This document discusses ARIMA (autoregressive integrated moving average) models for time series forecasting. It covers the basic steps for identifying and fitting ARIMA models, including plotting the data, identifying possible AR or MA components using the autocorrelation function (ACF) and partial autocorrelation function (PACF), estimating model parameters, checking the residuals to validate the model fit, and choosing the best model. An example analyzes quarterly US GNP data to demonstrate these steps.
![ARIMA Models [tSeriesR.2010.Ch3.Lab-3]
Theodore Grammatikopoulos∗
Tue 6th
Jan, 2015
Abstract
In previous articles 1 and 2, we introduced autocorrelation and cross-correlation func-
tions (ACFs and CCFs) as mathematical tools to investigate relations that may occur
within and between time series at various lags. We explained how to build linear mod-
els based on classical regression theory for exploiting the associations indicated by
the ACF or CCF. Here, we discuss time domain methods which are appropriate when
we are dealing with possibly non-stationary, shorter time series. These data series are
the rule rather than the exception in many applications, and the methods examined
here are the necessary ingredient of a successful forecasting.
Classical regression is often insufficient for explaining all of the interesting dy-
namics of a time series. For example, the ACF of the residuals of the simple linear
regression fit to the global temperature data (gtemp) reveals additional structure in
the data which is not captured by the regression (see Example 2.1 of article 2). Instead,
the correlation as a phenomenon that may be generated through lagged linear rela-
tions leads to proposing the autoregressive (AR) and autoregressive moving average
(ARMA) models. Have to also describe non-stationary processes leads to the autore-
gressive integrated moving average (ARIMA) model [Box and Jenkins, 1970]. Here we
discuss shortly the so-called Box-Jenkins method for identifying a plausible ARIMA
model, and see how it can be actually applied through practical examples. We also
apply techniques for parameter estimation and forecasting for these models.
## OTN License Agreement: Oracle Technology Network -
Developer
## Oracle Distribution of R version 3.0.1 (--) Good Sport
## Copyright (C) The R Foundation for Statistical Computing
## Platform: x86_64-unknown-linux-gnu (64-bit)
D:20150106215920+02’00’
∗
e-mail: tgrammat@gmail.com
1](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-1-2048.jpg)

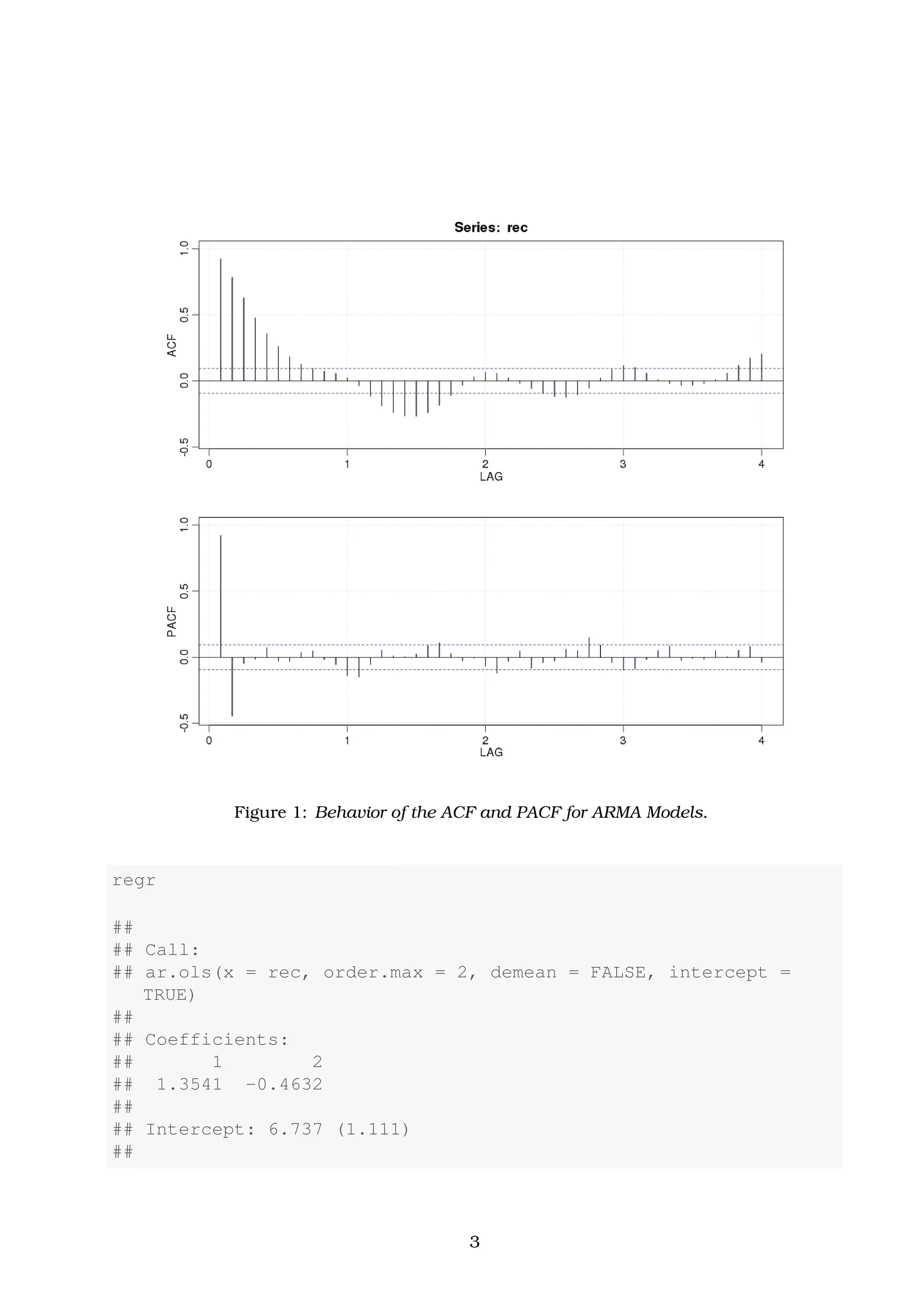
![2 Estimation
Example 2.1. Yule-Walker (YW) Estimation of the Recruitment Series (rec)
Solution. In Example 1.1 we fit an AR(2) model to the recruitment series using regression.
Here, we calculate the coefficients of the same model using Yule-Walker estimation in R.
The coefficients of the estimated model are nearly identical with the ones found in Example
1.1.
# YW Estimation of an AR(2) - rec series
rec.yw <- ar.yw(rec, order = 2)
rec.yw$x.mean # = 62.26278 (mean estimate)
## [1] 62.26278
rec.yw$ar # = 1.3315874, -.4445447 (AR parameter estimates)
## [1] 1.3315874 -0.4445447
sqrt(diag(rec.yw$asy.var.coef)) # = .04222637, .04222637 (
standard errors)
## [1] 0.04222637 0.04222637
rec.yw$var.pred # = 94.79912 (error variance estimate)
## [1] 94.79912
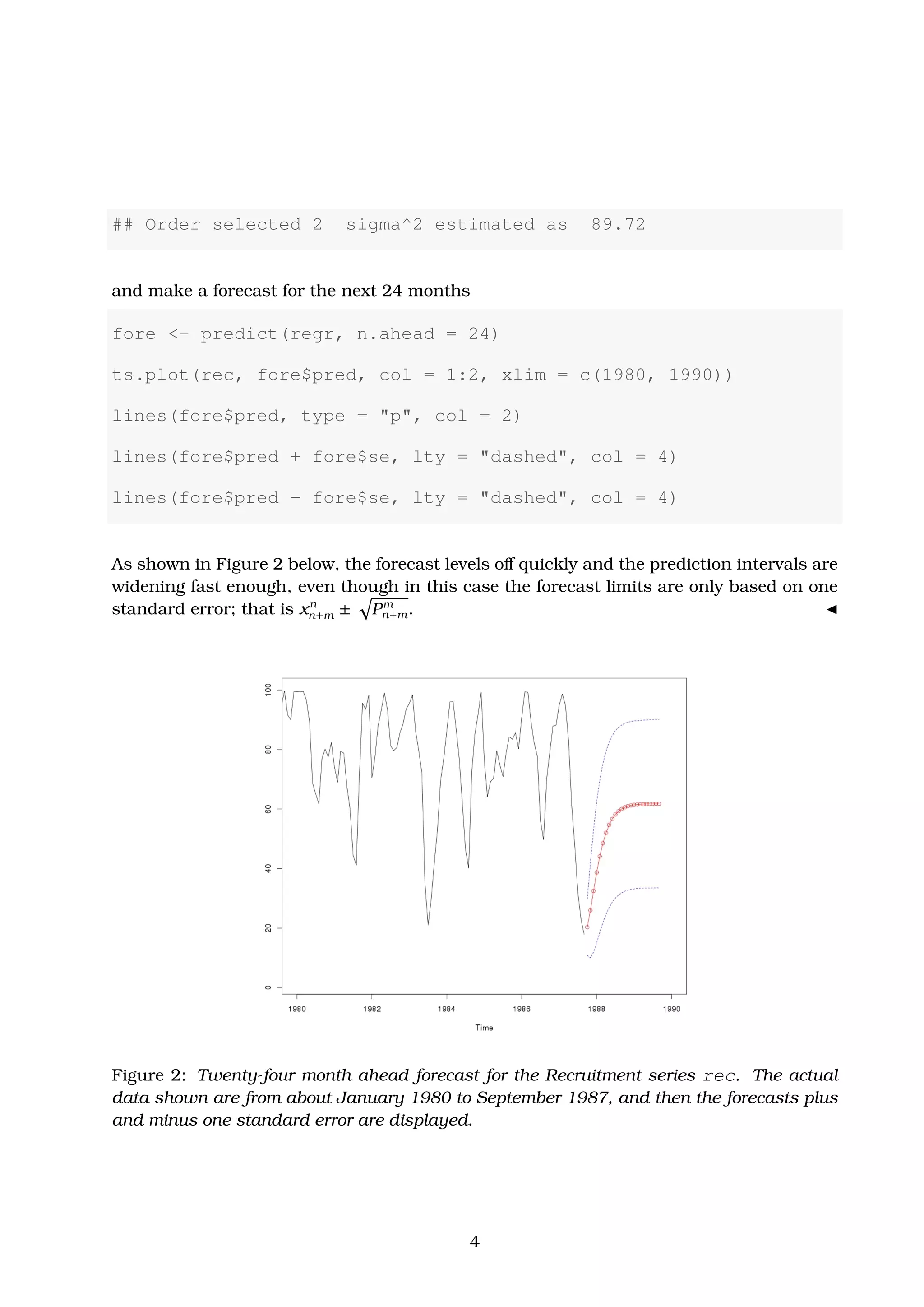
# 24-month ahead Forecast
rec.pr <- predict(rec.yw, n.ahead = 24)
U <- rec.pr$pred + rec.pr$se
L <- rec.pr$pred - rec.pr$se
minx <- min(rec, L)
maxx <- max(rec, U)
dev.new()
opar <- par(no.readonly = TRUE)
5](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-5-2048.jpg)
![par(opar)
ts.plot(rec, rec.pr$pred, xlim = c(1980, 1990), ylim = c(minx,
maxx), ylab = "rec", main = "24-month ahead forecast of
Recruitment Seriesn[rec, Yule-Walker (red,blue), MLE(
green)]")
lines(rec.pr$pred, col = "red", type = "o")
lines(U, col = "blue", lty = "dashed")
lines(L, col = "blue", lty = "dashed")
Figure 3: Twenty-four month ahead forecast for the Recruitment series rec. The actual
data shown are from about January 1980 to September 1987, and then the forecasts plus
and minus one standard error are displayed. The plot has been produced by fitting an
AR(2) process using first Yule-Walker estimation (red curve with blue upper and lower
bounds) and MLE (green curves) afterwards.
6](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-6-2048.jpg)


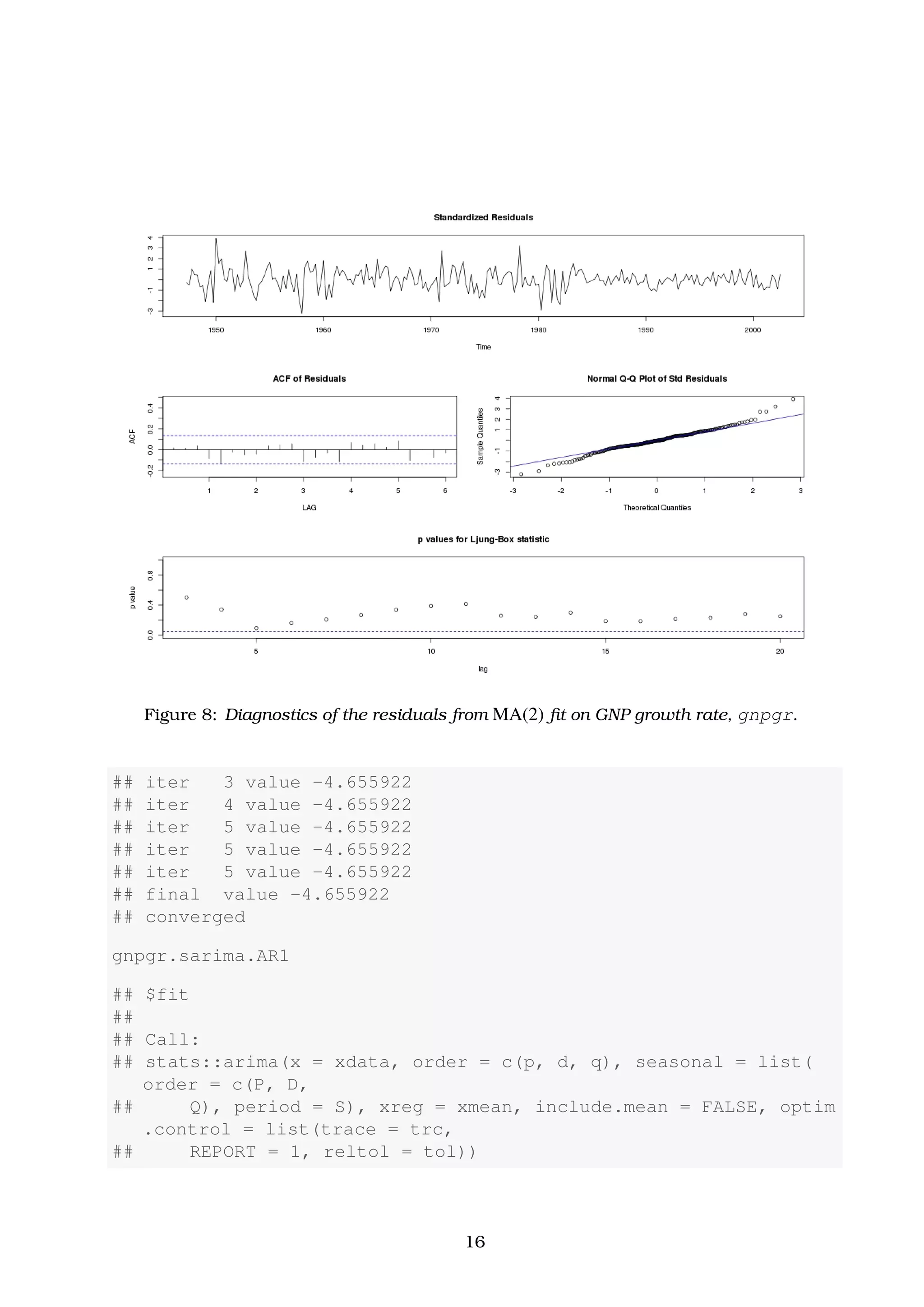
![5. Model diagnostics. This step includes the analysis of the residuals as well as model
comparisons.
ˆ First, we produce a time plot of the innovations (or residuals), xt − xt
t−1
, or of
the standardized innovations
et = (xt − xt
t−1
)/ (Pt
t−1
) . (2)
Here, xt
t−1
is the one-step-ahead prediction of xt (based on the fitted model) and
Pt
t−1
is the estimated one-step-ahead error variance. If the model provides a good
fit to the observational data, the standardized residuals, et, should behave as
et ∼ N(0, 1) . (3)
However, unless the time series is Gaussian, it is not enough that the residuals
are uncorrelated. For example, it is possible in the non-Gaussian case to have
an uncorrelated process for which values contiguous in time are highly depen-
dent. An important class of such models are the so-called, GARCH models.
ˆ In case that a time plot of residuals appears marginal normality a histogram
of the residuals may be extremely helpful. In addition to this, a normal prob-
ability plot or a Q-Q plot can help in identifying departures from normality.
For details of this test as well as additional tests for multivariate normality
consult [Johnson and Wichern, 2013].
ˆ Another test to search for possible departure from normality is to inspect the
sample autocorrelations of the residuals, ρe(h), for any patterns or large values.
Recall that, for a white noise sequence
ρe(h) ∼ iid N(0, 1/n) . (4)
Divergences from this expected result and beyond its expected error bounds,
±2/
√
n, suggest that the fitted model can be improved. For details consult [Box
and Pierce, 1970] and [McLeod, 1978].
ˆ A more general test takes into consideration the magnitudes of ρe(h) as a group.
For example, it may be the case that, individually, each ρe(h) is slightly less
in magnitude than the expected error bounds, 2/
√
n, but the ρe(h) as a whole
follows collectively a different statistic than the one expected by an iid N(0, 1/n)
distribution. More specifically, the statistic of interest to perform this test is
Ljung-Box-Pierce
Statistic
: Q = n(n + 2)
H
h=1
ρe
2
(h)
n − h
n→∞
−−−−→ XH−p−q . (5)
The value H in eq. (5) above is chosen somewhat arbitrarily, typically, H = 20.
Then, under the null hypothesis of model adequacy, Q
n→∞
−−−−→ XH−p−q. Thus, we
9](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-9-2048.jpg)
![would reject the null hypothesis at level α if the value of Q exceeds the (1 − α)
quantile of X2
H−p−q distribution. For details consult [Box and Pierce, 1970],
[Ljung and Box, 1978] and [Davies et al., 1977]. The basic idea is that providing
wt describes white noise, the n ρw
2
(h), for h = 1, . . . , H, are asymptotically
independent χ2
1 random variables, which in turn means n H
h=1 ρw
2
(h) ∼ X2
H .
The loss of p + q degrees of freedom in eq. (5) is because the test involves ACF
of residuals from ARMA(p, q) model fit.
6. Model choice. In this final step of model fitting we must decide which model we will
retain for forecasting. The most popular criteria to do so are AIC, AICc and BIC.
Example 3.1. Analysis of GNP Data. Here, we consider the analysis of quarterly U.S. GNP
from 1947 to 2002, gnp, having n = 223 observations. The data are real U.S. gross national
product in billions of dollars and have been seasonally adjusted. The data were obtained
from the Federal Reserve Bank of St. Louis (http://research.stlouisfed.org) and
they are provided by the astsa package of [Shumway and Stoffer, 2013]. We are going to
make a preliminary exploratory data analysis, determine if we need to transform our data
and make a preliminary claim of possible ARIMA(p, d, q) models to fit. We will estimate
the model parameters and make a first conclusion on the performance of the produced fits.
Finally, we decide which model we will retain for forecasting and make an actual forecast.
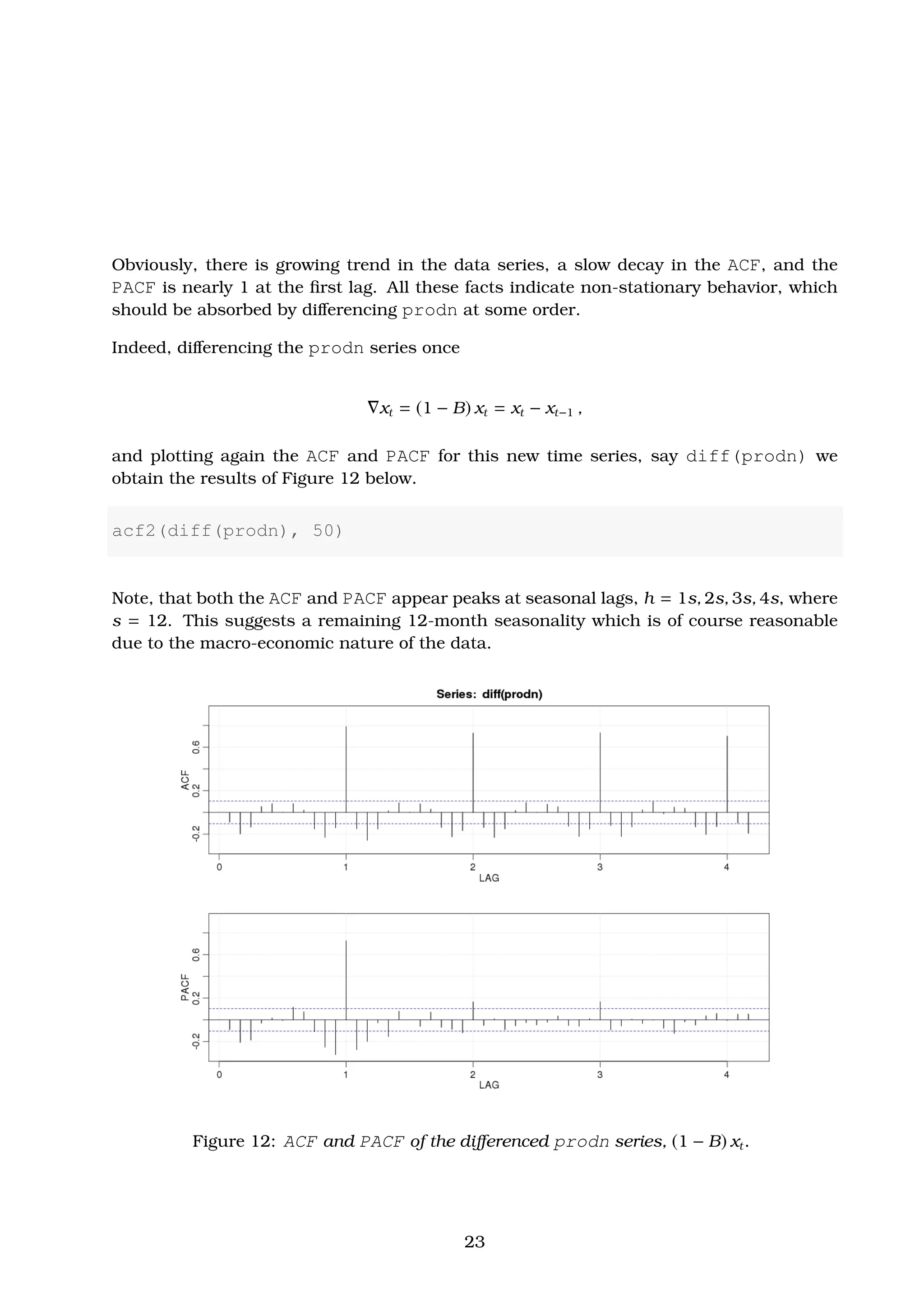
Solution. To have a first idea of the gnp data series, yt, we produce a time plot of the data
alongside with its sample ACF. As shown in Figure 4, the gnp time series appears a strong
trend of growing GNP with time, and it is not clear that the variance is also increasing.
The sample ACF, on the other hand, decay slowly with growing lag, h, indicating that we
should differ the time series first.
par(opar)
par(mfrow = c(2, 1), mar = c(3, 4.1, 4.1, 3), oma = c(0, 0, 3,
0))
plot(gnp, xlab = "Time", ylab = "gnp")
acf(gnp, 50, xlab = "Lag", ylab = "ACF") # Maximum 50 Lags
title(main = "Quarterly U.S. GNP (gnp)", outer = TRUE)
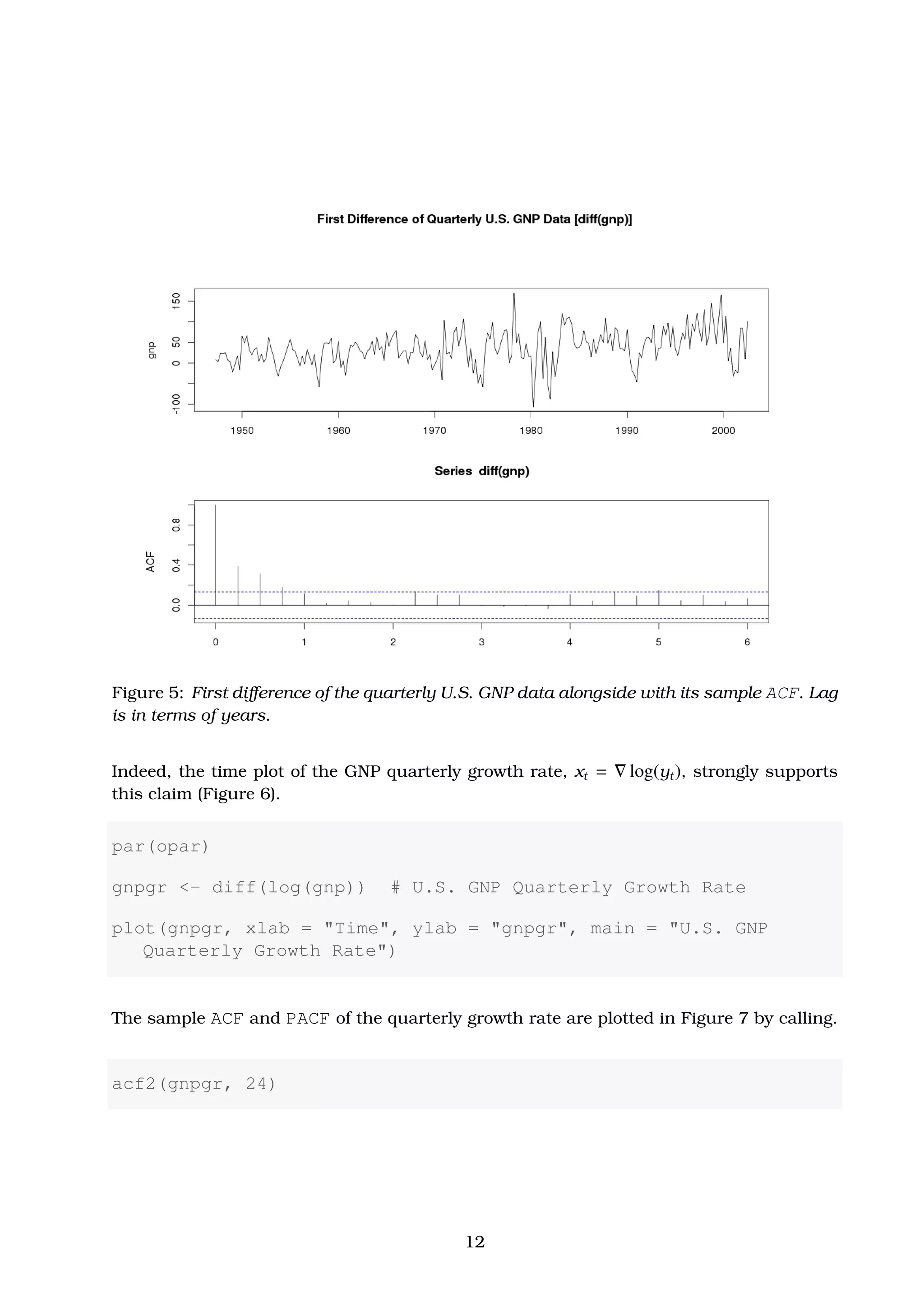
Differencing the gnp time series once and re-plotting this new data series diff(gnp), we
observe in Figure 5 that the strong growing trend has been removed and a larger variability
in the second half of the time plot has been revealed. This suggests that an additional
log-transform of the gnp data may result in a more stable process.
10](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-10-2048.jpg)
![par(opar)
par(mfrow = c(2, 1), mar = c(3, 4.1, 4.1, 3), oma = c(0, 0, 3,
0))
plot(diff(gnp), xlab = "Time", ylab = "gnp")
acf(diff(gnp), 24, xlab = "Lag", ylab = "ACF") # Maximum 50 Lags
title(main = "First Difference of Quarterly U.S. GNP Data [diff(
gnp)]",
outer = TRUE)
Figure 4: Quarterly U.S. GNP from 1947 to 2002 alongside with its sample ACF. Lag is in
terms of years.
11](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-11-2048.jpg)

![##
## sigma^2 estimated as 8.919e-05: log likelihood = 719.96, aic
= -1431.93
##
## $AIC
## [1] -8.297695
##
## $AICc
## [1] -8.287855
##
## $BIC
## [1] -9.251712
That is using MLE to fit the MA(2) model for the growth rate, xt, the estimated model is
found to be
xt = 0.0083(0.0010) + 0.3028(0.0654)wt−1 + 0.2035(0.0644)wt−2 + wt , (6)
where σw = 8.919 × 10−05
. The values in parentheses are the corresponding estimated
errors. Note, that all of the regression coefficients are significant, including the constant∗
.
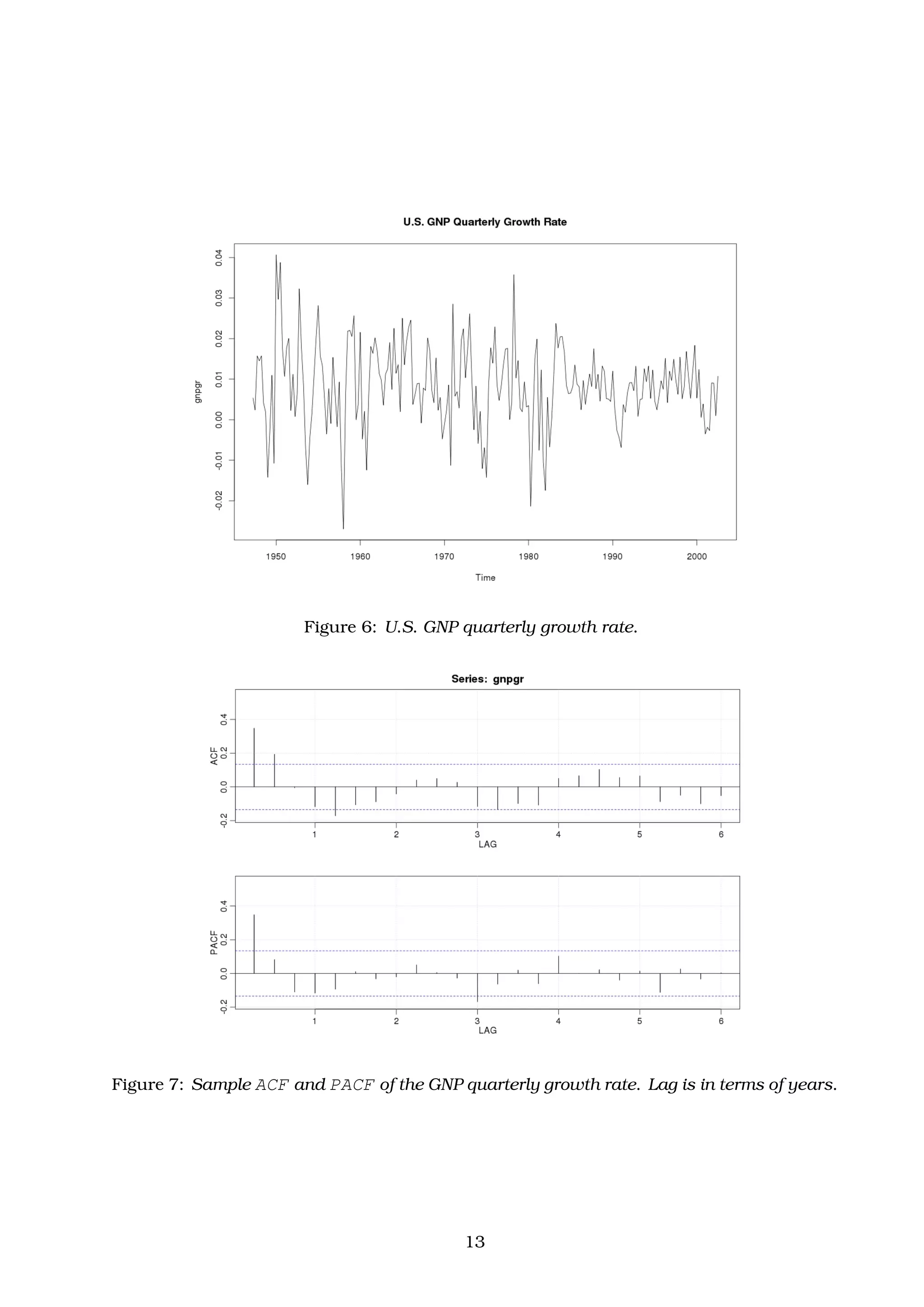
In this example, not including a constant assumes the average quarterly growth rate is
zero, whereas in fact the average quarterly growth rate is about 1% (Figure 6).
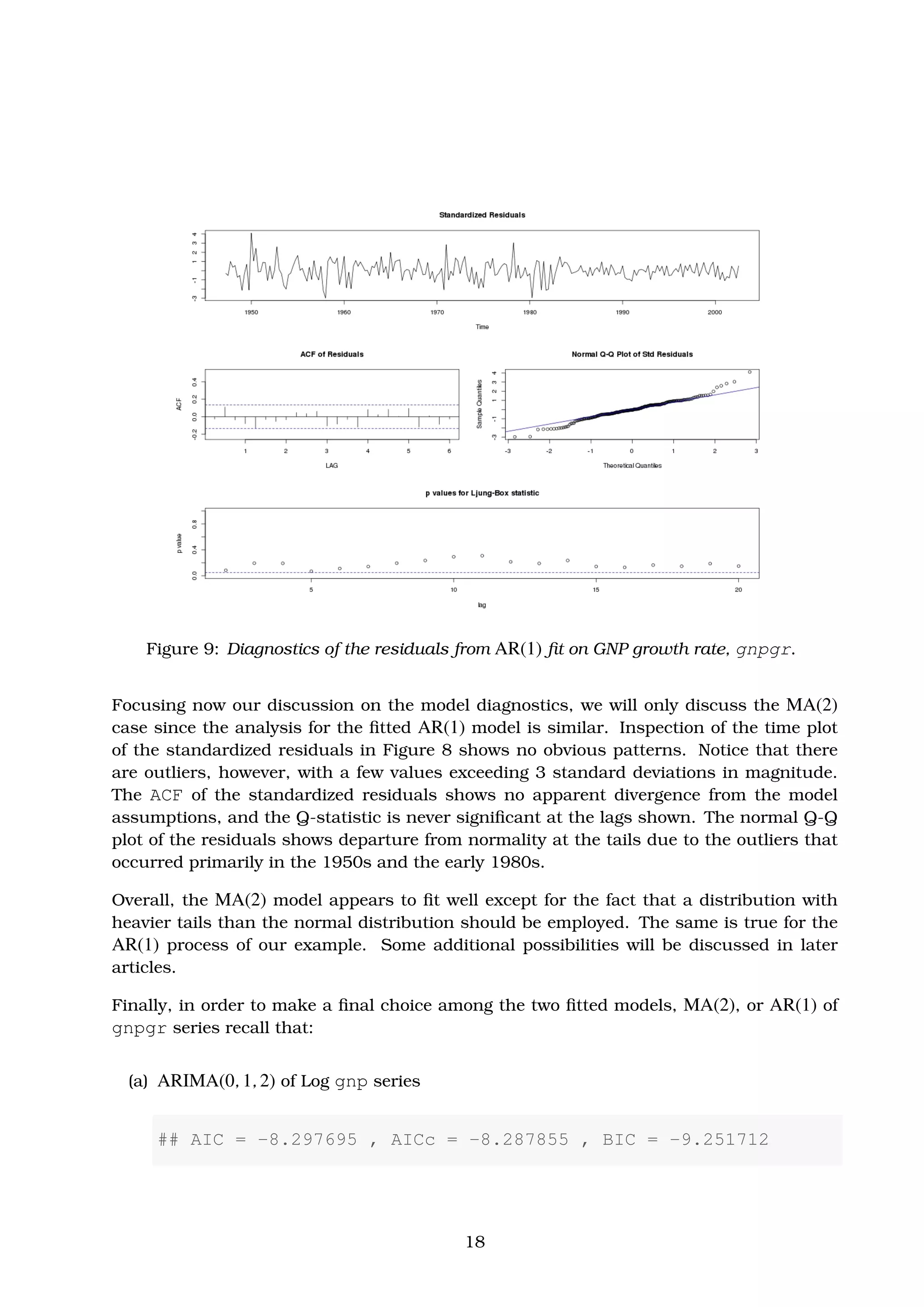
The estimated AR(1) model, on the other hand, is calculated as follows.
gnpgr.sarima.AR1 <- sarima(gnpgr, 1, 0, 0) # AR(1) of gnpgr
## initial value -4.589567
## iter 2 value -4.654150
## iter 3 value -4.654150
## iter 4 value -4.654151
## iter 4 value -4.654151
## iter 4 value -4.654151
## final value -4.654151
## converged
## initial value -4.655919
## iter 2 value -4.655921
∗
Some software packages do not fit a constant in a differenced model.
15](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-15-2048.jpg)
![##
## Coefficients:
## ar1 xmean
## 0.3467 0.0083
## s.e. 0.0627 0.0010
##
## sigma^2 estimated as 9.03e-05: log likelihood = 718.61, aic
= -1431.22
##
## $AIC
## [1] -8.294403
##
## $AICc
## [1] -8.284898
##
## $BIC
## [1] -9.263748
Thus, the AR(1) model for the growth rate, xt, is found to be
xt = 0.0083(0.0010)(1 − 0.3467) + 0.3467(0.0627)xt−1 + wt , (7)
where σw = 9.03 × 10−05
and the intercept now is 0.0083(1 − 0.3467) ≈ 0.005.
Before we discuss the produced diagnostics of these two models, we can make a first
comparison among them. They are nearly the same. This is because the fitted AR(1)
model is similar to the MA(2) one, providing that it is written in its causal form.
ARMAtoMA(ar = 0.3467, ma = 0, 10)
## [1] 3.467000e-01 1.202009e-01 4.167365e-02 1.444825e-02
## [5] 5.009210e-03 1.736693e-03 6.021115e-04 2.087520e-04
## [9] 7.237433e-05 2.509218e-05
That is the fitted AR(1) model in its causal form can be approximated by the MA(2) model
xt ≈ 0.35wt−1 + 0.12wt−2 + wt .
This process is indeed similar with the fitted MA(2) model of eq. (6).
17](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-17-2048.jpg)


![where wt is a Gaussian white noise process, i.e. wt ∼ iid N(0, 1). This general model is
denoted as ARIMA(p, d, q) × (P, D, Q)s.
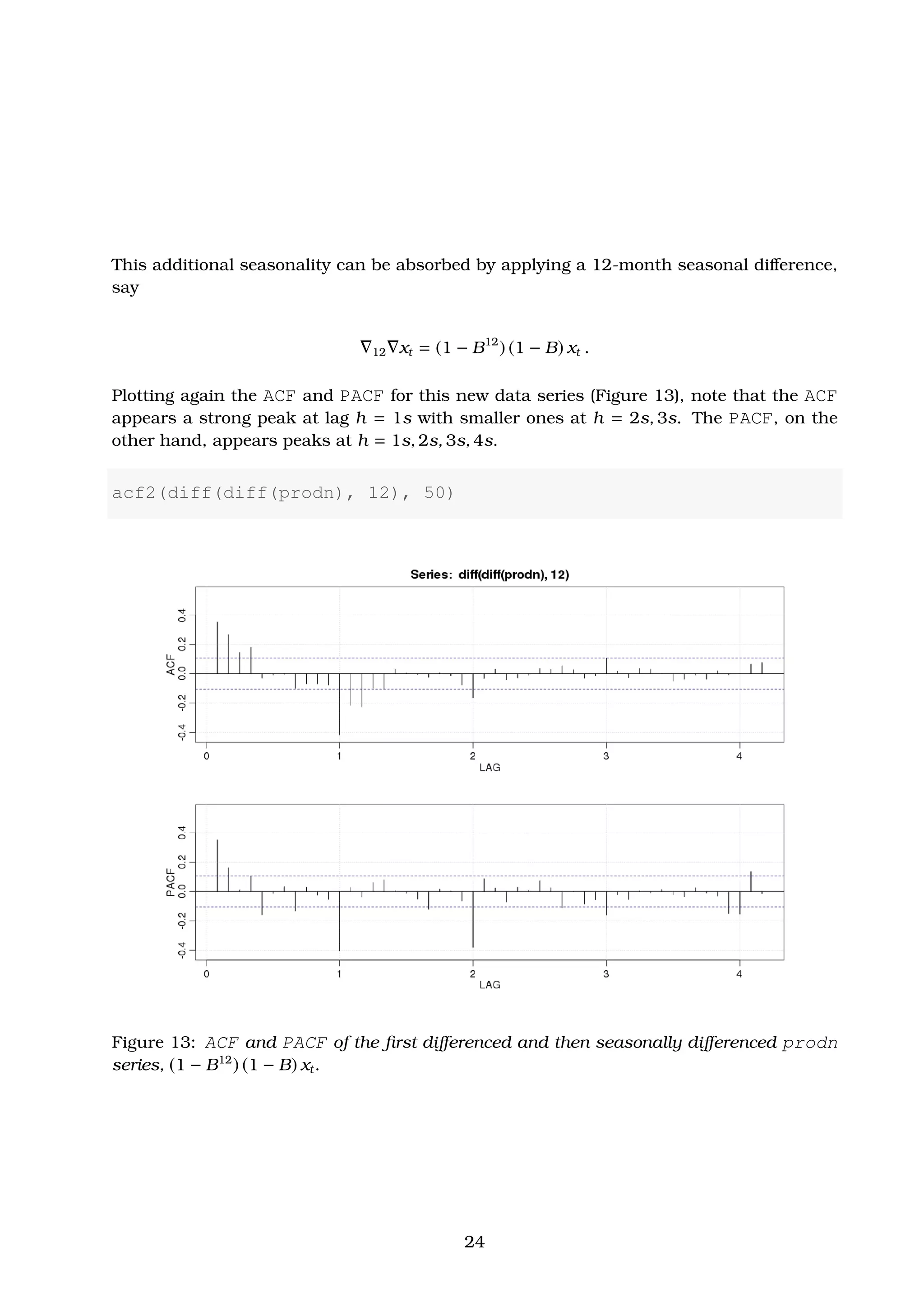
Building SARIMA Models
Selecting the appropriate SARIMA model for a given set of data is not an easy task, but a
rough description of how doing so is the following:
1. We determine the difference (seasonal or ordinary) operators (if any) that produce a
roughly stationary series.
2. We evaluate the ACF and PACF functions of the remaining stationary data series
and using the general properties of Tables 1 and 2, we determine a preliminary set
of ARMA/SARMA models to test.
3. Given this preliminary set of ARIMA(p, d, q) × (P, D, Q)s models we proceed with their
parameter estimation. To do so we use either (a) the method of Yule-Walker Esti-
mation (YW) or (b) the method of Maximum Likelihood and Least Square Estimation
(MLE), which is more precise for large data samples.
4. Then, by using the same criteria mentioned in Section 3 (see “Model diagnostics”),
we can judge whether these models are satisfactory enough to further consider.
5. Finally, we decide which model will retain for forecasting based on their AIC, AICc
and/or BIC statistics.
Example 4.1. The Federal Reserve Board Production Index. Given the monthly time
series of “Federal Reserve Board Production Index”, prodn, which is provided by the astsa
package of [Shumway and Stoffer, 2013] and includes the monthly values of the index for
the period 1948-1978, we now fit a preliminary set of SARIMA models and finally select the
best one to make a forecast for the next 12 months.
Solution. First we provide a time plot of the prodn time series (Figure 10). In Figure 11
we also plot the ACF and PACF functions for this time series.
par(opar)
plot(prodn, main = "Monthly Federal Reserve Board Production
Indexn[prodn{astsa}, 1948-1978]")
par(opar)
acf2(prodn, 50)
21](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-21-2048.jpg)
![Figure 10: Monthly values of the “Federal Reserve Board Production Index”, [prodn, 1948 -
1978]
Figure 11: ACF and PACF of the prodn series.
22](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-22-2048.jpg)

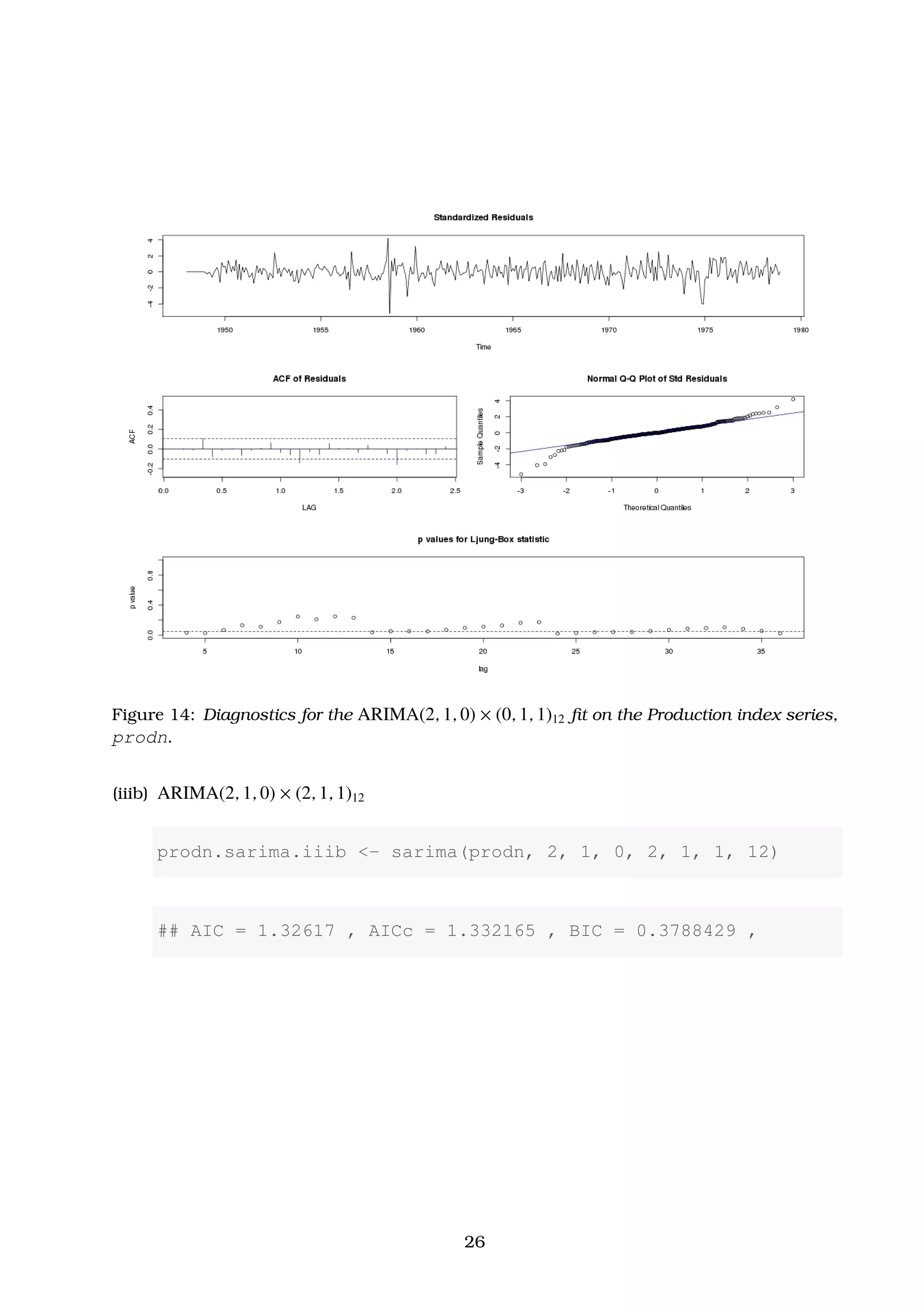
![Figure 16: Diagnostics for the ARIMA(2, 1, 0) × (2, 1, 1)12 fit on the Production index series,
prodn.
## ar1 ar2 sma1 sma2 sma3
## 0.3038 0.1077 -0.7393 -0.1445 0.2815
## s.e. 0.0526 0.0538 0.0539 0.0653 0.0526
##
## sigma^2 estimated as 1.312: log likelihood = -563.98, aic =
1139.97
##
## $AIC
## [1] 1.298543
##
## $AICc
## [1] 1.304538
##
## $BIC
## [1] 0.3512166
28](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-28-2048.jpg)
![or in operator form
1 − 0.3038(0.0526) B − 0.1077(0.0538) B2
12 xt =
= 1 − 0.7393(0.0539) B12
− 0.1445(0.0653) B24
+ 0.2815(0.0526) B36
wt ,
with σ2
w = 1.312.
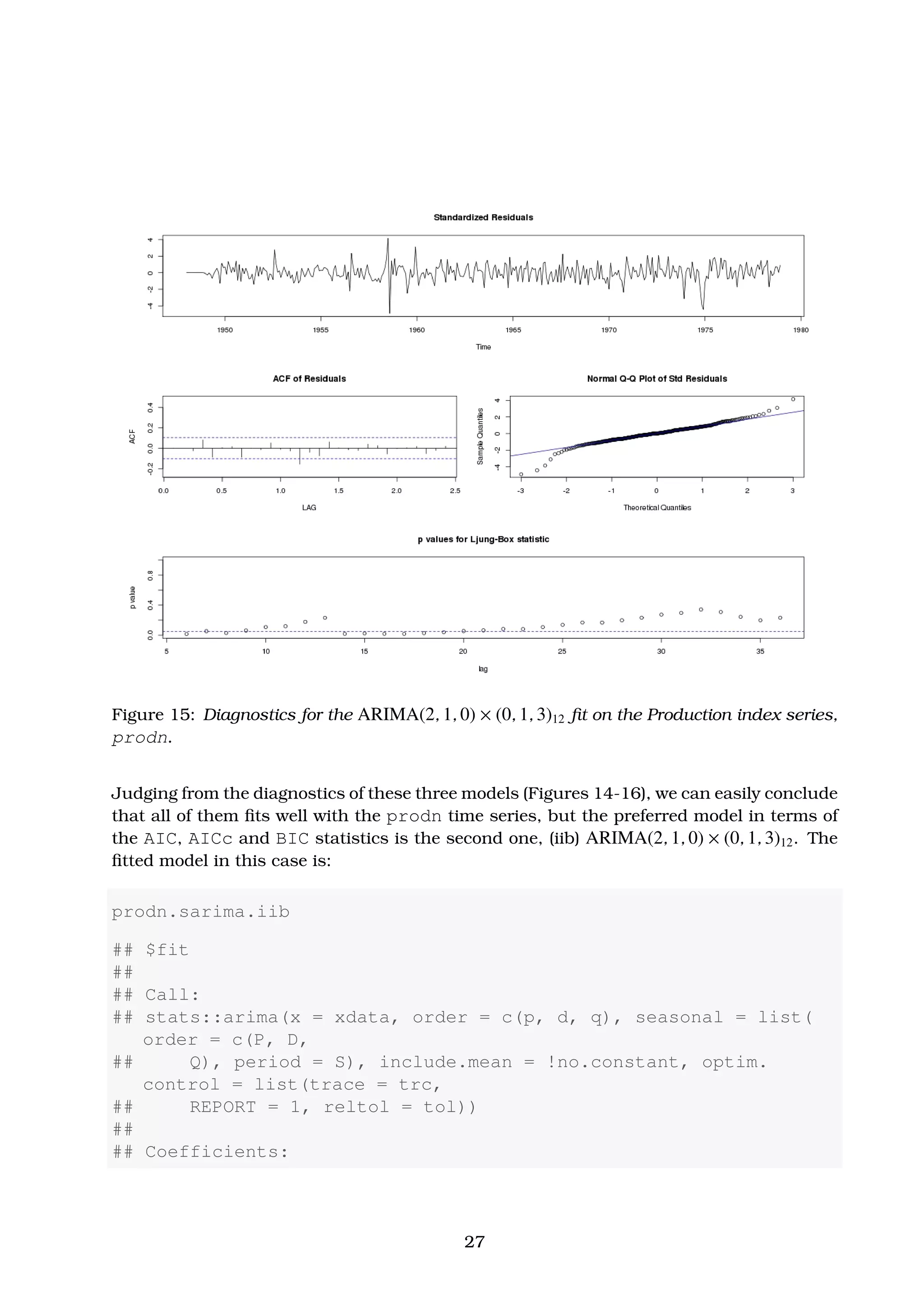
Finally, we actually make forecasts for the next 12 months using this fitted model, i.e.
(iib) ARIMA(2, 1, 0) × (0, 1, 3)12. These are shown in Figure 17 below.
prodn.sarima.iib.fore <- sarima.for(prodn, 12, 2, 1, 0, 0, 1,
3, 12) # 12-month forecast
title(main = "Federal Reserve Board Production IndexnForecasts
and Error Bound Limits [prodn{astsa}, 1948-1978]",
outer = FALSE)
Figure 17: Forecasts and error bounds for the “Federal Reserve Board Production Index”,
prodn series, based on ARIMA(2, 1, 0) × (0, 1, 3)12 fitted model [case (iib)].
29](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-29-2048.jpg)
![References
[Box and Pierce, 1970] Box, G. and Pierce, D. (1970). Distributions of residual auto-
correlations in autoregressive integrated moving average models. J. Am. Stat. Assoc.,
72:397–402.
[Box and Jenkins, 1970] Box, G. E. P. and Jenkins, G. M. (1970). Time Series Analysis
Forecasting and Control. Holden-Day, San Francisco.
[Davies et al., 1977] Davies, N., Triggs, C., and Newbold, P. (1977). Significance levels of
the box-pierce portmanteau statistic in finite samples. Biometrica, 64:517–522.
[Johnson and Wichern, 2013] Johnson, R. A. and Wichern, D. W. (2013). Applied Multi-
variate Statistical Analysis. Pearson, 6th ed. 2013 edition.
[Ljung and Box, 1978] Ljung, L. and Box, G. E. P. (1978). On a measure of lack of fit in a
time series. Biometrica, 65:297–303.
[McLeod, 1978] McLeod, A. (1978). On the distribution of residual autocorrelations in
box-jenkins models. J. R. Stat. Soc., B(40):296–302.
[Shumway and Stoffer, 2013] Shumway, R. H. and Stoffer, D. S. (2013). Time Series Anal-
ysis and Its Applications: With R Examples (Springer Texts in Statistics). Springer,
softcover reprint of hardcover 3rd ed. 2011 edition.
30](https://image.slidesharecdn.com/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01/75/ARIMA-Models-Lab-3-30-2048.jpg)




























































![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


