Download as PDF, PPTX



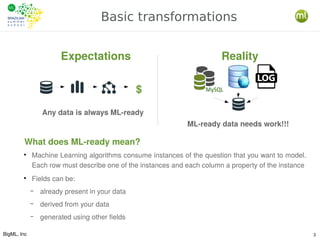



















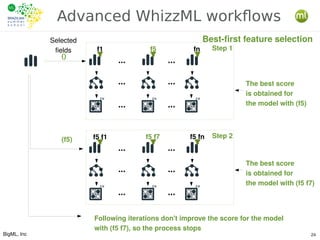

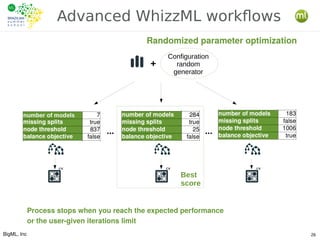

The document outlines the key processes involved in data preparation and feature engineering for machine learning (ML), emphasizing the transformation of raw data into 'ML-ready' formats through cleansing, denormalization, and other data wrangling techniques. Additionally, it introduces BigML's REST API and various tools that facilitate workflow automation and abstraction in ML tasks, including the use of Whizzml for creating and managing complex workflows. It highlights the importance of statistical relationships between features and objectives to improve model performance and the role of feature engineering in achieving these goals.























































































