Download as PDF, PPTX



















![Example workflow: Python bindings
# Now do it 100 times, serially
for i in range(0, 100):
r, s = 0.8, i
train = api.create_dataset(dataset, {"rate": r, "seed": s})
test = api.create_dataset(dataset, {"rate": r, "seed": s, "out_of_bag": True})
api.ok(train)
model.append(api.create_model(train))
api.ok(model)
api.ok(test)
evaluation.append(api.create_evaluation(model, test))
api.ok(evaluation[i])
30 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-35-320.jpg)
![Example workflow: Python bindings
# More efficient if we parallelize, but at what level?
for i in range(0, 100):
r, s = 0.8, i
train.append(api.create_dataset(dataset, {"rate": r, "seed": s}))
test.append(api.create_dataset(dataset, {"rate": r, "seed": s, "out_of_bag": True})
# Do we wait here?
api.ok(train[i])
api.ok(test[i])
for i in range(0, 100):
model.append(api.create_model(train[i]))
api.ok(model[i])
for i in range(0, 100):
evaluation.append(api.create_evaluation(model, test_dataset))
api.ok(evaluation[i])
31 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-36-320.jpg)
![Example workflow: Python bindings
# More efficient if we parallelize, but at what level?
for i in range(0, 100):
r, s = 0.8, i
train.append(api.create_dataset(dataset, {"rate": r, "seed": s}))
test.append(api.create_dataset(dataset, {"rate": r, "seed": s, "out_of_bag": True})
for i in range(0, 100):
# Or do we wait here?
api.ok(train[i])
model.append(api.create_model(train[i]))
for i in range(0, 100):
# and here?
api.ok(model[i])
api.ok(train[i])
evaluation.append(api.create_evaluation(model, test_dataset))
api.ok(evaluation[i])
32 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-37-320.jpg)
![Example workflow: Python bindings
# More efficient if we parallelize, but how do we handle errors??
for i in range(0, 100):
r, s = 0.8, i
train.append(api.create_dataset(dataset, {"rate": r, "seed": s}))
test.append(api.create_dataset(dataset, {"rate": r, "seed": s, "out_of_bag": True})
for i in range(0, 100):
api.ok(train[i])
model.append(api.create_model(train[i]))
for i in range(0, 100):
try:
api.ok(model[i])
api.ok(test[i])
evaluation.append(api.create_evaluation(model, test_dataset))
api.ok(evaluation[i])
except:
# How to recover if test[i] is failed? New datasets? Abort?
33 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-38-320.jpg)










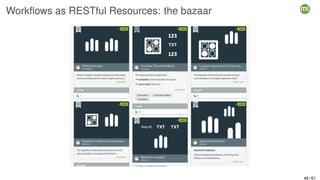



![Syntactic Abstraction in WhizzML: Simple workflow
;; ML artifacts are first-class citizens,
;; we only need to talk about our domain
(let ([train-id test-id] (create-dataset-split id 0.8)
model-id (create-model train-id))
(create-evaluation test-id
model-id
{"name" "Evaluation 80/20"
"missing_strategy" 0}))
53 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-61-320.jpg)
![Syntactic Abstraction in WhizzML: Simple workflow
;; ML artifacts are first-class citizens,
;; we only need to talk about our domain
(let ([train-id test-id] (create-dataset-split id 0.8)
model-id (create-model train-id))
(create-evaluation test-id
model-id
{"name" "Evaluation 80/20"
"missing_strategy" 0}))
Ready for production!
53 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-62-320.jpg)
![Domain Specificity and Scalability: Trivial parallelization
;; Workflow for 1 resource
(let ([train-id test-id] (create-dataset-split id 0.8)
model-id (create-model train-id))
(create-evaluation test-id model-id))
54 / 61](https://image.slidesharecdn.com/dutchmlschool2022automation-220726082007-b87b2fb8/85/DutchMLSchool-2022-Automation-63-320.jpg)


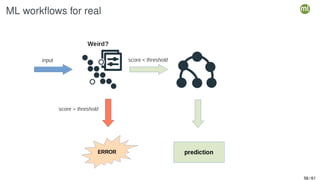





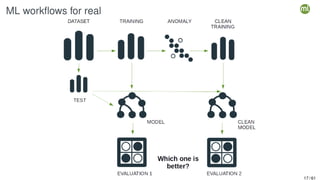
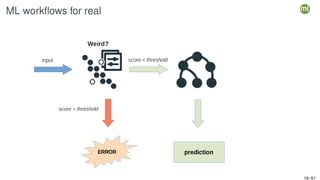
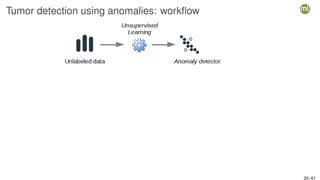
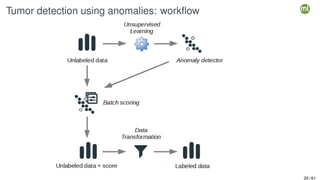
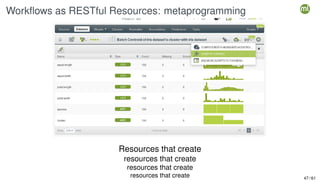
The document outlines the second edition of a workshop by BigML focusing on automating and deploying machine learning projects. It discusses various aspects such as machine learning as a system service, RESTful services, and client-side automation, while emphasizing the importance of accessibility, integrability, and ease of use in ML workflows. Furthermore, it introduces WhizzML, a domain-specific language aimed at simplifying workflow automation and enhancing scalability.
















































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)




