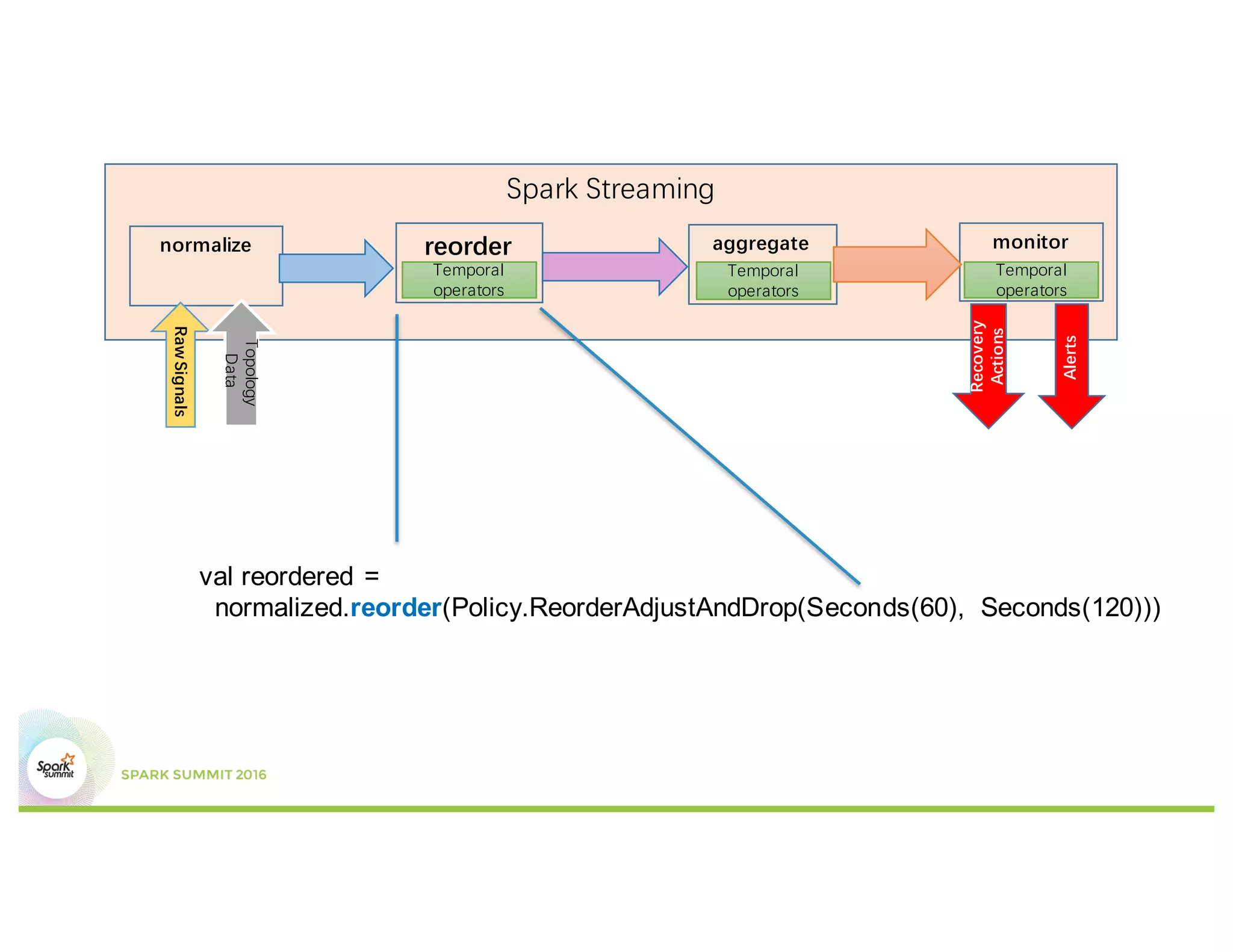
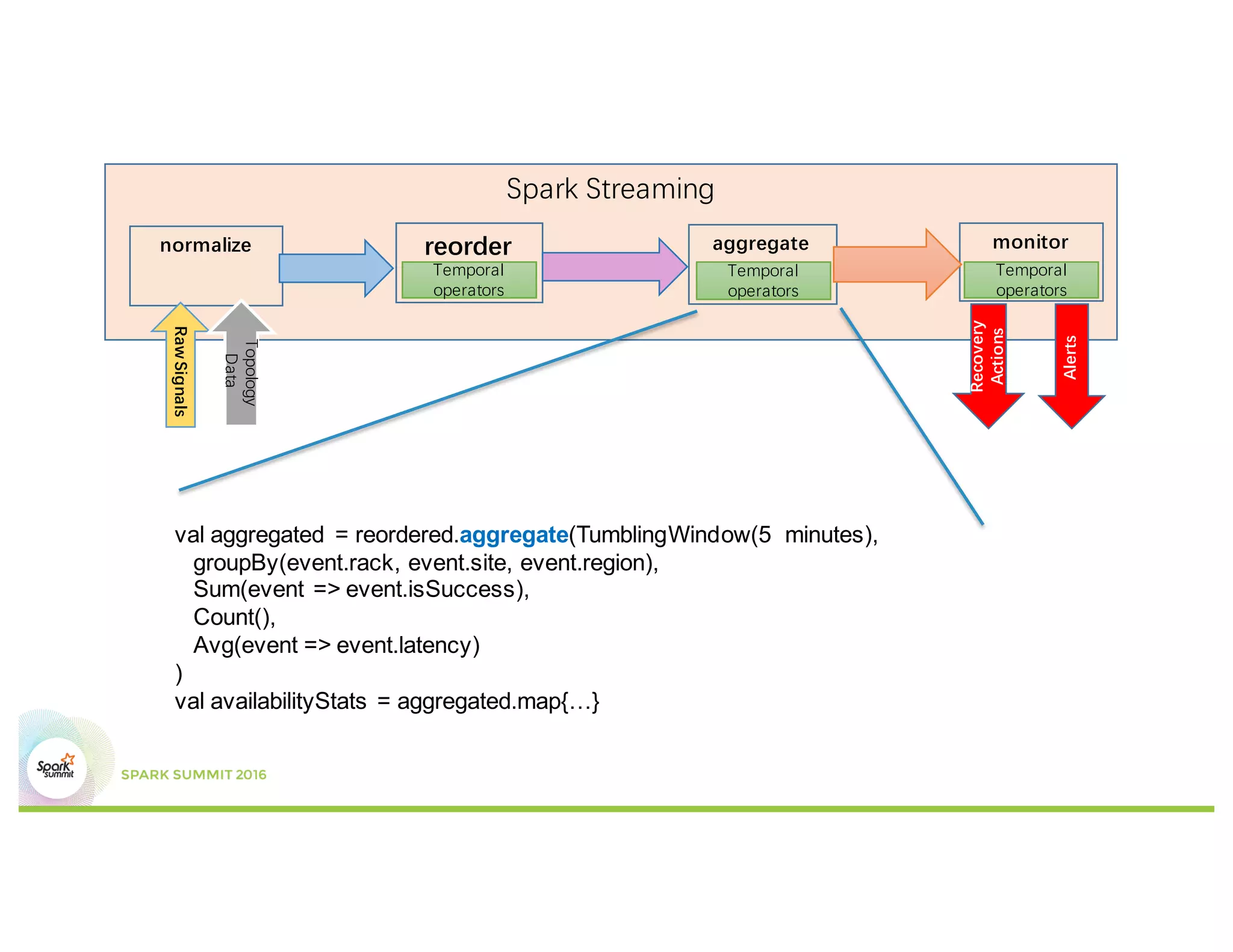
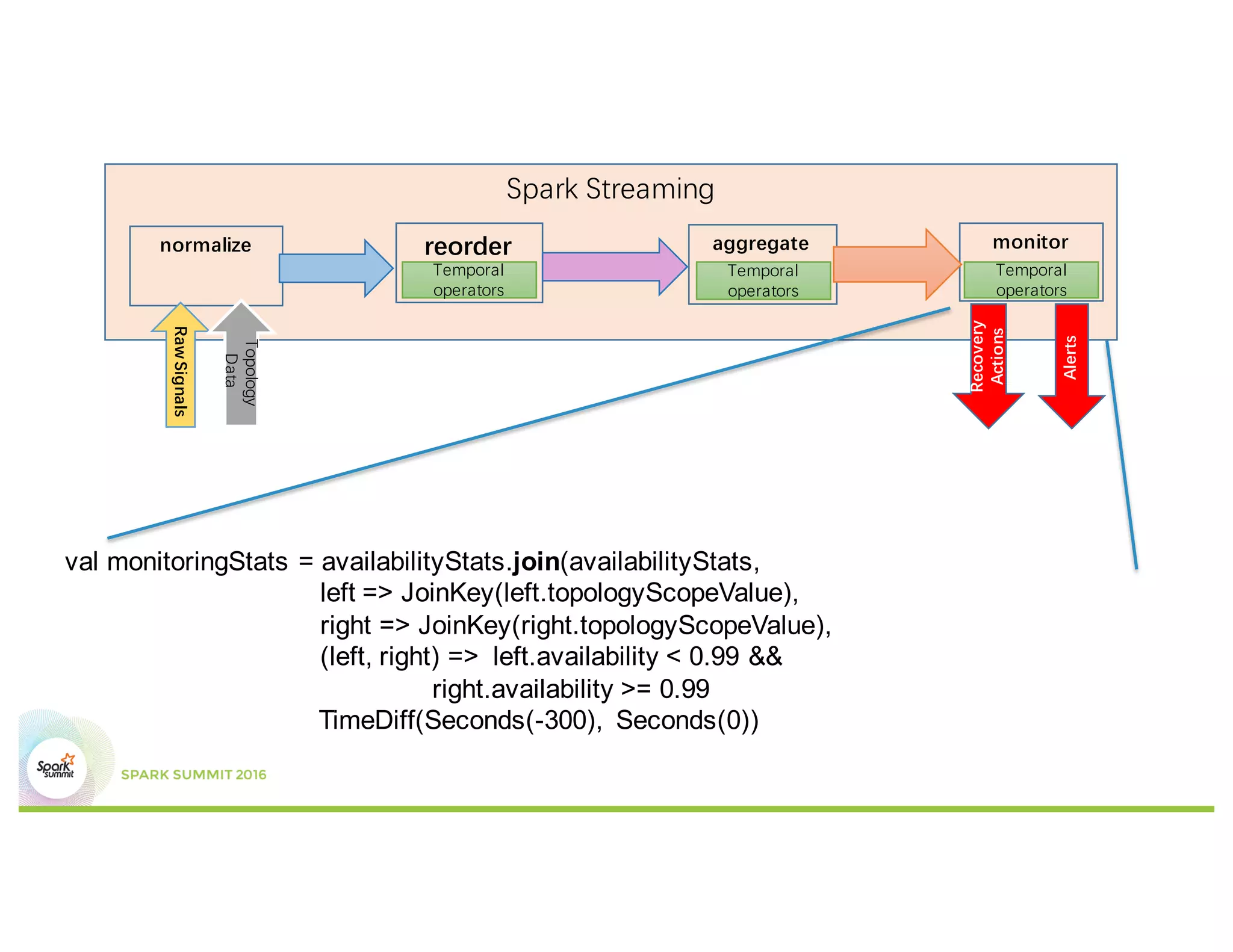
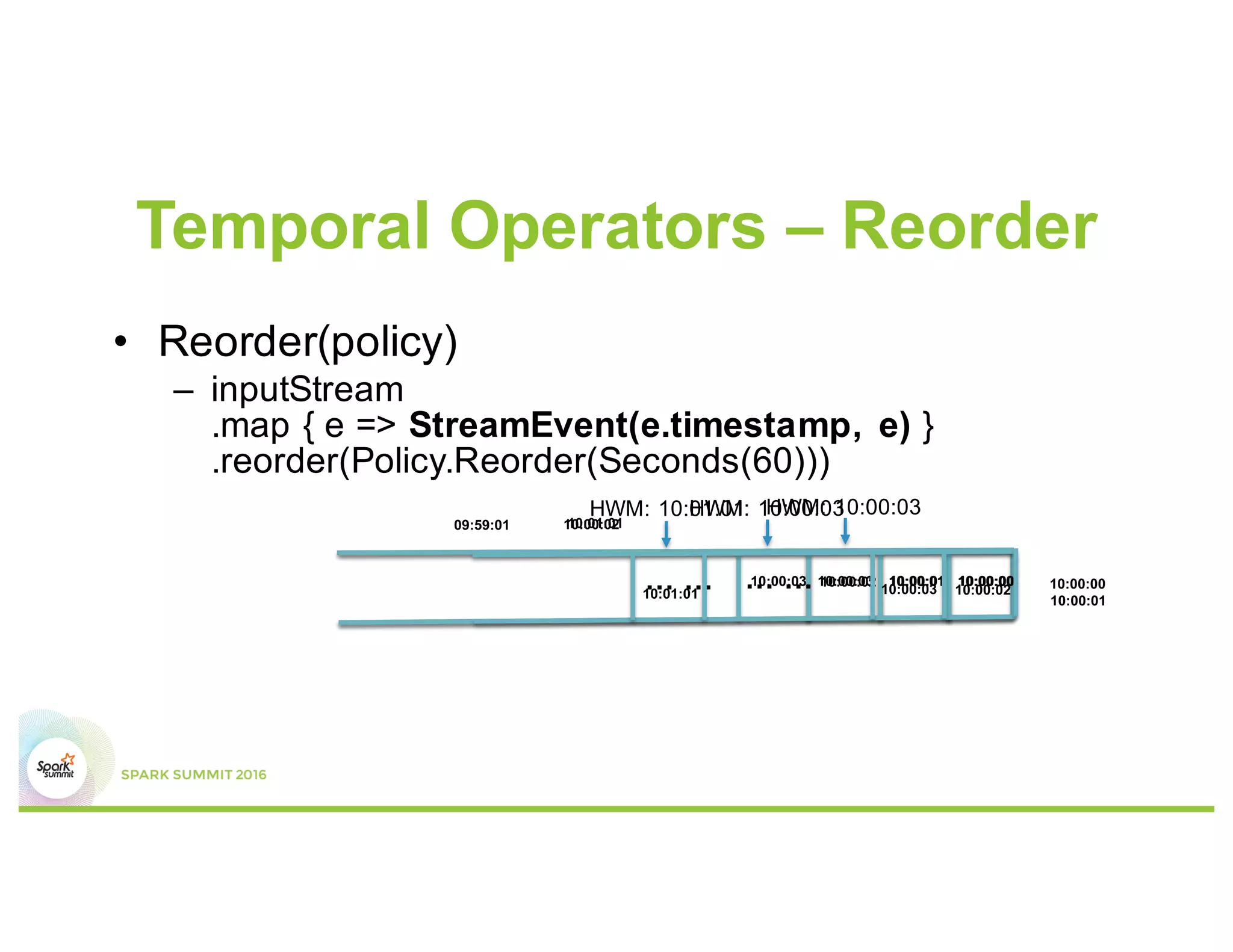
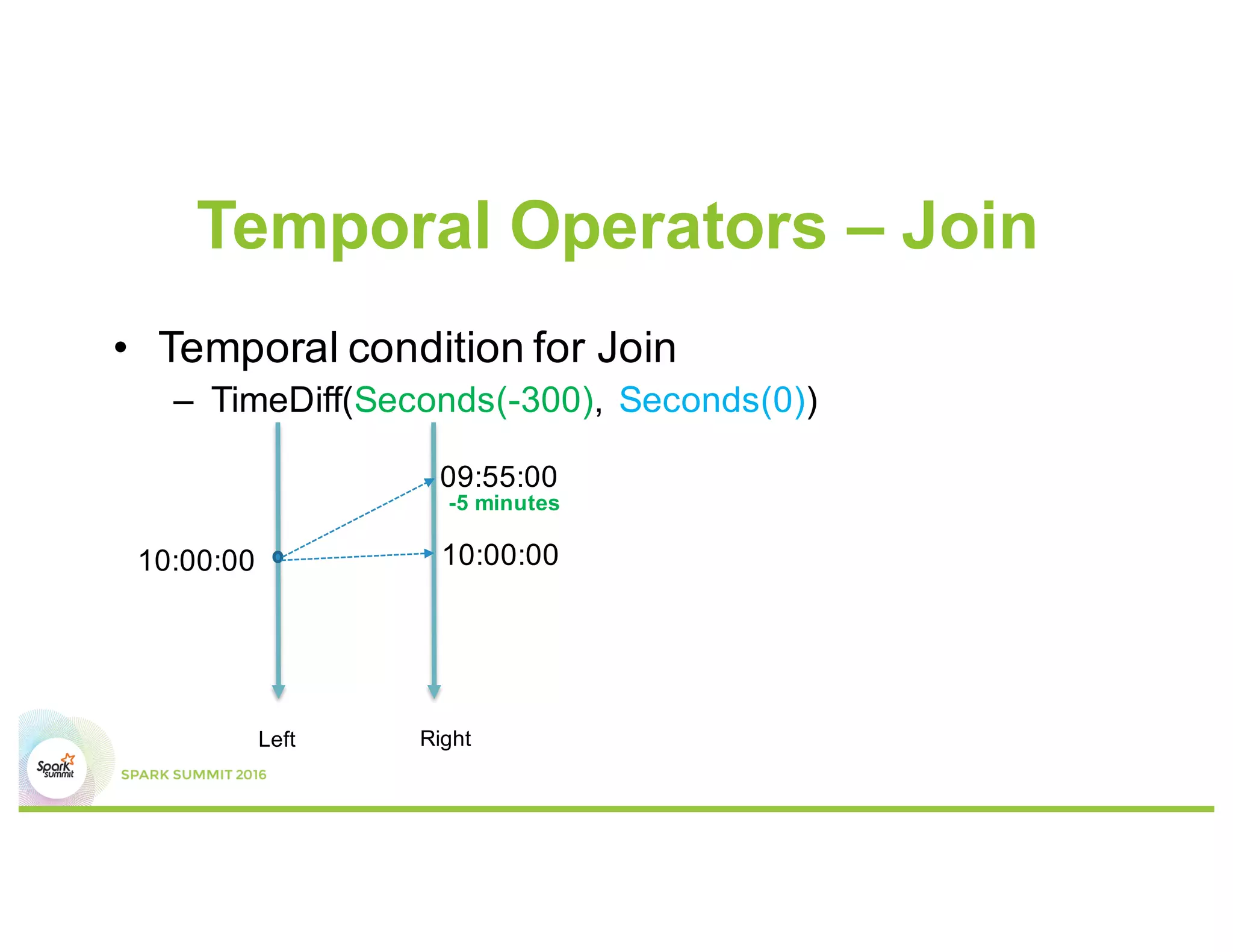
This document discusses temporal operators for Spark Streaming and their application for Office365 service monitoring. It introduces temporal operators like reorder, event-time window aggregate, and join that allow normalizing and aggregating streaming data that may arrive out of order. These operators are used to calculate availability metrics over tumbling windows and generate alarms when availability drops between the current and previous windows. Examples show how temporal operators reorder, aggregate, and join streaming events based on timestamps to perform time-based analysis for monitoring Office365 services.

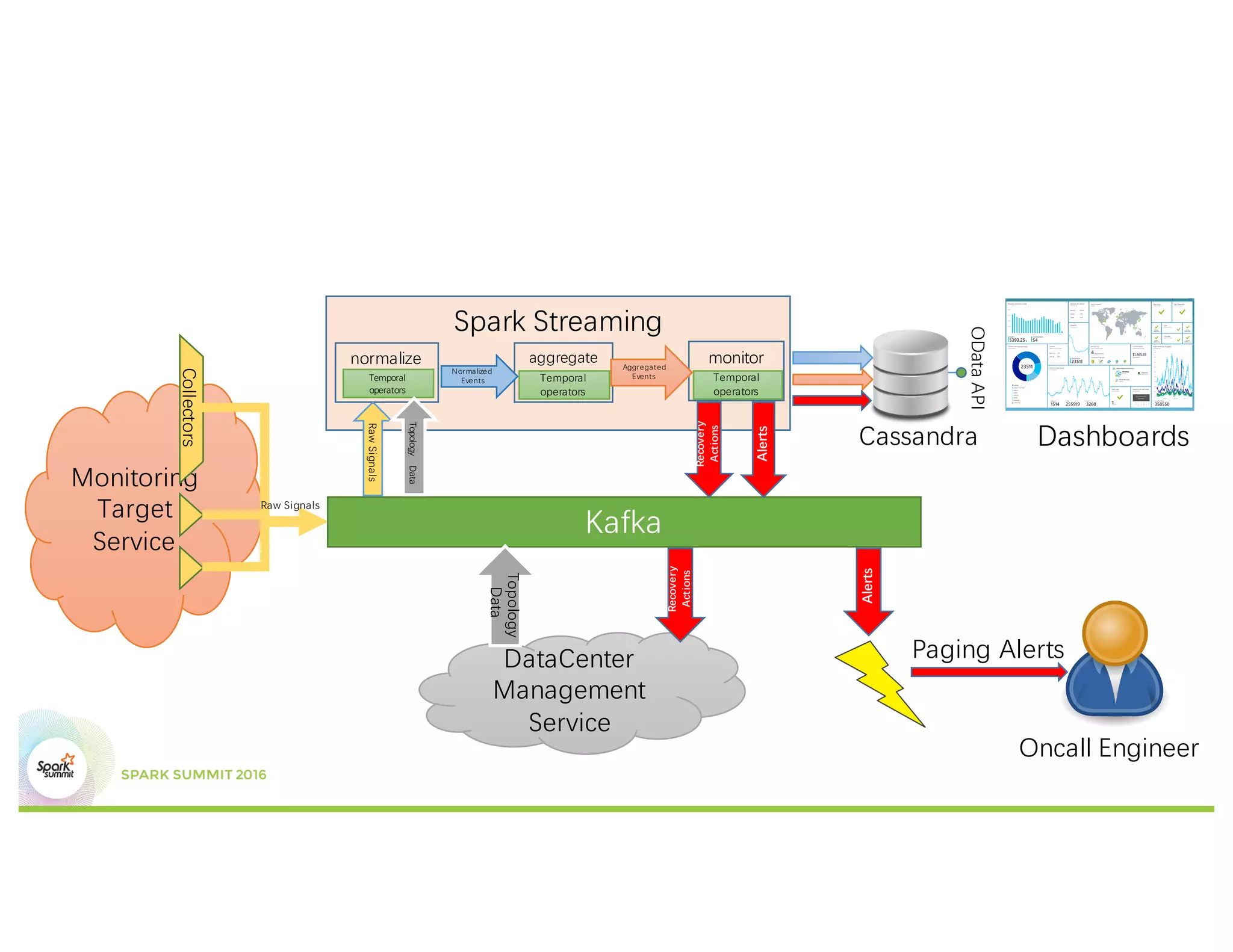

![Spark Streaming
aggregate monitor
Recovery
Actions
Temporal
operators
Temporal
operators
normalize
RawSignals
Topology
Data
Alerts
reorder
Temporal
operators
val rawSignals : DStream[T]
val topologyData: DStream[T1]
val normalized =
rawSignals.join(topologyData, …)](https://image.slidesharecdn.com/3blimiao-160614184543/75/Temporal-Operators-For-Spark-Streaming-And-Its-Application-For-Office365-Service-Monitoring-4-2048.jpg)