Download as PDF, PPTX


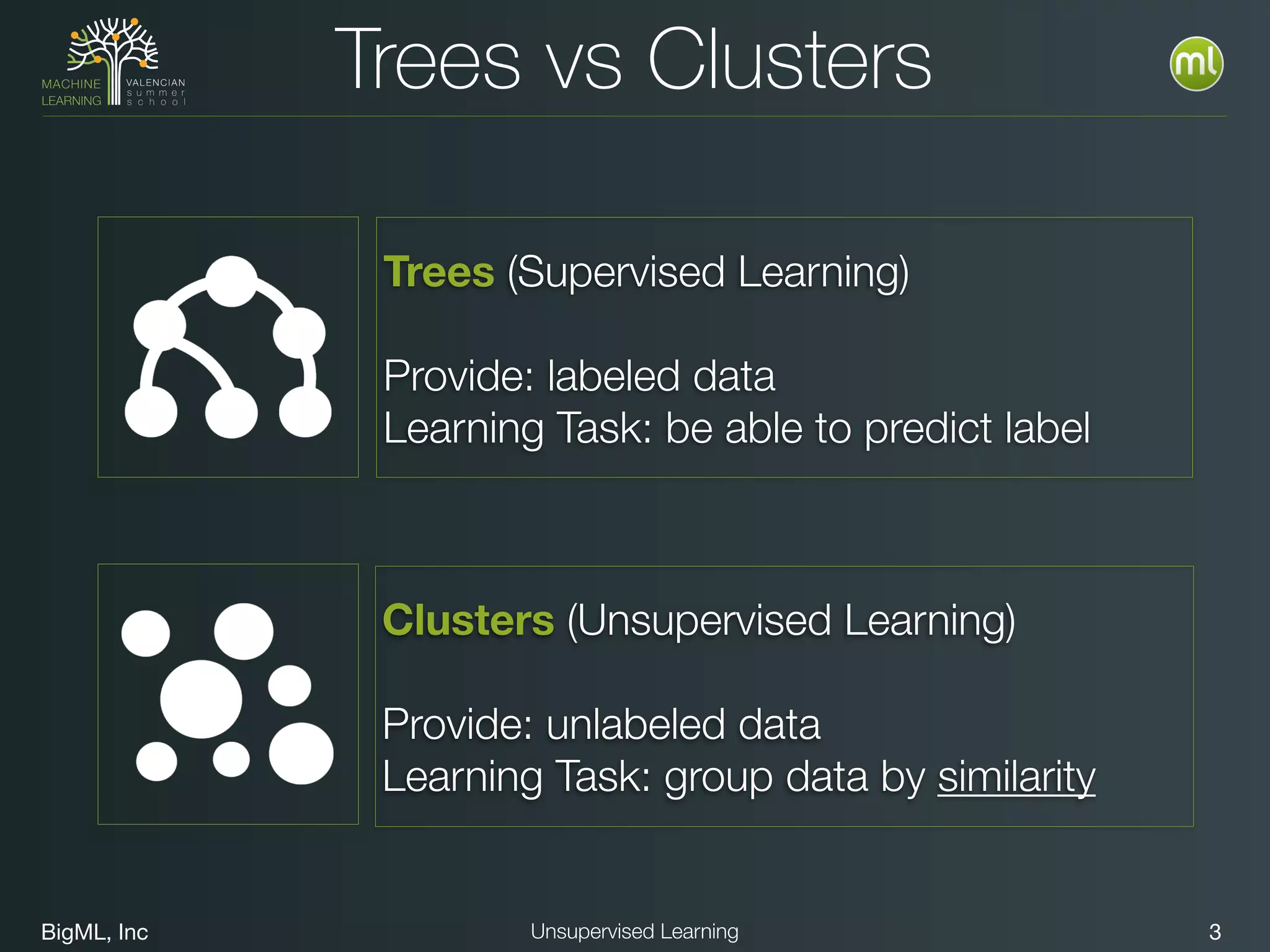


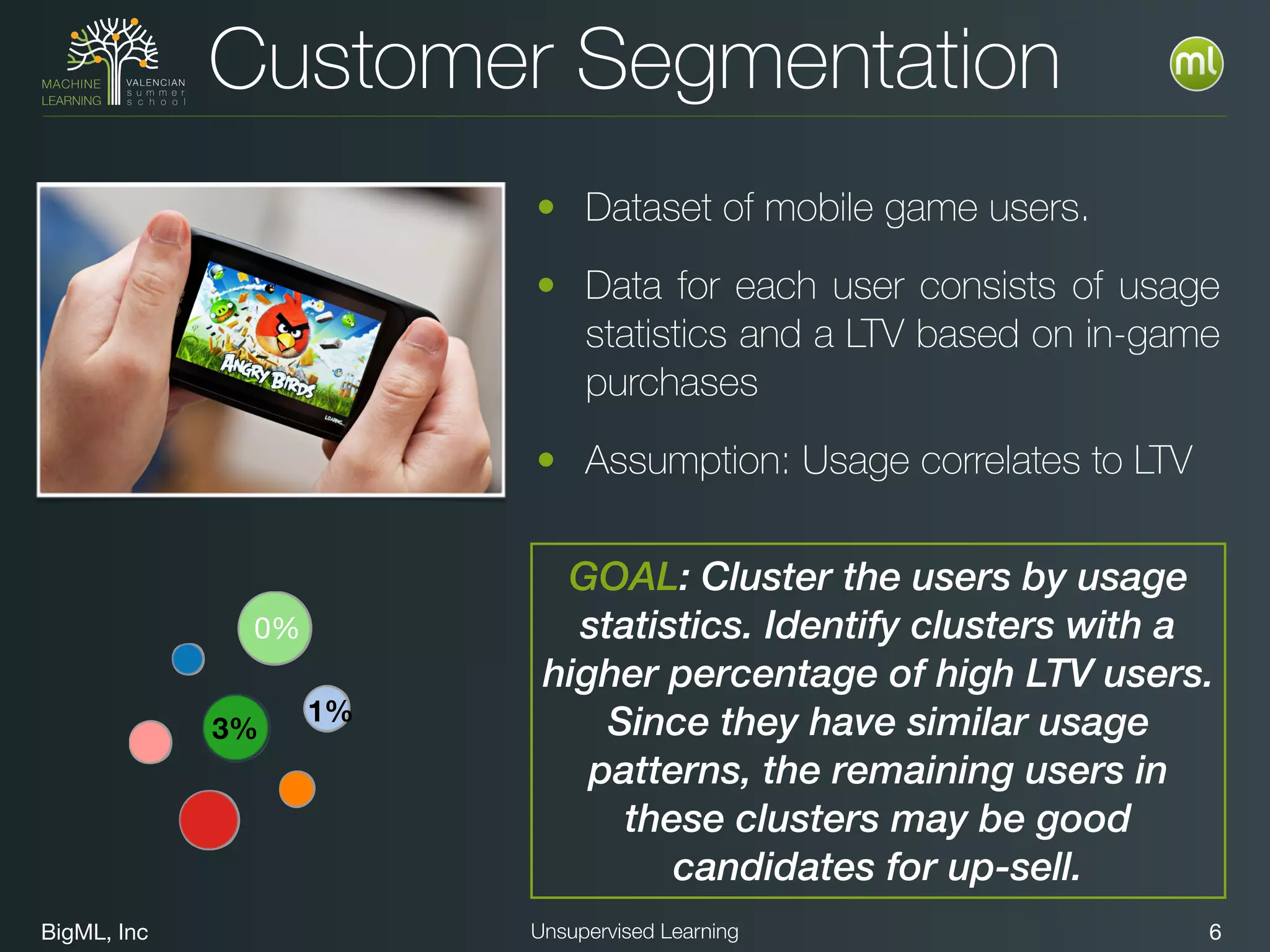


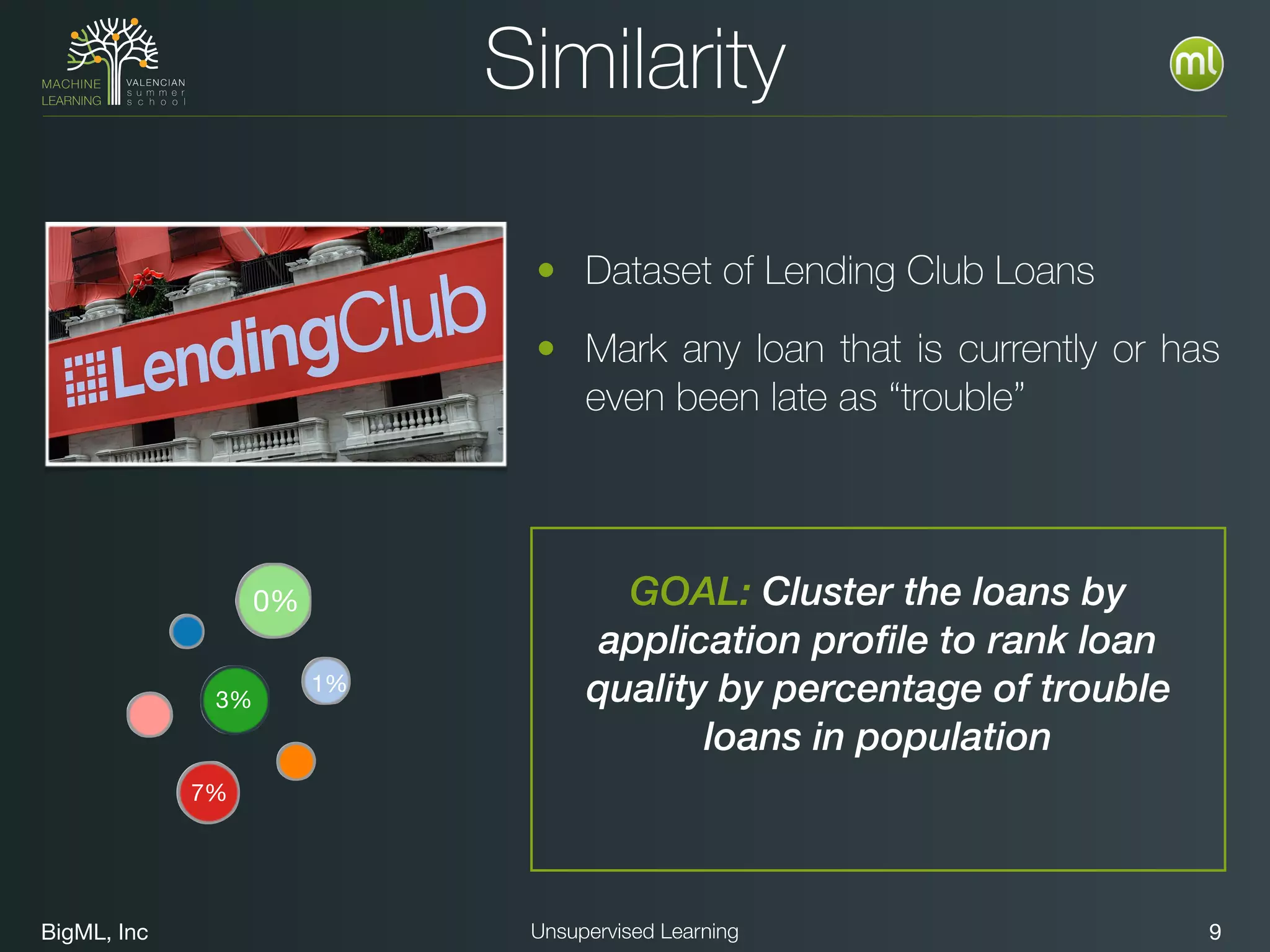









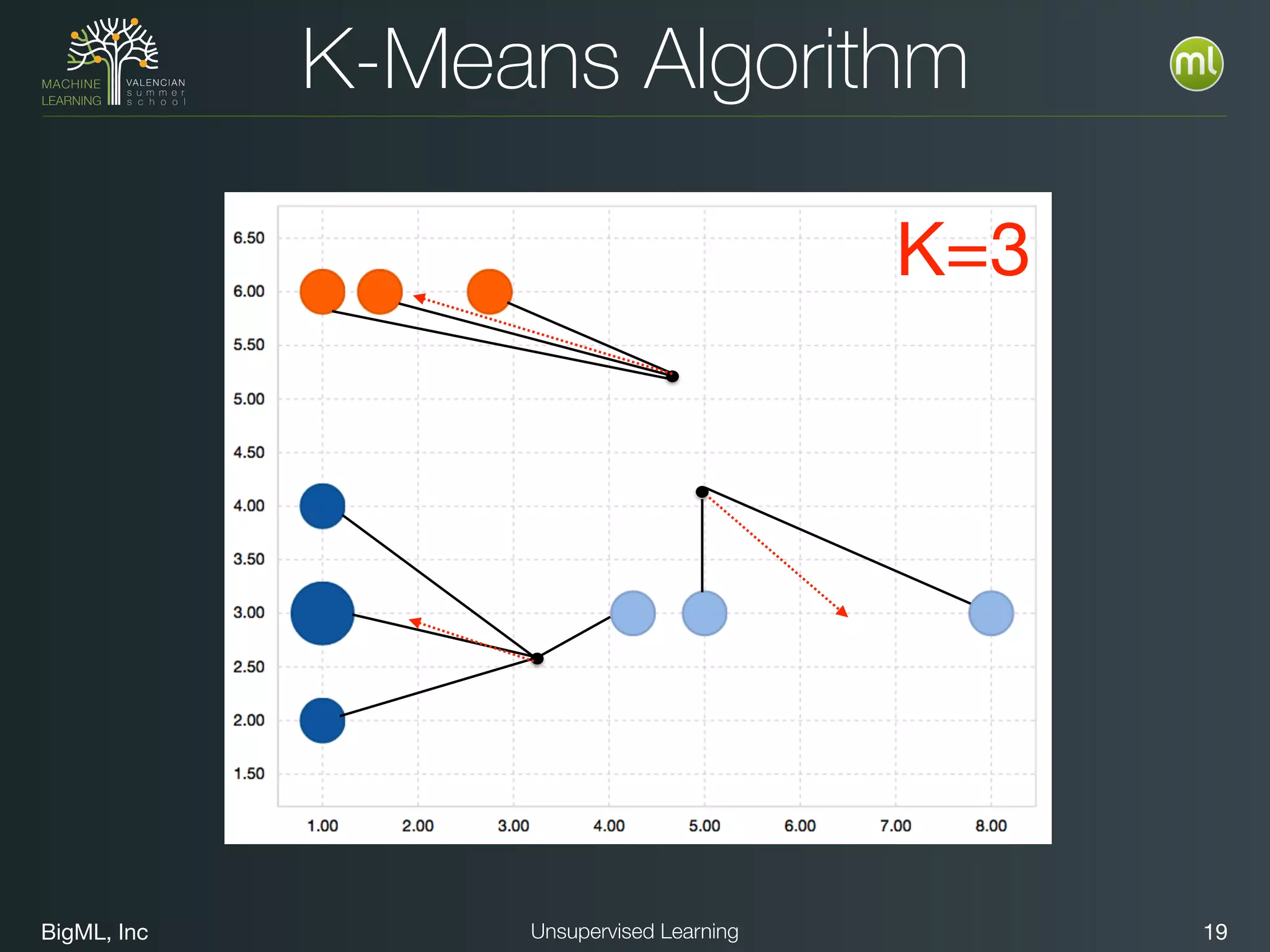


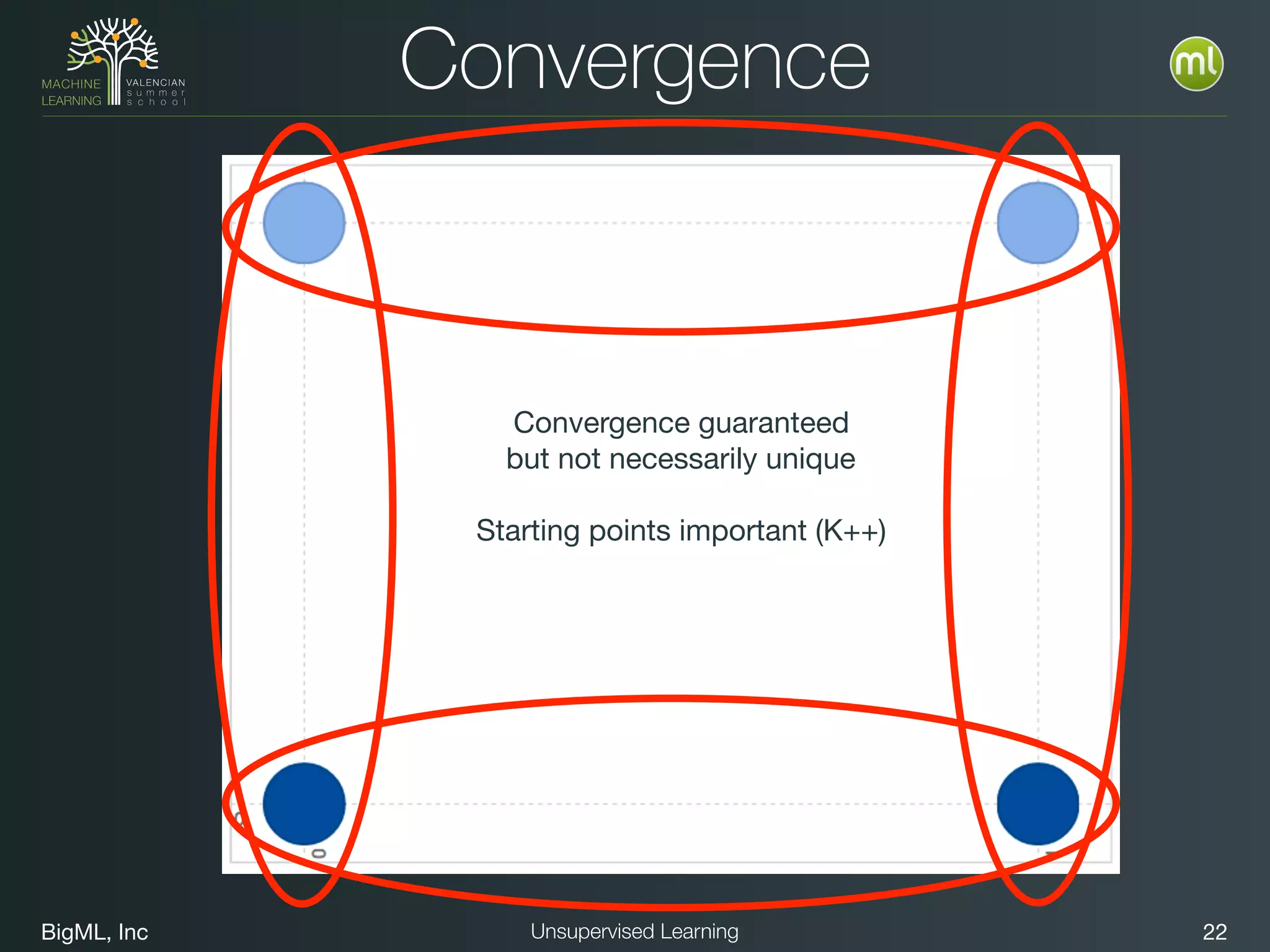






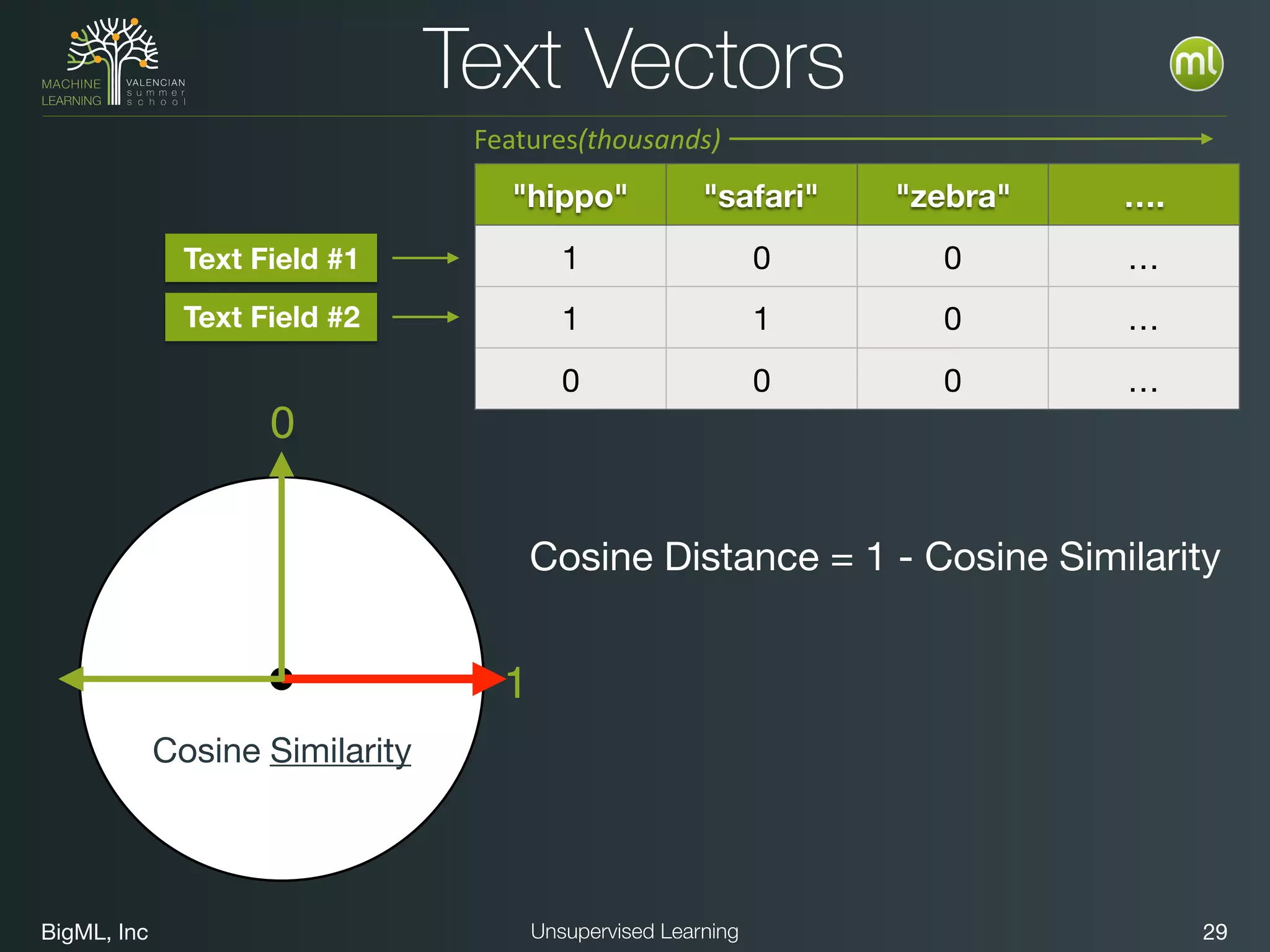
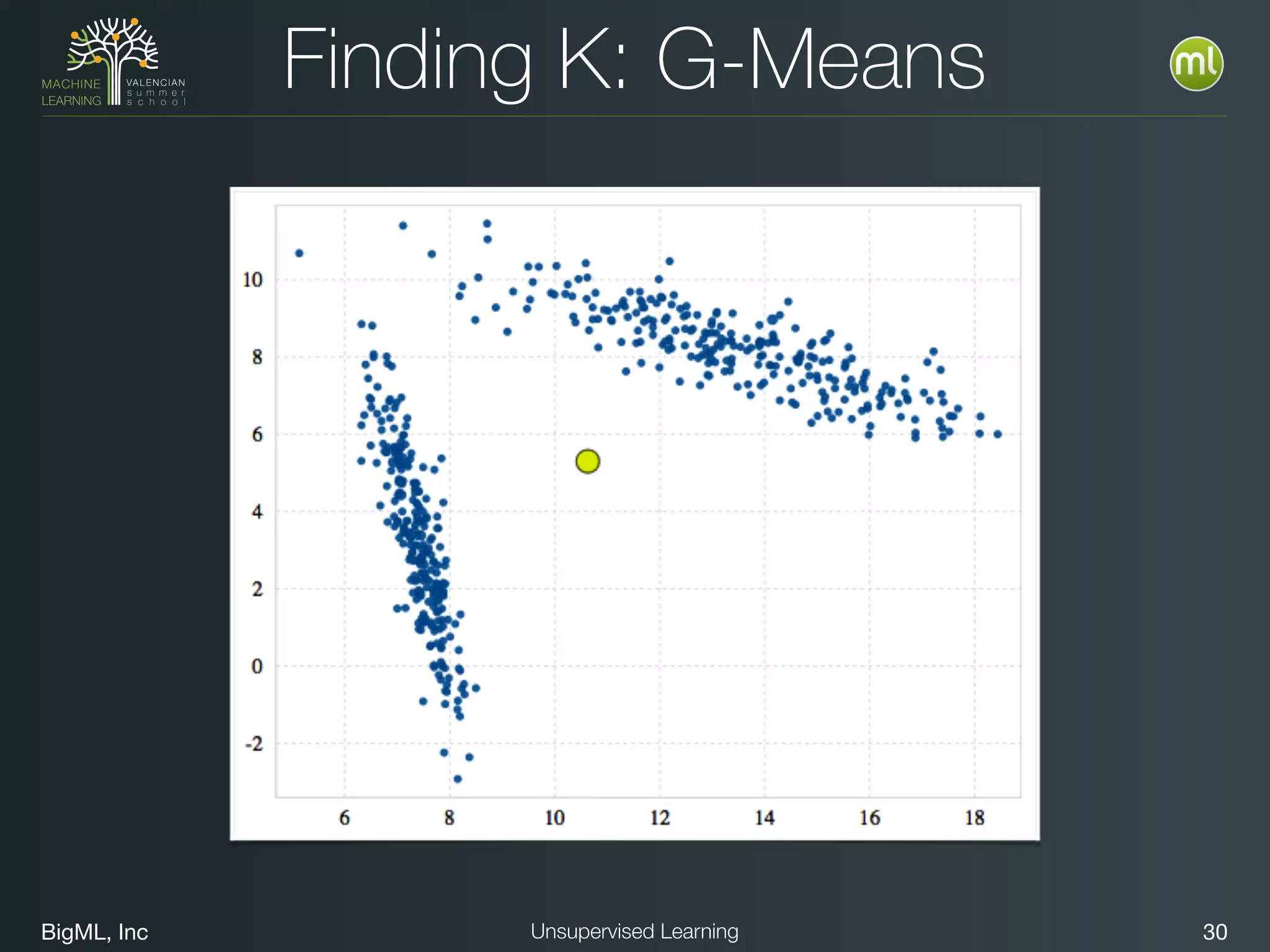
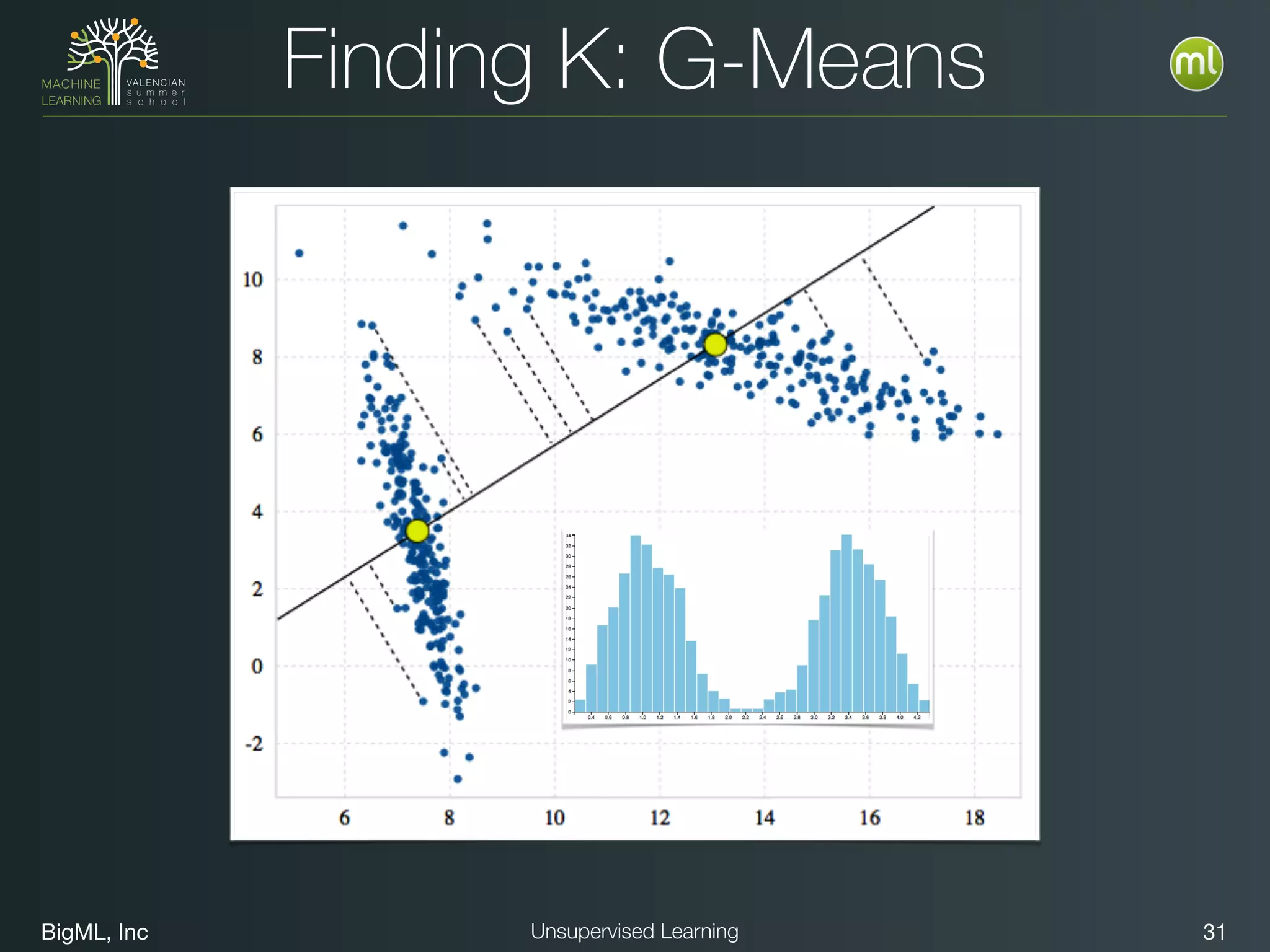



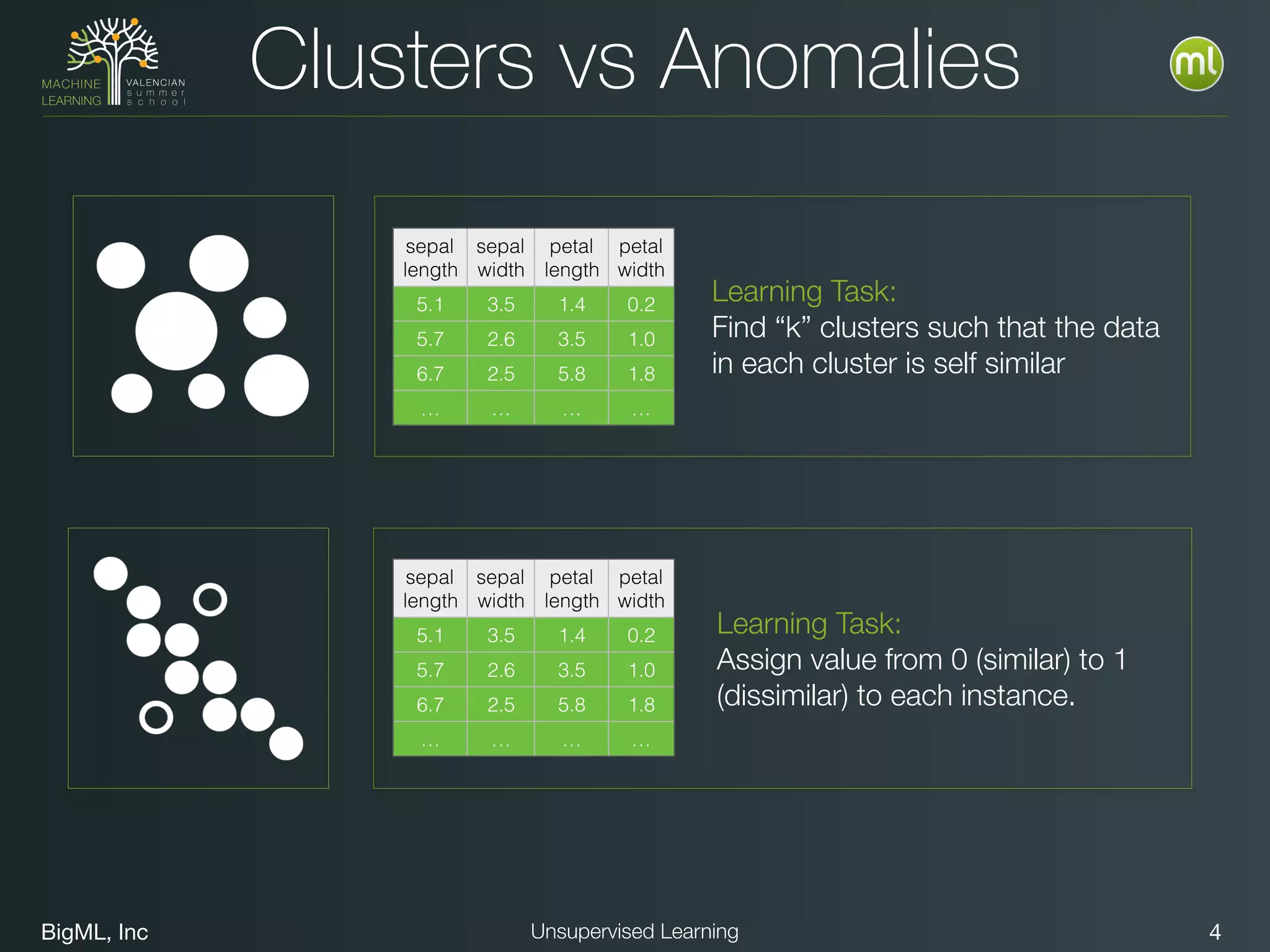




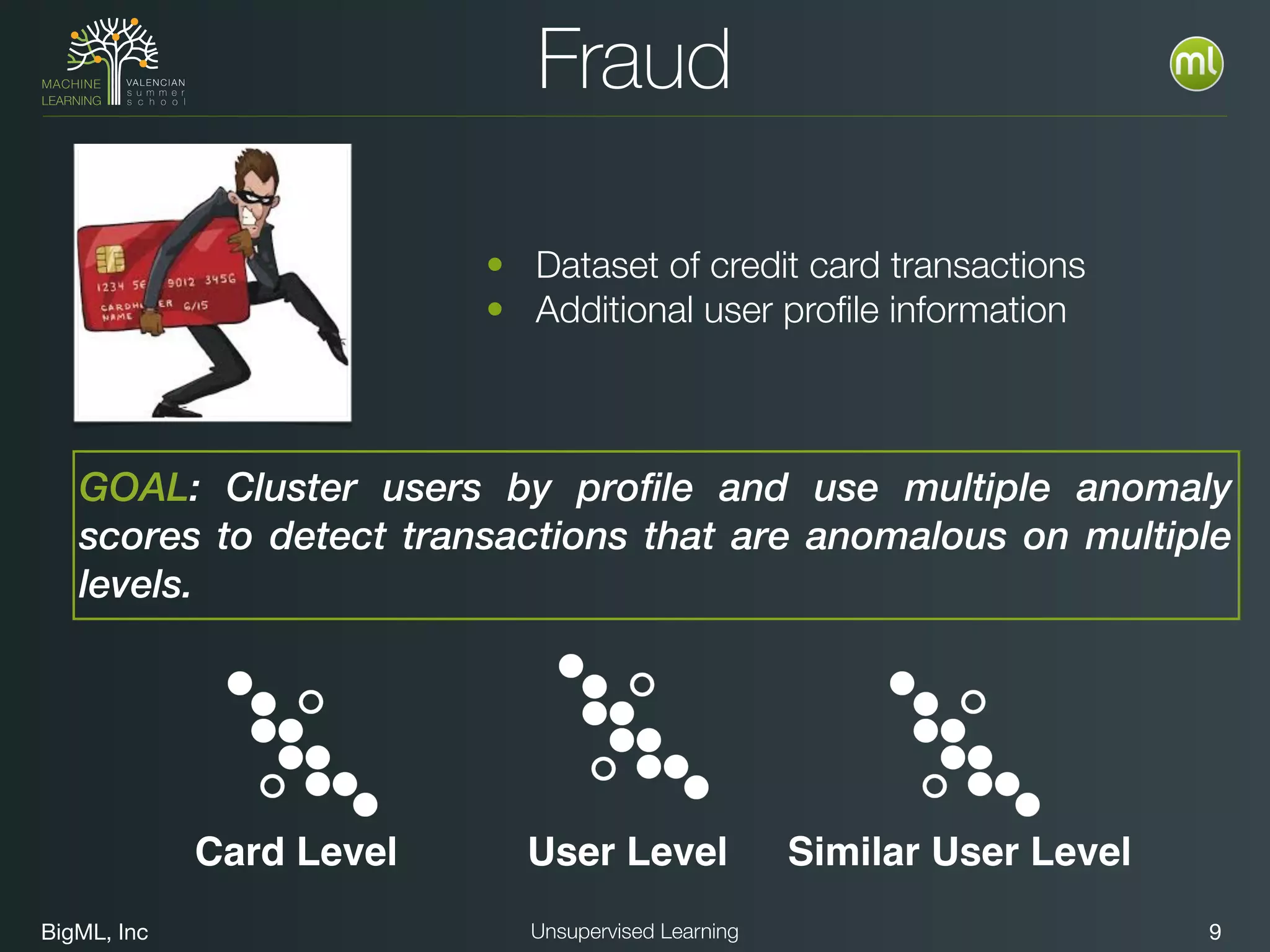


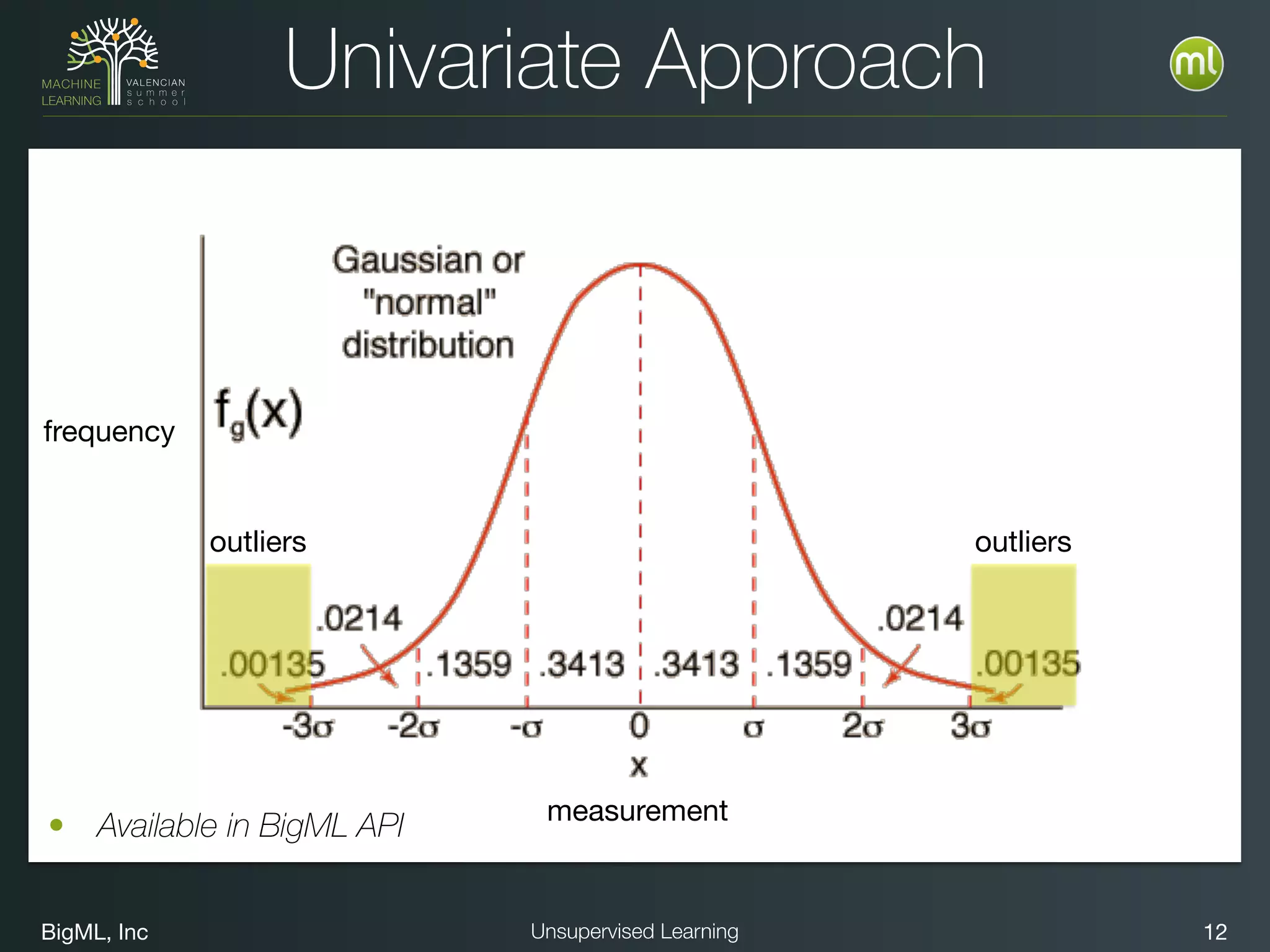


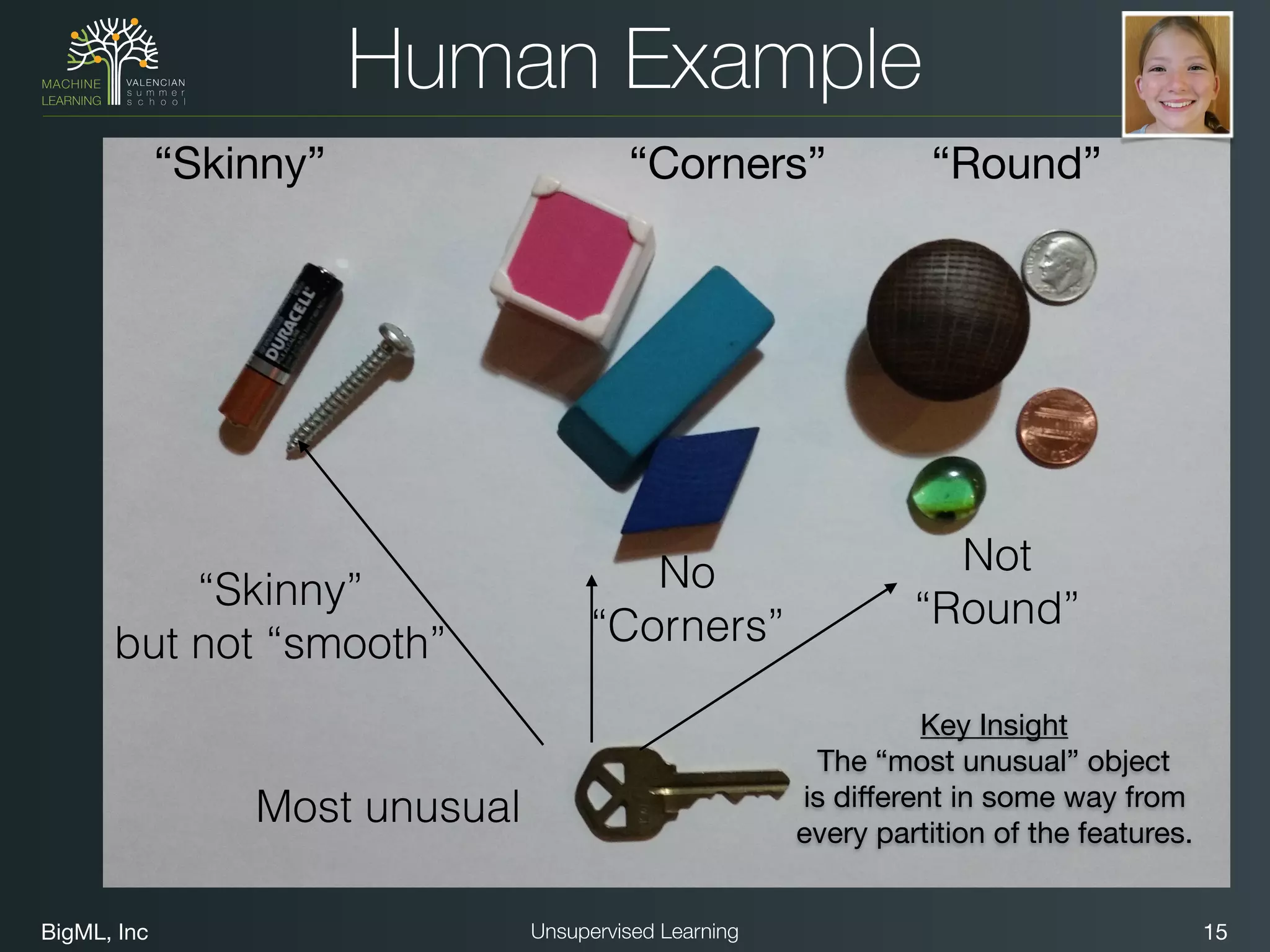


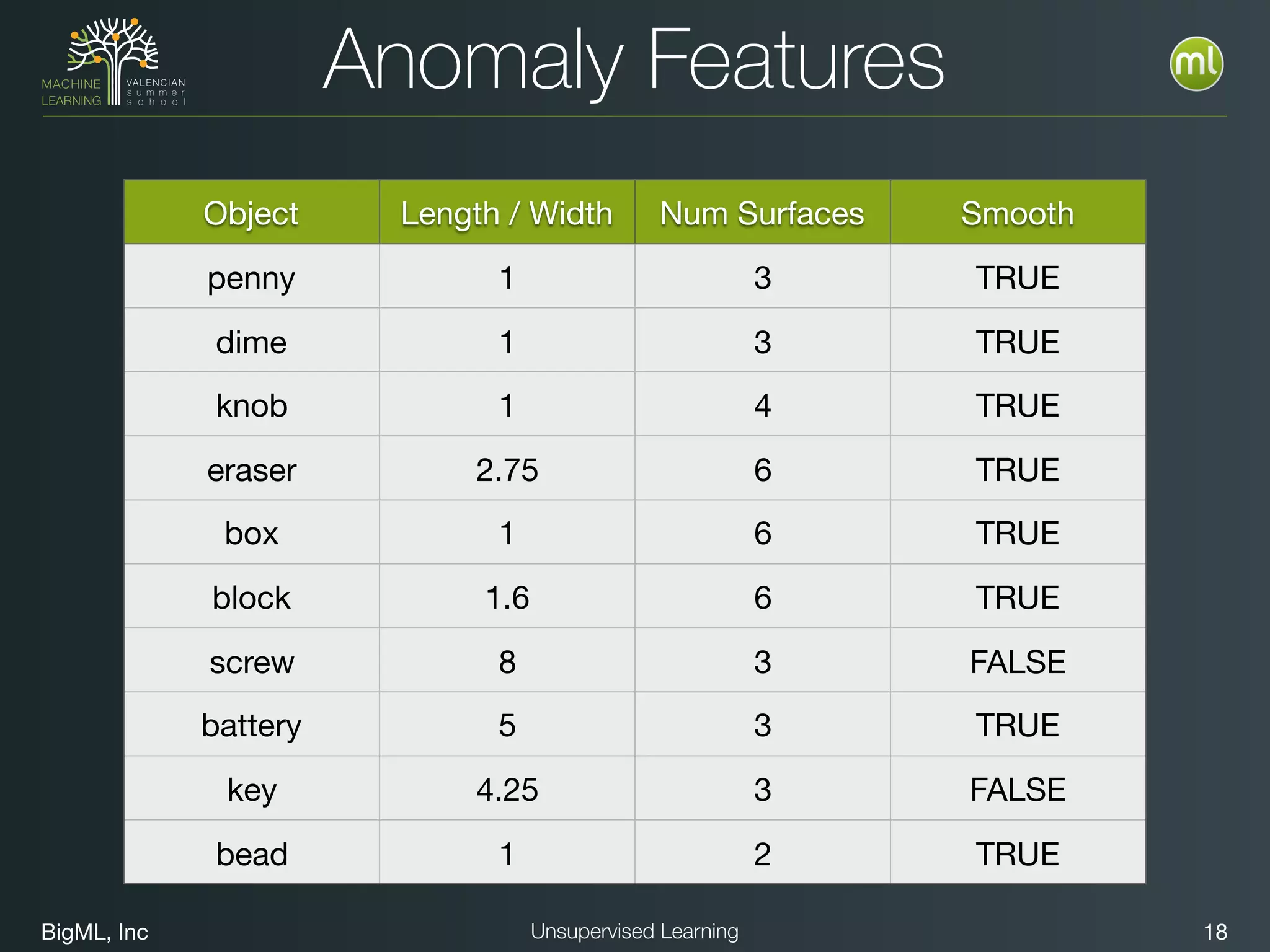

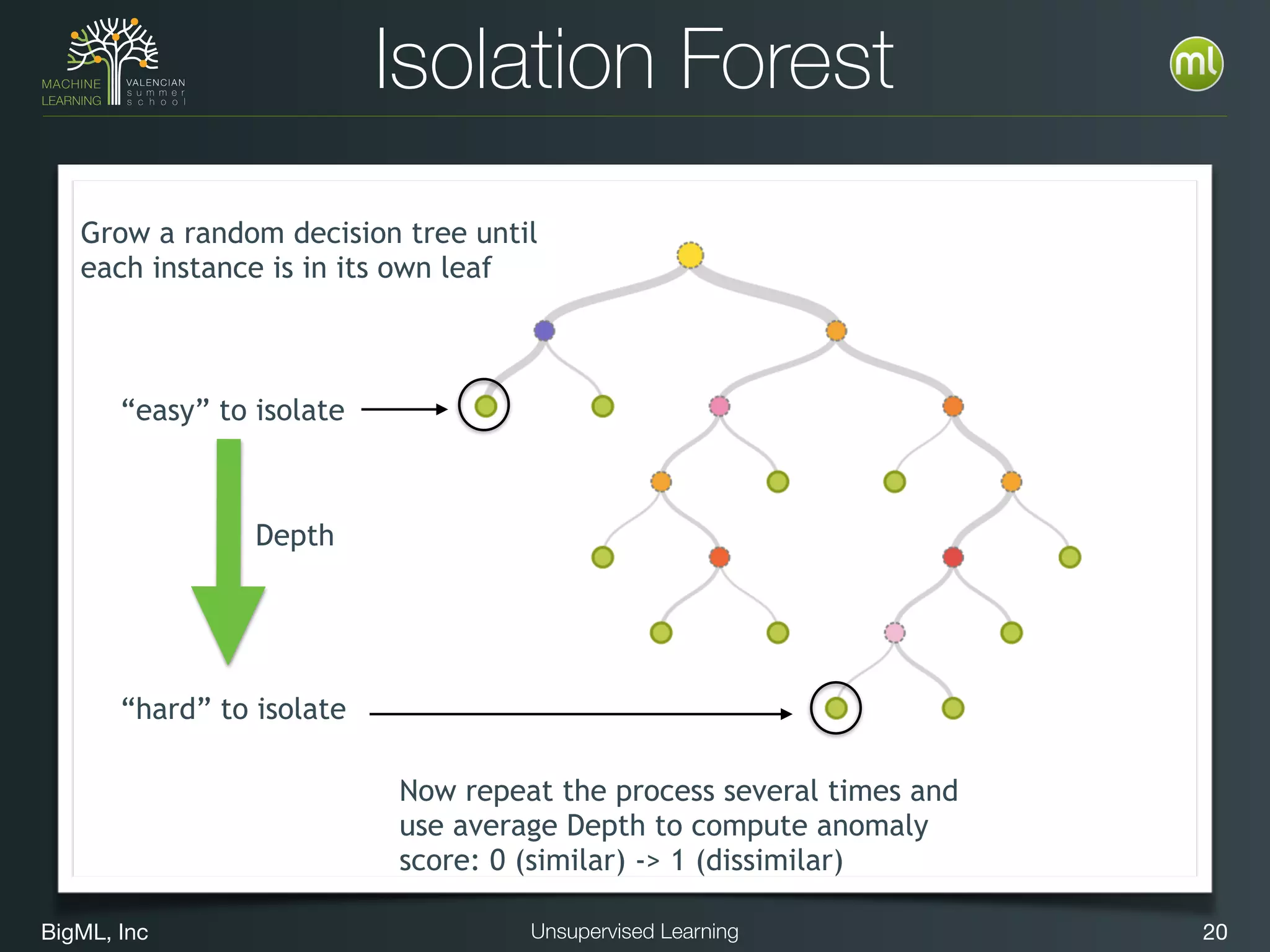
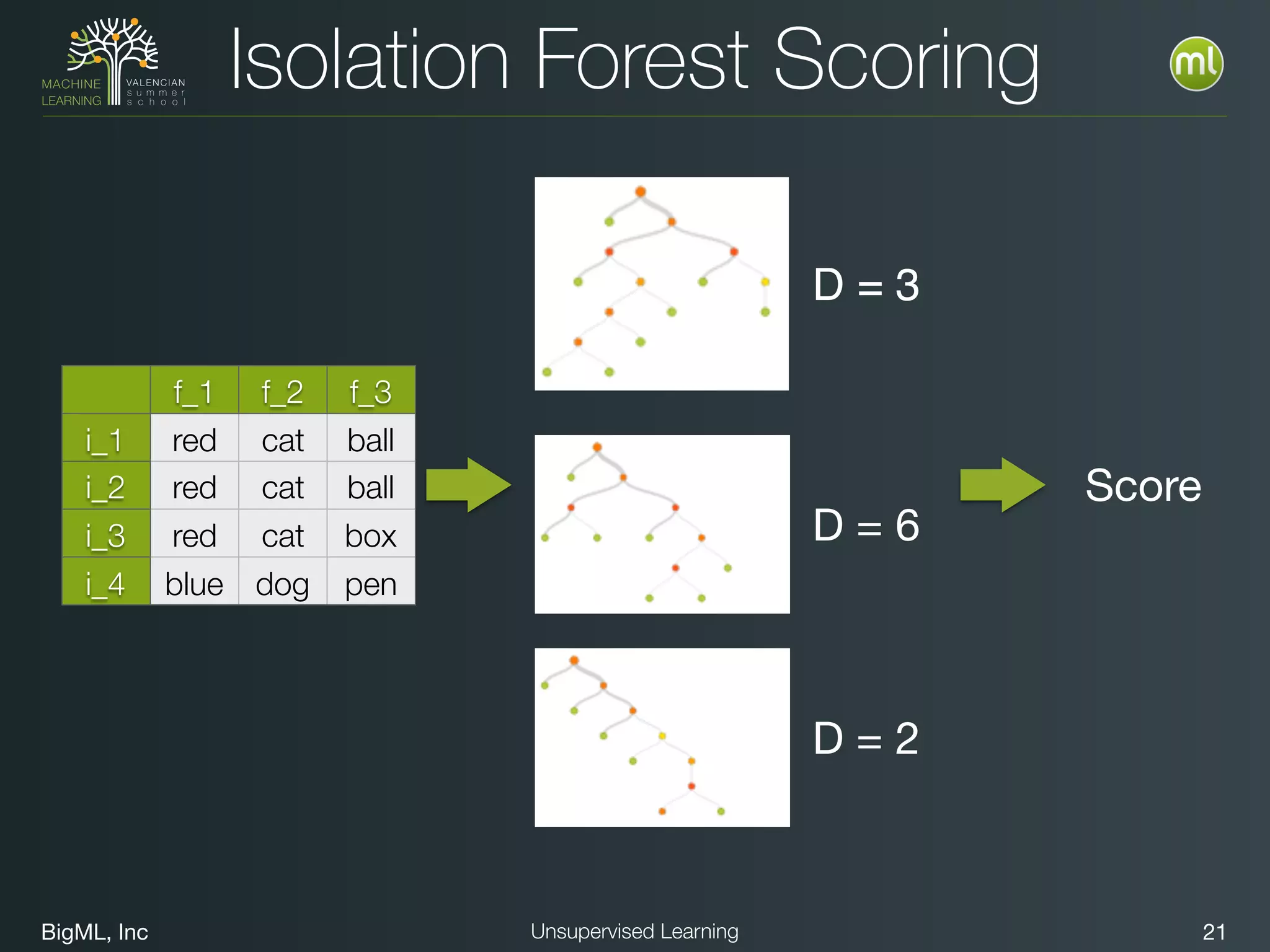



The document discusses unsupervised learning techniques, specifically cluster analysis, including applications in customer segmentation, item discovery, and anomaly detection. It outlines various use cases, such as grouping mobile game users by usage and clustering loans by application profiles. The document also explores methods for identifying anomalous behavior and ensuring model competence through anomaly detection strategies.





































































































