Downloaded 47 times









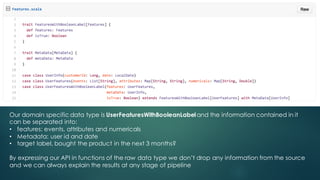



![The simplest numerical transformer, takes a getter function that extract a Map[Key, Double] from the
generic Features type and return a SubFeaturesTransformer where they key-value map is flattened into a
vector with the original values (no normalization).
If we want to apply for example a standard scaling we could simply train on OriginalNumericalsTransformer
and pipe the function returned by subfeaturesToVector into a function Vector => Vector which would
represent our scaler.](https://image.slidesharecdn.com/machine-learning-pipelines-predictive-buying-160408123059/85/Robust-and-declarative-machine-learning-pipelines-for-predictive-buying-at-Barclays-16-320.jpg)


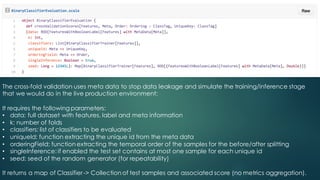
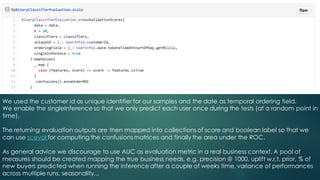
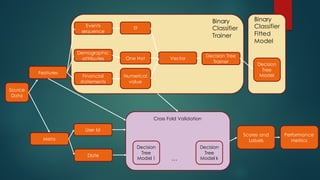



The document discusses the development of robust machine learning pipelines for predictive buying, emphasizing the integration of modern engineering practices with the scientific method. It outlines principles for data validation and evaluation frameworks, introduces a case study involving a binary classifier predicting user purchases, and highlights the creation of a type-safe API for machine learning within Spark. Key conclusions stress the importance of transparency, reproducibility, and iterative refinement in building production-ready models.





























































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)













