Downloaded 254 times





















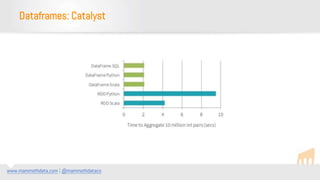








Apache Spark is a fast, general-purpose engine for large-scale data processing, providing support for various programming languages and frameworks. It enables high-performance analytics, machine learning, and data transformation through resilient distributed datasets (RDDs) and dataframes. Spark is suitable for both batch and streaming data, making it a robust tool for modern data applications.









































![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)










































