Download as PDF, PPTX















![Wire up and Run
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(
args[0], conf, builder.createTopology());
}else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf,
builder.createTopology());
...
}
}](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-20-320.jpg)
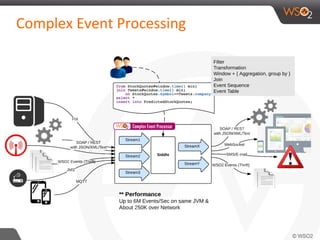






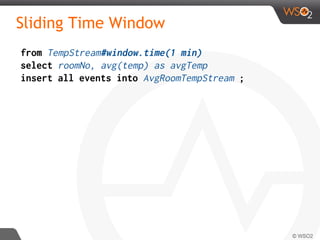
![Filter
from TempStream [ roomNo > 245 and roomNo <= 365]
select roomNo, temp
insert into ServerRoomTempStream ;
In Storm
In CEP ( Siddhi)](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-28-320.jpg)
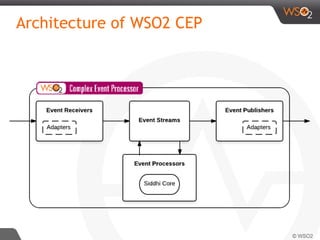

![Stream Definition (Data Model)
{
'name':'soft.drink.coop.sales', 'version':'1.0.0',
'nickName': 'Soft_Drink_Sales', 'description': 'Soft drink sales',
'metaData':[
{'name':'region','type':'STRING'}
],
'correlationData':[
{'name':’transactionID’,'type':'STRING'}
],
'payloadData':[
{'name':'brand','type':'STRING'},
{'name':'quantity','type':'INT'},
{'name':'total','type':'INT'},
{'name':'user','type':'STRING'}
]
}](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-31-320.jpg)






![Filter Alert
from TempStream [ roomNo > 245 and roomNo <= 365
and temp > 40 ]
select roomNo, temp
insert into AlertServerRoomTempStream ;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-38-320.jpg)


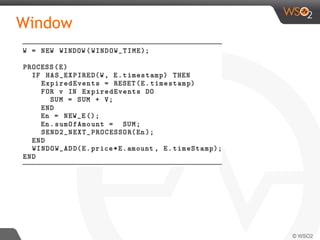
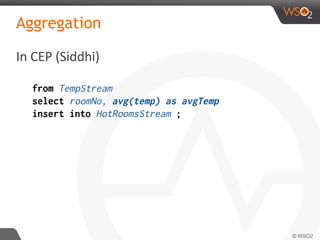




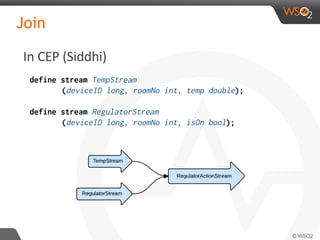
![Join
define stream TempStream
(deviceID long, roomNo int, temp double);
define stream RegulatorStream
(deviceID long, roomNo int, isOn bool);
from TempStream[temp > 30.0]#window.time(1 min) as T
join RegulatorStream[isOn == false]#window.length(1) as R
on T.roomNo == R.roomNo
select T.roomNo, R.deviceID, ‘start’ as action
insert into RegulatorActionStream ;
In CEP (Siddhi)](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-49-320.jpg)


![Missing Event in CEP
In CEP (Siddhi)
from RequestStream#window.time(1h)
insert expired events into ExpiryStream
from r1=RequestStream->r2=Response[id=r1.id] or
r3=ExpiryStream[id=r1.id]
select r1.id as id ...
insert into AlertStream having having r2.id == null;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-52-320.jpg)

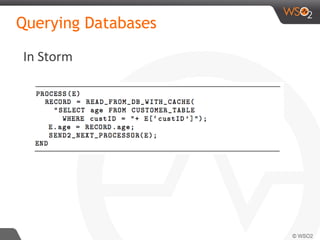






![In CEP (Siddhi)
Pattern
define stream Purchase (price double, cardNo long,place string);
from every (a1 = Purchase[price < 100] -> a3= ..) ->
a2 = Purchase[price >10000 and a1.cardNo == a2.cardNo]
within 1 day
select a1.cardNo as cardNo, a2.price as price, a2.place as place
insert into PotentialFraud ;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-61-320.jpg)


![Pattern 9: Detecting Trends
o What? tracking something over space and time and
detects given conditions.
o Useful in stock markets, SLA enforcement, auto
scaling, predictive maintenance
o Use Cases?
o Rise, Fall of values and Turn (switch from rise to
a fall)
o Outliers - deviate from the current trend by a
large value
o Complex trends like “Triple Bottom” and “Cup
and Handle” [17].](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-64-320.jpg)
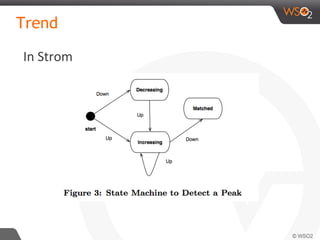
![In CEP (Siddhi)
Sequence
from t1=TempStream,
t2=TempStream [(isNull(t2[last].temp) and t1.temp<temp) or
(t2[last].temp < temp and not(isNull(t2[last].temp))]+
within 5 min
select t1.temp as initialTemp,
t2[last].temp as finalTemp,
t1.deviceID,
t1.roomNo
insert into IncreaingHotRoomsStream ;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-66-320.jpg)
![In CEP (Siddhi)
Partition
partition by (roomNo of TempStream)
begin
from t1=TempStream,
t2=TempStream [(isNull(t2[last].temp) and t1.temp<temp)
or (t2[last].temp < temp and not(isNull(t2[last].temp))]+
within 5 min
select t1.temp as initialTemp,
t2[last].temp as finalTemp,
t1.deviceID,
t1.roomNo
insert into IncreaingHotRoomsStream ;
end;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-67-320.jpg)








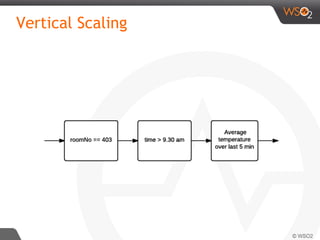
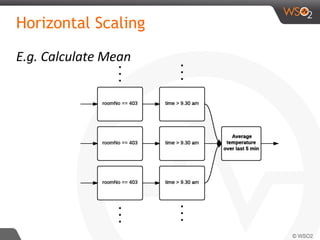
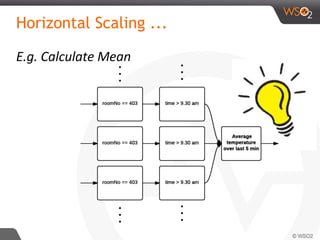
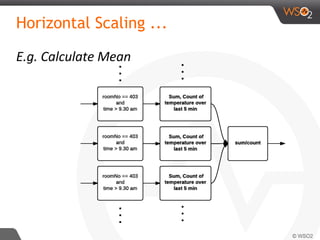






![Siddhi QL
define stream StockStream
(symbol string, volume int, price double);
@name(‘Filter Query’)
from StockStream[price > 75]
select *
insert into HighPriceStockStream ;
@name(‘Window Query’)
from HighPriceStockStream#window.time(10 min)
select symbol, sum(volume) as sumVolume
insert into ResultStockStream ;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-93-320.jpg)
![Siddhi QL - with partition
define stream StockStream
(symbol string, volume int, price double);
@name(‘Filter Query’)
from StockStream[price > 75]
select *
insert into HighPriceStockStream ;
@name(‘Window Query’)
partition with (symbol of HighPriceStockStream)
begin
from HighPriceStockStream#window.time(10 min)
select symbol, sum(volume) as sumVolume
insert into ResultStockStream ;
end;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-94-320.jpg)
![Siddhi QL - distributed
define stream StockStream
(symbol string, volume int, price double);
@name(Filter Query’)
@dist(parallel= ‘3')
from StockStream[price > 75]
select *
insert into HightPriceStockStream ;
@name(‘Window Query’)
@dist(parallel= ‘2')
partition with (symbol of HighPriceStockStream)
begin
from HighPriceStockStream#window.time(10 min)
select symbol, sum(volume) as sumVolume
insert into ResultStockStream ;
end;](https://image.slidesharecdn.com/debs2015tutorial-150629115008-lva1-app6892/85/DEBS-2015-Tutorial-Patterns-for-Realtime-Streaming-Analytics-95-320.jpg)
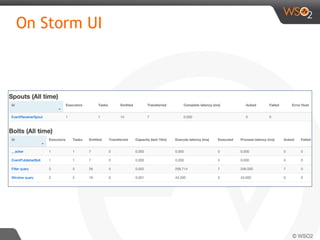








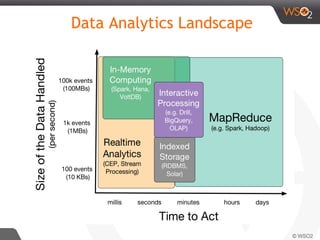
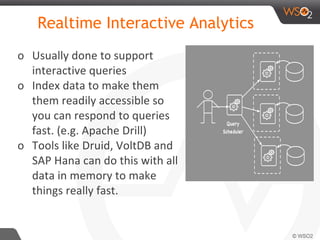
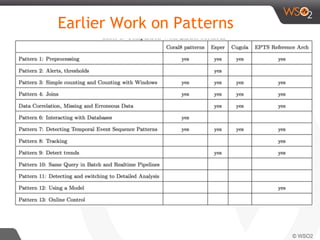
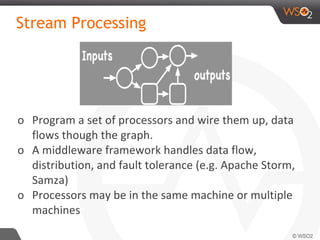
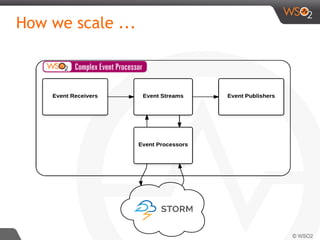
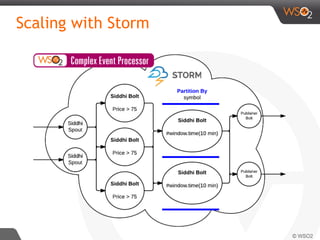
The document discusses real-time streaming analytics patterns and technologies, emphasizing the need for fast data processing in time-sensitive applications like stock markets and surveillance. It outlines various patterns of analytics and tools such as Apache Storm, Spark Streaming, and complex event processing (CEP) for implementing these analytics, including preprocessing, alerts, counting, and trends detection. Furthermore, it highlights the importance of choosing the right framework and the complexities involved in real-time analytics while providing examples of typical use cases.




















































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)







![[WSO2Con USA 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018theriseofstreamingsql-180717041454-thumbnail.jpg?width=640&height=640&fit=bounds)

























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







