Downloaded 153 times




![[-0.4, 0.9, …]
History
Word vectors
cats = [0.2, -0.3, …]
dogs = [0.4, -0.5, …]
Sentence/doc vectors
It’s raining
cats and dogs.
We have two
cats.
[0.8, 0.9, …]
[-1.2, 0.0, …]
}
}
Word-in-context
vectors
We have two cats.
}
[1.2, -0.3, …]
It’s raining cats and dogs.
}
Transfer Learning in NLP: Concepts and Tools - Thomas Wolf - Slide 11](https://image.slidesharecdn.com/transferlearninginnlp-190909115130/85/Thomas-Wolf-Transfer-learning-in-NLP-9-320.jpg)















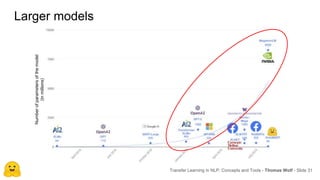

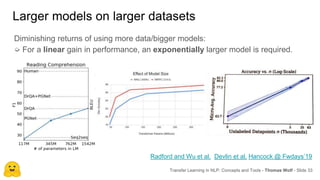
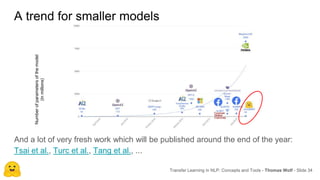








Transfer learning in NLP involves pre-training large language models on unlabeled text and then fine-tuning them on downstream tasks. Current state-of-the-art models such as BERT, GPT-2, and XLNet use bidirectional transformers pretrained using techniques like masked language modeling. These models have billions of parameters and require huge amounts of compute but have achieved SOTA results on many NLP tasks. Researchers are exploring ways to reduce model sizes through techniques like distillation while maintaining high performance. Open questions remain around model interpretability and generalization.






![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)































































![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Ratko Nikolic - BI with AI: Automating Business Intelligence ...](https://cdn.slidesharecdn.com/ss_thumbnails/ecd7hahhq6qiwefuoiyw-dsc2025-ratko-nikolic-ai-data-analyst-260119101519-54d52956-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)







