Download as PDF, PPTX


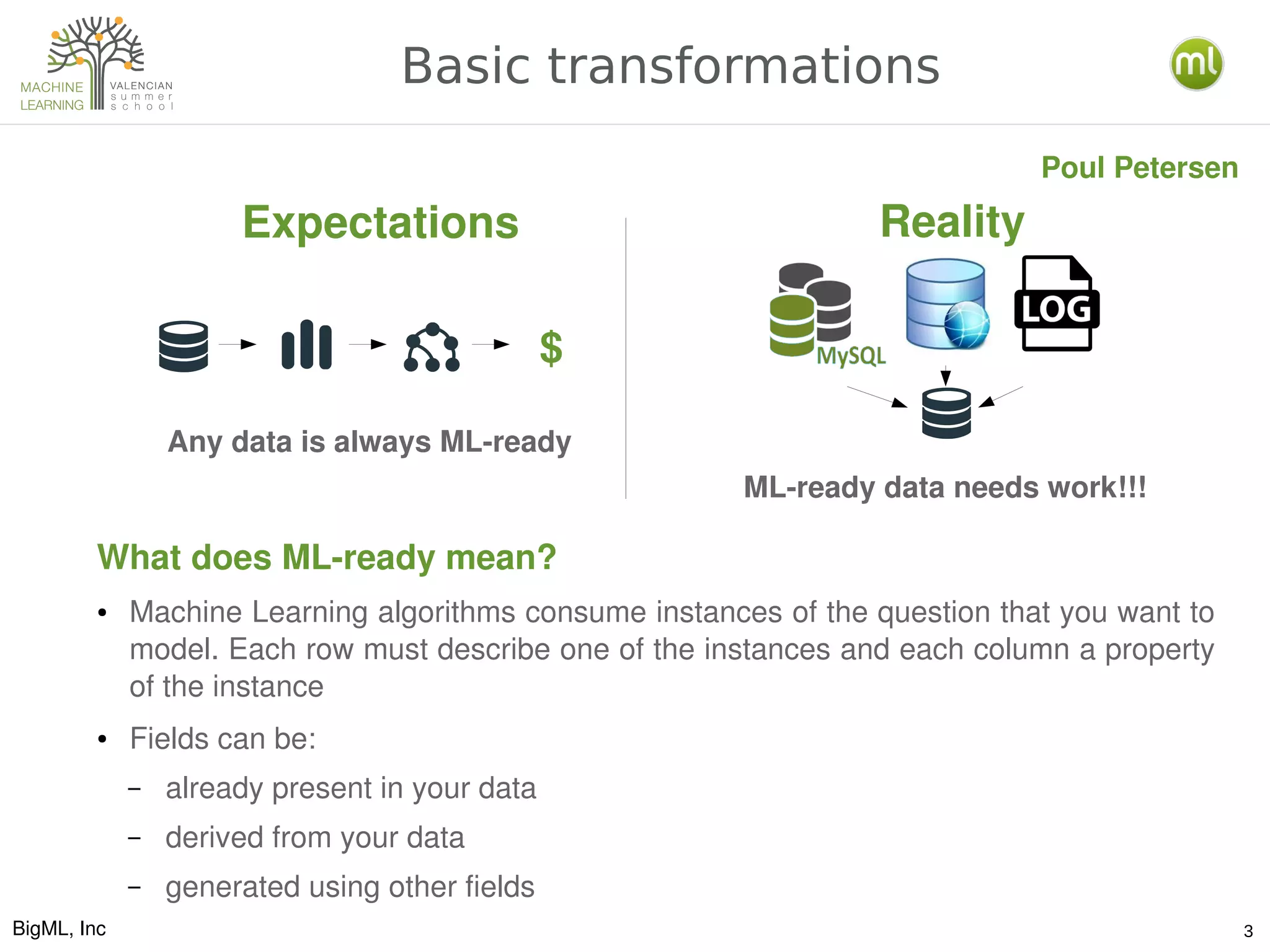












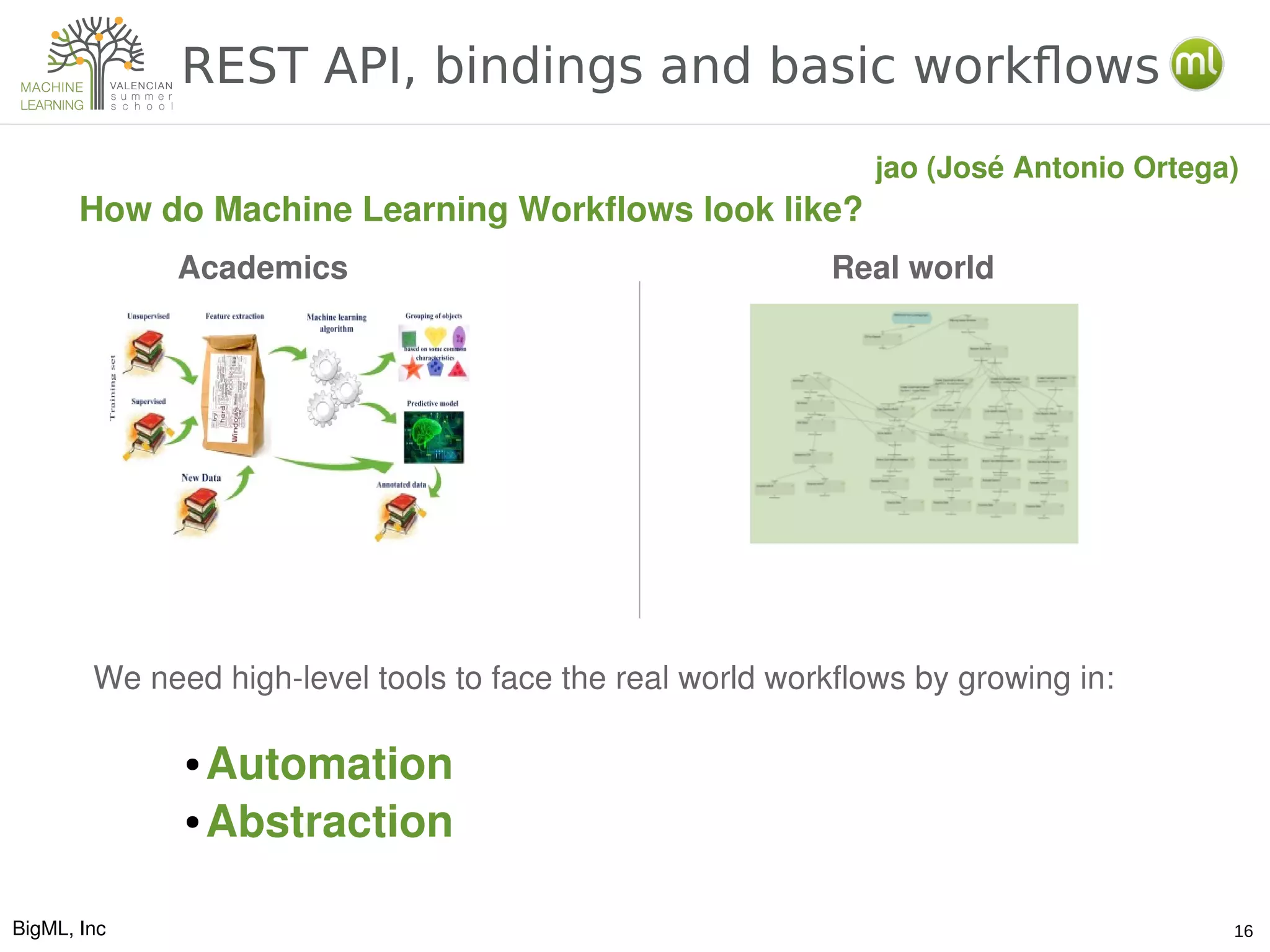







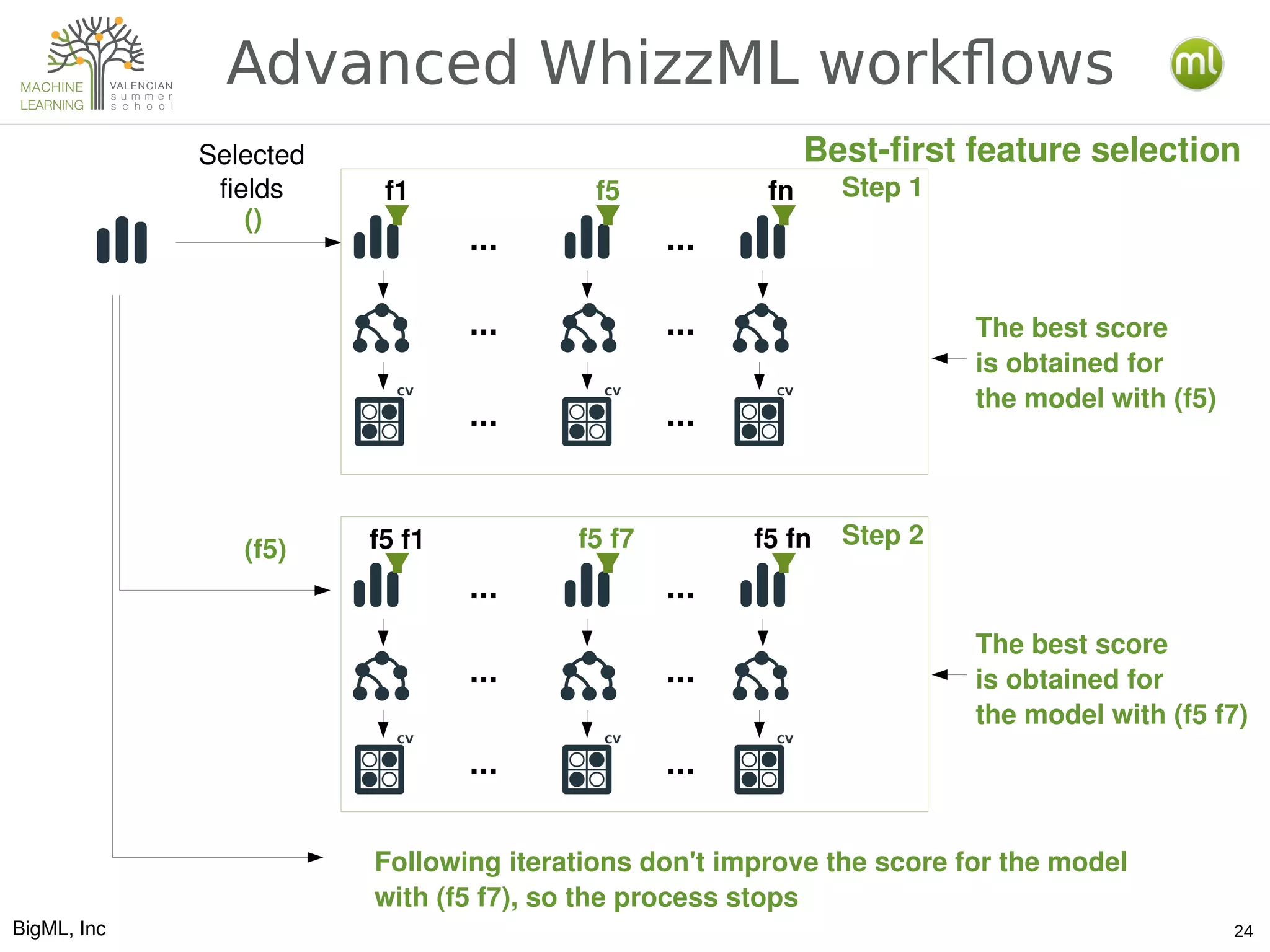
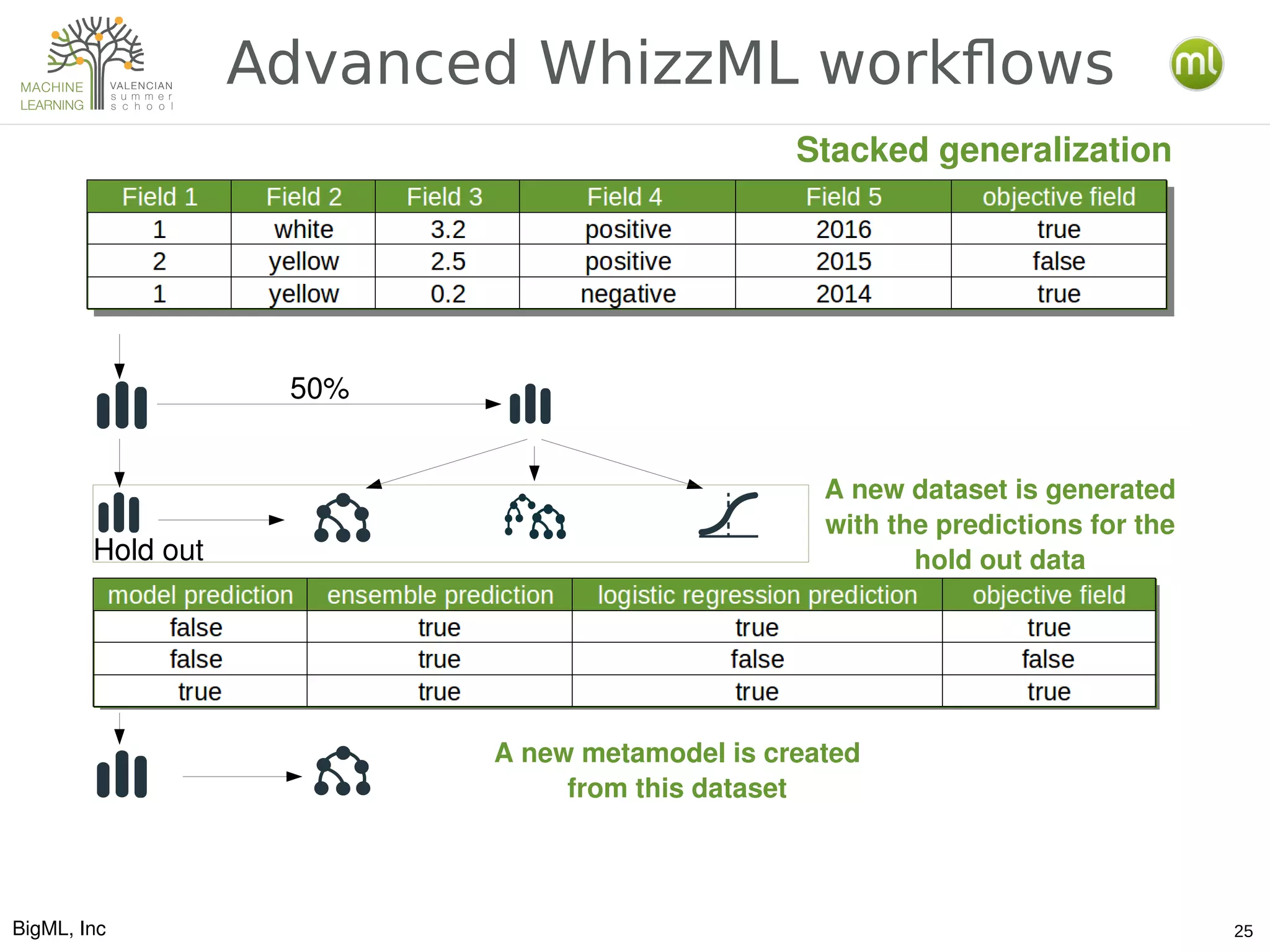
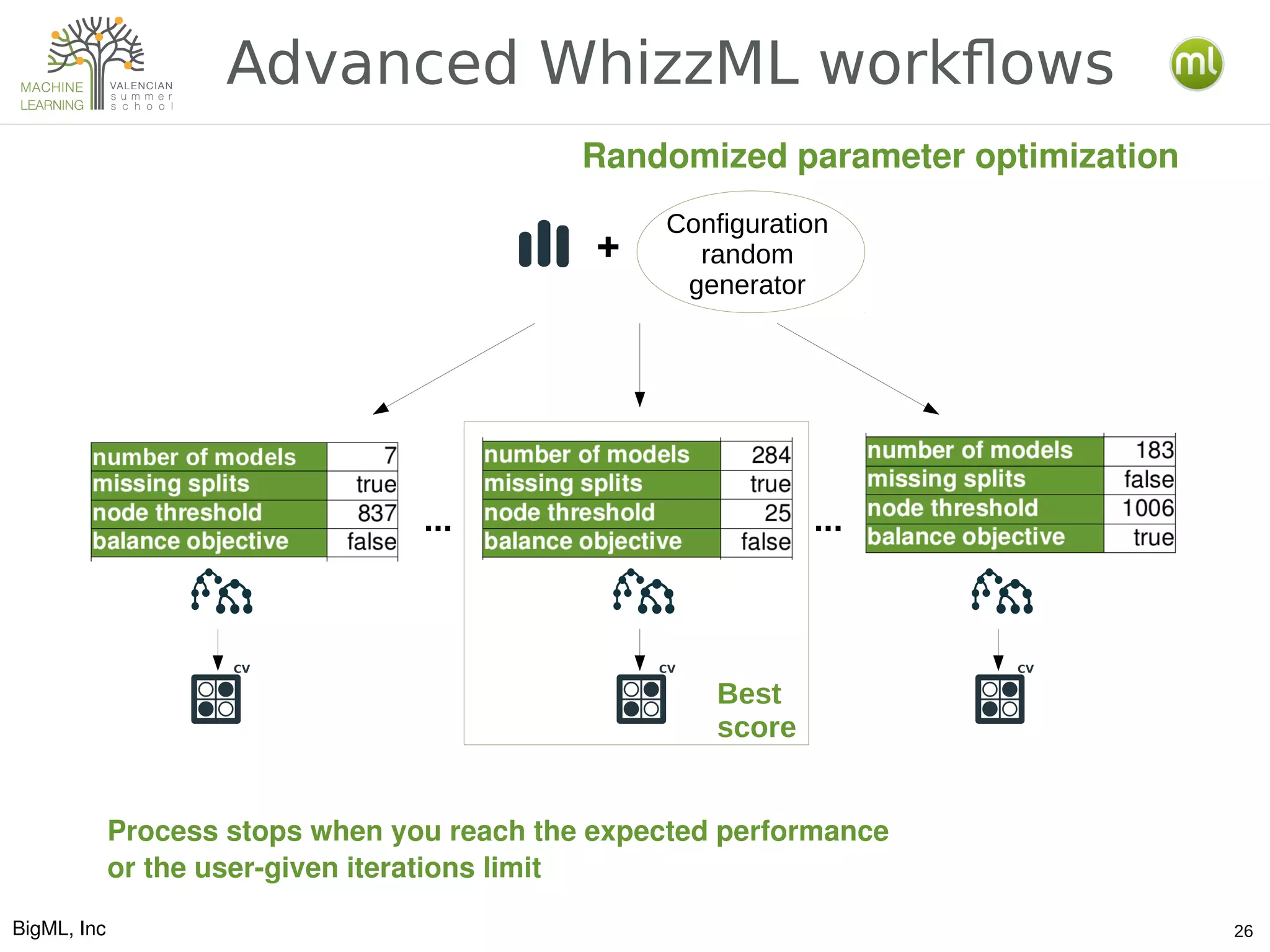
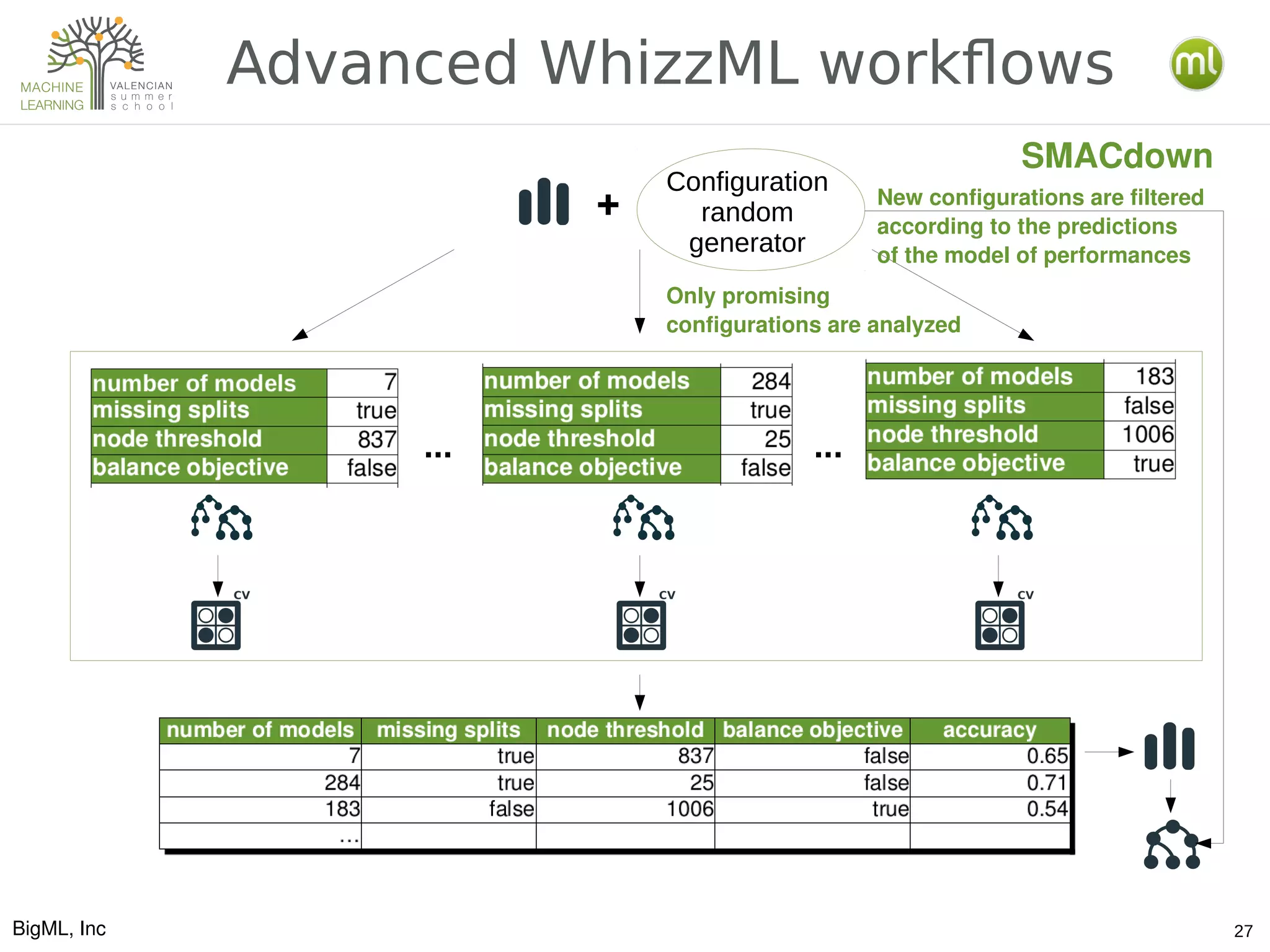
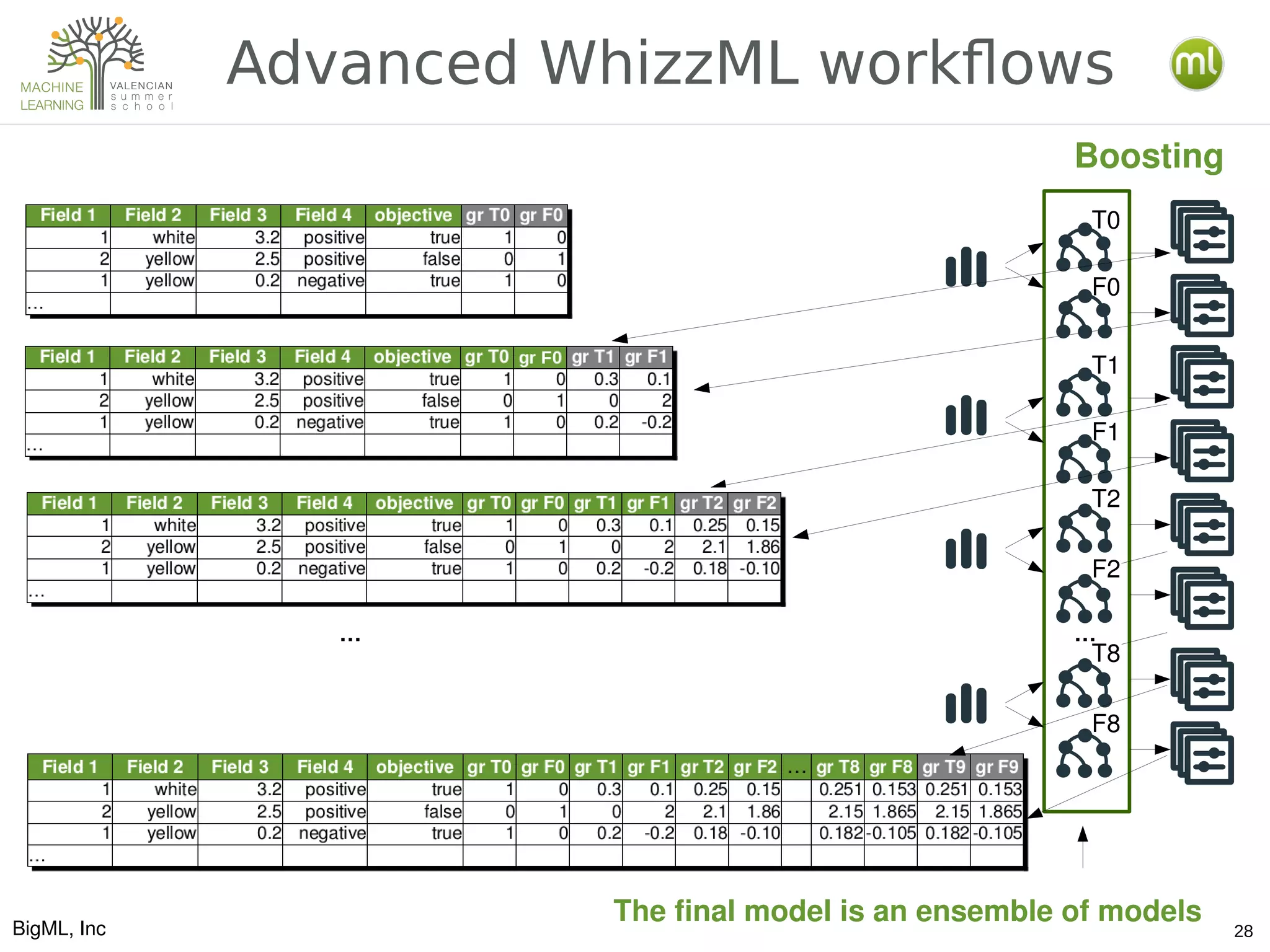


The document discusses various aspects of preparing data for machine learning, emphasizing the concept of making data 'ml-ready' through transformations such as cleansing, denormalizing, and feature engineering. It details the importance of selecting relevant features and the challenges associated with handling missing data and time-series information. Additionally, it introduces the use of tools and workflows for automating machine learning processes, including the use of REST APIs and the WhizzML scripting language for advanced data manipulation.


































































































