Downloaded 66 times



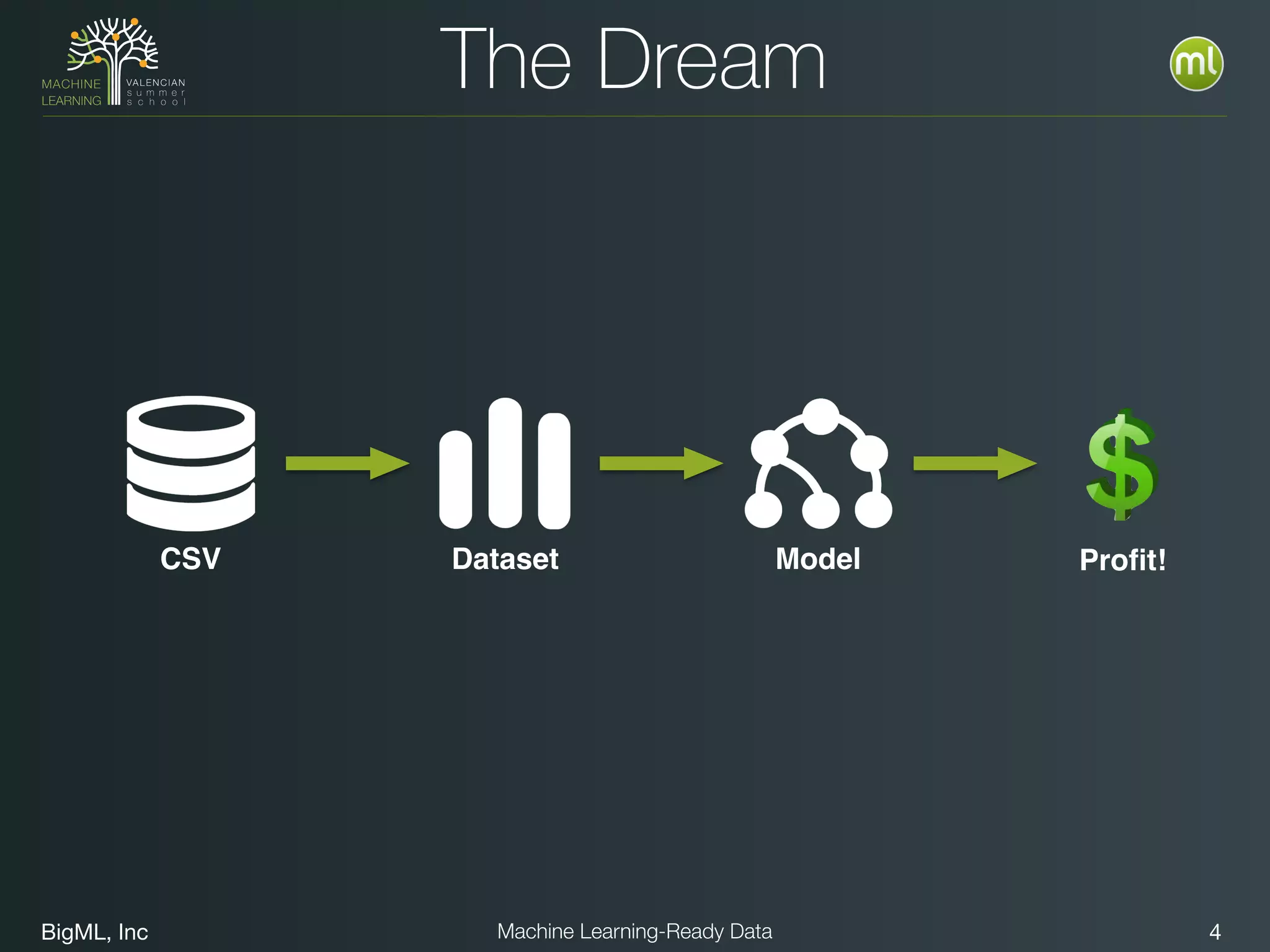
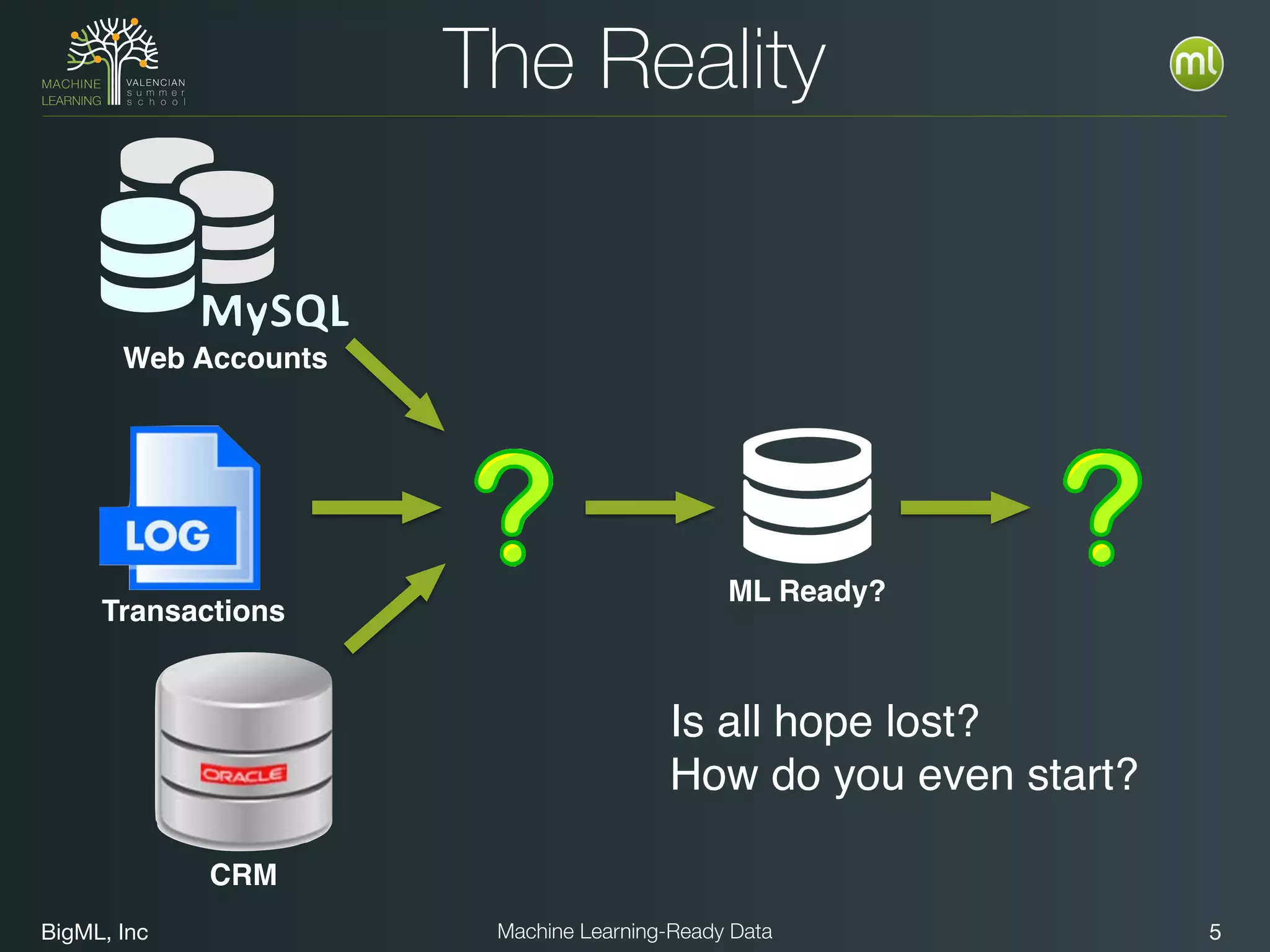




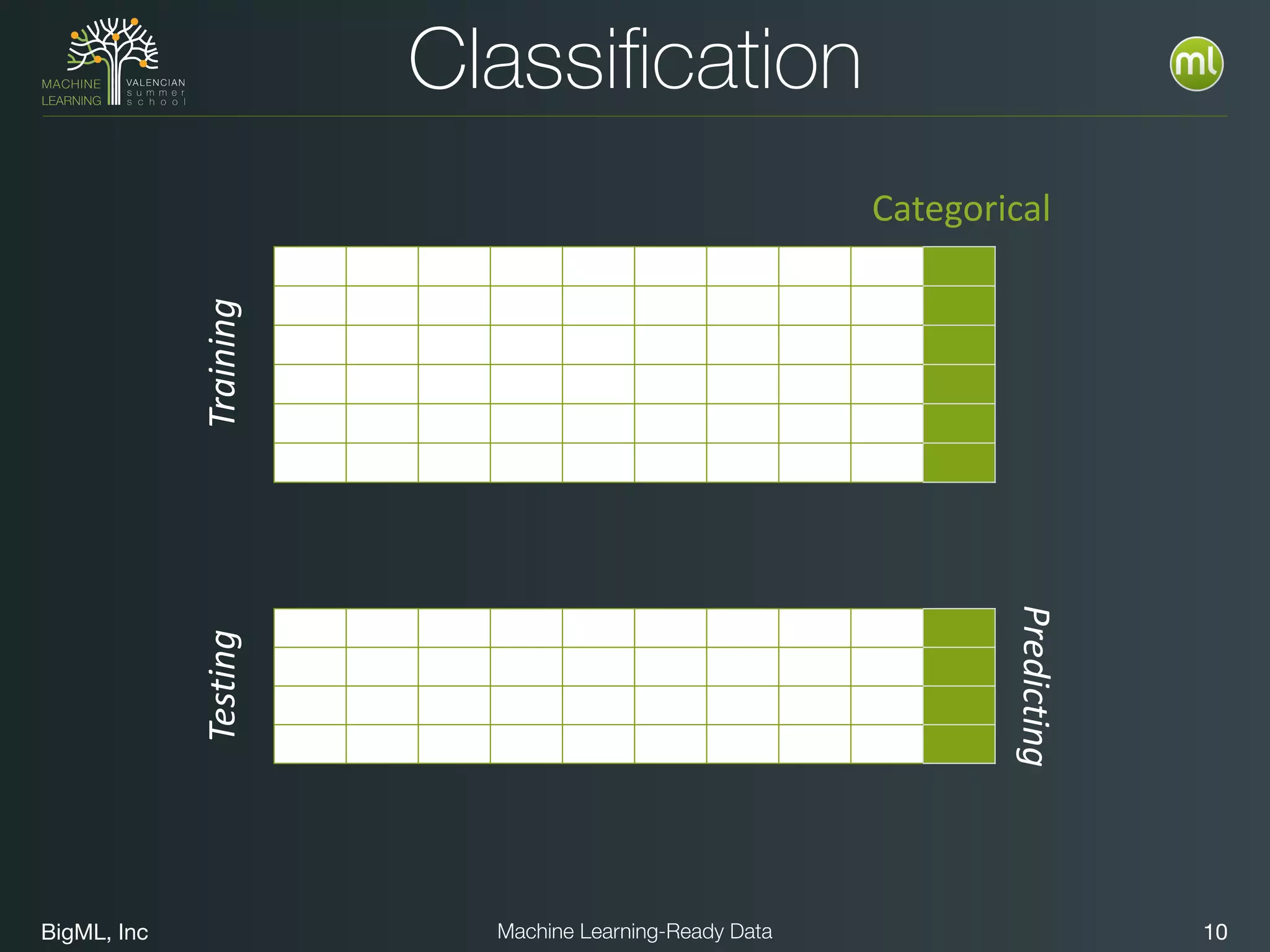
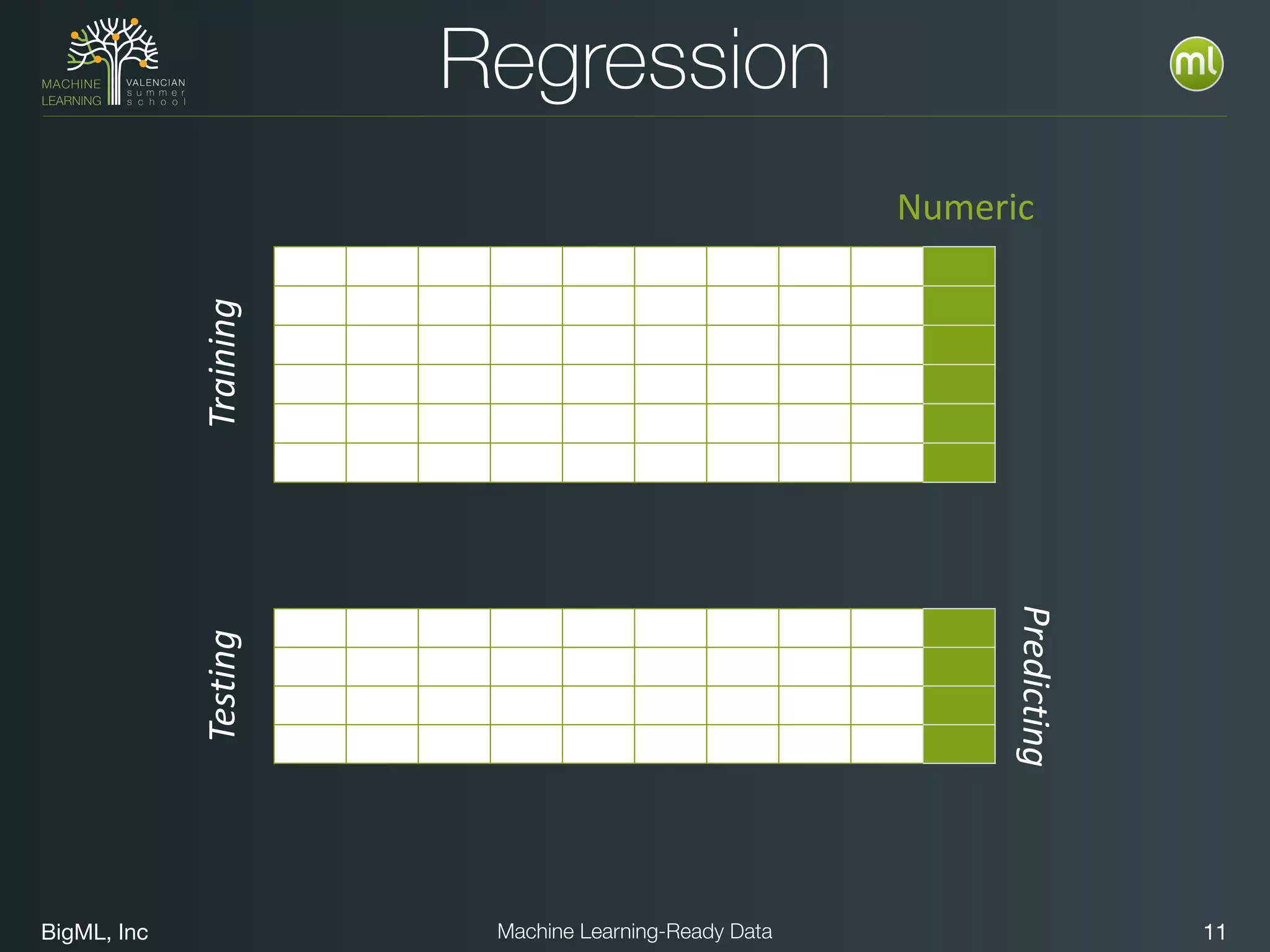


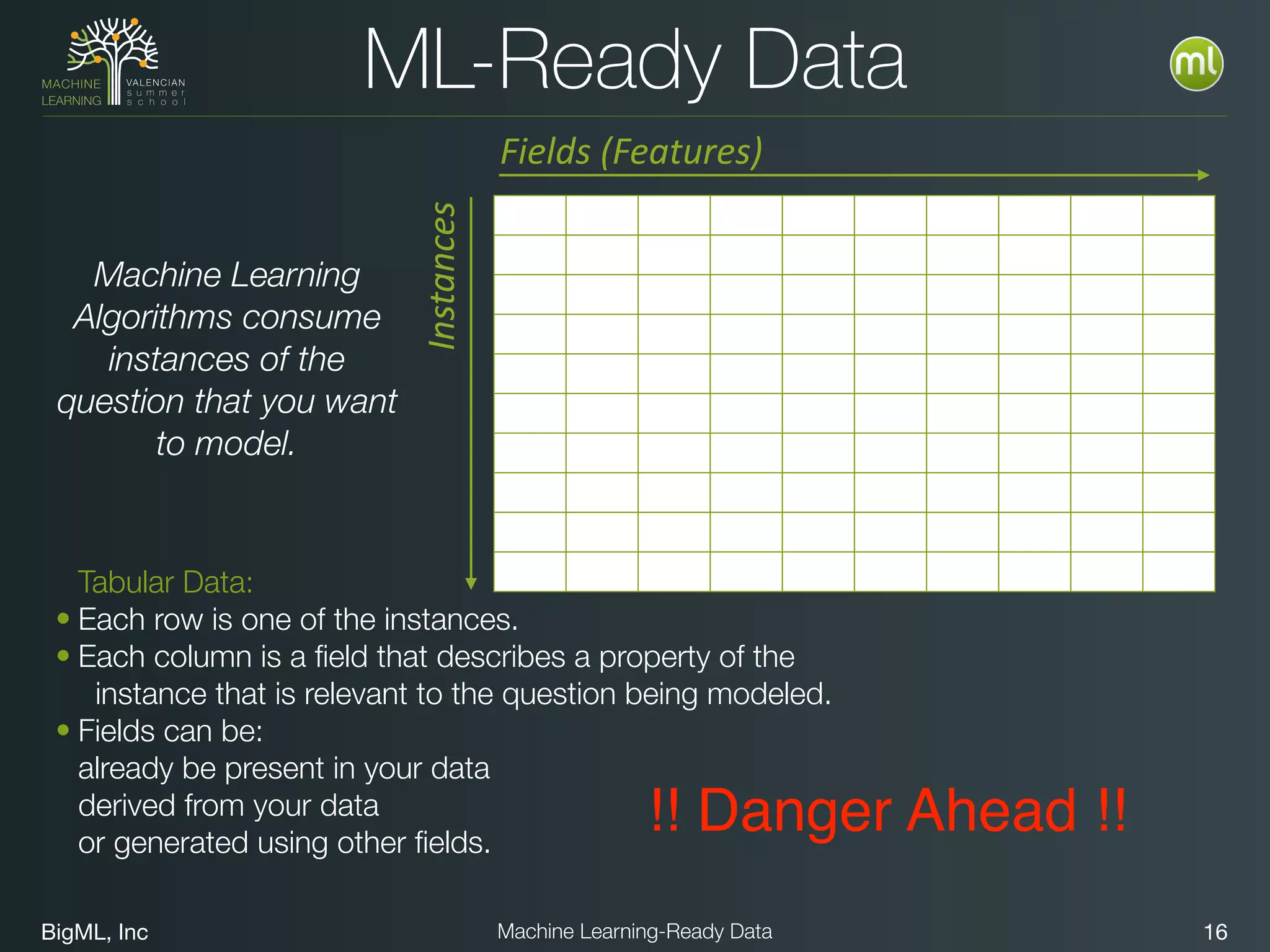
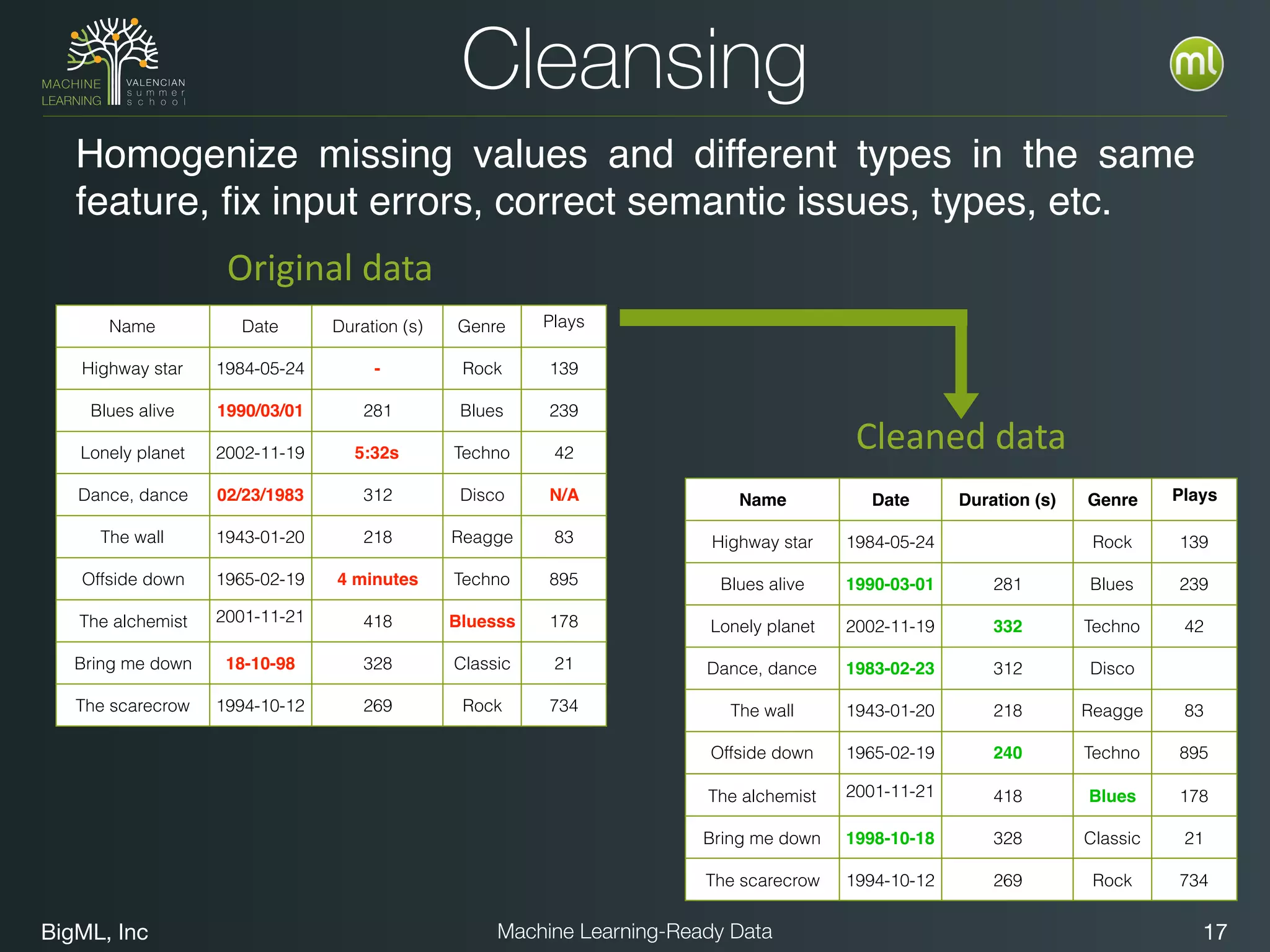


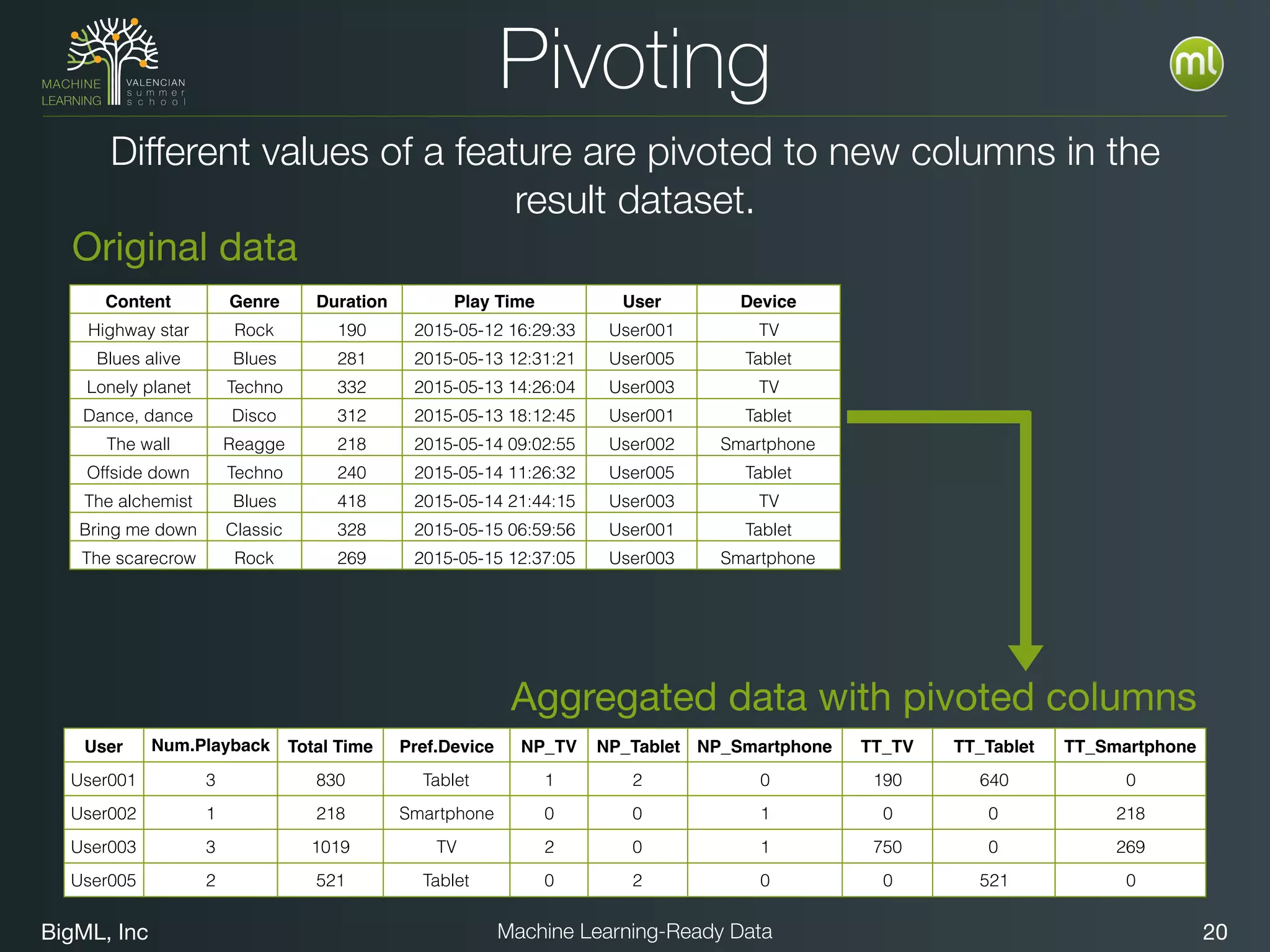
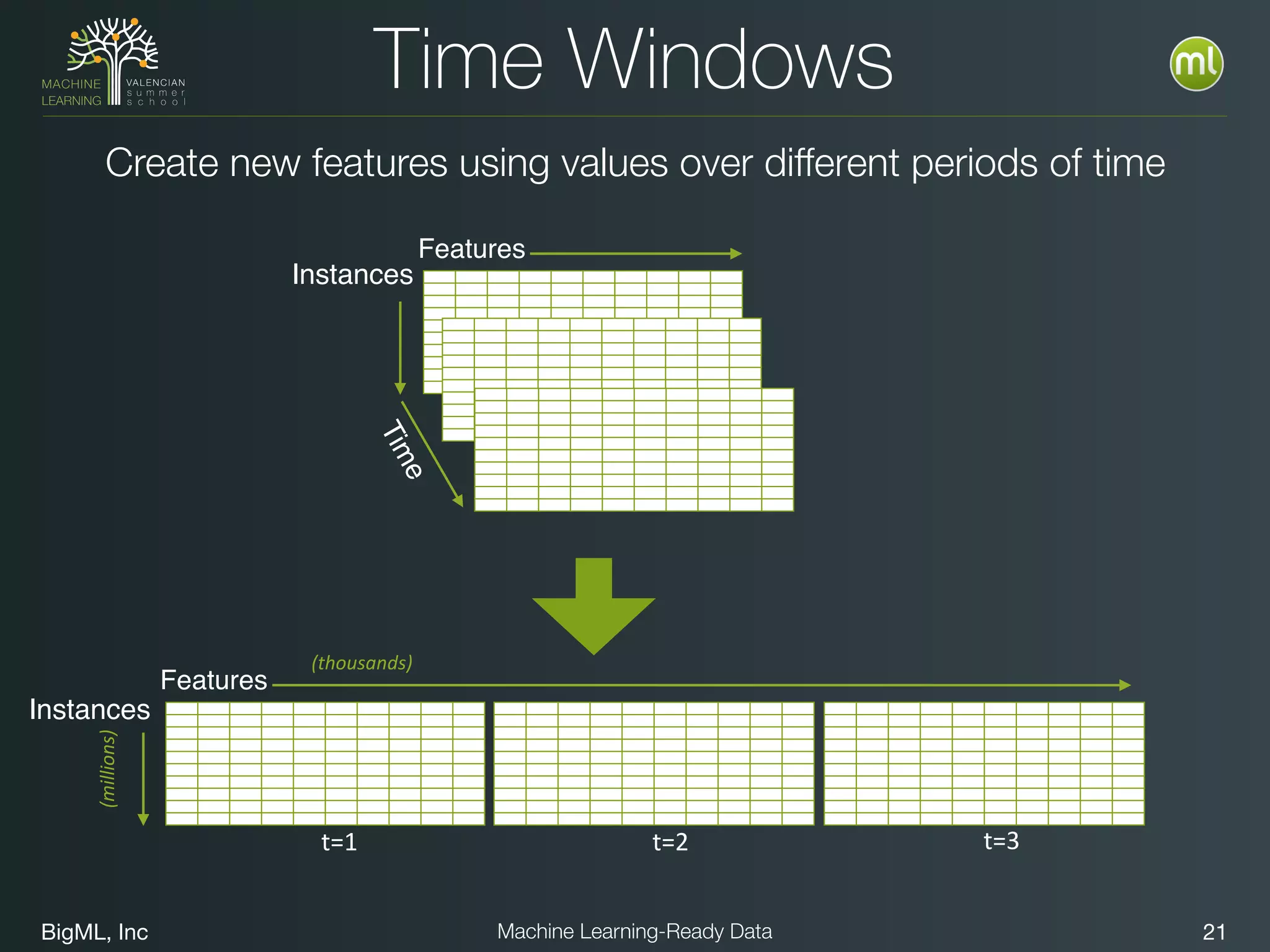








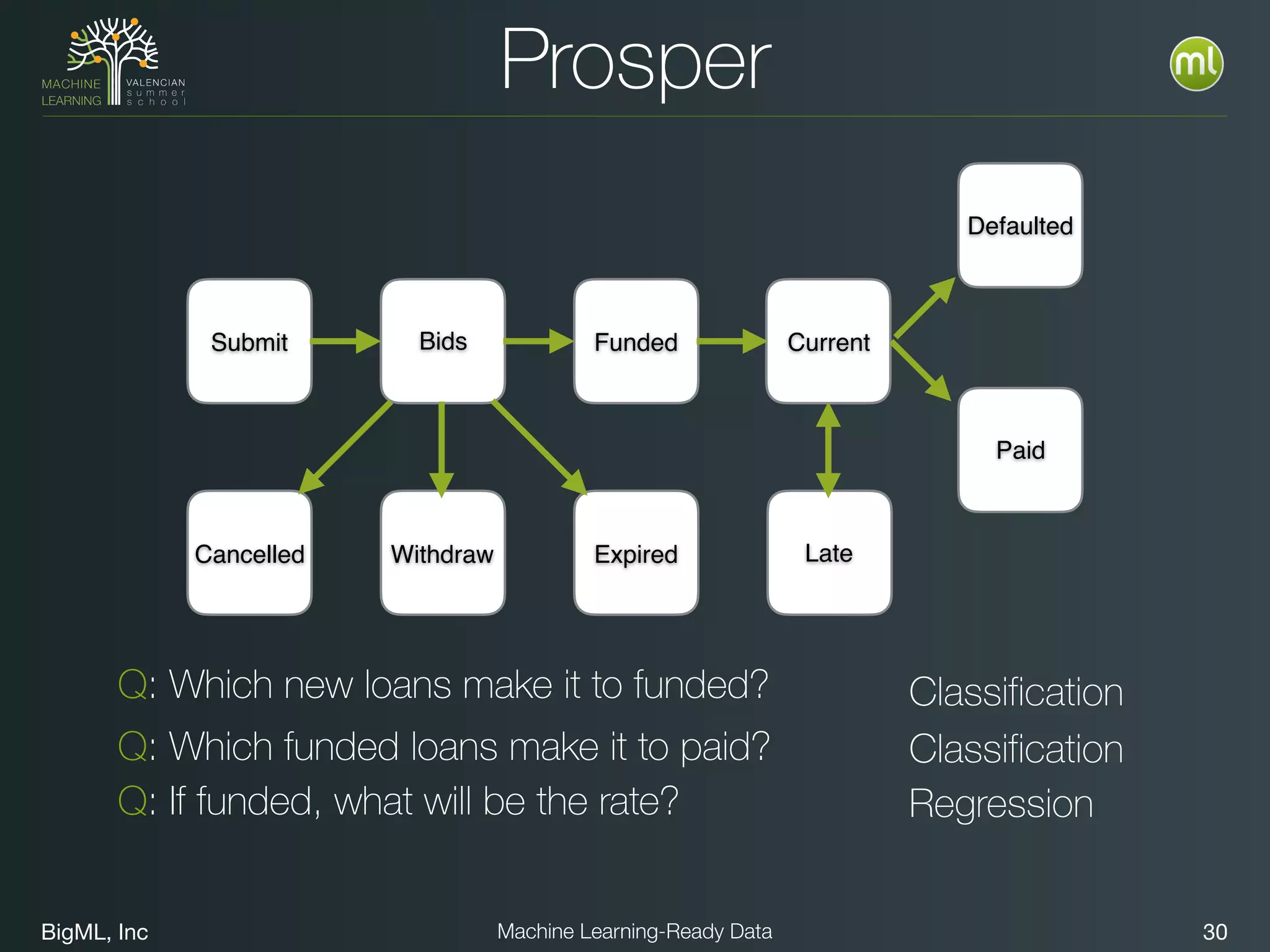
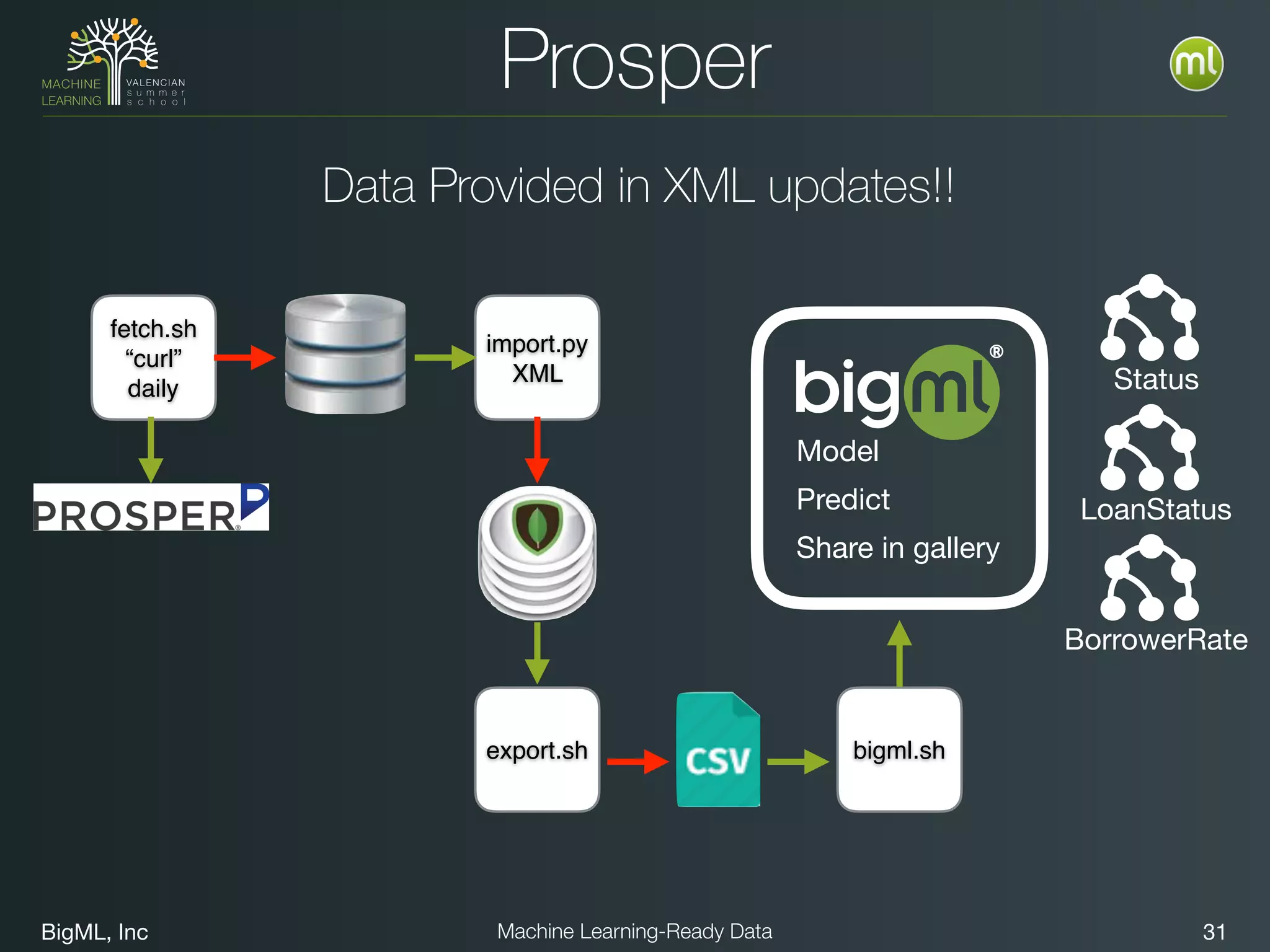

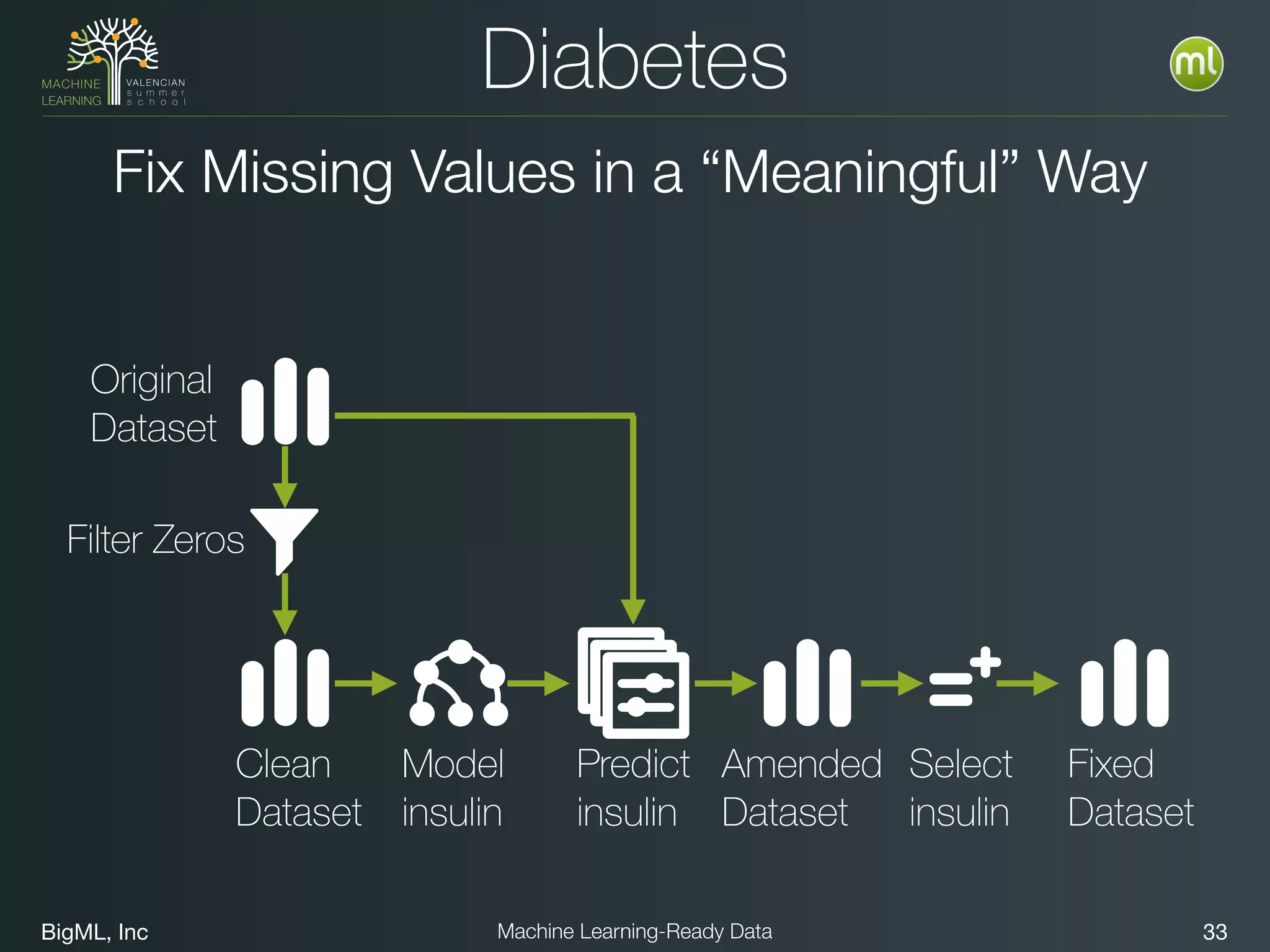
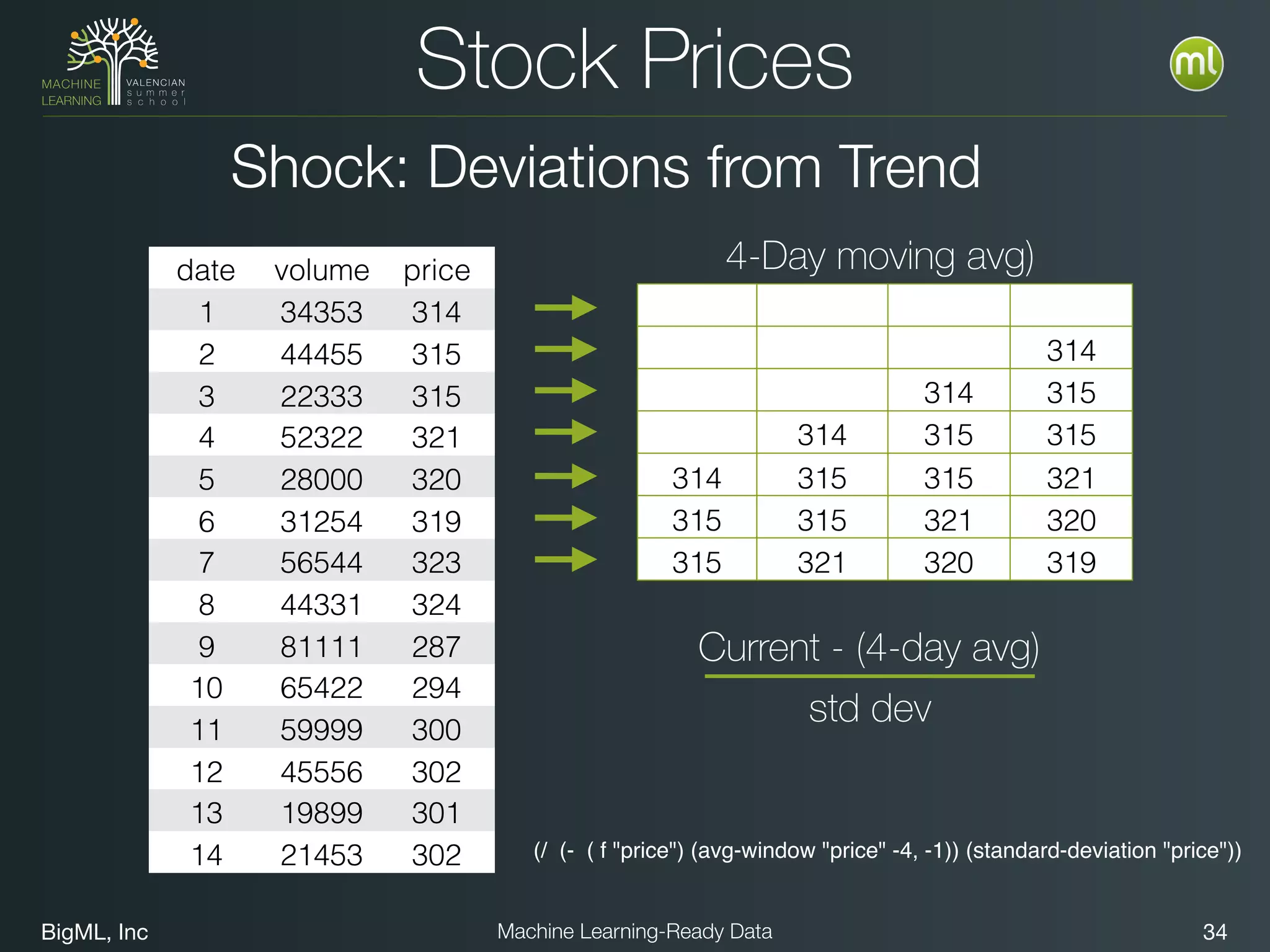
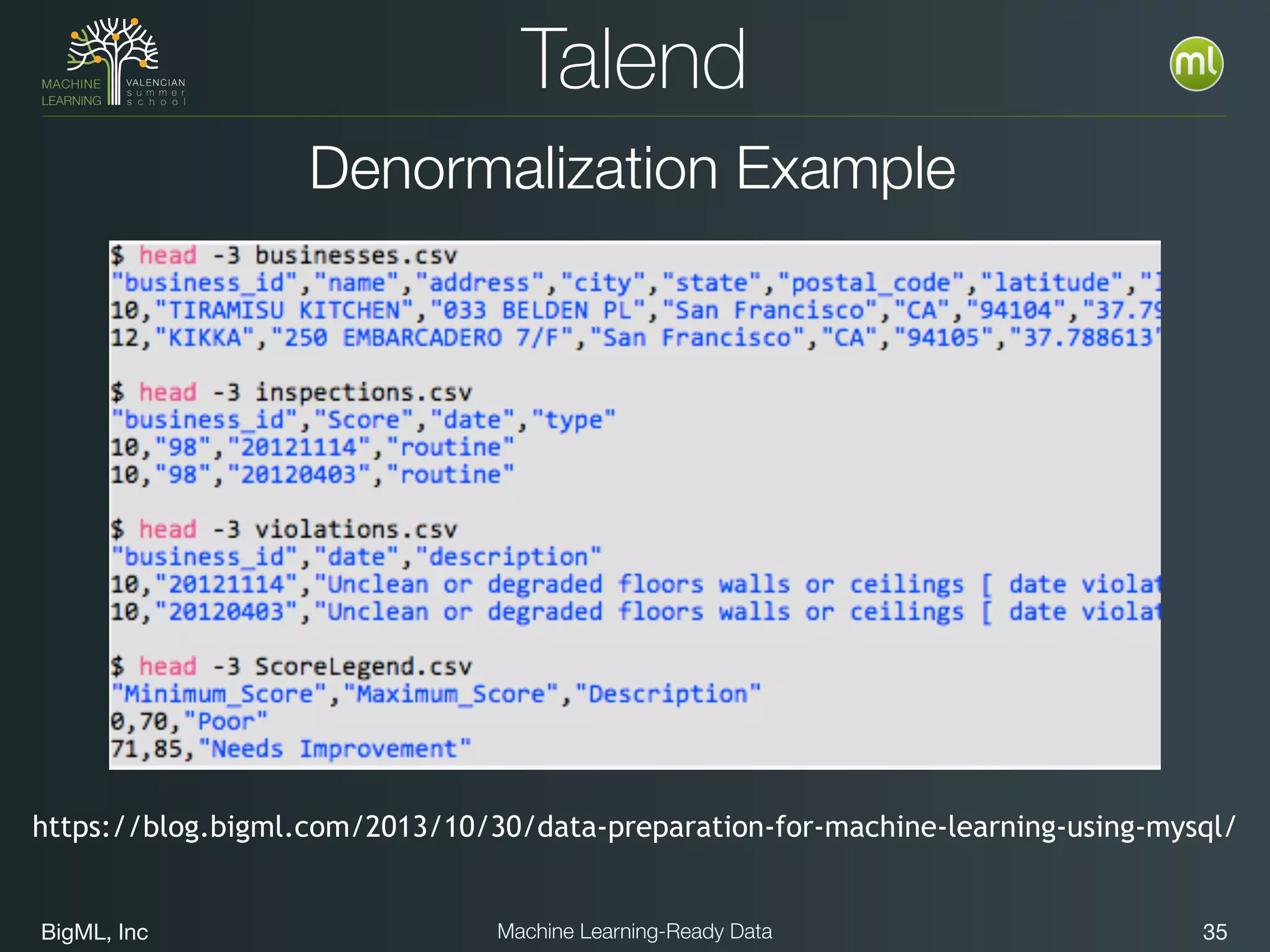
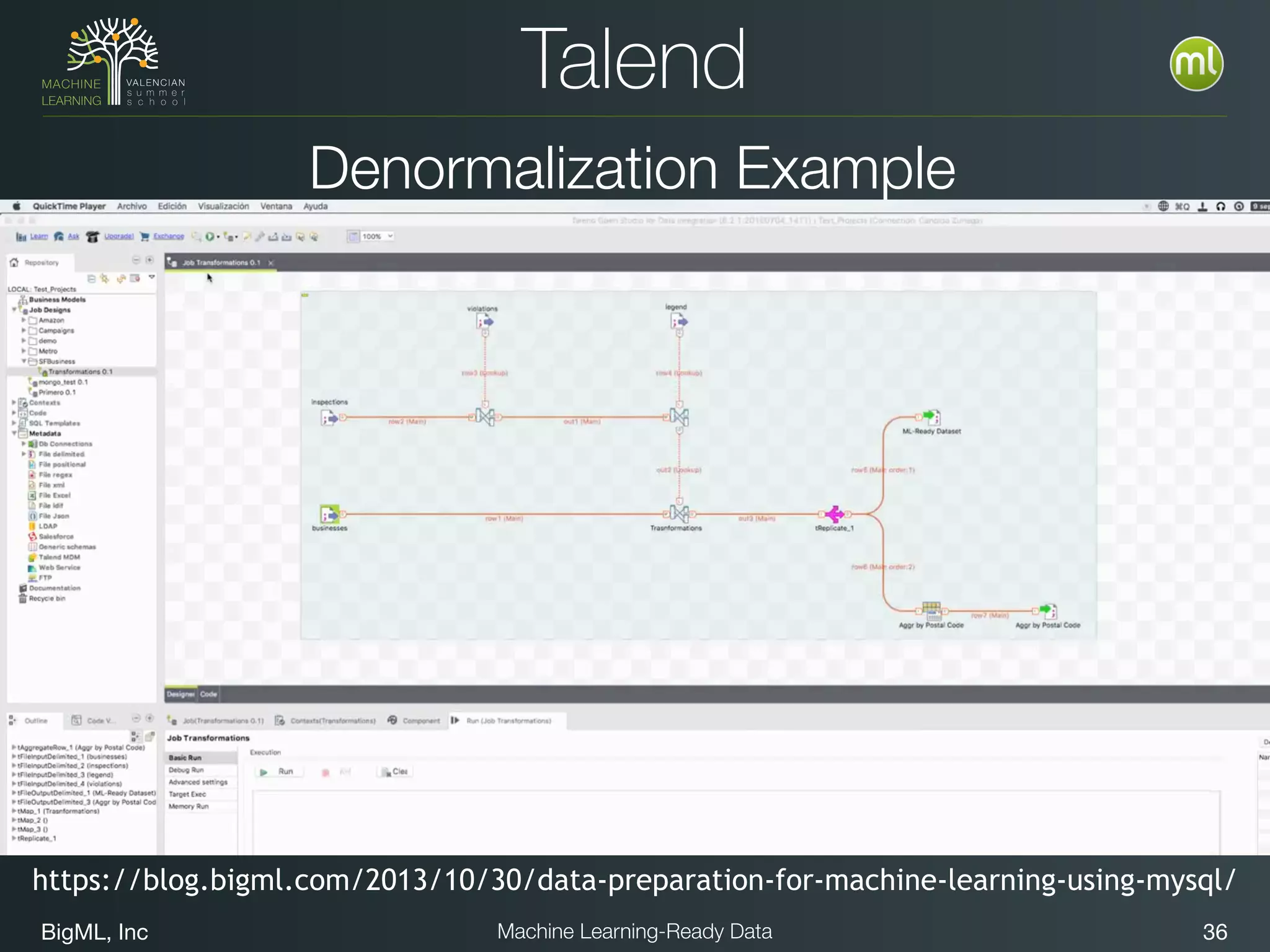

The document discusses preparing data for machine learning by transforming raw data into machine learning-ready data. It outlines a holistic approach that involves defining goals, understanding required data structures, assessing available data, and performing transformations like cleaning, denormalizing, aggregating, pivoting, and feature engineering. The transformations are aimed at structuring the data into a format that machine learning algorithms can consume to build models. Automating the transformations and evaluating results is also emphasized.























































































