Downloaded 10 times




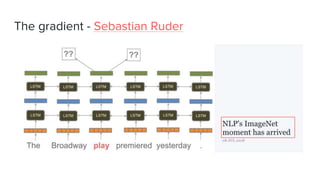


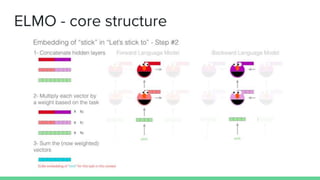


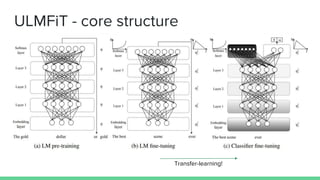



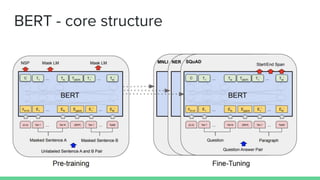




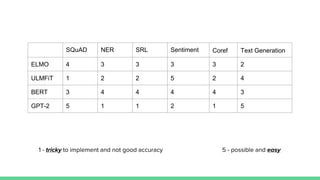

The document discusses recent developments in pre-trained language models including ELMO, ULMFiT, BERT, and GPT-2. It provides overviews of the core structures and implementations of each model, noting that they have achieved great performance on natural language tasks without requiring labeled data for pre-training, similar to how pre-training helps in computer vision tasks. The document also includes a comparison chart of the types of natural language tasks each model can perform.




























![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)






































