の16単位で処理した残り(n<16)
• 読み書きするデータは残りn個(n = 7の例)
ループの端数処理
L(mod16); // 端数処理時のジャンプ先
and_(ecx, 15); // ecx = n = n & 15
jz(exit); // 0ならexitにジャンプ
mov(eax, 1); // eax = 1
shl(eax, cl); // eax = 1 << n
sub(eax, 1); // eax = (1 << n) - 1 ; n個の1bit
kmovd(k1, eax); // k1に設定
vmovups(zmm0|k1|T_z, ptr[src]); // srcからn個の要素を読む
// log一つ分の処理
vmovups(ptr[dst]|k1, zm00); // n個書き込む
L(exit);
+0 +1 +2 +3 +4 +5 +6|+7 +8 +9 +a +b +c +d +e +f
[x0 x1 x2 x3 x4 x5 x6 -- -- -- -- -- -- -- -- --]
k1 1 1 1 1 1 1 1 0 0 0 0 ...
39 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-39-320.jpg)
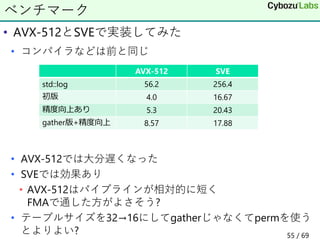
![• この実装は区間[2, 3]で相対誤差eの最大値は1.7e-7
• e=(x-真の値)/真の値
• 区間[0.99, 1.01]では4.2e-2とかなり悪い
• 何故?log(𝑥)は𝑥が1に近いとき0に近い
• log 𝑥 = 𝑛𝑙𝑜𝑔 2 + log 1.5 + log(1 + 𝑎)
• 計算途中で桁落ちして精度低下
• 𝑥 = 1 + 𝜖(𝜖が小さい)ならlog 𝑥 = log(1 + 𝜖)で計算すべき
精度向上
// aとnを計算
if (abs(x - 1) < 1/32) { // 追加すべきコード
n = 0;
a = x - 1;
}
return n + log(1+a);
40 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-40-320.jpg)
![• 分岐はSIMDで扱いづらい
• マスクレジスタを利用して分岐を表現する
• 区間[0.99, 1.01]で4.2e-2→1.2e-7と劇的に精度向上
SIMD化
// 数値リテラルは事前にレジスタに代入しておく
vmovapx(keepX, zmm0); // xの値を保持
...(計算)...
vsubps(zmm2, keepX, {1}); // x-1
vandps(zmm2, zmm2, {0x7fffffff}); // |x-1|
vcmpltps(k2, zmm2, {1/32}); // k2 = |x-1| < 1/32
vsubps(zmm0|k2, keepX, {1}); // if (k2) y = x-1
vxorps(zmm3|k2, zmm3); // if (k2) h = 0
x 1.5 1.01 2.3 1.001 ...
k2 0 1 0 1 ...
41 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-41-320.jpg)
![• Xeon 8280 2.7GHz
• float x[16384];に対する1ループ(16要素)あたりの時間(nsec)
• gcc-9.3.0 -O3
• -Ofastにするとstd::logもSIMD化されて8.7nsecに
ベンチマーク
std::log fmath::log
初版 56.2 4.0
精度向上版 56.2 5.3
42 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-42-320.jpg)




![• input/output : z0, use z1, z2
• 定数は事前にレジスタに入れておく
• p0はptrue(p0.s);により全て1にしておく
SVEを使ったlogの実装例
sub(z1.s, z0.s, {127 << 23}); // intとしてz1 = z0 - (127 << 23)
asr(z1.s, z1.s, 23); // z1 = int(z1) >> 23
scvtf(z1.s, p0, z1.s); // z1 = float(z1)
and_(z0.s, p0, {0x7fffff}); // z0 = x & 0x7fffff
orr(z0.s, p0, {127 << 23}); // y = (x & 0x7fffff) | (123 << 23)
fnmsb(z0.s, p0, {2/3}, {1.0}); // z0 = z0 * (2/3) - 1
fmad(z1.s, p0, {log2}, {log1p5}); // z1 = n = z1 * log2 + log(1.5)
movprfx(z2.s, p0, tbl[8]);
fmad(z2.s, p0, z0.s, tbl[7]);
for (int i = 6; i >= 0; i--) fmad(z2.s, p0, z0.s, tbl[i].s);
fmad(z0.s, p0, z2.s, z1.s); // z0 = x * a + n
47 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-47-320.jpg)

![• whilelt (p.s, x5, n);
• マスクレジスタpについてp[i] = (x5+i < n) for i = 0, ...
• b_first(lp);
• x5 < nならlpにジャンプ
ループの端数処理
Label cond;
mov(x5, 0); // x5をインデックスiとして使う
b(cond);
Label lp2 = L();
ld1w(z0.s, p0/T_z, ptr(src, x5, LSL, 2)); // z0 = src[x5 << 2]
// log 1個分の処理
st1w(z0.s, p0, ptr(dst, x5, LSL, 2)); // dst[x5 << 2] = z0
incd(x5); // x5 += 16
L(cond);
whilelt(p0.s, x5, n);
b_first(lp2);
49 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-49-320.jpg)
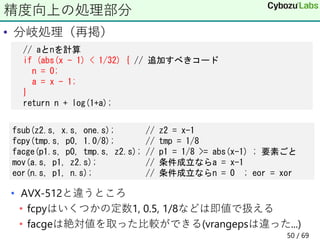
![• FX700 2.0GHz?
• float x[16384];に対する1ループ(16要素)あたりの時間(nsec)
• gcc-8.4.1 -O3
ベンチマーク
std::log fmath::log
初版 256.4 20.23
精度向上版 256.4 23.29
51 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-51-320.jpg)
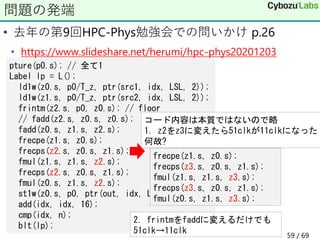
![• 𝑐について
• 𝑓を1/𝑐の近似値とすると𝑔 ≔ 𝑓𝑐 − 1は0に近い
• 𝑐 = (1 + 𝑔)/𝑓だからlog 𝑐 = log 1 + 𝑔 − log(𝑓)
• 𝑓とlog(𝑓)をテーブルルックアップする
• 近似値の取り方
• 仮数部を使うには1以上2未満の範囲に入る必要がある
• 今扱いたい区間は1の付近(< 1と≥ 1で不連続なので避ける)
• 区間[0.9, 1.1]は[0.9×1.4, 1.1×1.4]になる
• 𝑎 ≔ 2𝑥 = 𝑏2𝑛
, 𝑐 ≔ Τ
𝑏 2とすると|log(𝑐)| ≤ 𝑙𝑜𝑔 2
• f2u(b)の仮数部の上位5bitをインデックスdとして
• T1[d] = 2/𝑏, T2[i]=log(T1[d])とする
• L=5のとき𝑔~1/32なのでlog(1 + 𝑔)は3次近似でよい
テーブルを使うアルゴリズム(1/2)
52 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-52-320.jpg)
![• 擬似コード
テーブルを使うアルゴリズム(2/2)
input : x
a = sqrt(2) x
a = b 2^nと分解する (1 <= b < 2)
c = (1/sqrt(2)) bとすると(1/sqrt(2) <= c < sqrt(2))
L = 5
d = (f2u(b) & mask(23)) >> (23 - L) // bの上位L bitを取り出す
// T1[i] = sqrt(2) / u2f((127 << 23) | (i << (23 - L)))
// T2[i] = log(T1[i])
f = T1[d] は 1/c = sqrt(2) / bの近似値
g = f c - 1 とすると |g| <= 1/2^L
log c = log ((1 + g)/f) = log(1+g) - log f
h = T2[d] は log f
log x = log (c * 2^n)
= n log 2 + log c = n log 2 - log f + log(1+g)
53 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-53-320.jpg)
![• テーブル引きy = tbl[x]のSIMD版
• SVE
• zにindexの4倍(floatだから)を入れる, xはtblのアドレス
• AVX-512
• マスクレジスタ必須 xnord(xor + not)で全て1にする
• zにindexを入れる, raxはtblのアドレス
• 実験コードは
• https://github.com/herumi/fmath/ のfmath2.hpp
• https://github.com/herumi/misc/sve/ のlog.hppなど
gather命令
ld1w(y.s, p0, ptr(x, z.s, SXTW));
kxnord(k2, k2, k2);
vgatherdps(y|k2, ptr[rax + z * 4]);
54 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-54-320.jpg)
![• SVEでループアンロール(N = 1, 2, 3)してみた
• 16要素ごとではなく16x2, 16x3要素ごと処理
• これが
• こんな感じになる
• 元がC個レジスタを使うならCN個のレジスタt[CN]を用意
ループアンロール(1/2)
sub(z1.s, z0.s, {127 << 23});
asr(z1.s, z1.s, 23);
scvtf(z1.s, p0, z1.s);
and_(z0.s, p0, {0x7fffff});
#define UNROLL for (int i = 0; i < N; i+=C)
UNROLL sub(t[i+1].s, t[i+0].s, {127 << 23});
UNROLL asr(t[i+1].s, t[i+1].s, 23);
UNROLL scvtf(t[i+1].s, p0, t[i+1].s);
UNROLL and_(t[i+0].s, p0, {0x7fffff});
生成コード
sub(z1.s, z0.s, {127 << 23});
sub(z4.s, z3.s, {127 << 23});
sub(z7.s, z6.s, {127 << 23});
asr(z1.s, z1.s, 23);
asr(z4.s, z4.s, 23);
asr(z7.s, z7.s, 23);
...
56 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-56-320.jpg)



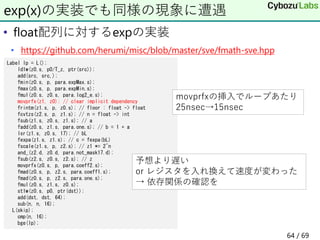



![• tileloadd tmm, [base+offset+stride]
• 部分行列の読み込み
• tmm ; タイルレジスタ
• sibmemという特殊なメモリアドレッシング
• base ; 行列の先頭アドレスを指すレジスタ
• offset ; ターゲットの計算位置を表す定数
• stride ; 次の列への差分を指すレジスタ
命令概要
tmm base+offset memory
stride
68 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-68-320.jpg)
![• 最内ループ
https://github.com/oneapi-src/oneDNN/blob/master/src/cpu/x64/brgemm/jit_brgemm_kernel.cpp
行列の積和C += ABの一部
tileloadd tmm0, [baseC+strideC]
tileloadd tmm1, [baseC+strideC+offset]
mov n, 0
lp:
tileloadd tmm2, [baseA+strideA]
tileloadd tmm3, [baseB+strideB]
// u8成分のAとs8成分のBの行列計算してtmm0に足し込む
tdpbusd tmm0, tmm2, tmm3
tileloadd tmm3, [baseB+strideB+offset] // 隣のB
tdpbusd tmm1, tmm2, tmm3 // 隣のCの積和
add baseA, k // 次のA
add baseB, k*strideB
add n, k
cmp n, limit
jne lp
tilestored [baseC+strideC], tmm0 // Cの更新
tilestored [baseC+strideC+m], tmm1 // 隣のCの更新
tmm0 tmm1 tmm2 tmm3
69 / 69](https://image.slidesharecdn.com/riken-20210624-210624054033/85/Intel-CPU-69-320.jpg)

The document discusses optimization techniques for deep learning frameworks on Intel CPUs and Fugaku aimed architectures. It introduces oneDNN, a performance library for deep learning operations on Intel CPUs. It discusses issues with C++ implementation, and how just-in-time assembly generation using Xbyak can address these issues by generating optimal code depending on parameters. It also introduces Xbyak_aarch64 for generating optimized code for Fugaku's Scalable Vector Extension instructions.













![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)


































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)






