Download as PDF, PPTX


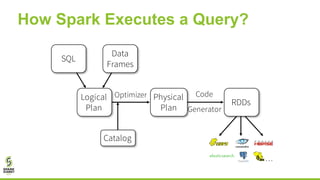
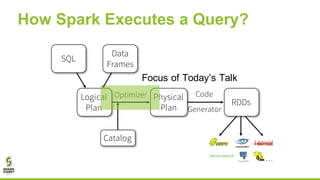
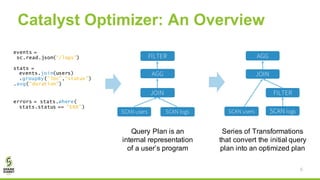


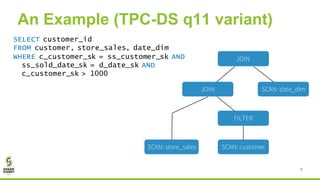































![New Commands in Apache Spark 2.2
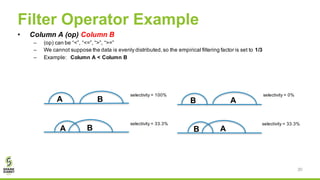
• CBO commands
– Collect table-level statistics
• ANALYZE TABLE table_name COMPUTE STATISTICS
– Collect column-level statistics
• ANALYZE TABLE table-name COMPUTE STATISTICS FOR COLUMNS column_name1,
column_name2, …
– Display statistics in the optimized logical plan
> EXPLAIN COST
> SELECT cc_call_center_sk, cc_call_center_id FROM call_center;
…
== Optimized Logical Plan ==
Project [cc_call_center_sk#75, cc_call_center_id#76], Statistics(sizeInBytes=1680.0 B, rowCount=42, hints=none)
+- Relation[…31 fields] parquet, Statistics(sizeInBytes=22.5 KB, rowCount=42, hints=none)
…
55](https://image.slidesharecdn.com/ss2017costbasedoptimizer-170608221811/85/Cost-Based-Optimizer-in-Apache-Spark-2-2-55-320.jpg)

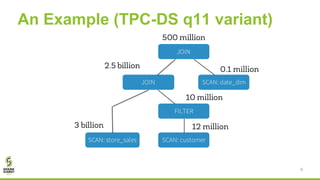
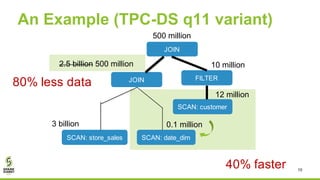
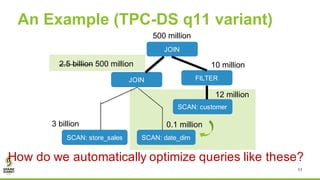
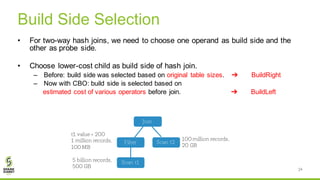
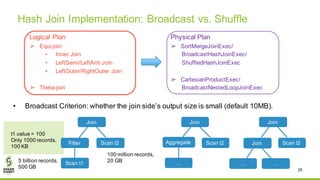
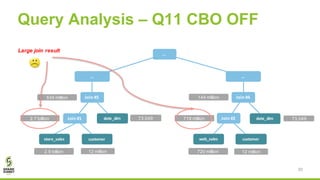
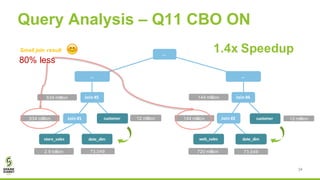
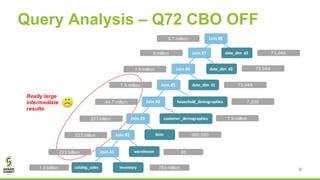
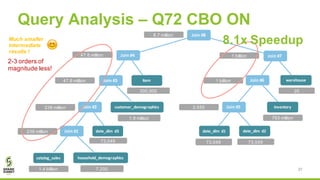
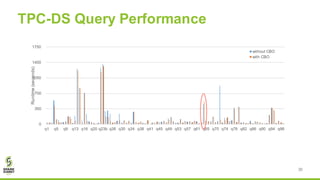
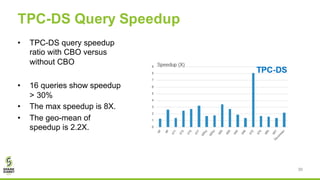
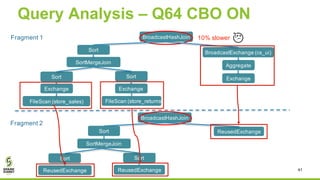
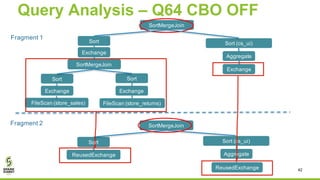
The document discusses Apache Spark's new cost-based optimizer (CBO) in version 2.2. It describes how the CBO works in two key steps: 1. It collects and propagates statistics about tables and columns to estimate the cardinality of operations like filters, joins and aggregates. 2. It calculates the estimated cost of different execution plans and selects the most optimal plan based on minimizing the estimated cost. This allows it to pick more efficient join orders and join algorithms. The document provides examples of how the CBO improves queries on TPC-DS benchmarks by producing smaller intermediate results and faster execution times compared to the previous rule-based optimizer in Spark 2.1.















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)







