Download as PDF, PPTX










![BigML, Inc #DutchMLSchool 13
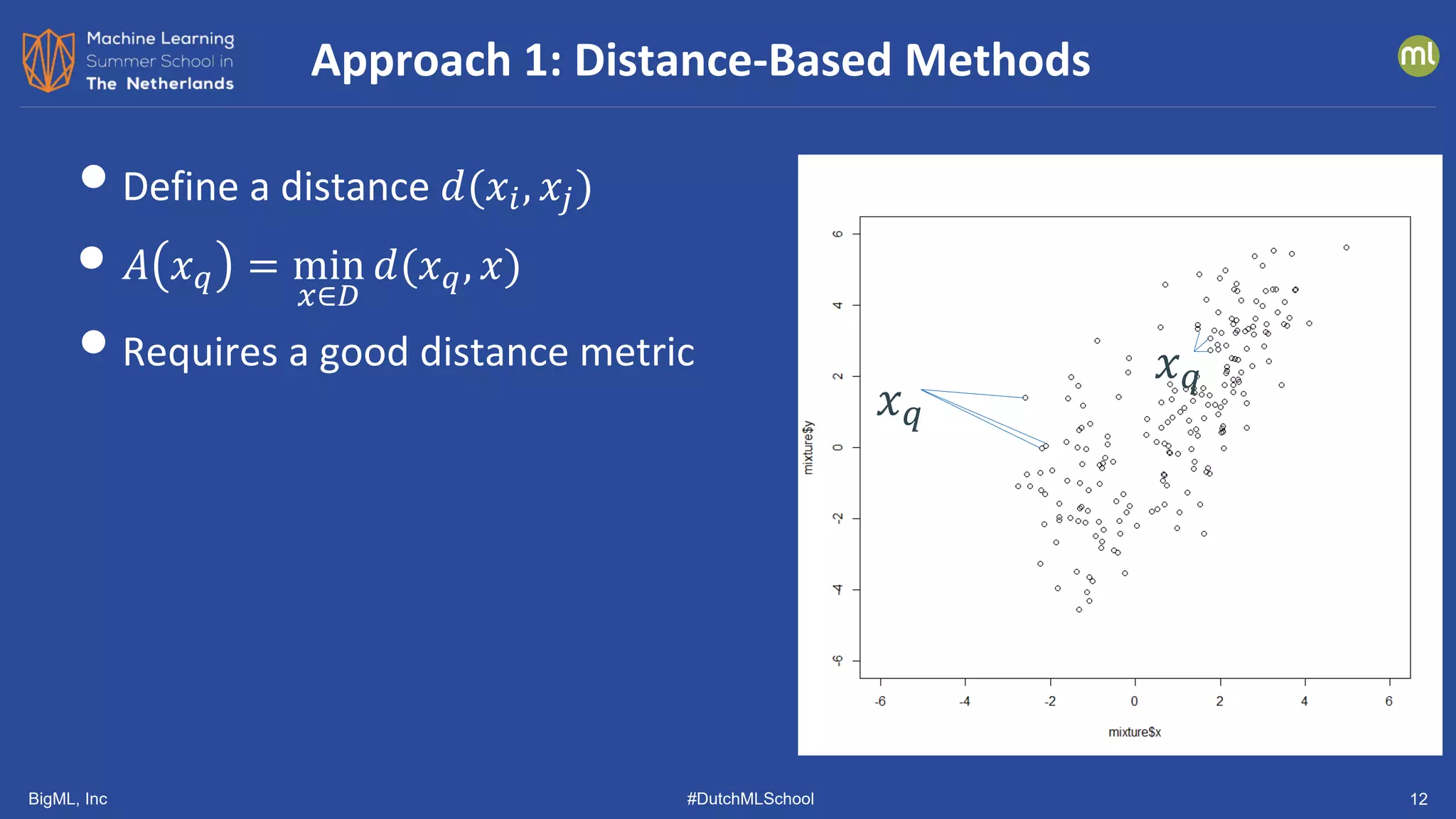
• Approximates L1 (Manhattan) Distance
• (Guha, et al., ICML 2016)
• Construct a fully random binary tree
• choose attribute 𝑗𝑗 at random
• choose splitting threshold 𝜃𝜃 uniformly from
min 𝑥𝑥⋅𝑗𝑗 , max 𝑥𝑥⋅𝑗𝑗
• until every data point is in its own leaf
• let 𝑑𝑑(𝑥𝑥𝑖𝑖) be the depth of point 𝑥𝑥𝑖𝑖
• repeat 𝐿𝐿 times
• let ̅
𝑑𝑑(𝑥𝑥𝑖𝑖) be the average depth of 𝑥𝑥𝑖𝑖
• 𝐴𝐴 𝑥𝑥𝑖𝑖 = 2
−
�
𝑑𝑑 𝑥𝑥𝑖𝑖
𝑟𝑟 𝑥𝑥𝑖𝑖
• 𝑟𝑟(𝑥𝑥𝑖𝑖) is the expected depth
Isolation Forest [Liu, Ting, Zhou, 2011]
𝑥𝑥⋅𝑗𝑗
𝑥𝑥⋅𝑗𝑗 > 𝜃𝜃
𝑥𝑥⋅2 > 𝜃𝜃2 𝑥𝑥⋅8 > 𝜃𝜃3
𝑥𝑥⋅3 > 𝜃𝜃4 𝑥𝑥⋅1 > 𝜃𝜃5
𝑥𝑥𝑖𝑖](https://image.slidesharecdn.com/dutchmlschool2022tom-dietterich-bigml-220720103646-f0de4afa/75/DutchMLSchool-2022-History-and-Developments-in-ML-13-2048.jpg)


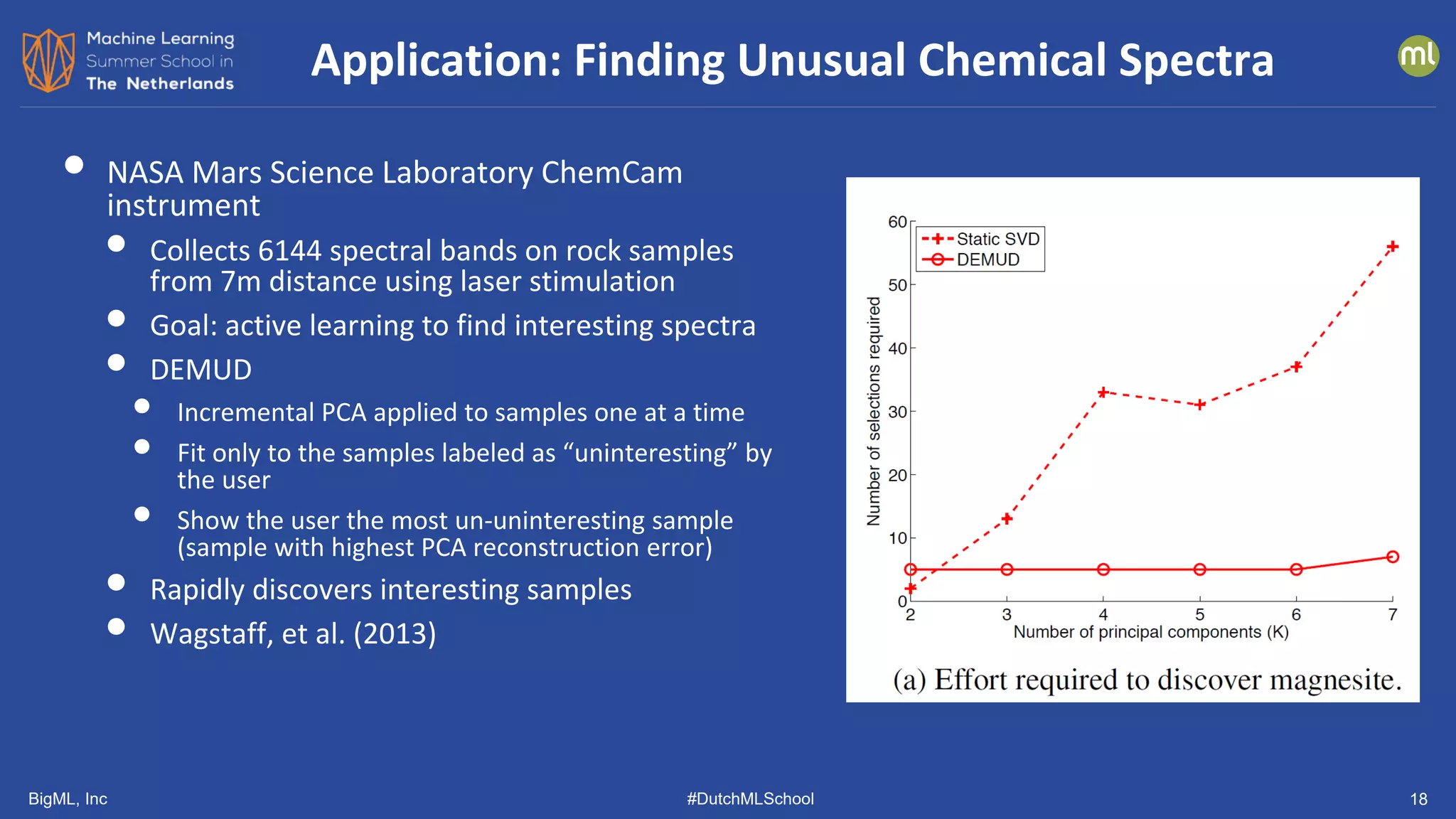
![BigML, Inc #DutchMLSchool 19
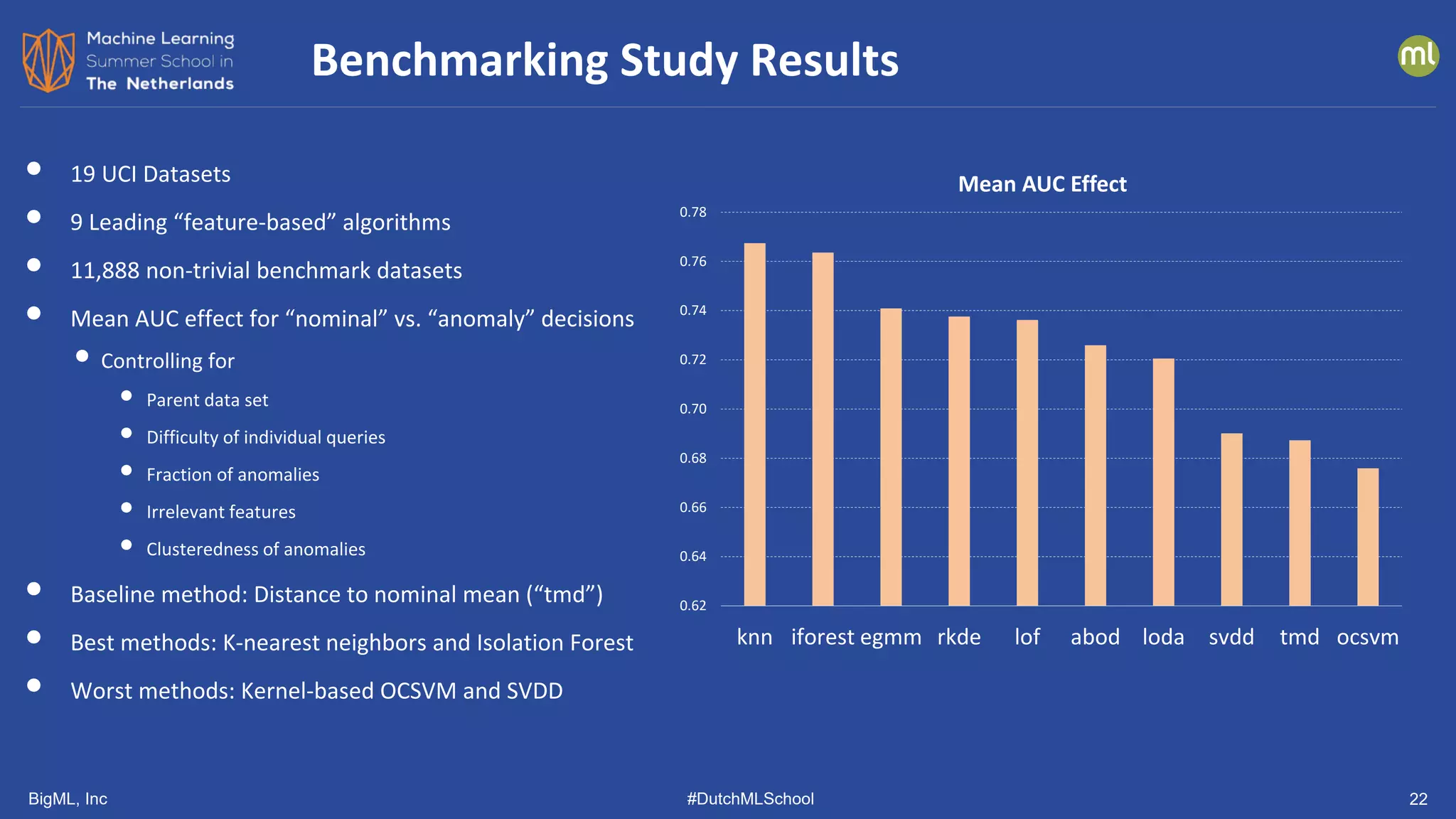
• Distance-Based Methods
• k-NN: Mean distance to 𝑘𝑘-nearest neighbors
• LOF: Local Outlier Factor (Breunig, et al., 2000)
• ABOD: kNN Angle-Based Outlier Detector (Kriegel, et al., 2008)
• IFOR: Isolation Forest (Liu, et al., 2008)
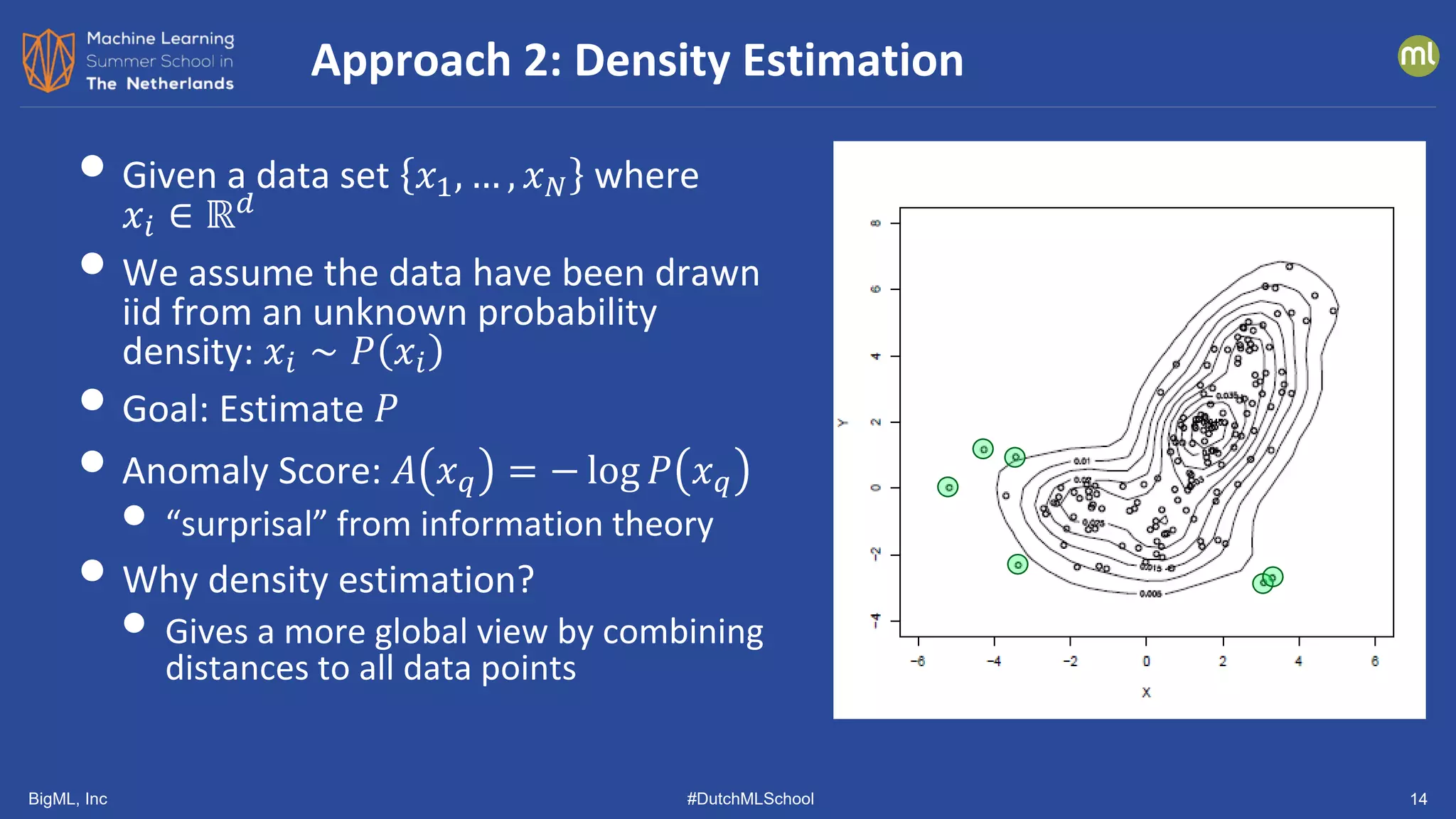
• Density-Based Approaches
• RKDE: Robust Kernel Density Estimation (Kim & Scott, 2008)
• EGMM: Ensemble Gaussian Mixture Model (our group)
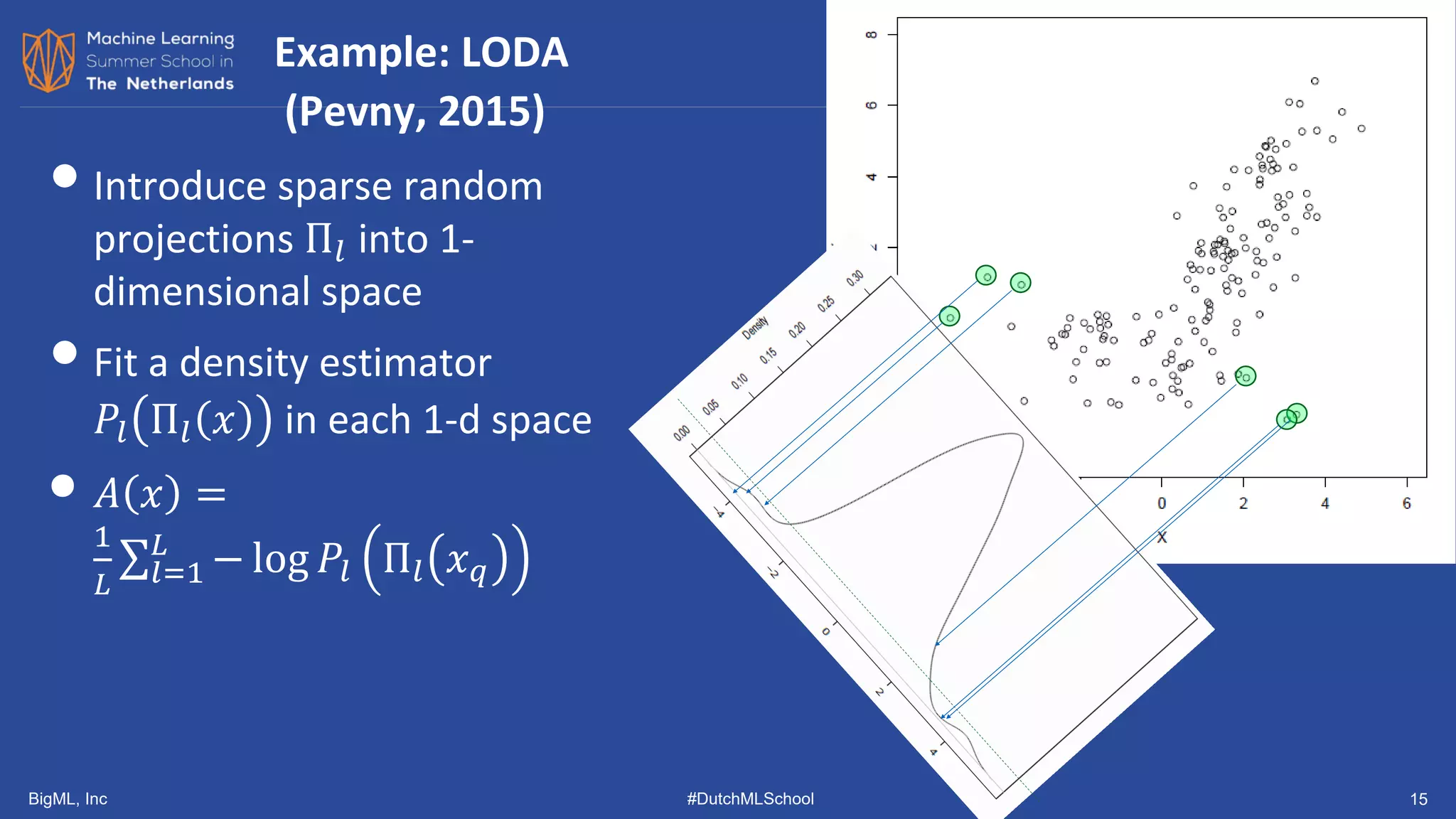
• LODA: Lightweight Online Detector of Anomalies (Pevny, 2016)
• Quantile-Based Methods
• OCSVM: One-class SVM (Schoelkopf, et al., 1999)
• SVDD: Support Vector Data Description (Tax & Duin, 2004)
Benchmarking Study [Andrew Emmott, 2015, 2020]](https://image.slidesharecdn.com/dutchmlschool2022tom-dietterich-bigml-220720103646-f0de4afa/75/DutchMLSchool-2022-History-and-Developments-in-ML-19-2048.jpg)


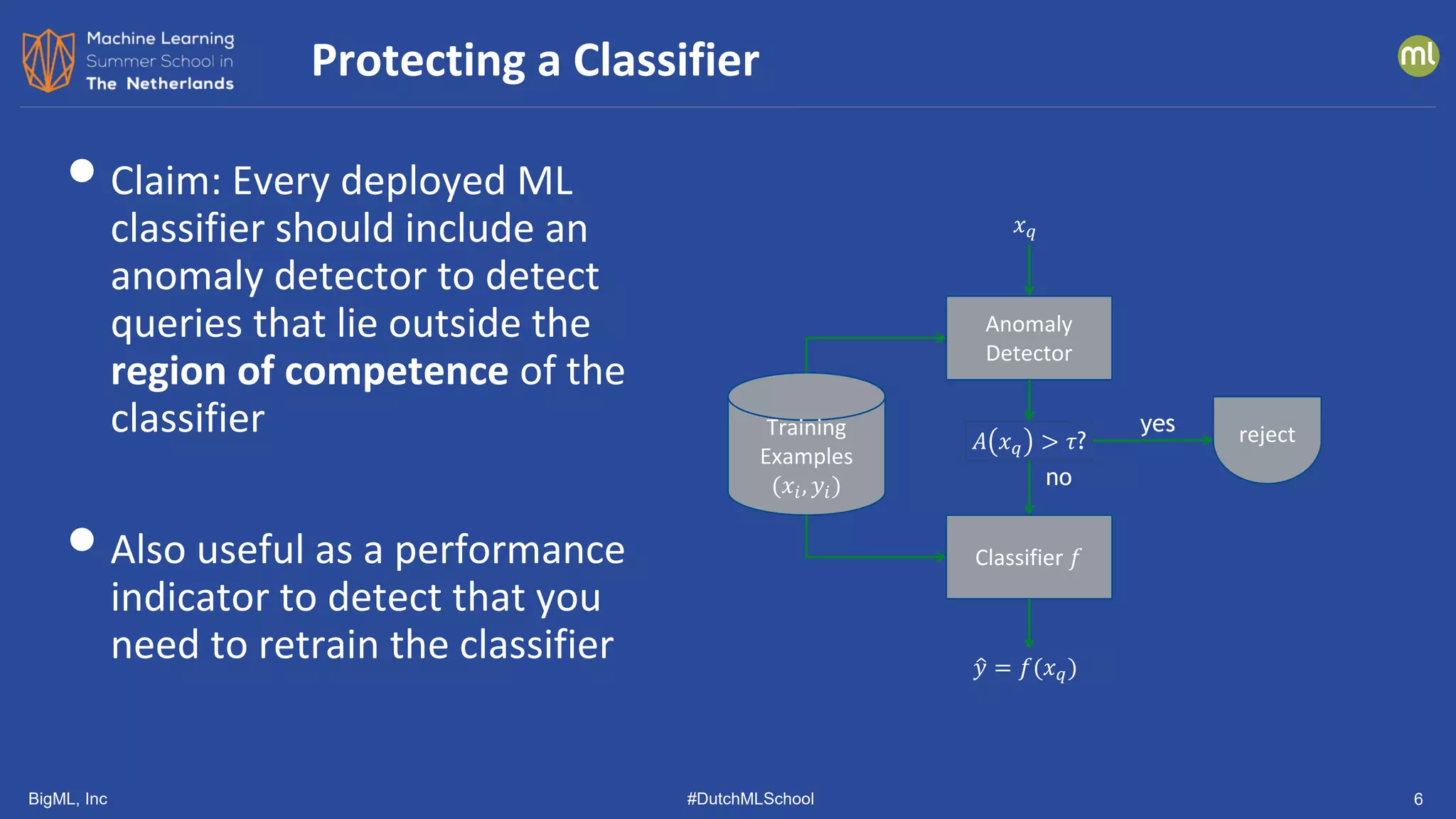
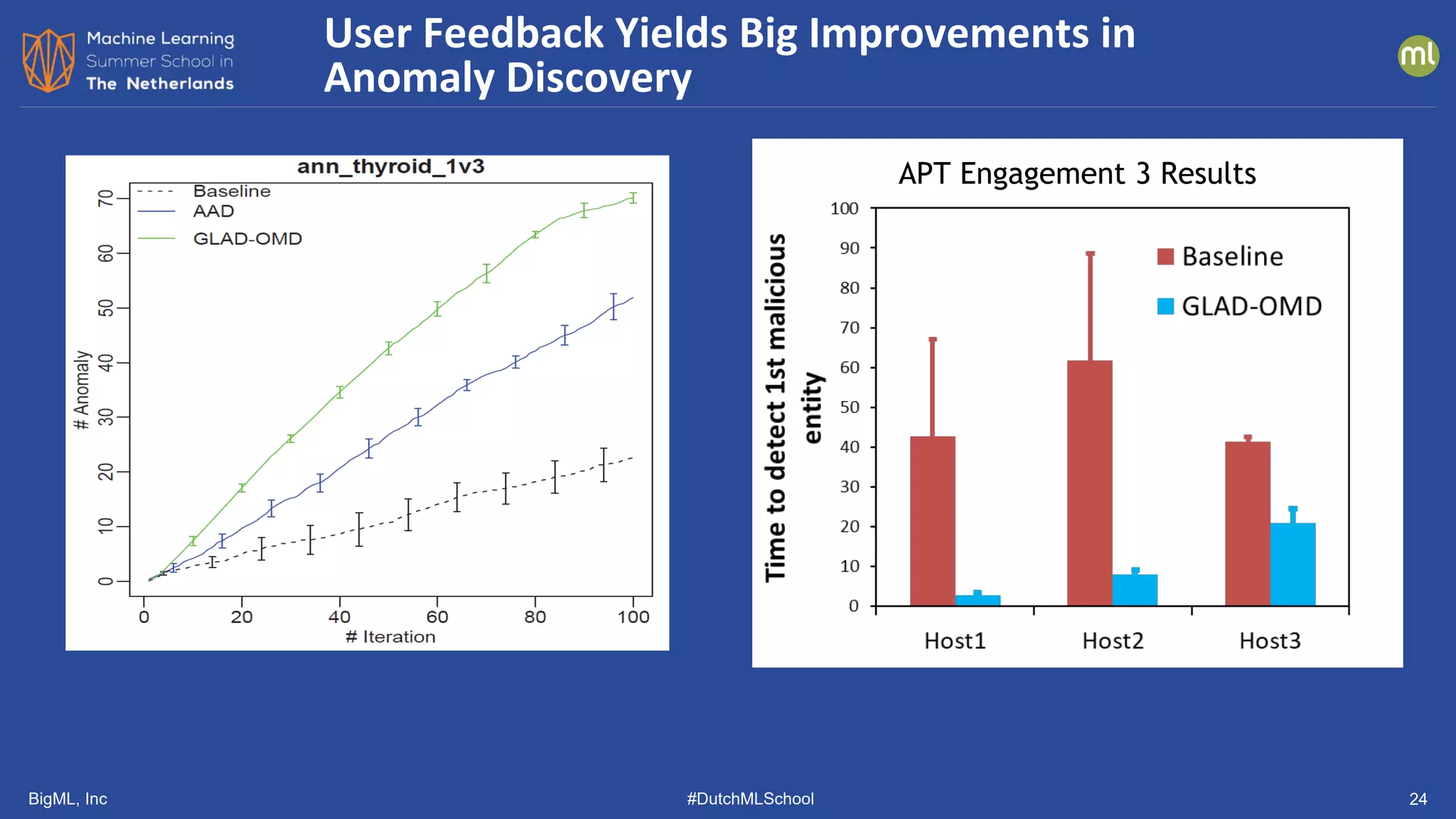
![BigML, Inc #DutchMLSchool 23
• Show top-ranked candidate to the
user
• User labels candidate
• Label is used to update the anomaly
detector
• Two methods
• AAD [Das, et al, ICDM 2016]
• GLAD-OMD (modified version of
iForest) [Siddiqui, et al., KDD 2018]
Incorporating User Feedback: Initial Work
Data
Anomaly
Detection
Best
Candidate
User
Anomaly Analysis
yes
no](https://image.slidesharecdn.com/dutchmlschool2022tom-dietterich-bigml-220720103646-f0de4afa/75/DutchMLSchool-2022-History-and-Developments-in-ML-23-2048.jpg)

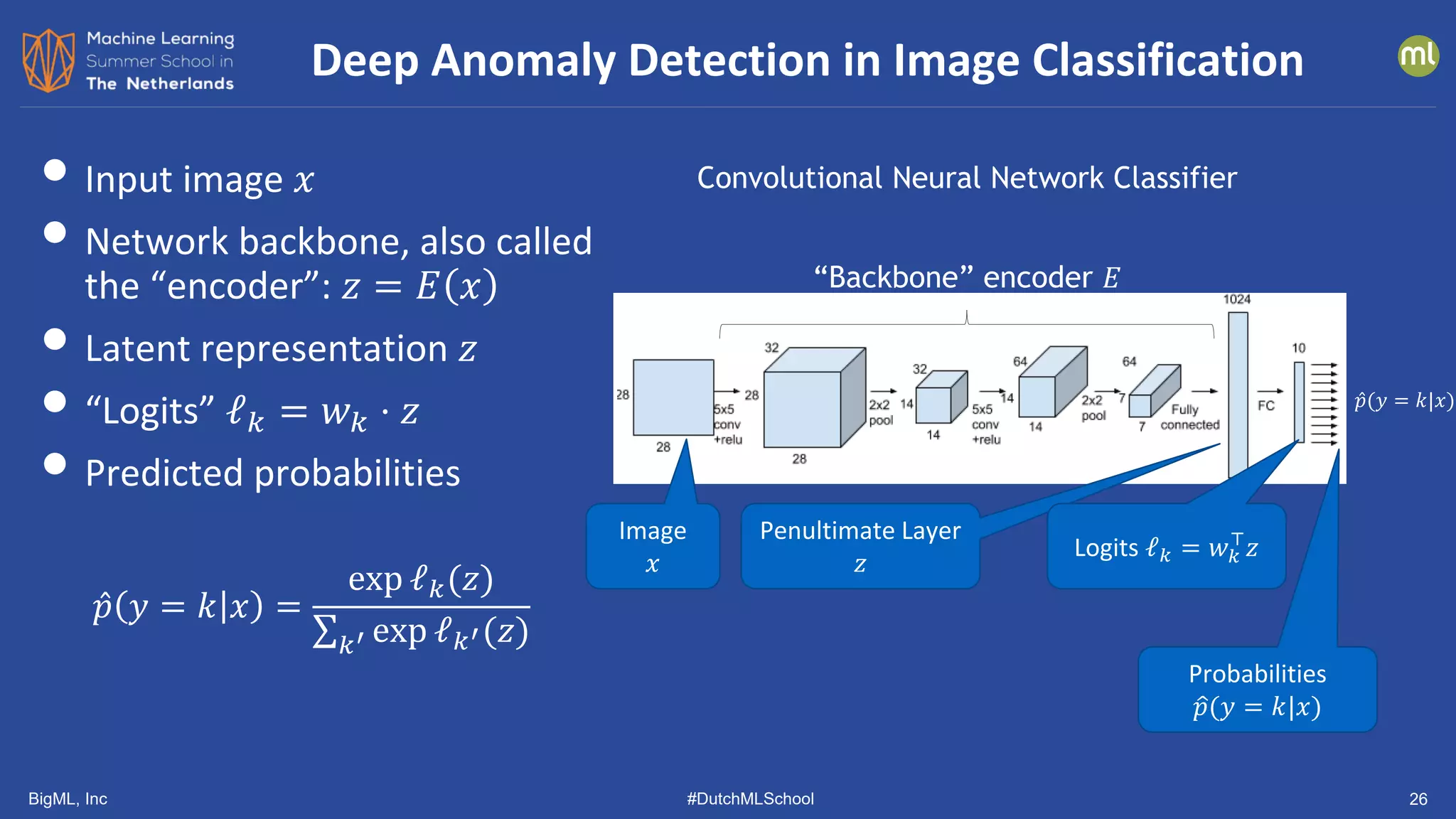





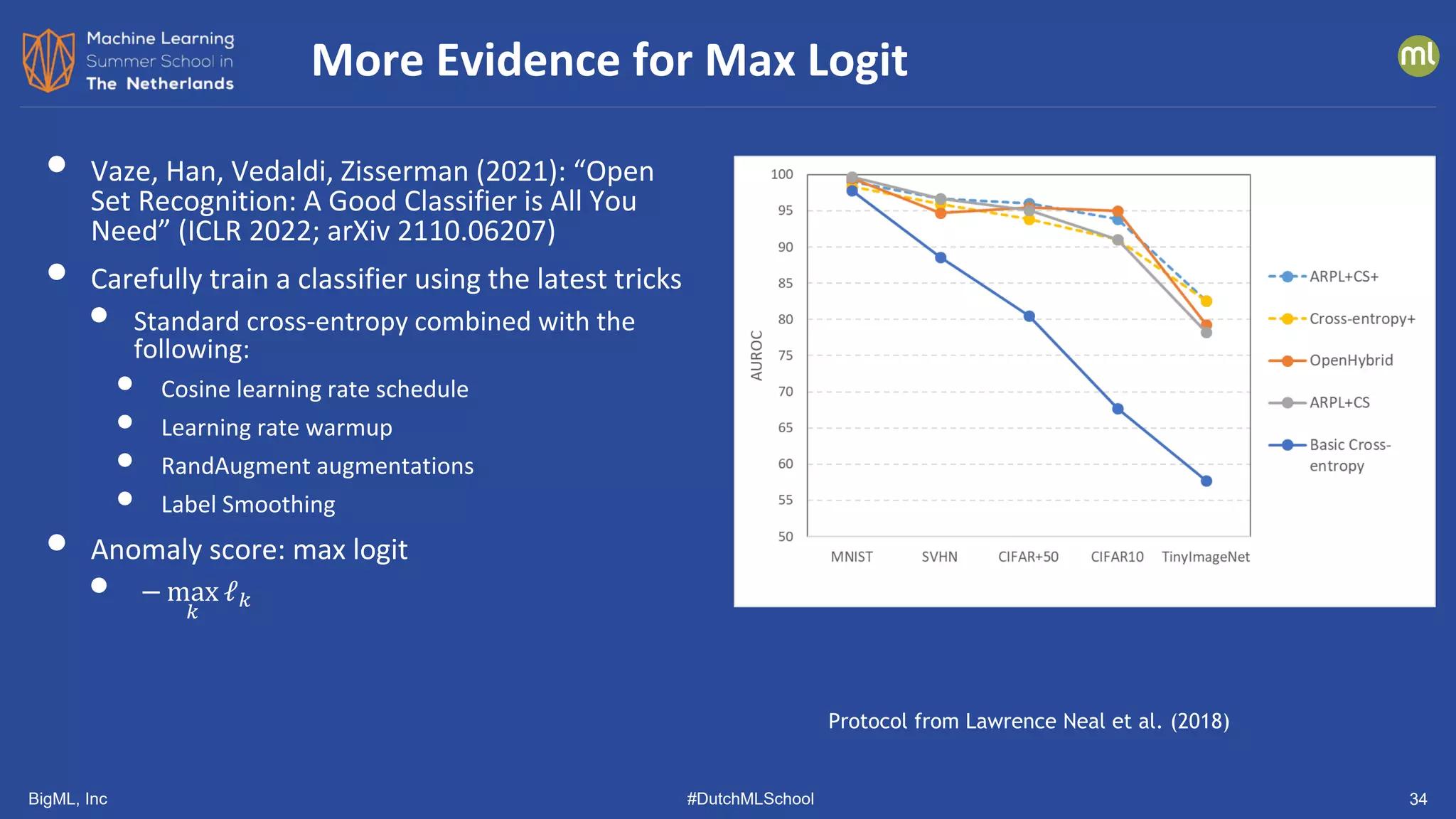
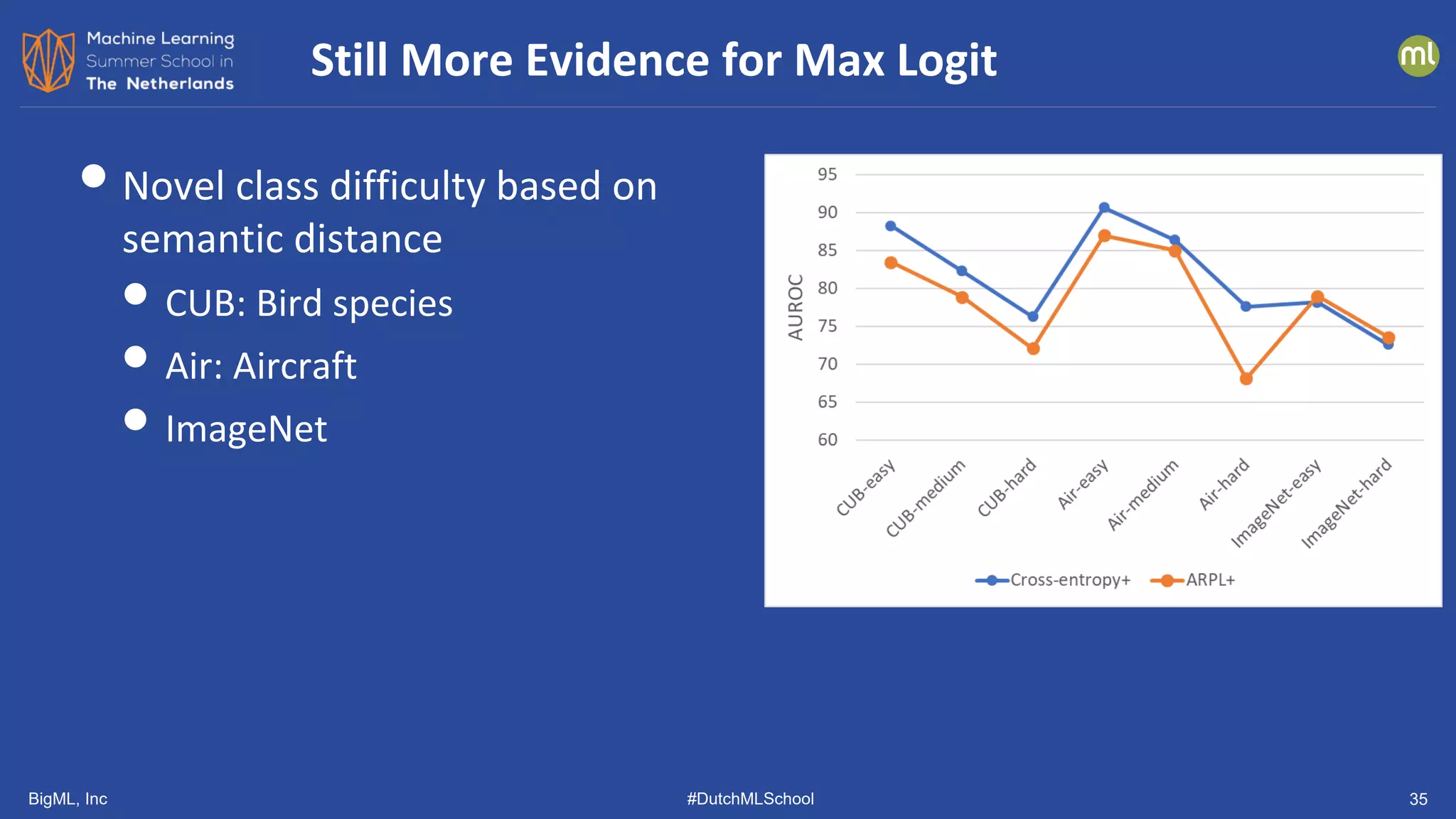

![BigML, Inc #DutchMLSchool 38
Similar Results from Other Groups
[Tack, et al. NeurIPS 2020] [Vaze, et al. arXiv 2110.06207]](https://image.slidesharecdn.com/dutchmlschool2022tom-dietterich-bigml-220720103646-f0de4afa/75/DutchMLSchool-2022-History-and-Developments-in-ML-38-2048.jpg)

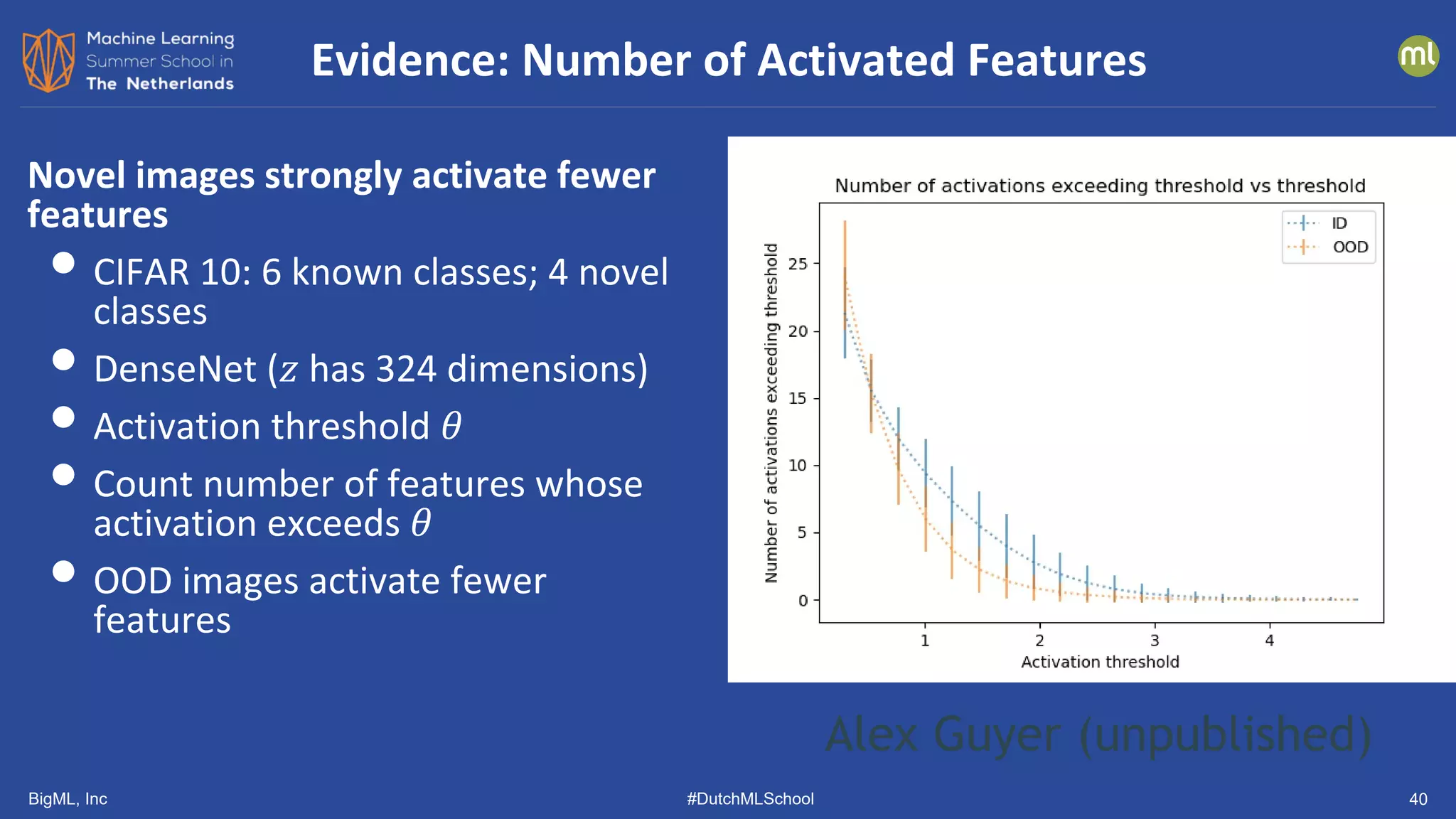





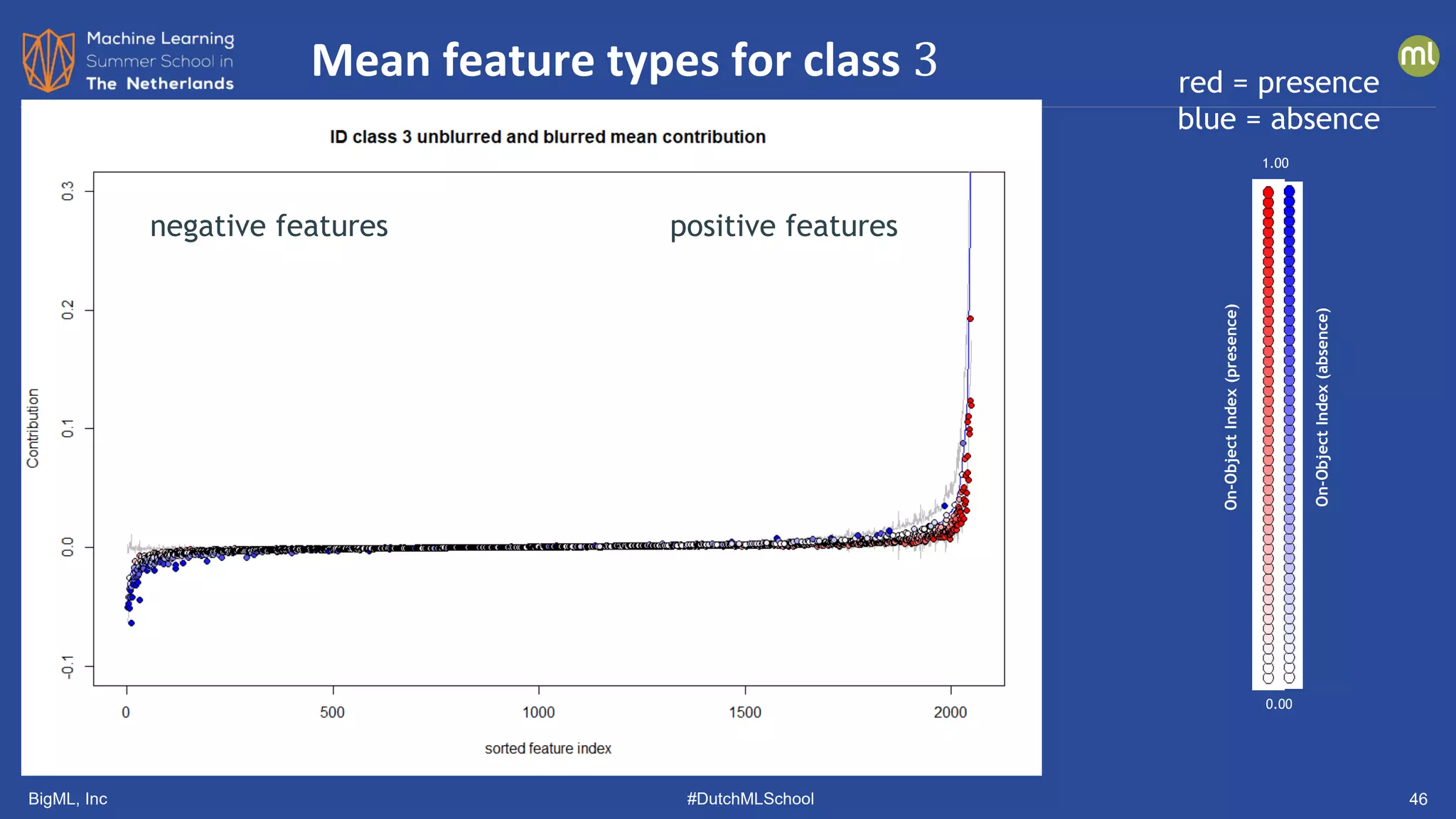
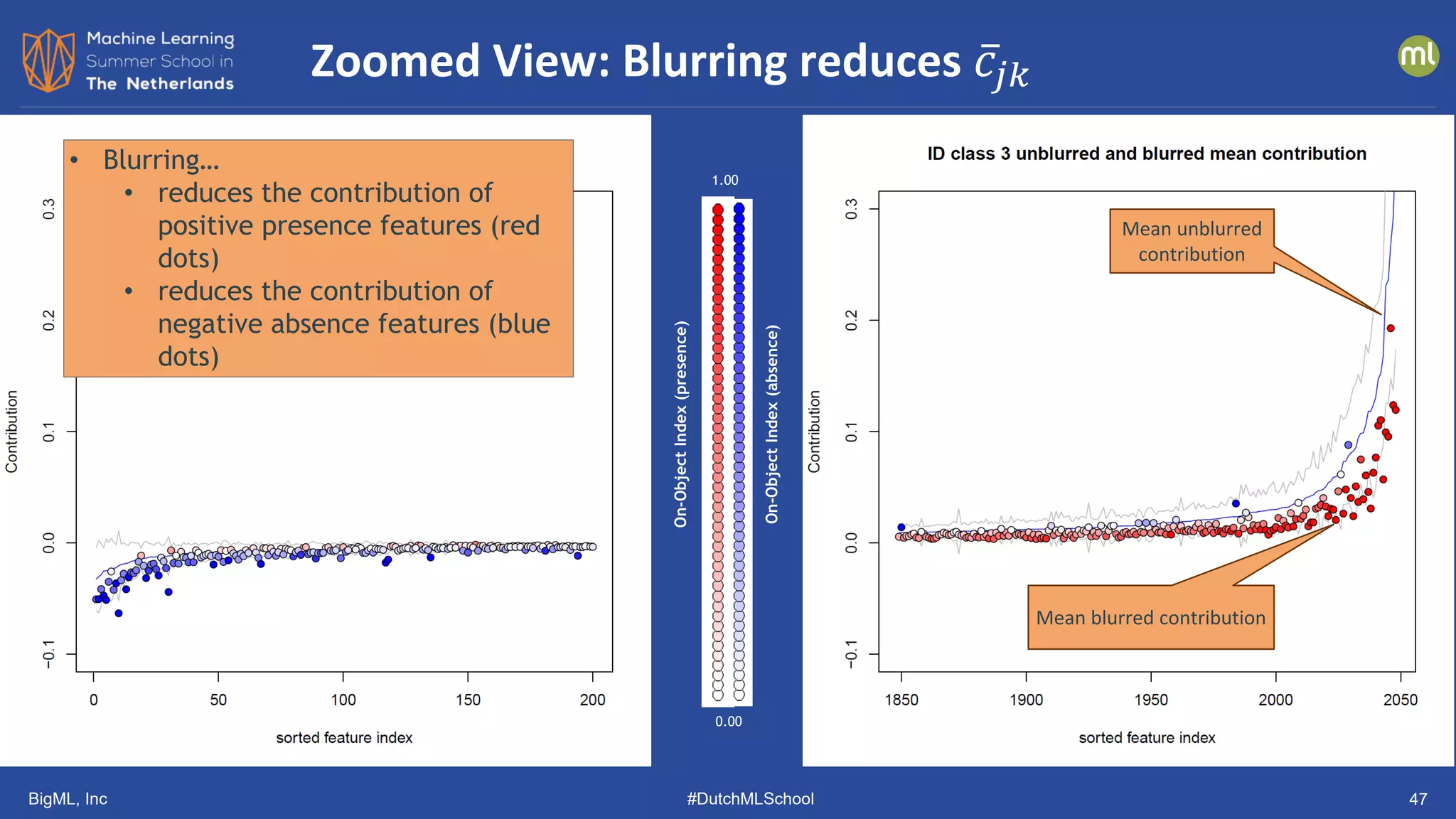
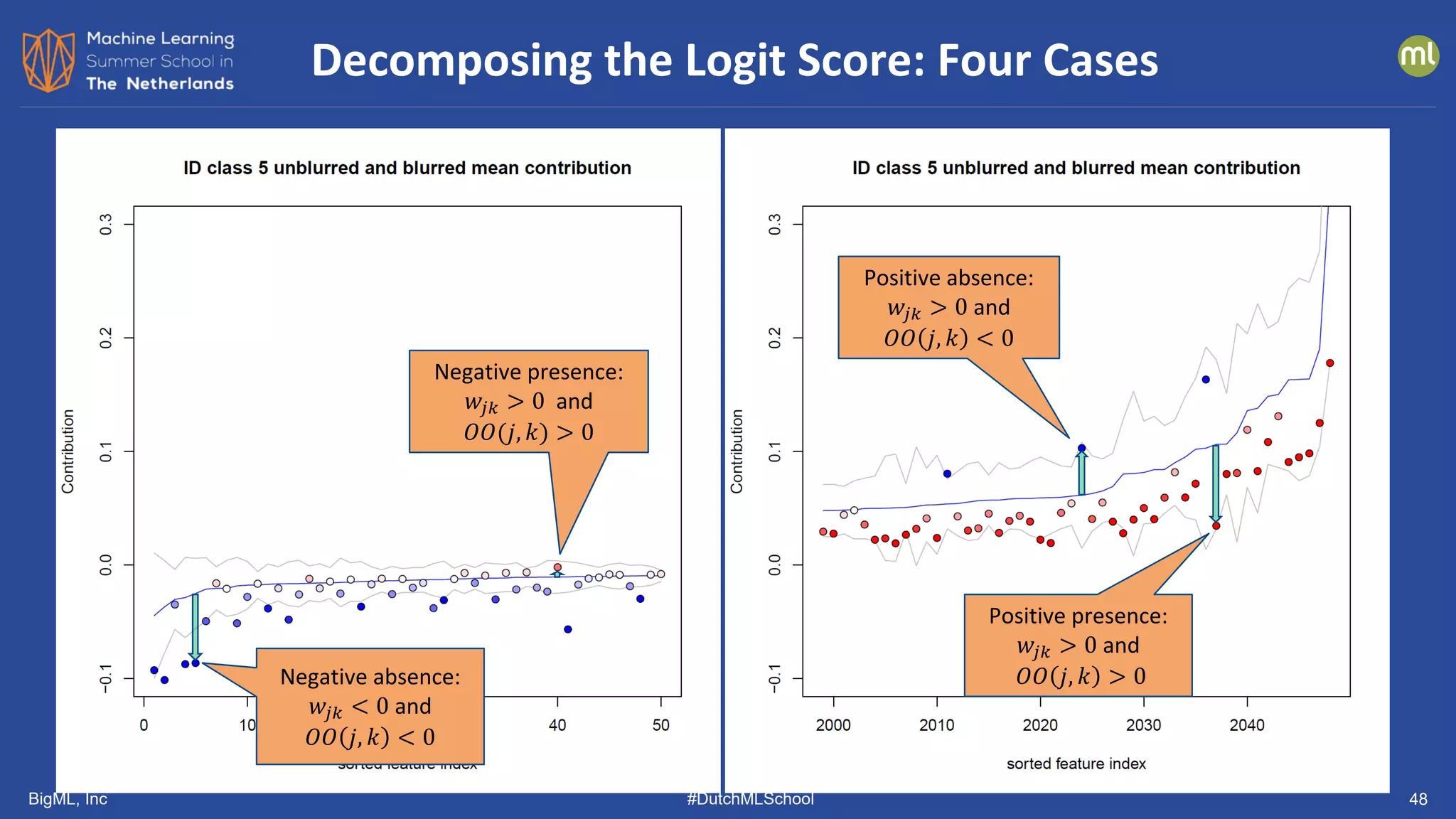
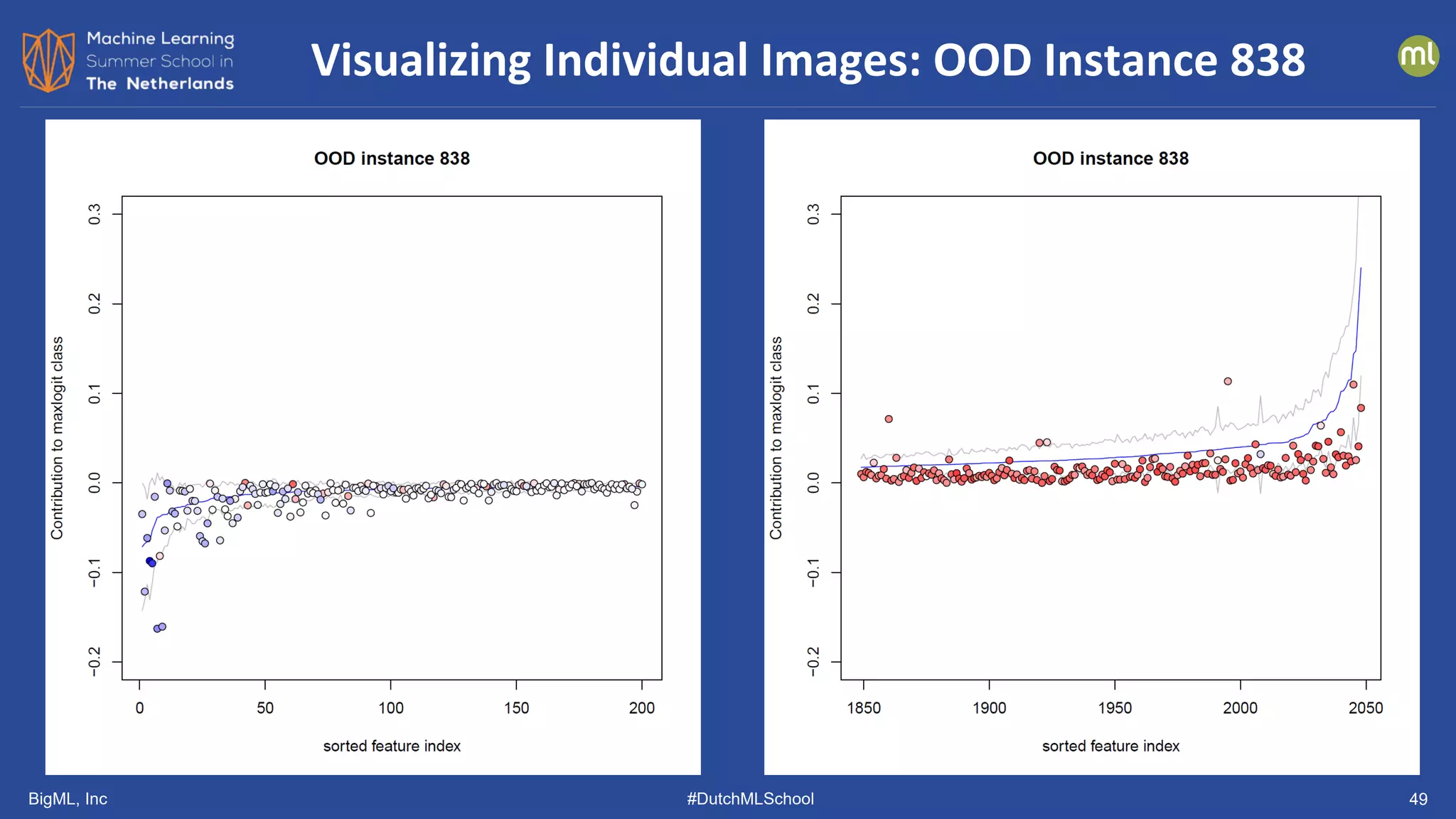
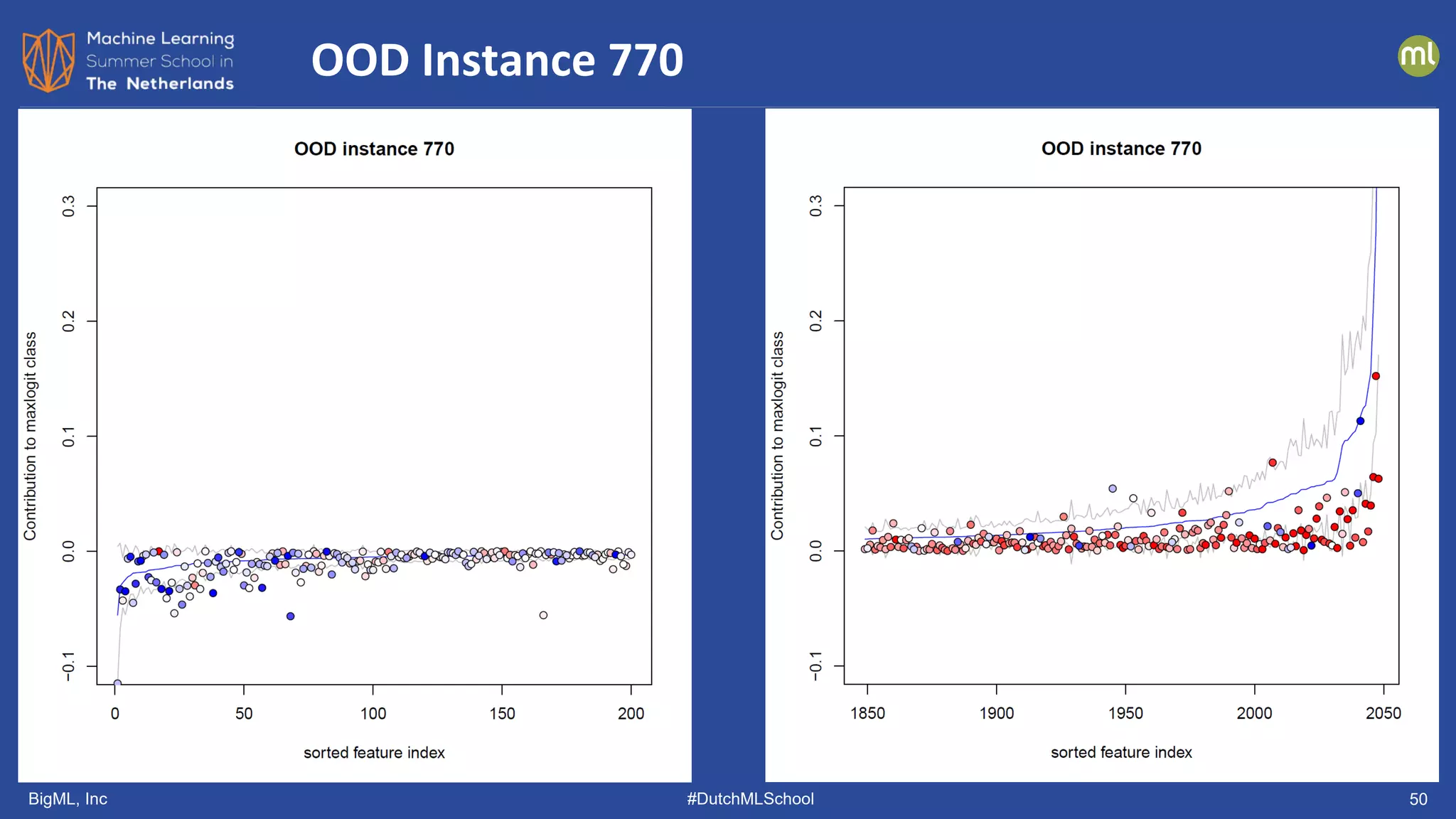
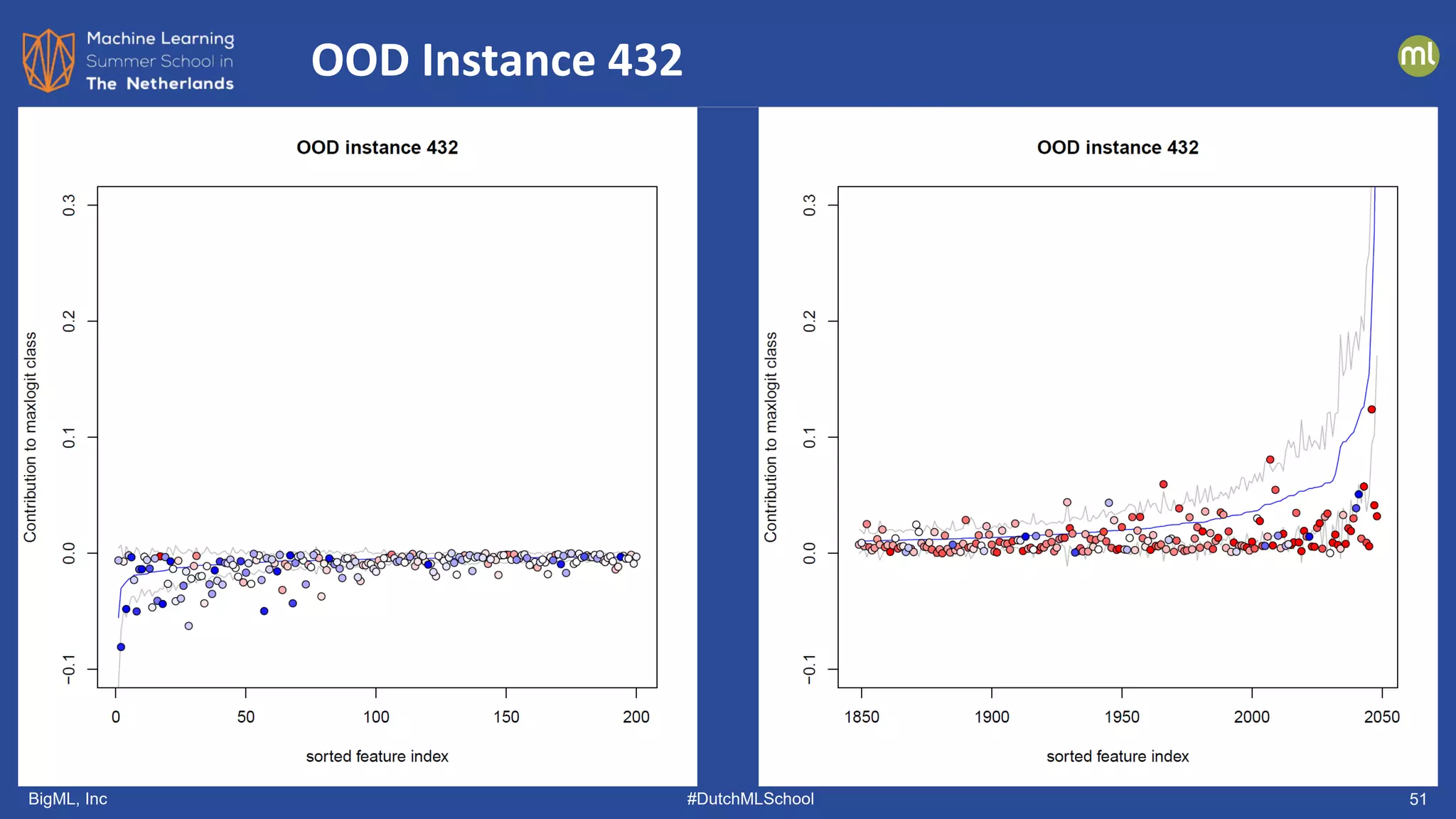
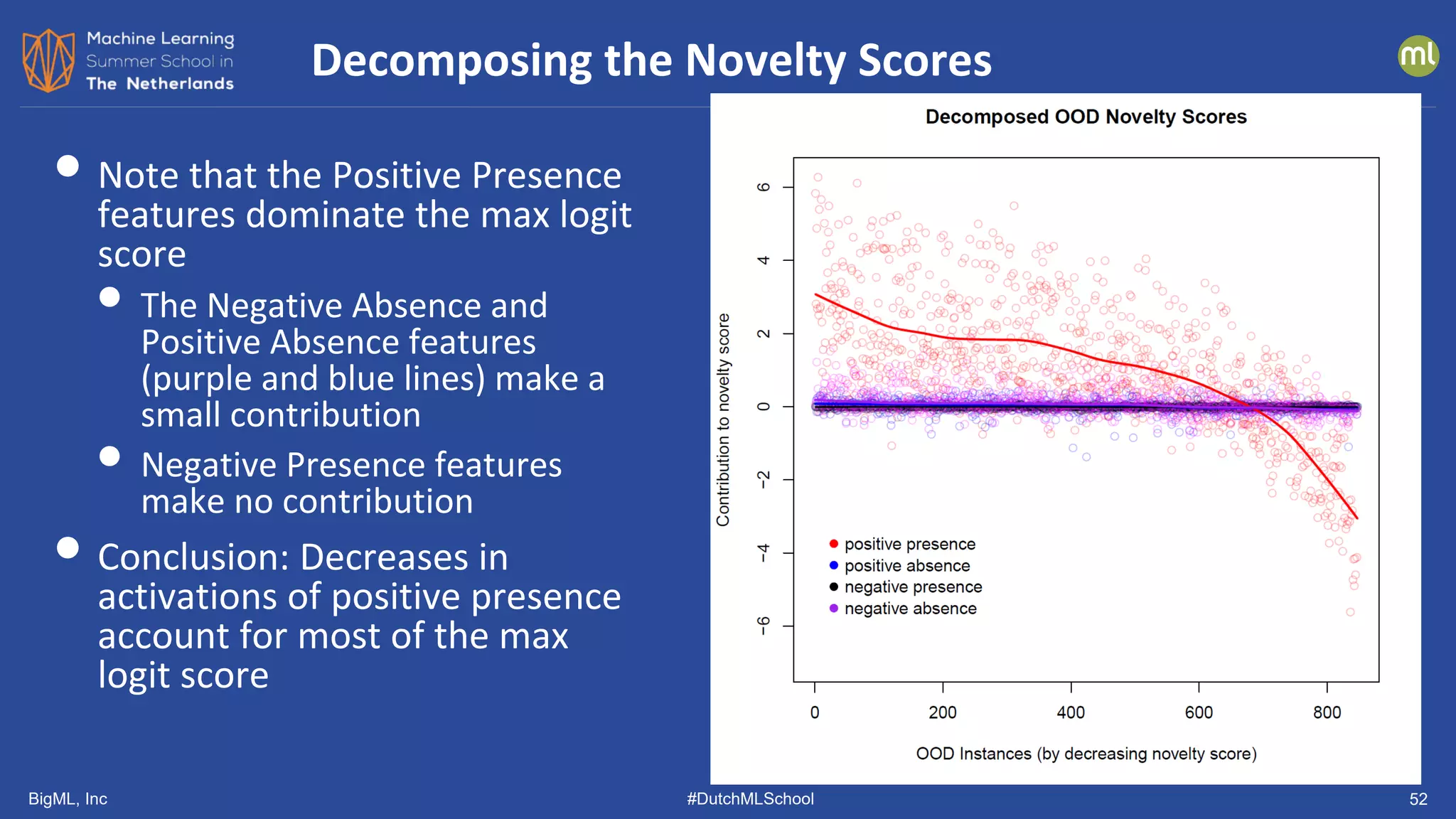
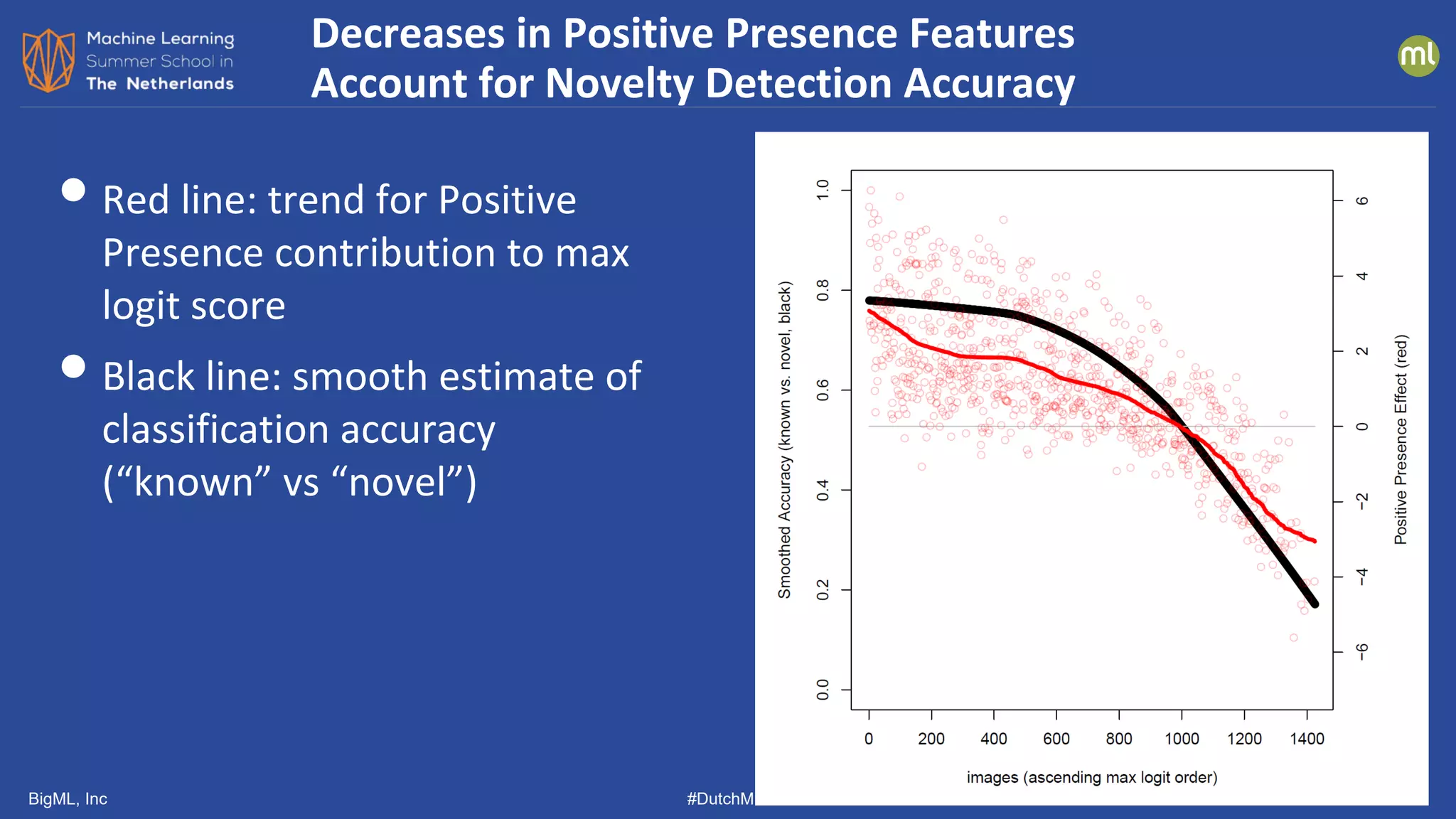








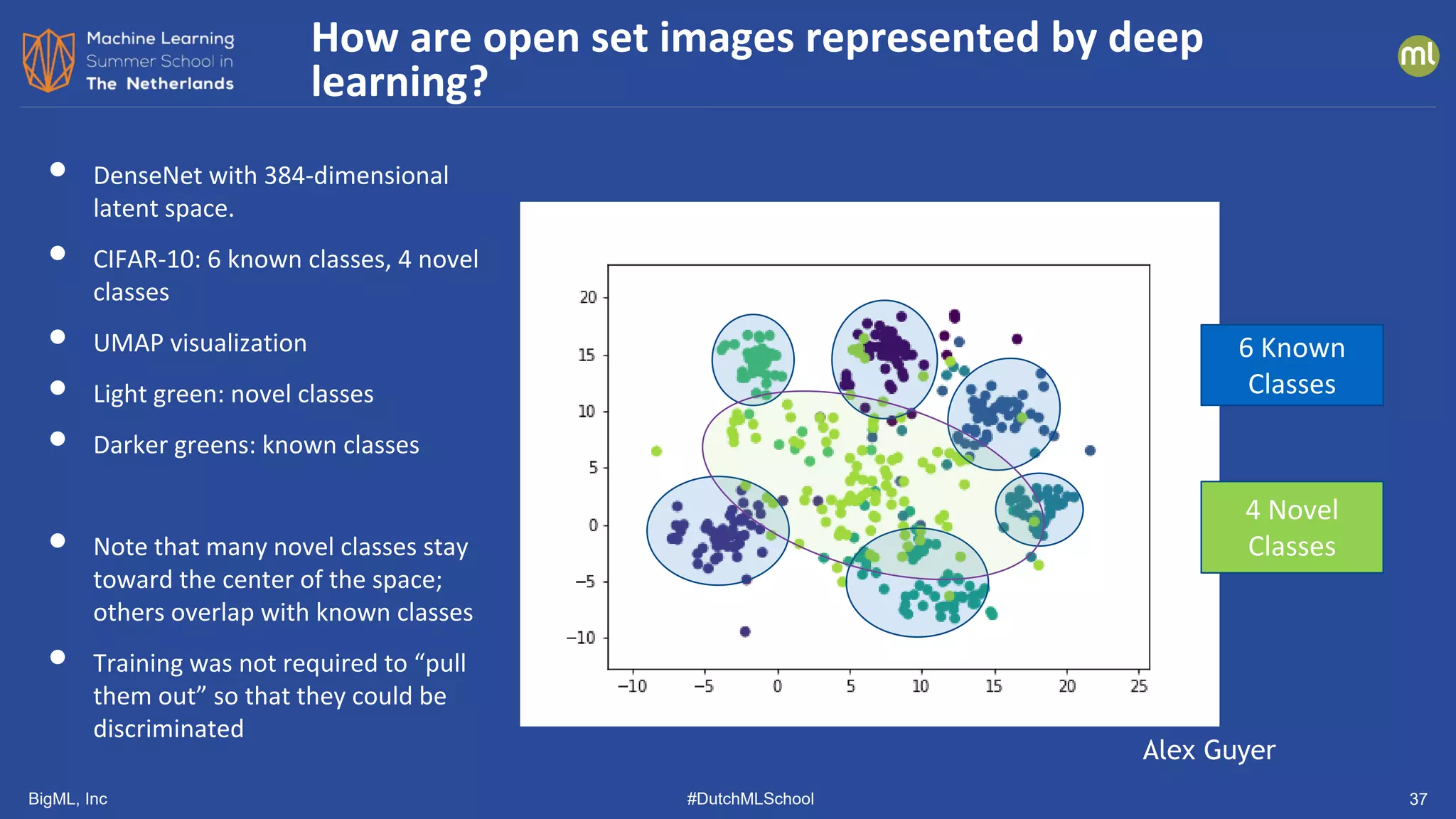
The document discusses various methods of anomaly detection, emphasizing the importance of incorporating anomaly detectors in machine learning classifiers to handle out-of-distribution instances and improve performance. It outlines four primary approaches for anomaly detection: distance-based methods, density estimation methods, quantile methods, and reconstruction methods, along with practical use cases and benchmarking studies. Additionally, it explores advancements in deep learning techniques for anomaly detection and the significance of user feedback in improving anomaly detection systems.

















































![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
