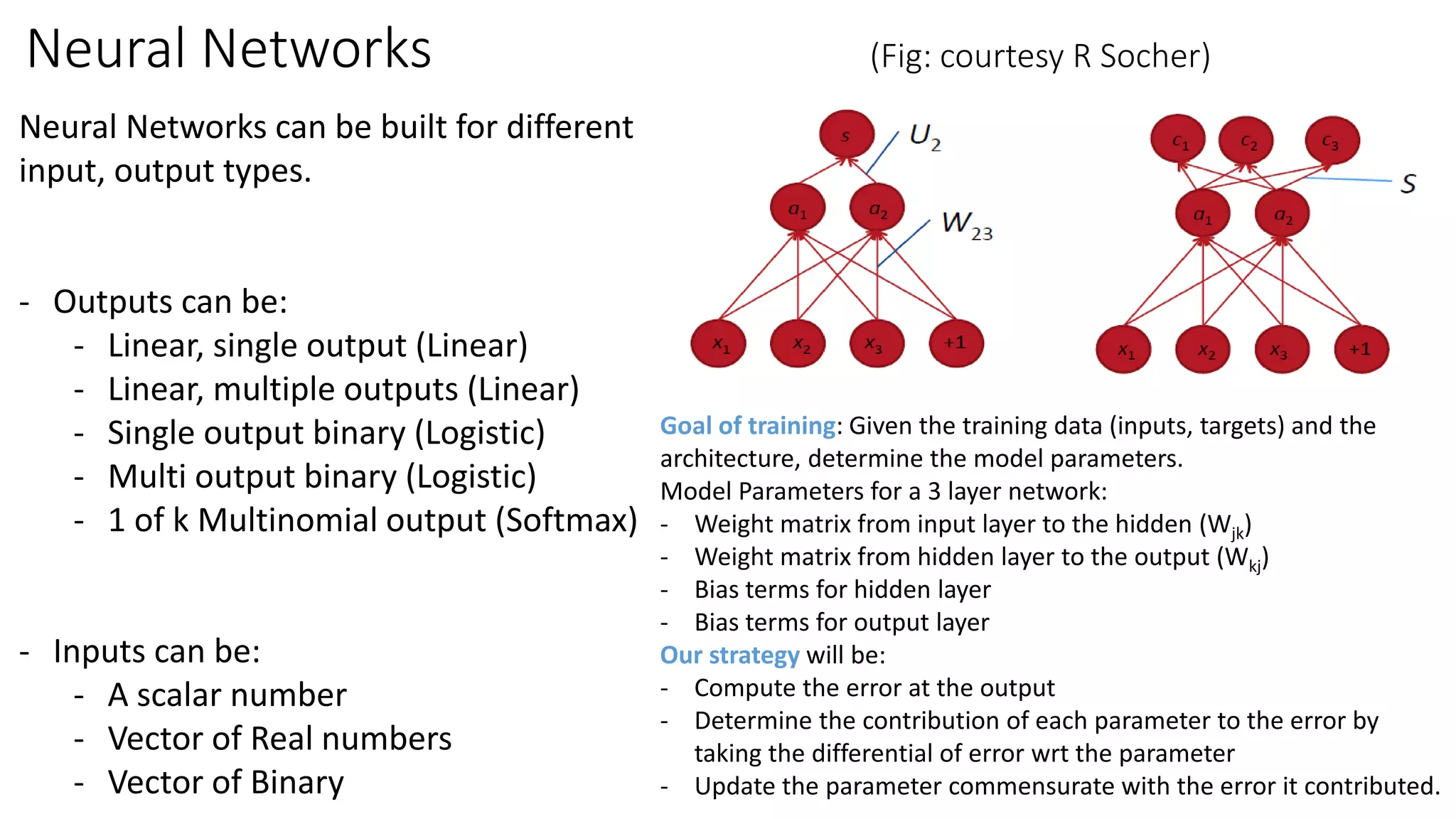
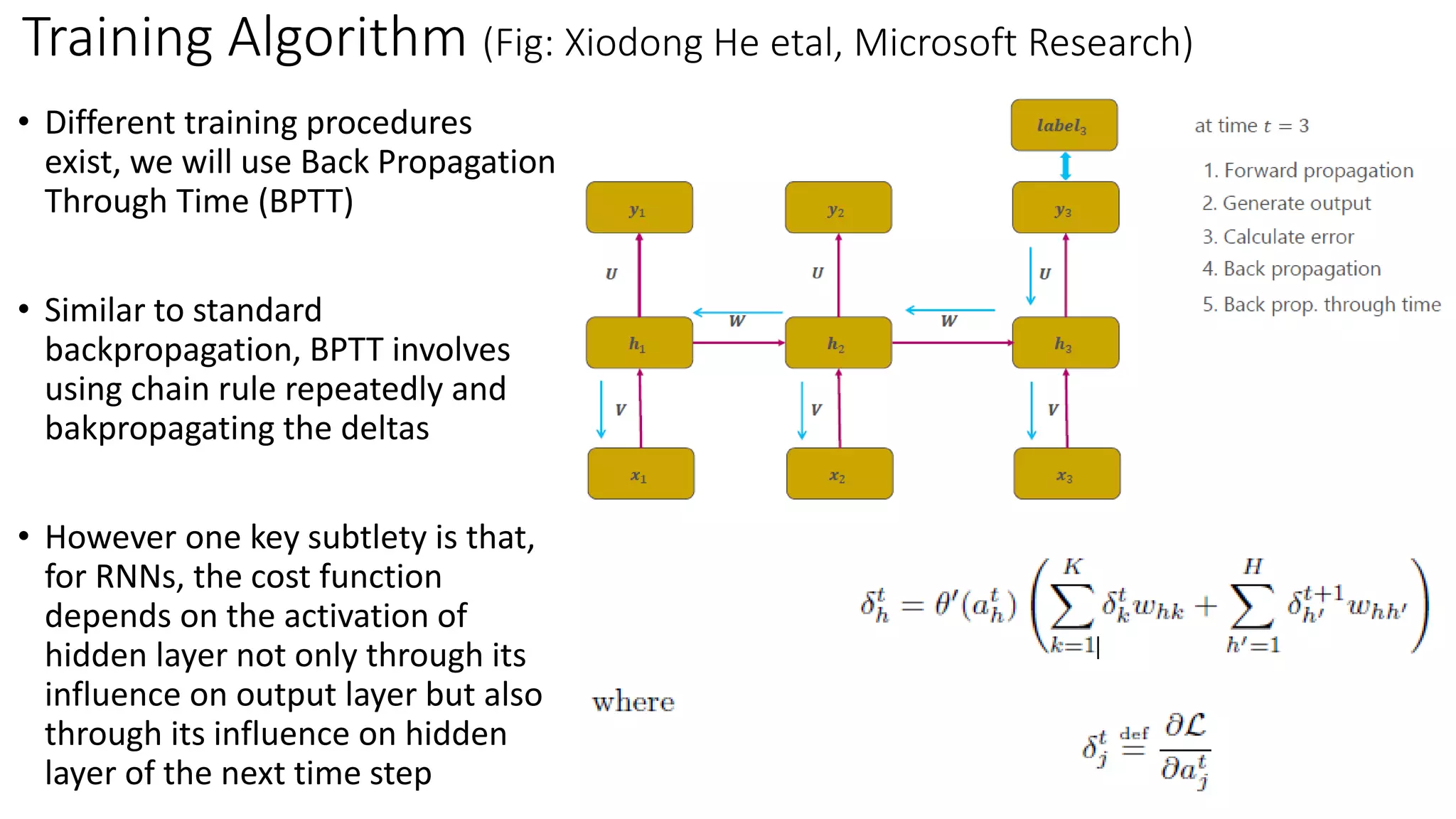
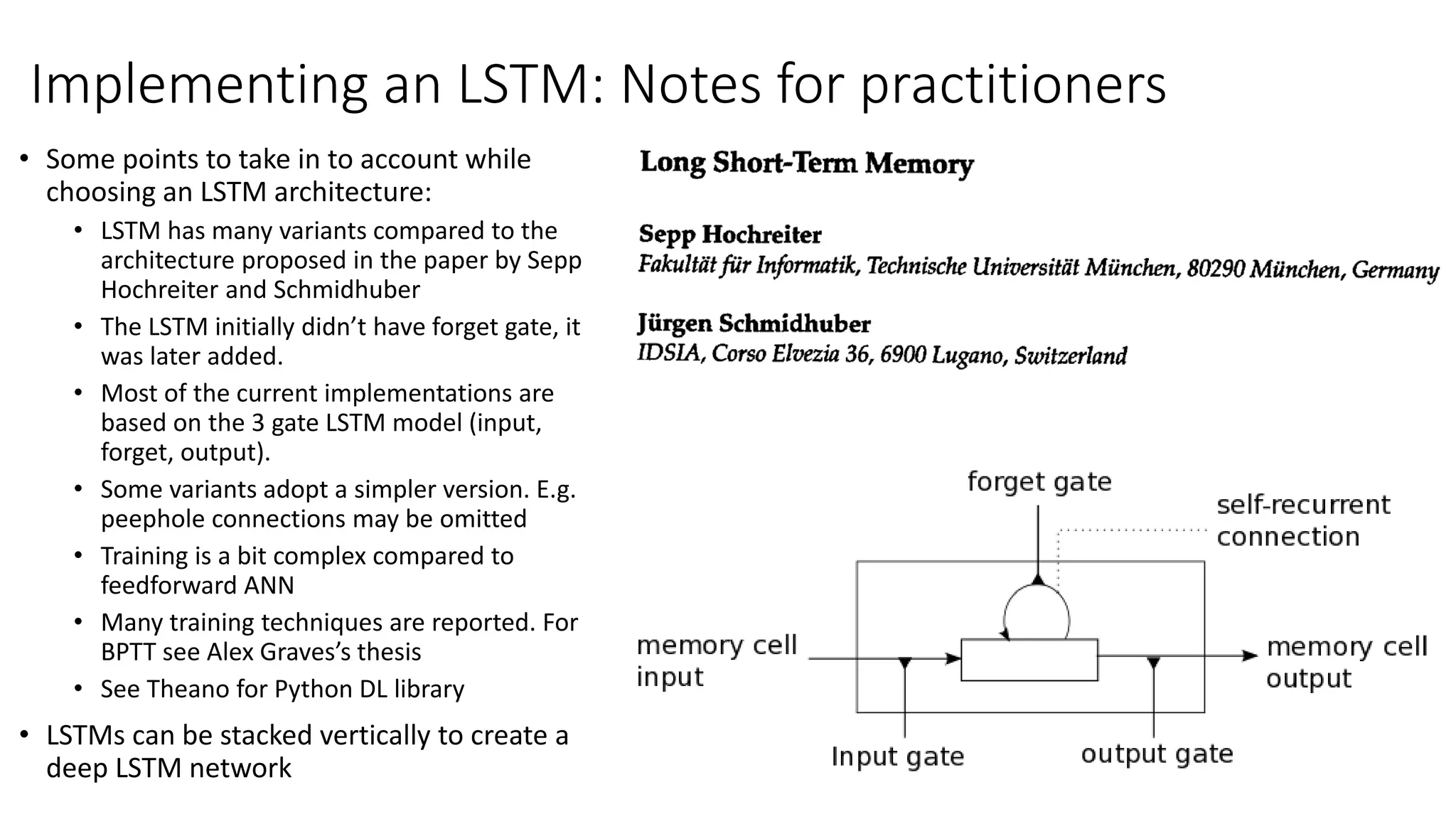
The document provides an overview of recurrent neural networks (RNNs) and their applications, including bidirectional RNNs and long short-term memory (LSTM) networks, highlighting their advantages in modeling non-linear cognitive tasks. It covers key concepts such as the vanishing gradient problem, backpropagation algorithms, and design choices for building neural networks. Applications range from language modeling and translation to sentiment analysis and machine translation.