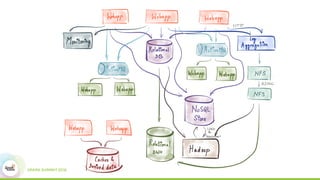
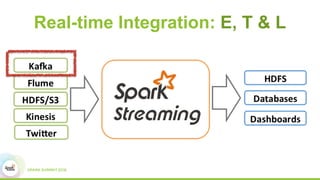
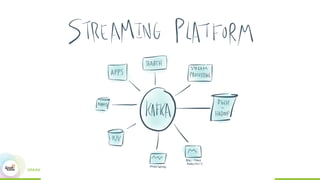
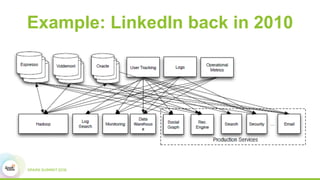
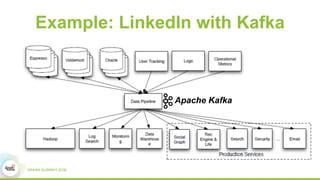
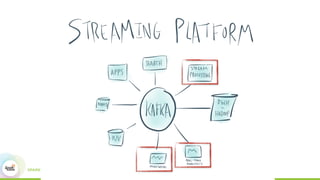
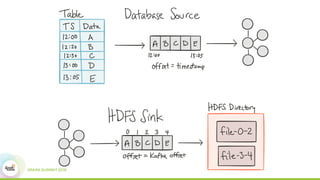
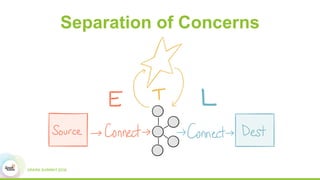
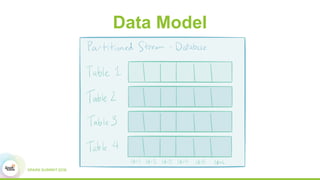
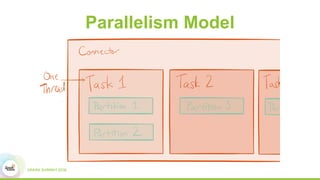
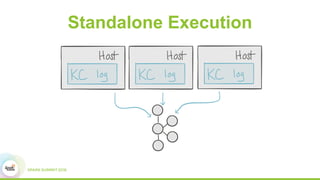
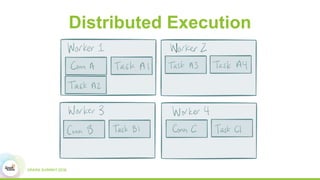
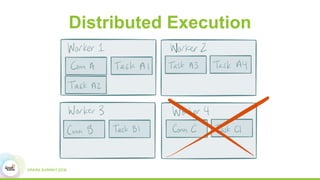
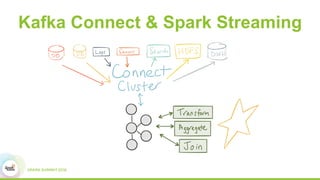
This document discusses building real-time data pipelines with Kafka Connect and Spark Streaming. It introduces Kafka Connect as a tool for large-scale streaming data import and export for Kafka. Kafka Connect uses connectors to move data between Kafka and other data systems in a scalable, parallel, and fault-tolerant manner. It then discusses how Kafka Connect can be used together with Spark Streaming to provide real-time data integration capabilities.