Download as PDF, PPTX




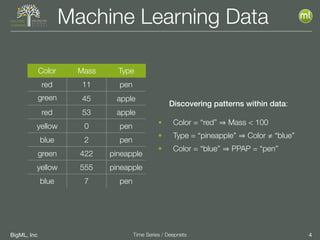
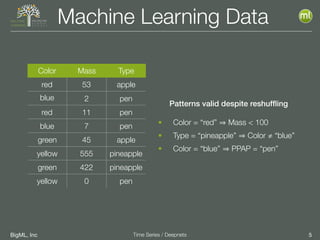
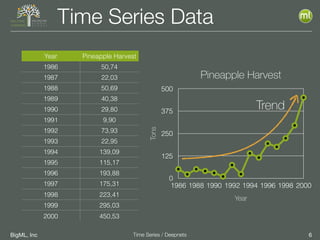
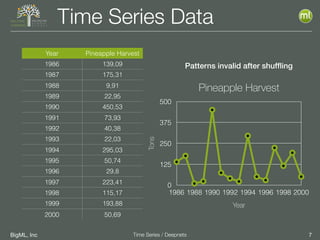
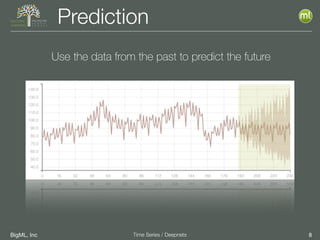
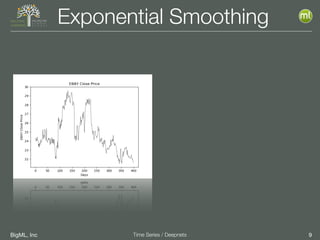
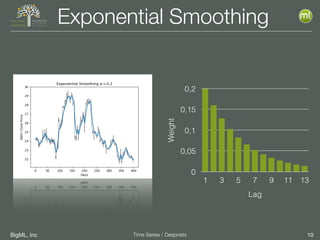
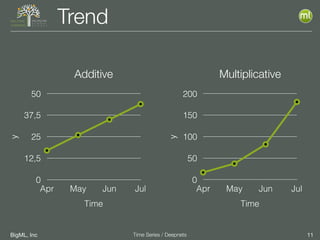
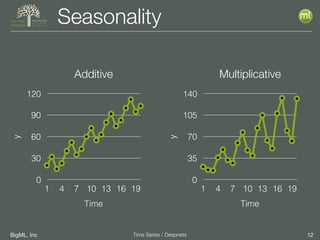
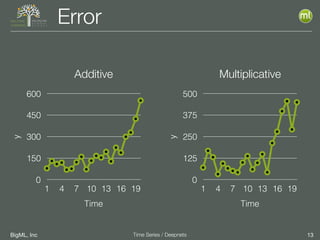


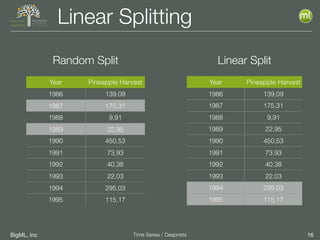



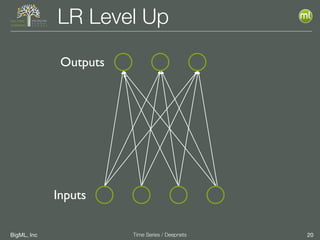
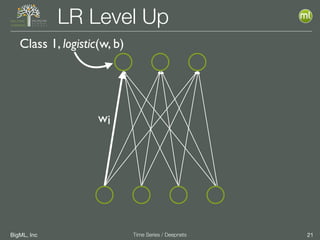
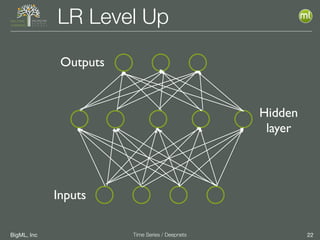
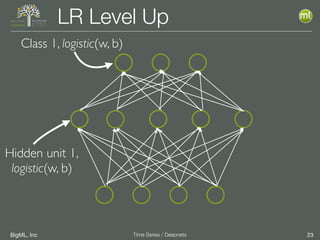
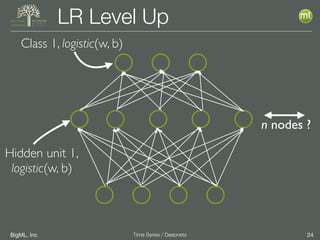
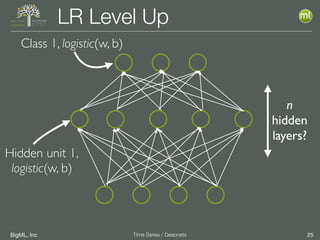
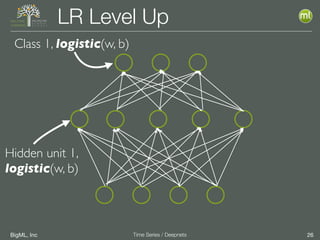




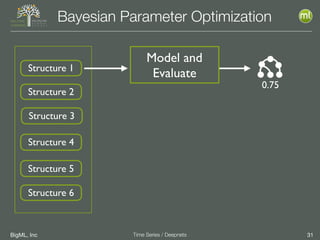
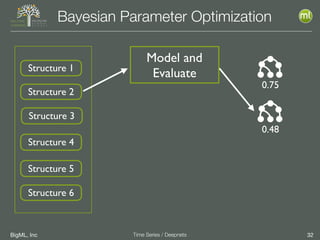
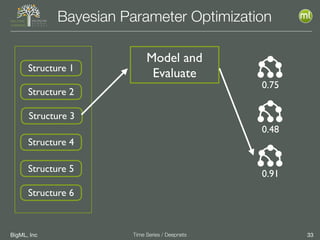
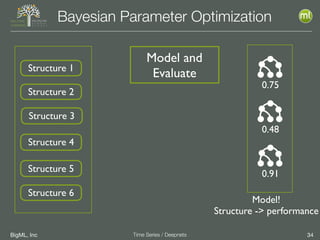
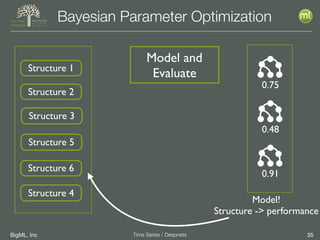



The document discusses the 3rd edition of the Valencian Summer School in Machine Learning, focusing on time series analysis and deep learning. It highlights challenges such as data assumptions, prediction methods, and model evaluation criteria in machine learning. Additionally, it addresses the rise of deep learning powered by advancements in algorithms, data availability, and computational resources.























































































