Download as PDF, PPTX







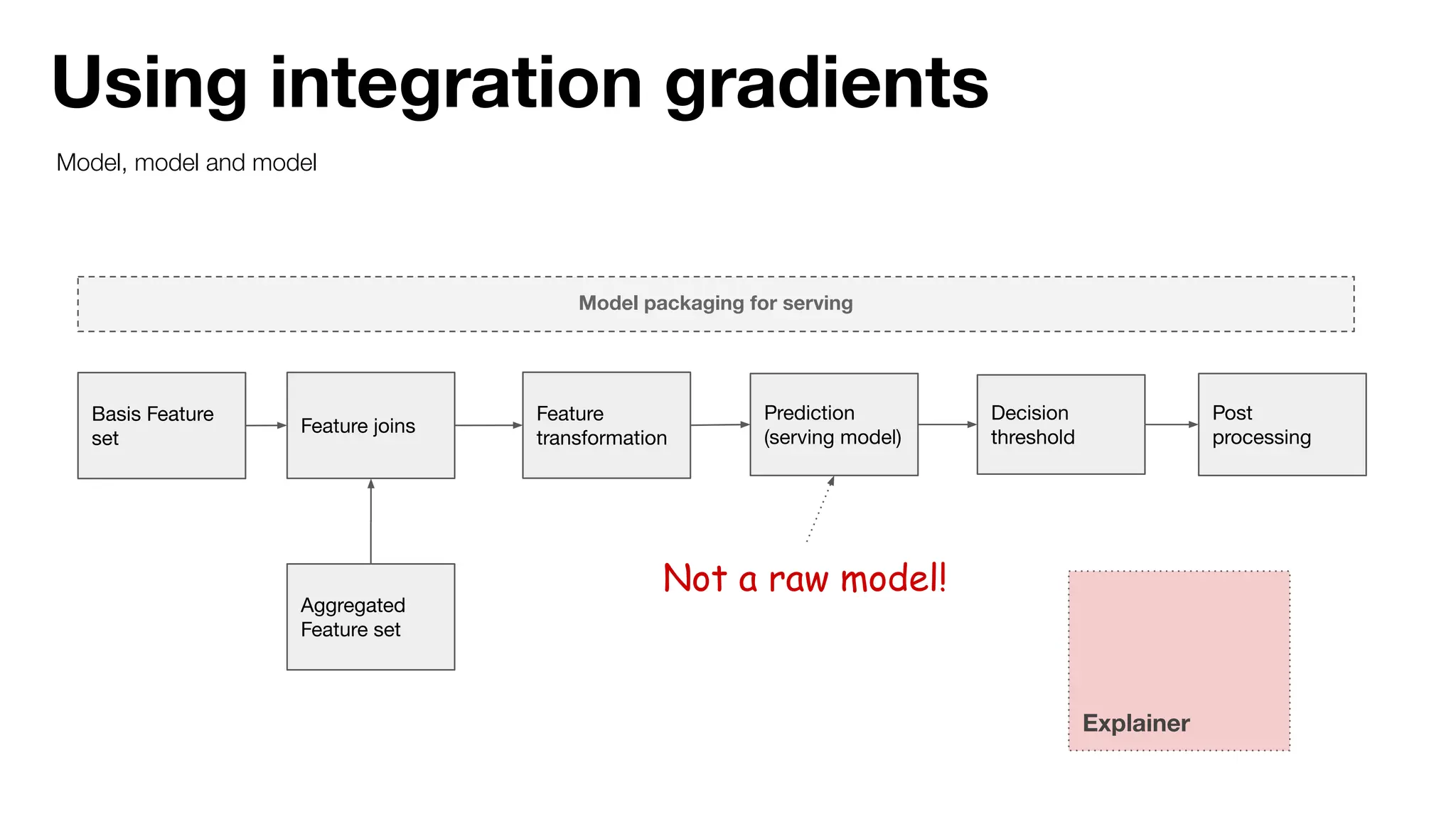
![Using integration gradients
Save DL model separately
Explainer
Train Serving model
Raw model
Deploy to
endpoint
[keras.model, torch.nn.model, lightning…]
[torchscript, tf.compat.v1…]](https://image.slidesharecdn.com/1uber-mlexplainabilityinmichelangelo-240524184941-80bdc699/75/AI-ML-Infra-Meetup-ML-explainability-in-Michelangelo-15-2048.jpg)
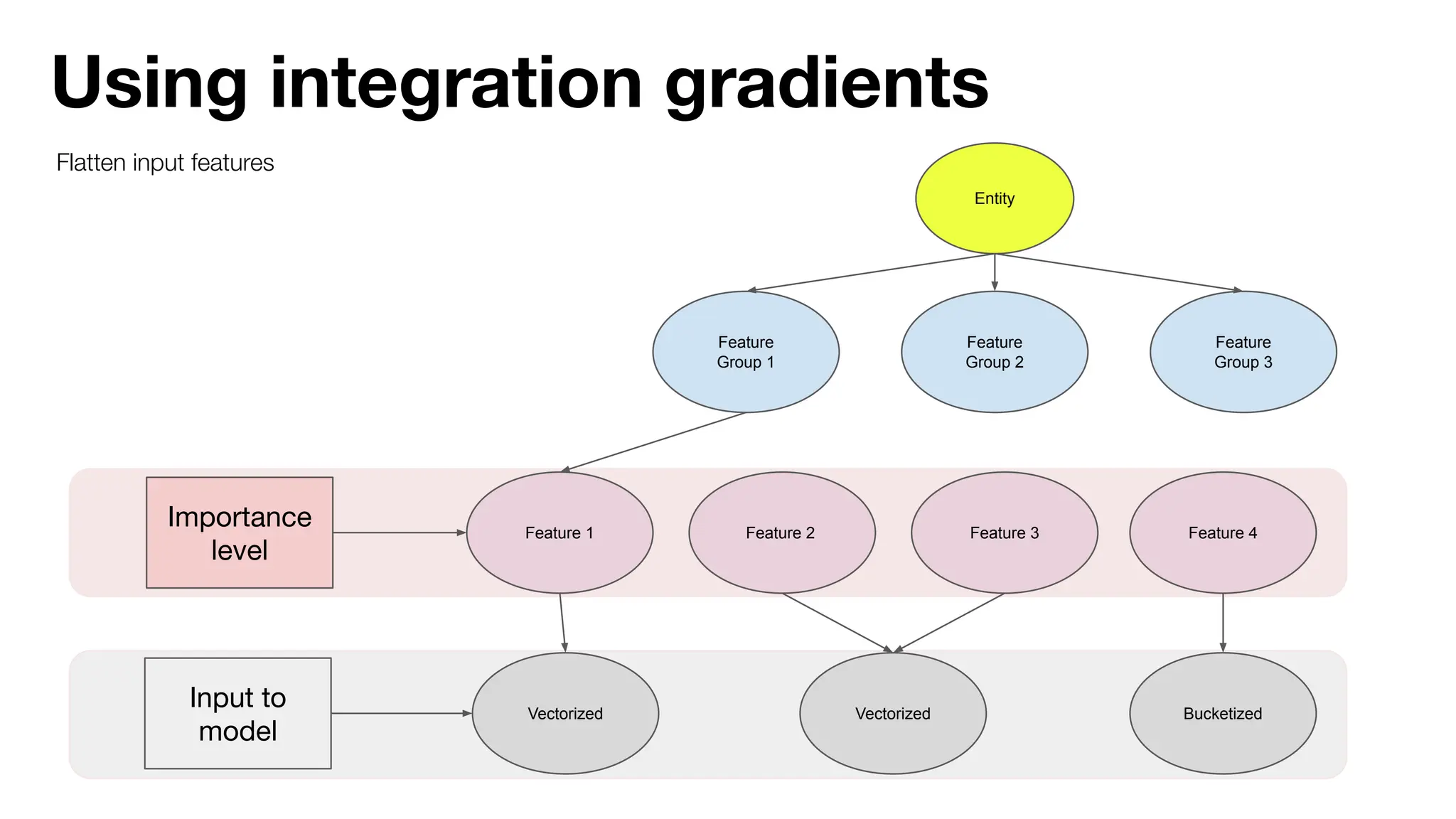
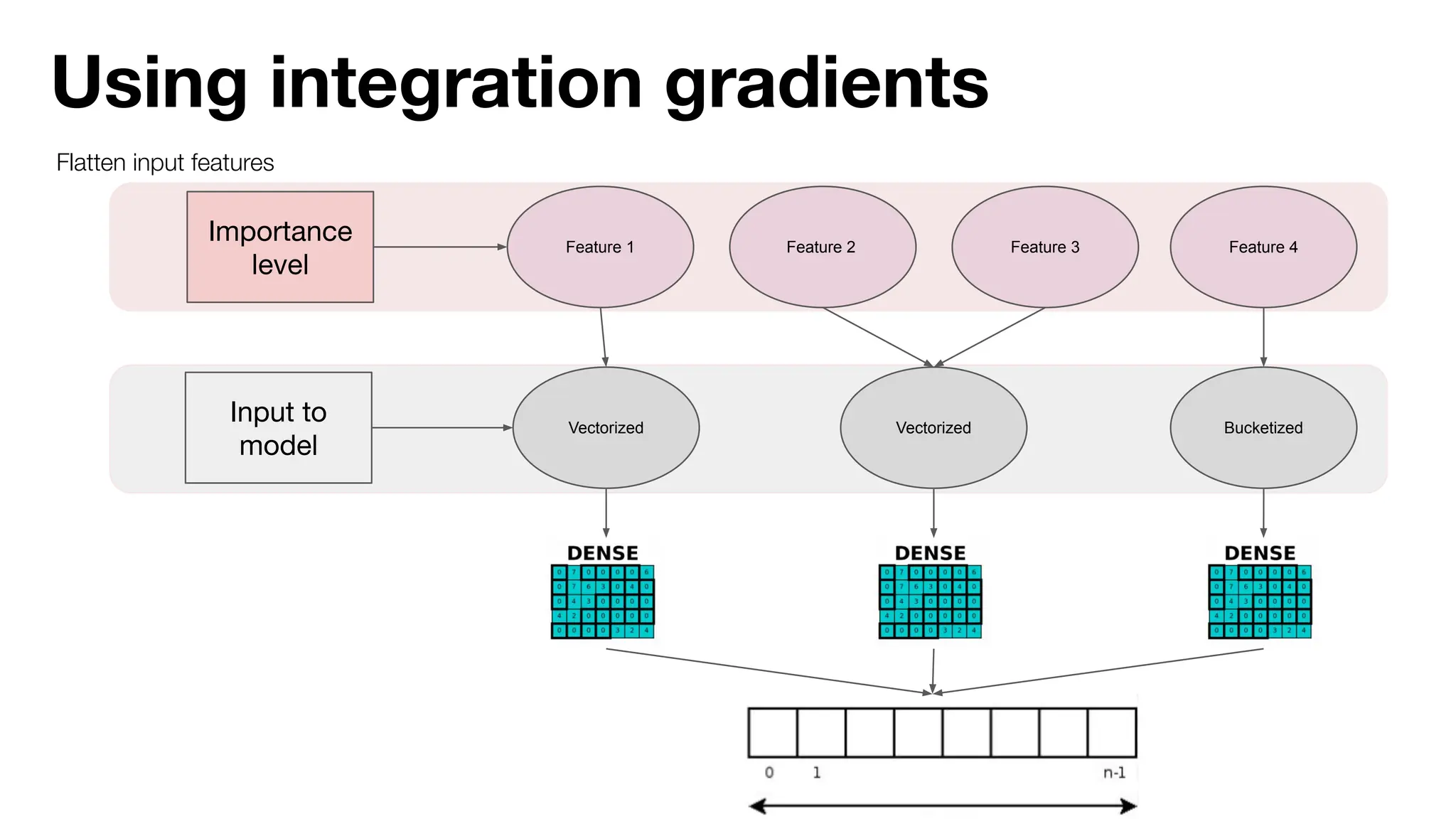
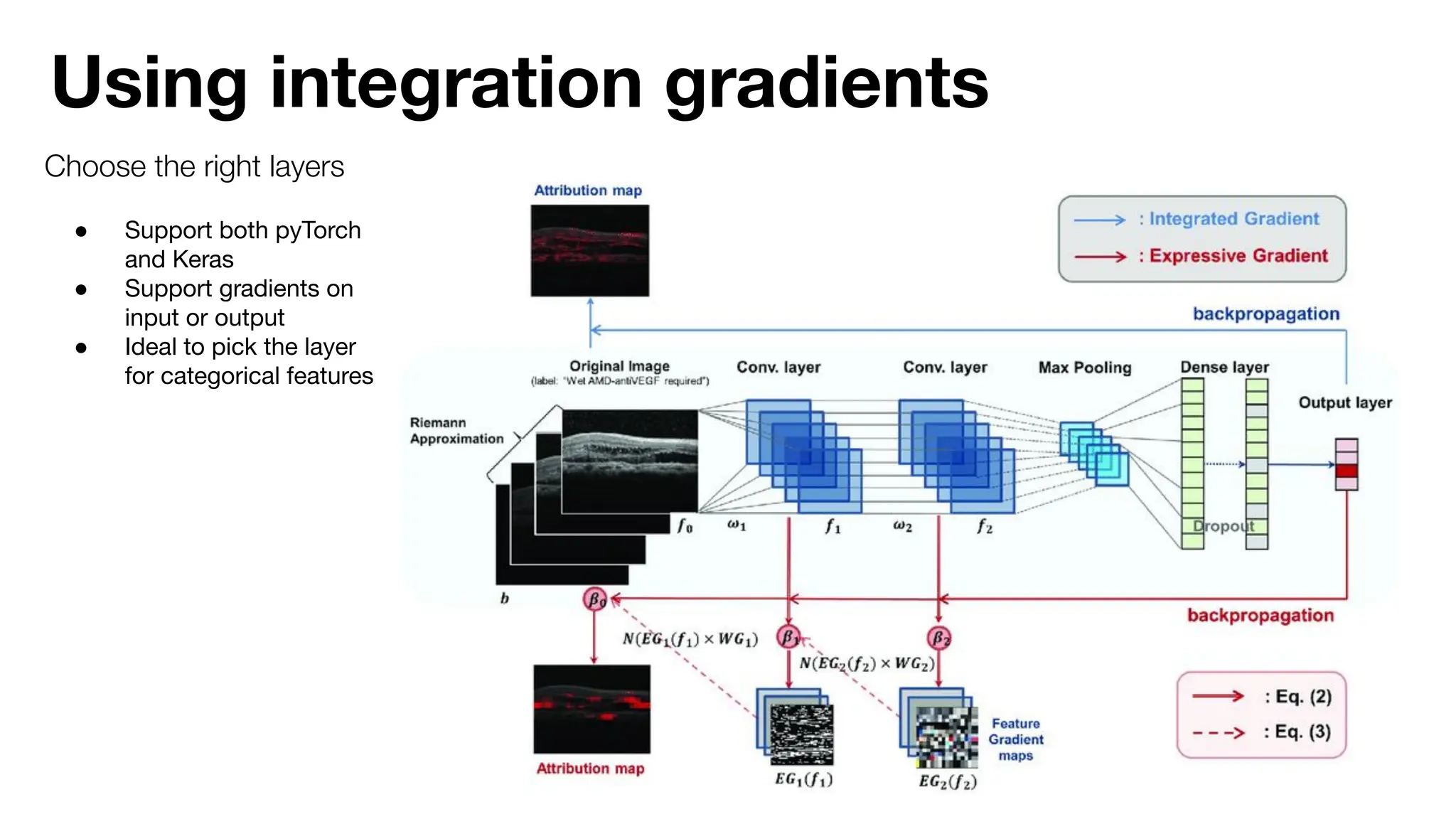
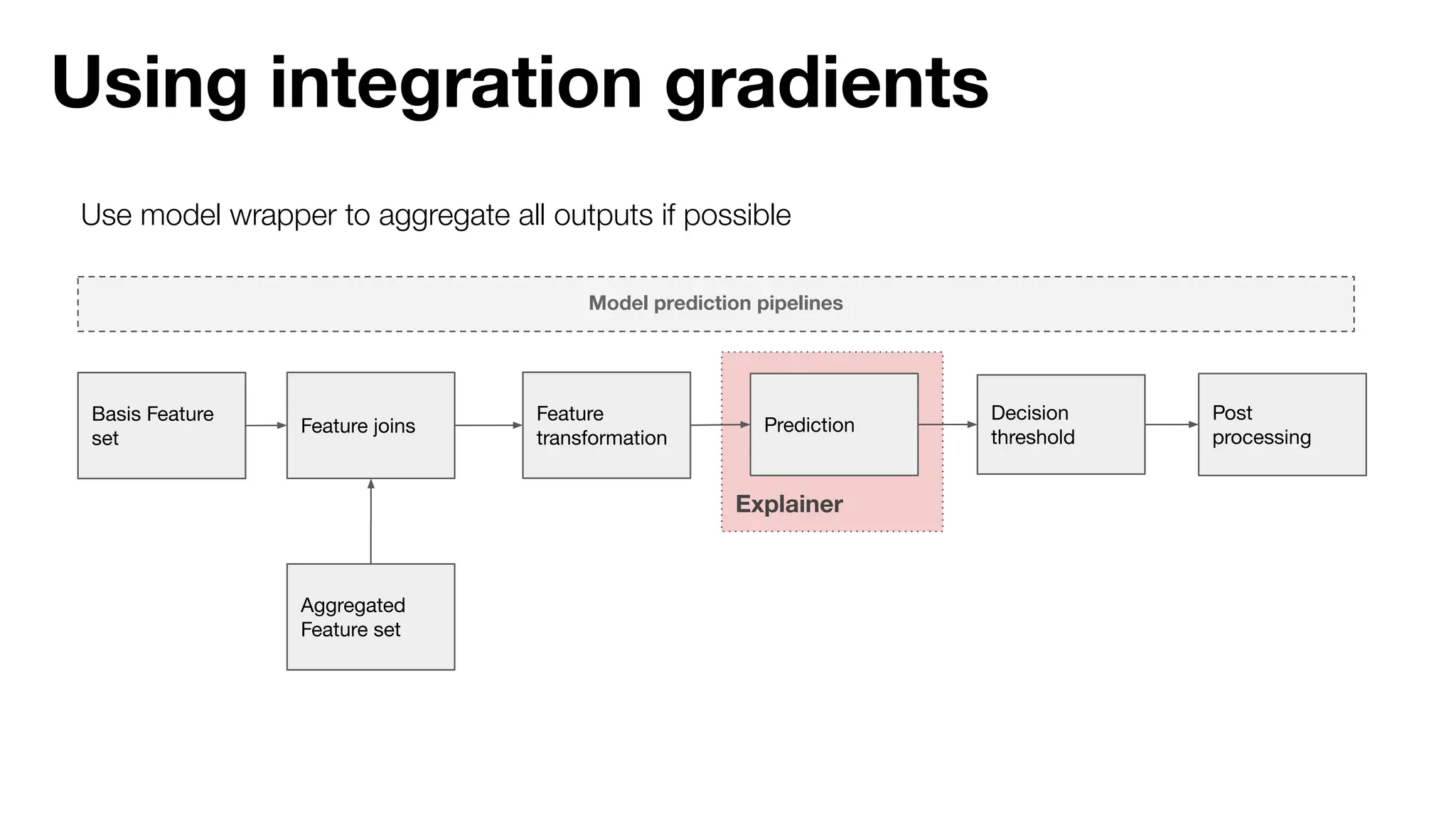
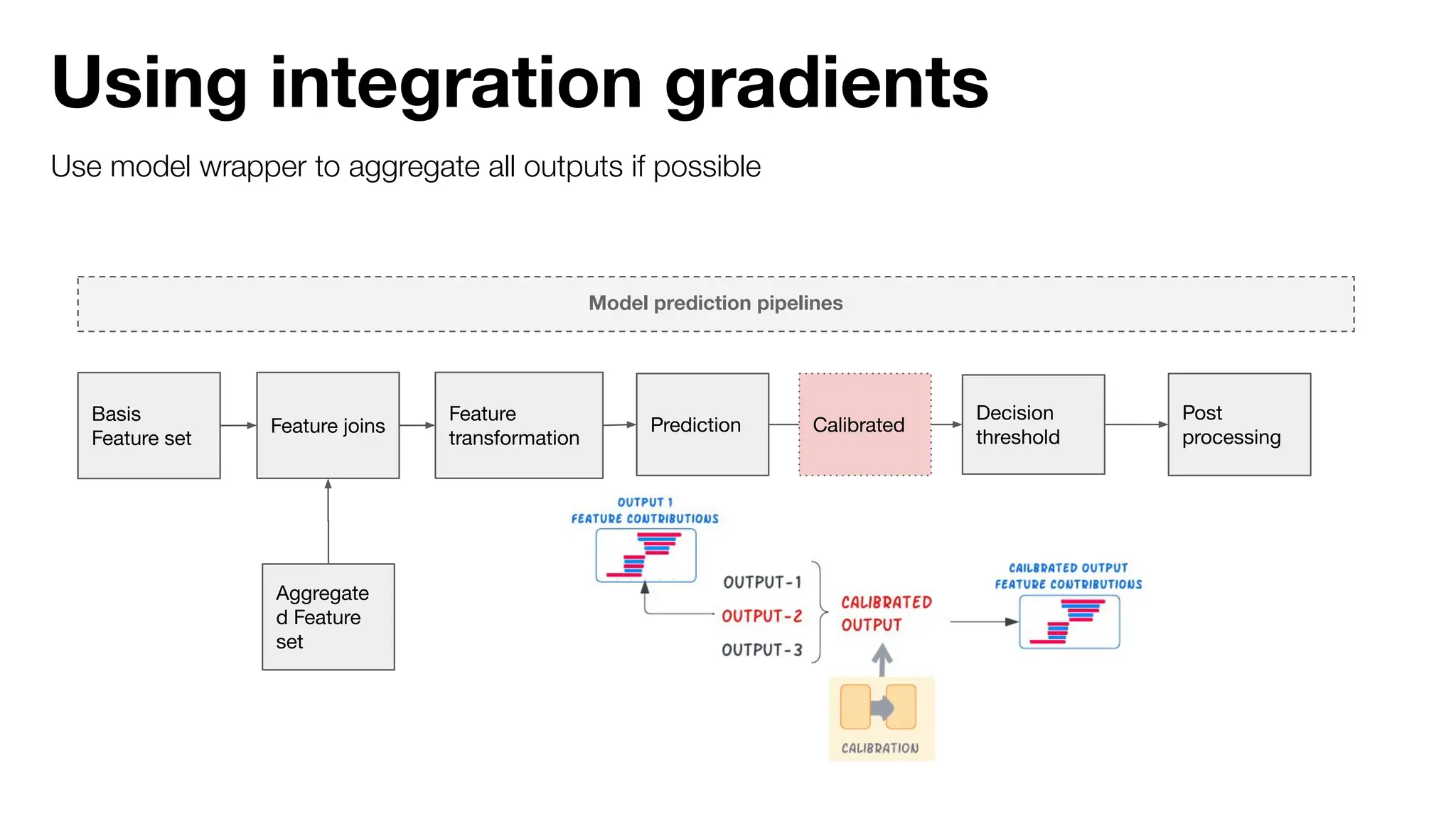

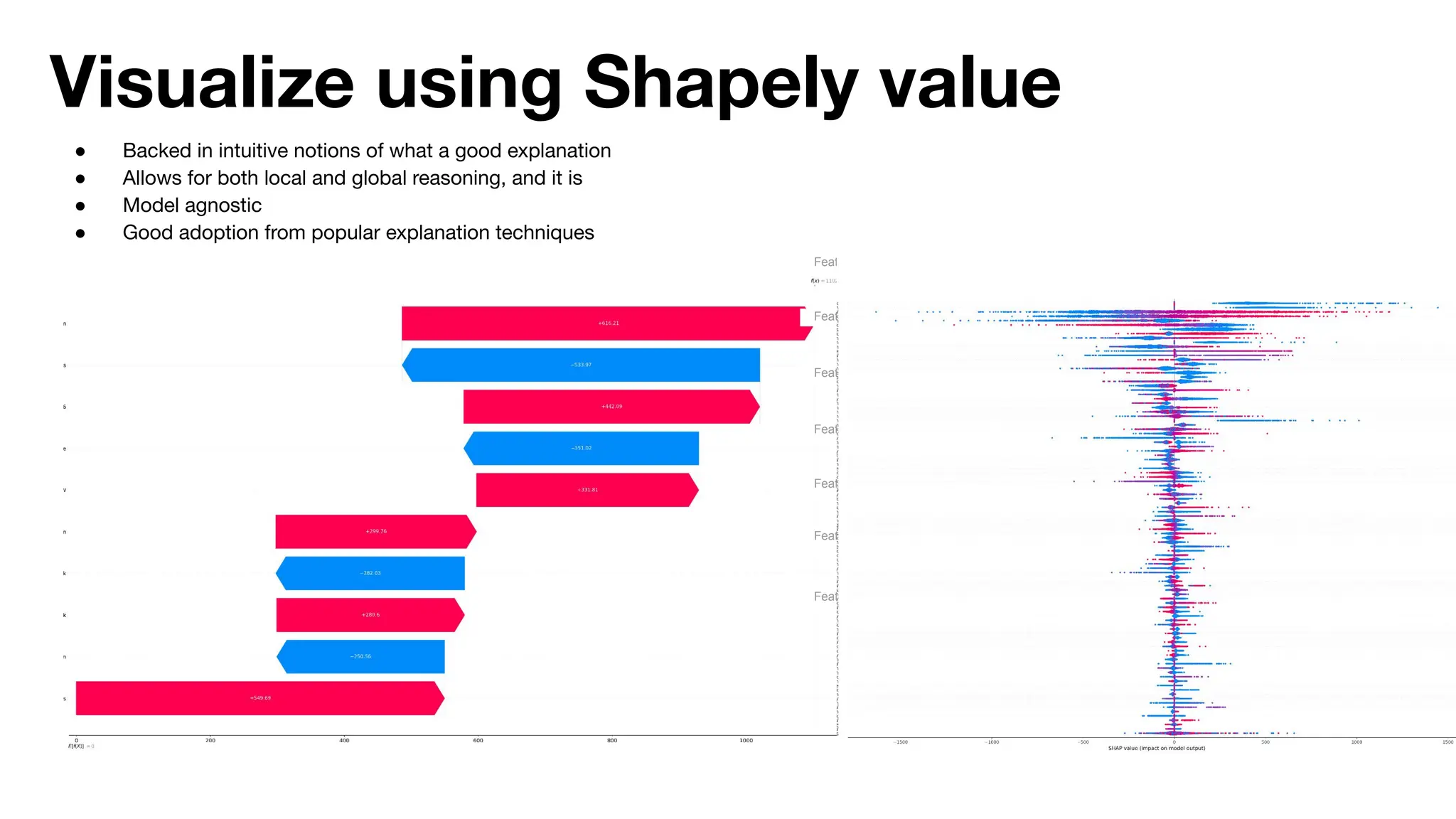
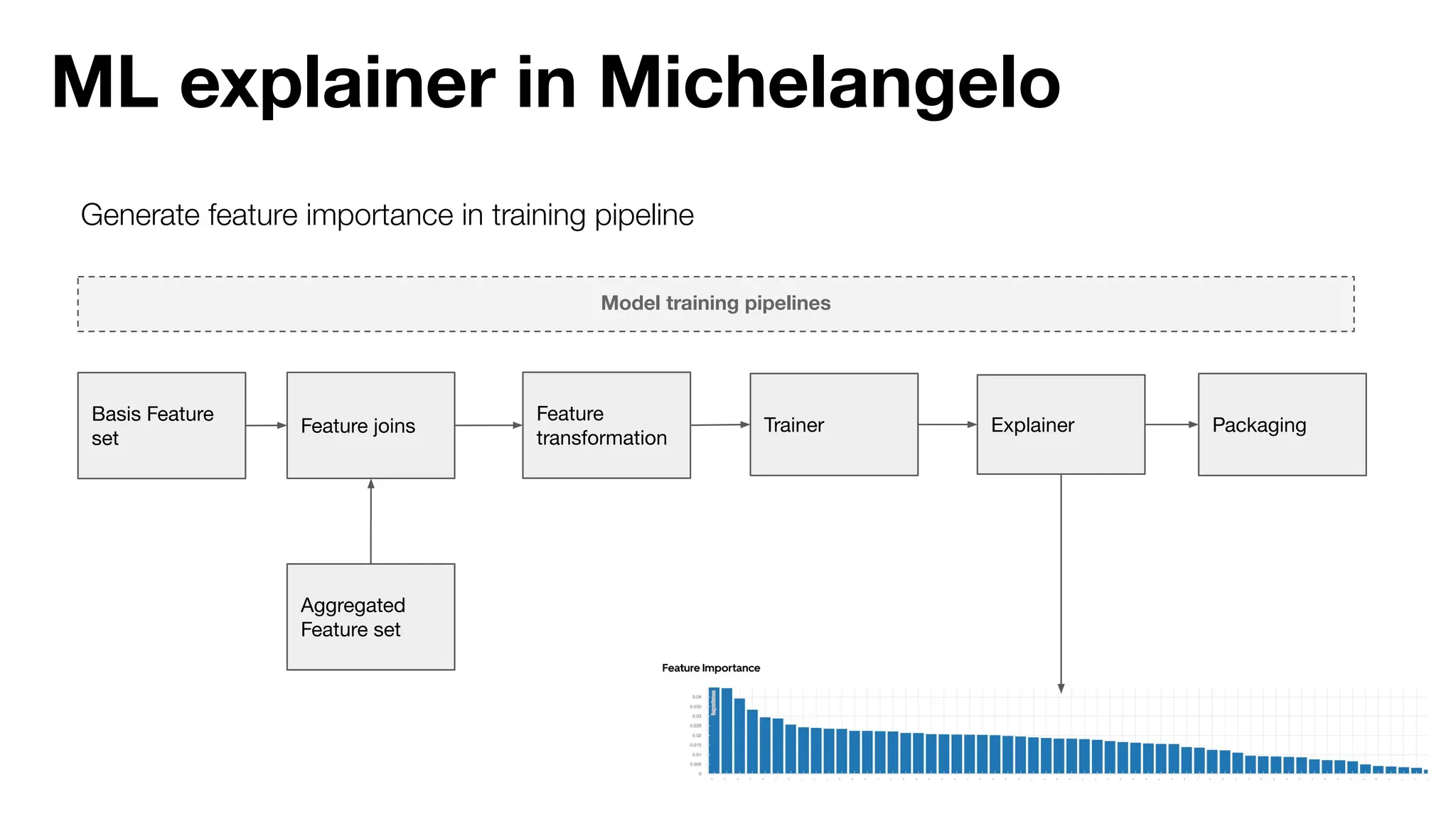
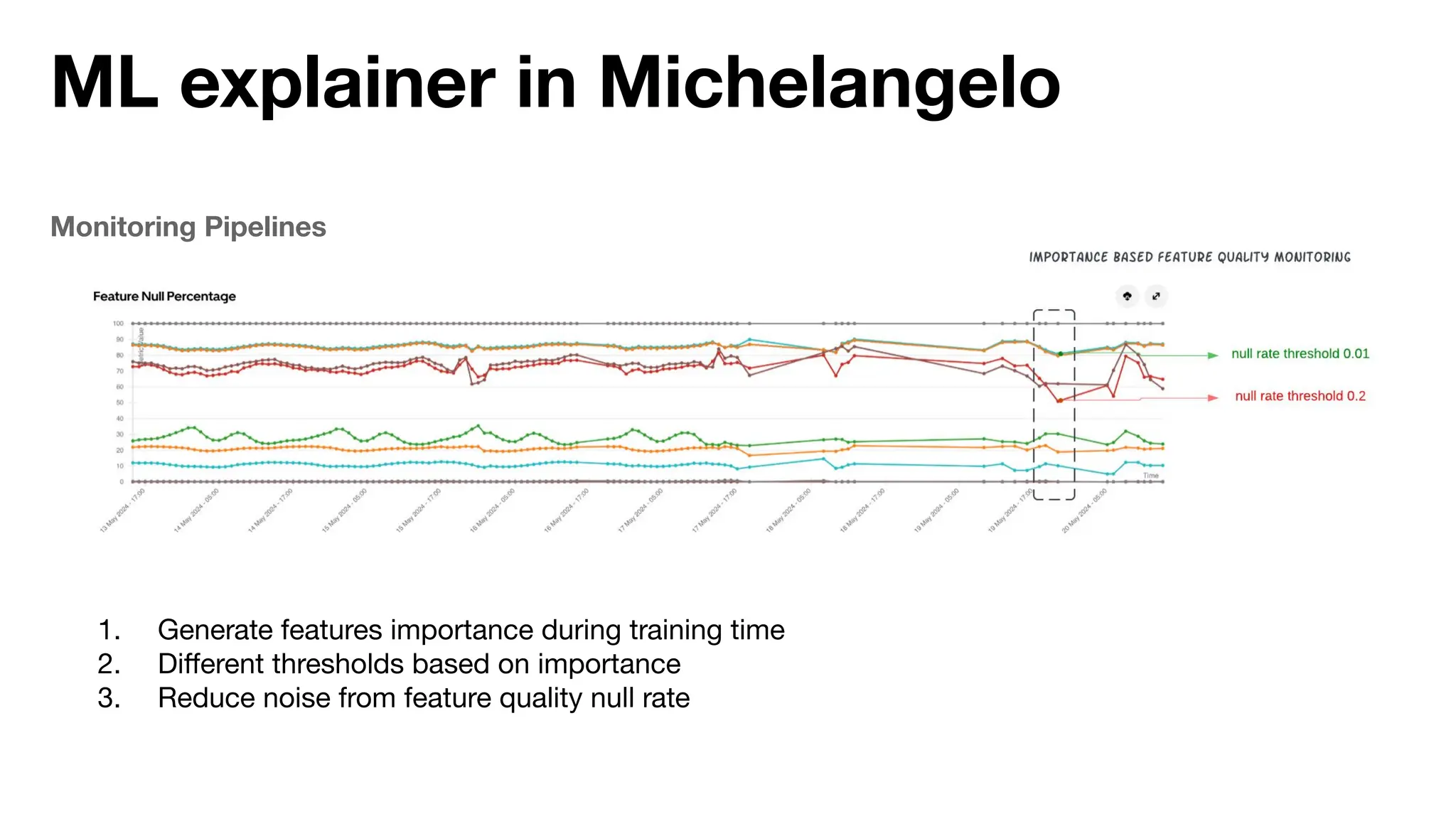

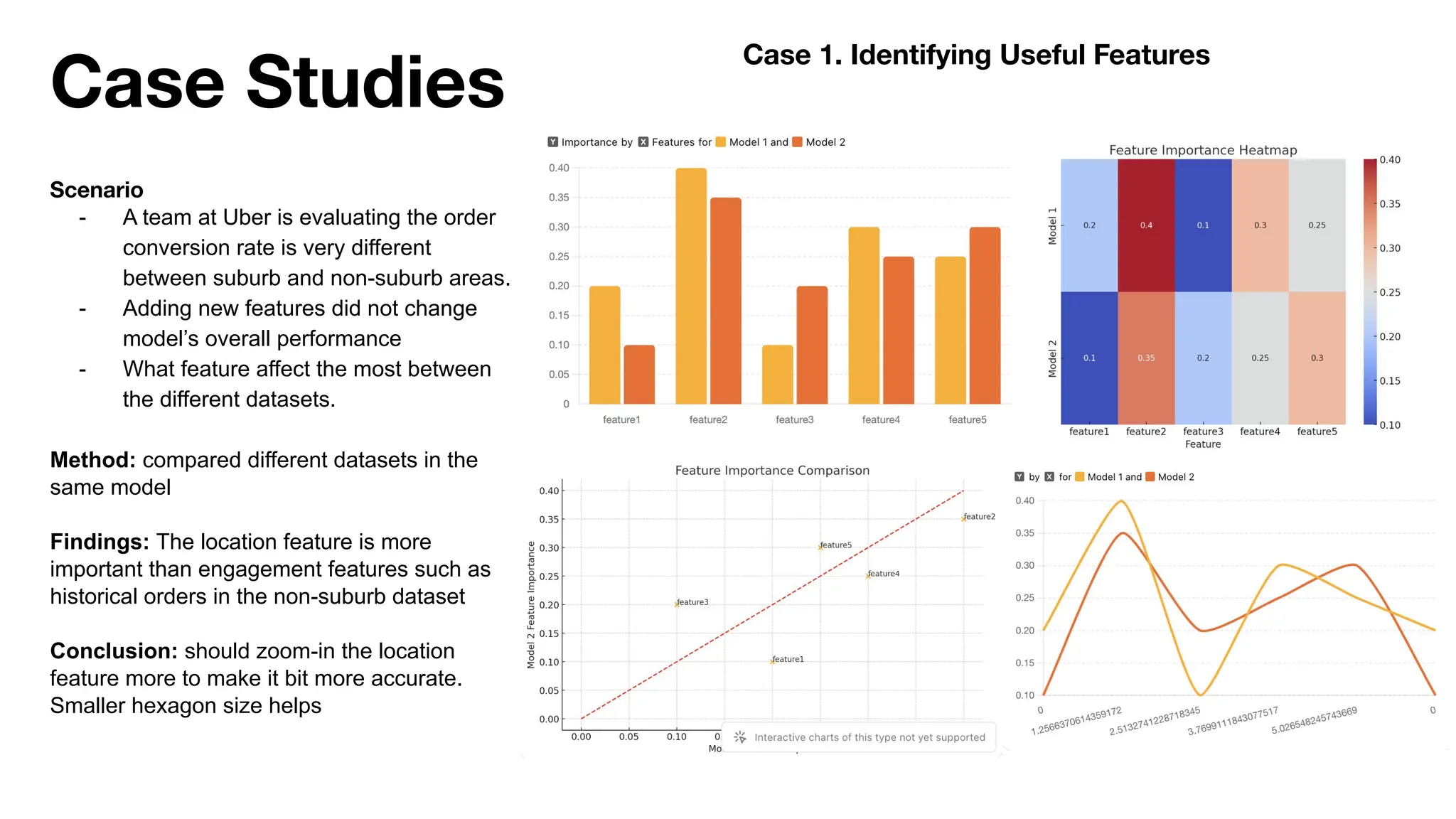
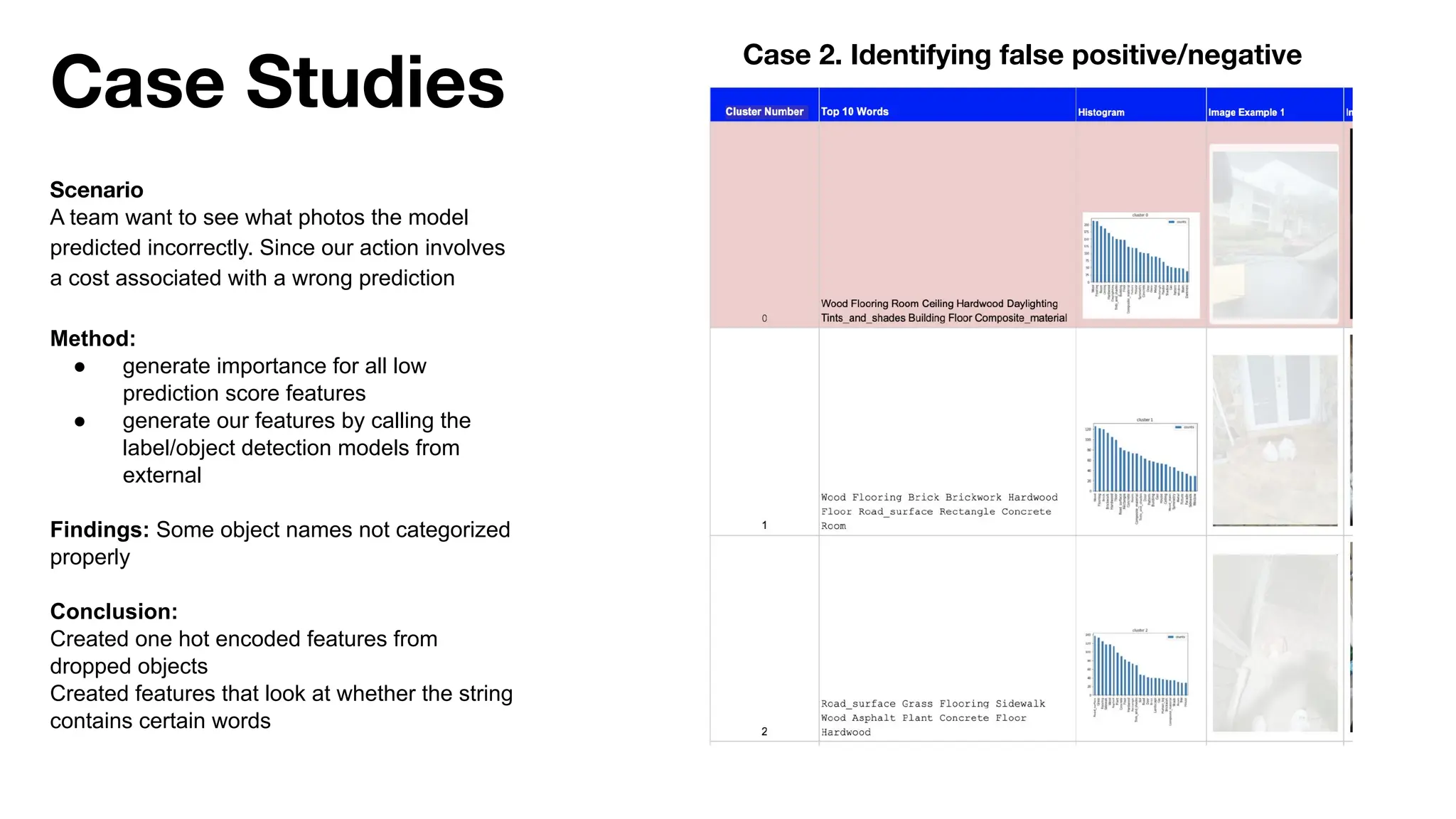
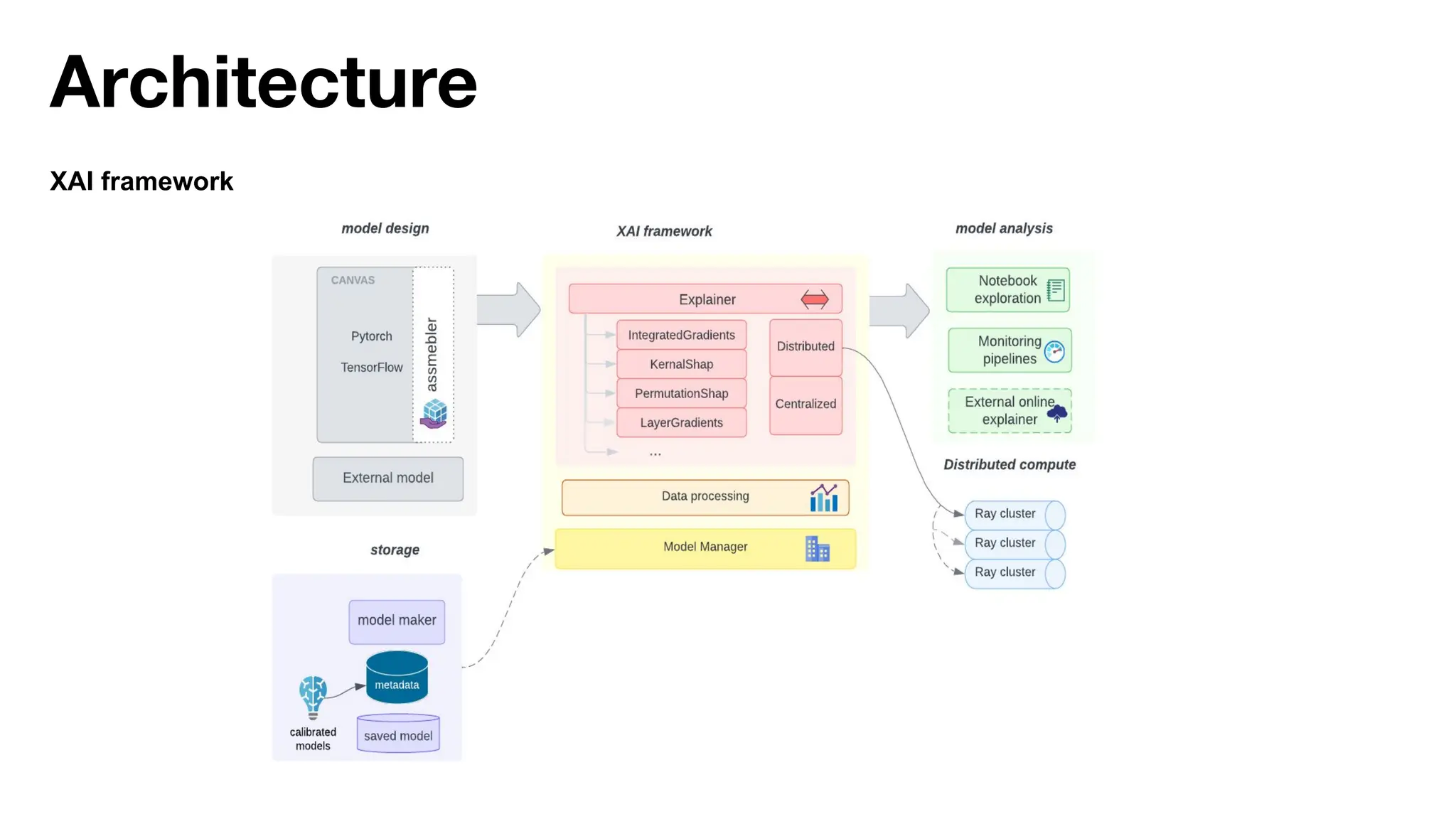
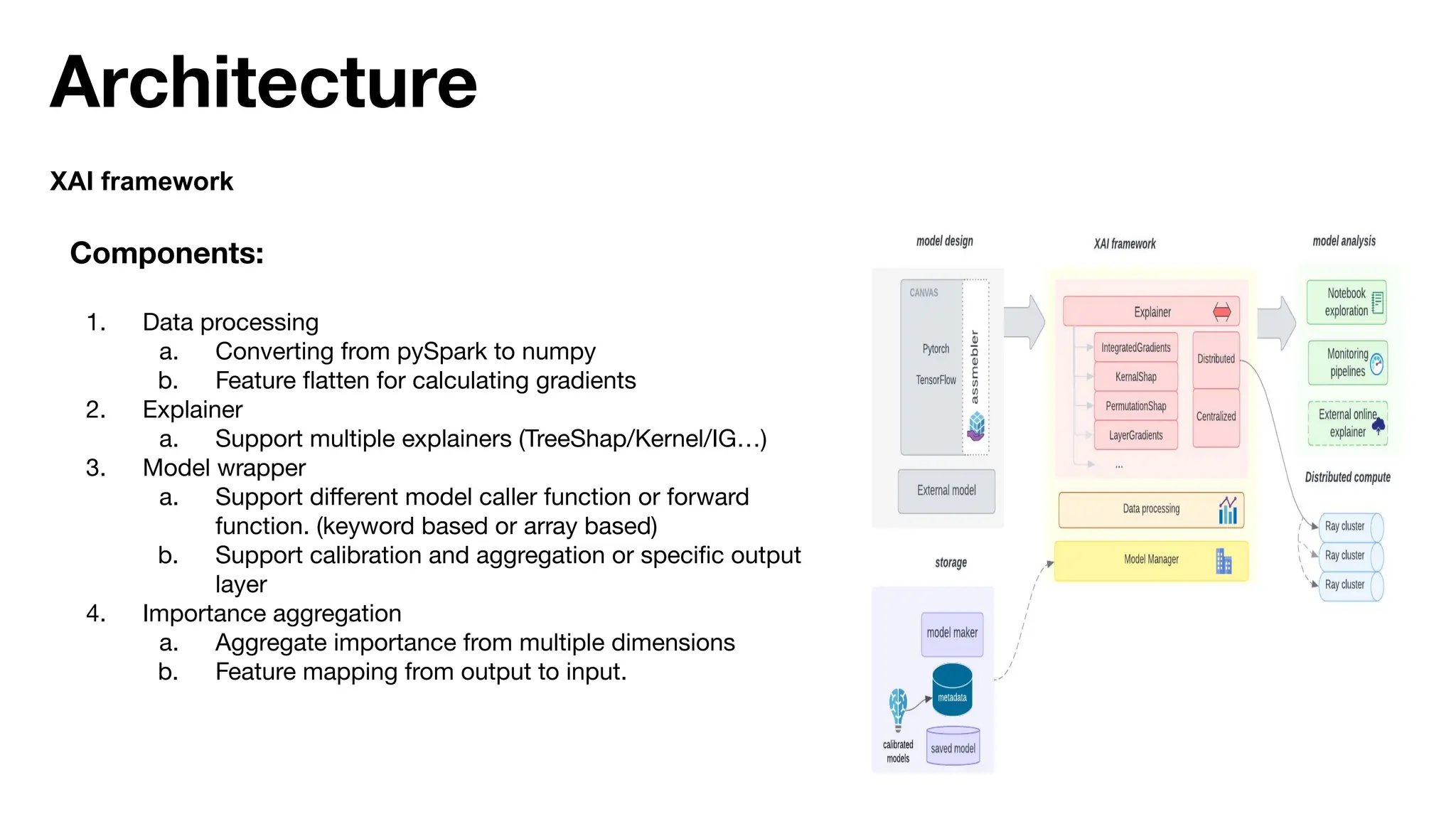




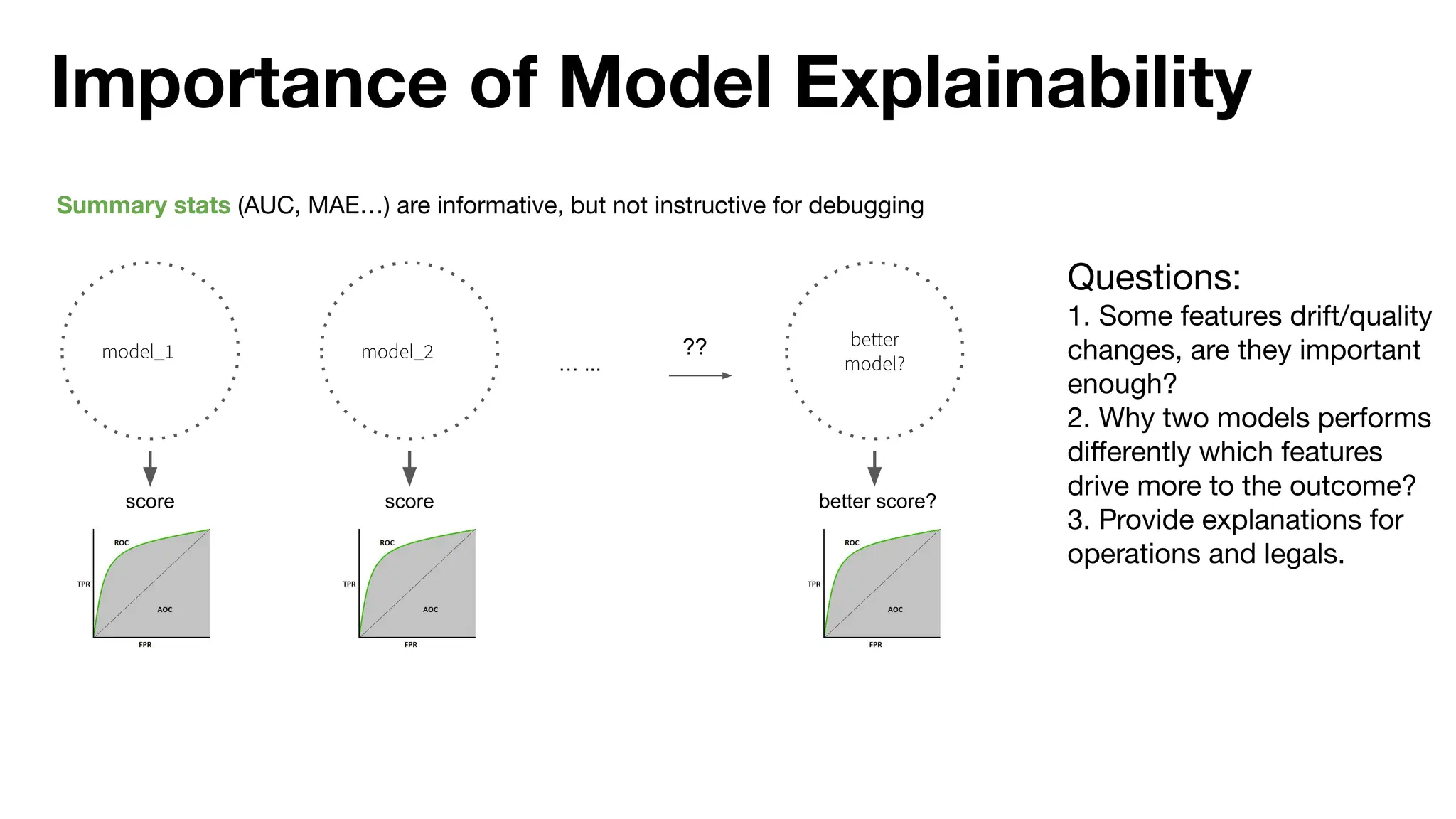
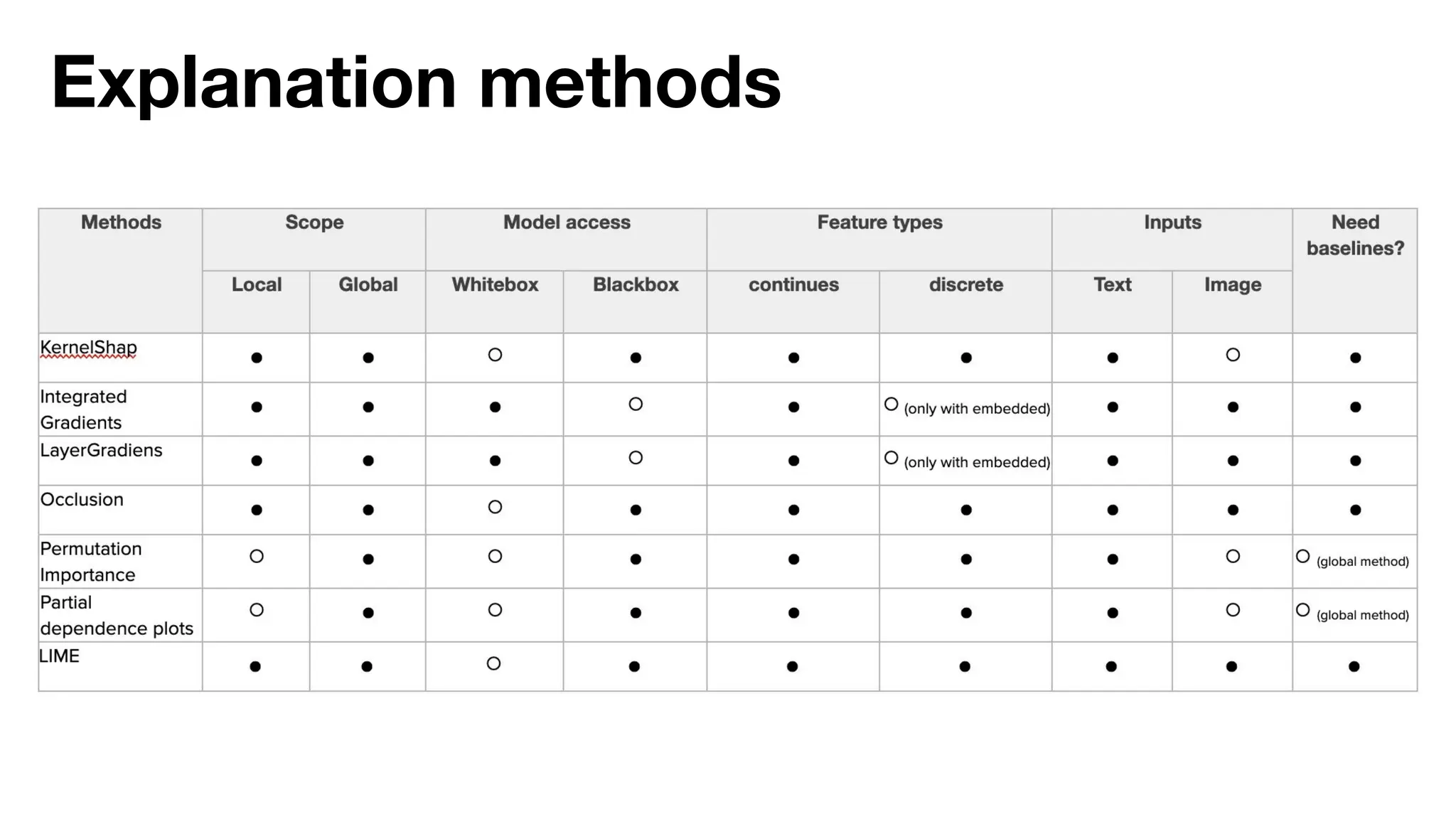
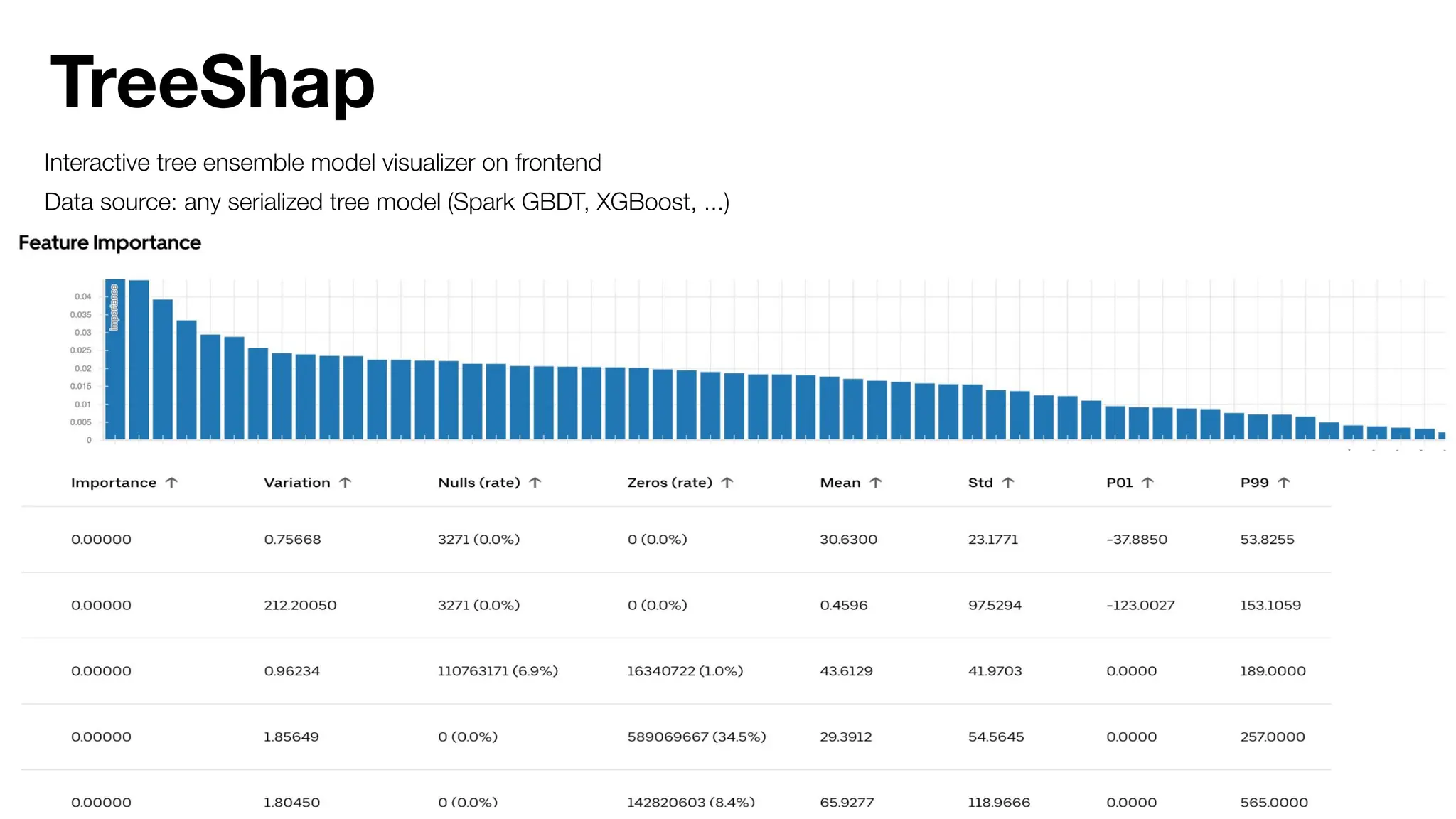
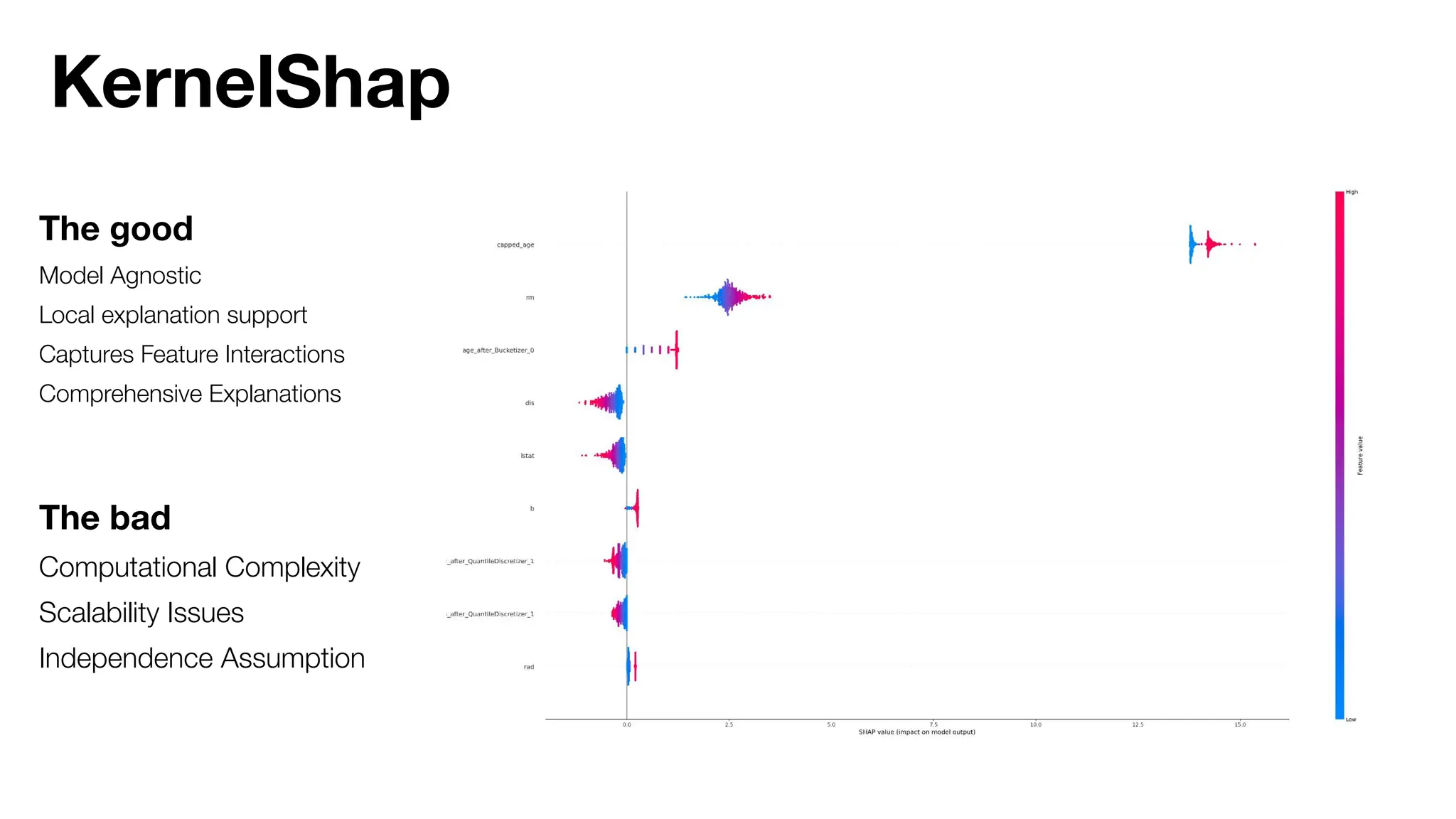
The document discusses the importance of machine learning (ML) explainability within Uber's Michelangelo platform, highlighting the challenges and needs for improved model transparency and understanding. It outlines various explanation methods, user workflows, case studies, and architectural components necessary to integrate explainable AI (XAI) in ML models. Future opportunities for advancing XAI practices and addressing user needs for interpretability and debugging are also noted.



































































