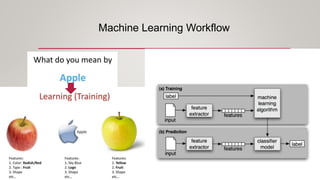
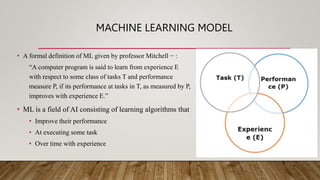
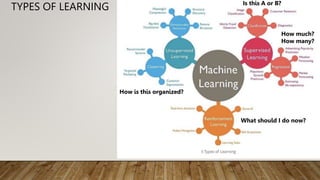
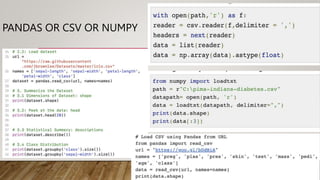
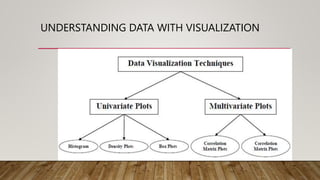
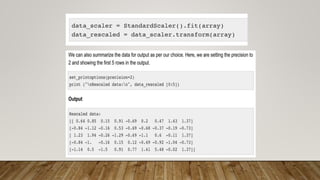
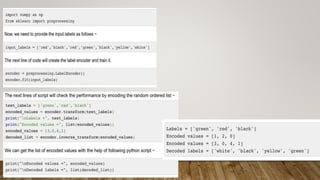
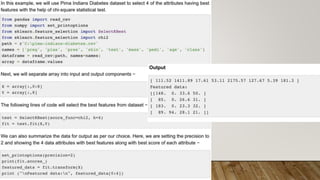
This document provides an overview of machine learning, including definitions of key concepts like tasks, experience, and performance in machine learning. It also discusses common machine learning workflows like data loading, understanding data through statistics and visualization, preparing data through techniques like scaling and normalization, selecting features, and discussing applications and types of machine learning. It provides examples of challenges in machine learning and techniques for data preparation and feature selection.









































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)














![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)