






![Word count in Batch and Streaming
15
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/flinkstreambpdata-150604125901-lva1-app6892/85/Flink-Streaming-BudapestData-15-320.jpg)
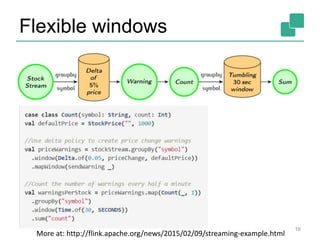



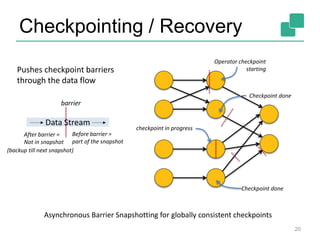


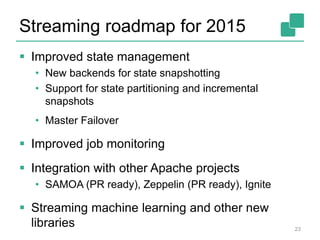


This document provides an overview of Apache Flink, an open-source platform for distributed stream and batch data processing. Flink allows for unified batch and stream processing with a simple yet powerful programming model. It features native stream processing, exactly-once fault tolerance based on consistent snapshots, and high performance optimized for streaming workloads. The document outlines Flink's APIs, state management, fault tolerance approach, and roadmap for continued improvements in 2015.




















































































