Download as PDF, PPTX



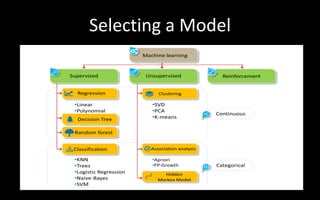






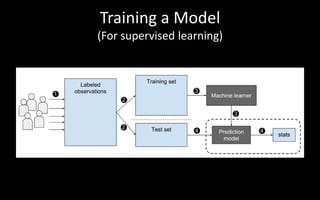

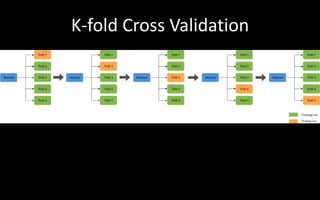




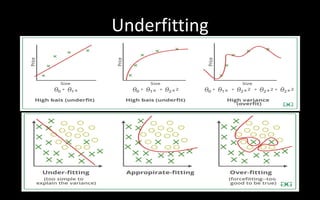





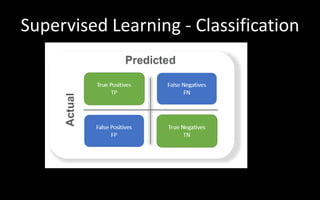

The document discusses modelling and evaluation in machine learning. It defines what models are and how they are selected and trained for predictive and descriptive tasks. Specifically, it covers: 1) Models represent raw data in meaningful patterns and are selected based on the problem and data type, like regression for continuous numeric prediction. 2) Models are trained by assigning parameters to optimize an objective function and evaluate quality. Cross-validation is used to evaluate models. 3) Predictive models predict target values like classification to categorize data or regression for continuous targets. Descriptive models find patterns without targets for tasks like clustering. 4) Model performance can be affected by underfitting if too simple or overfitting if too complex,




















































































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)


