












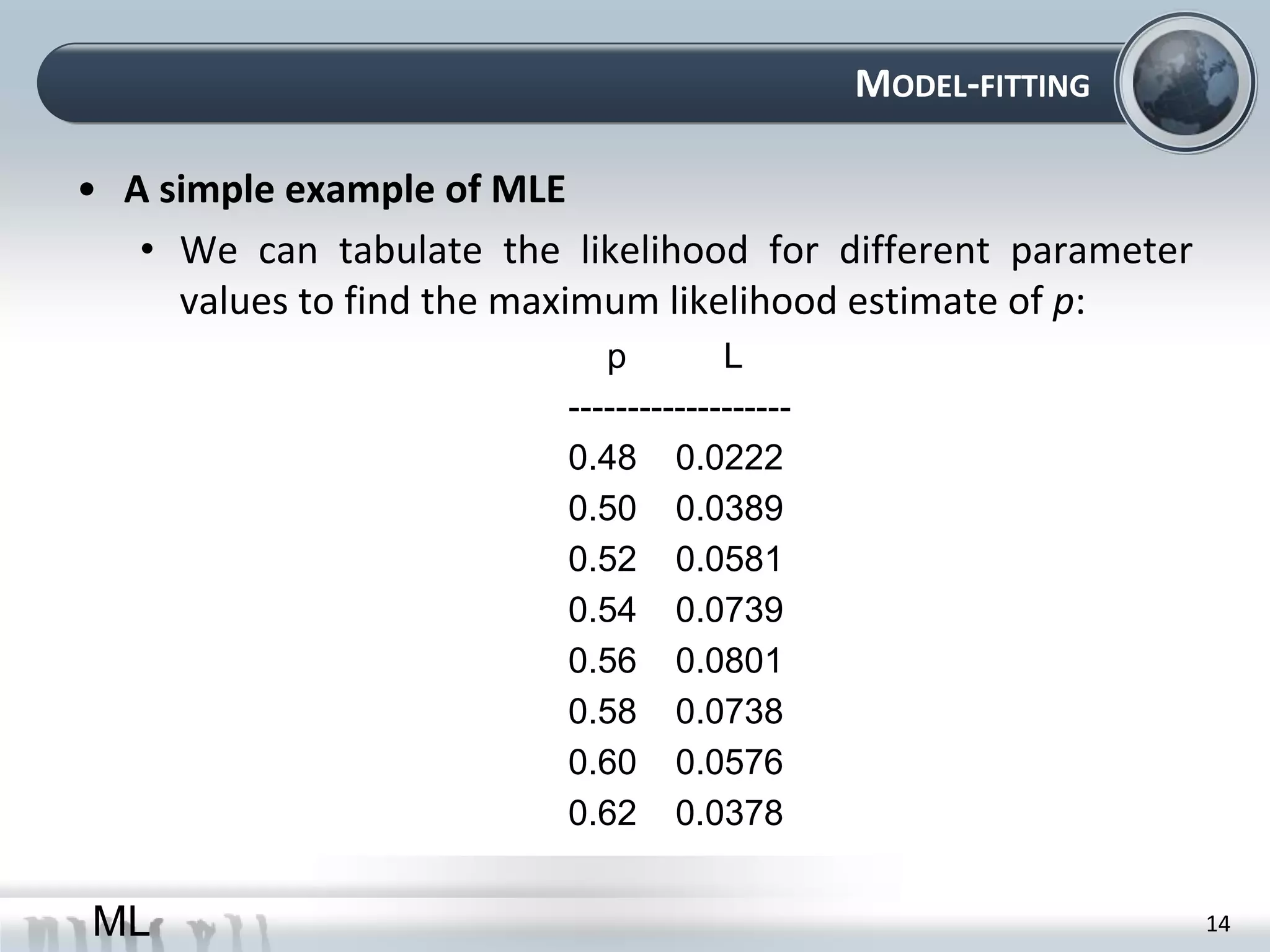
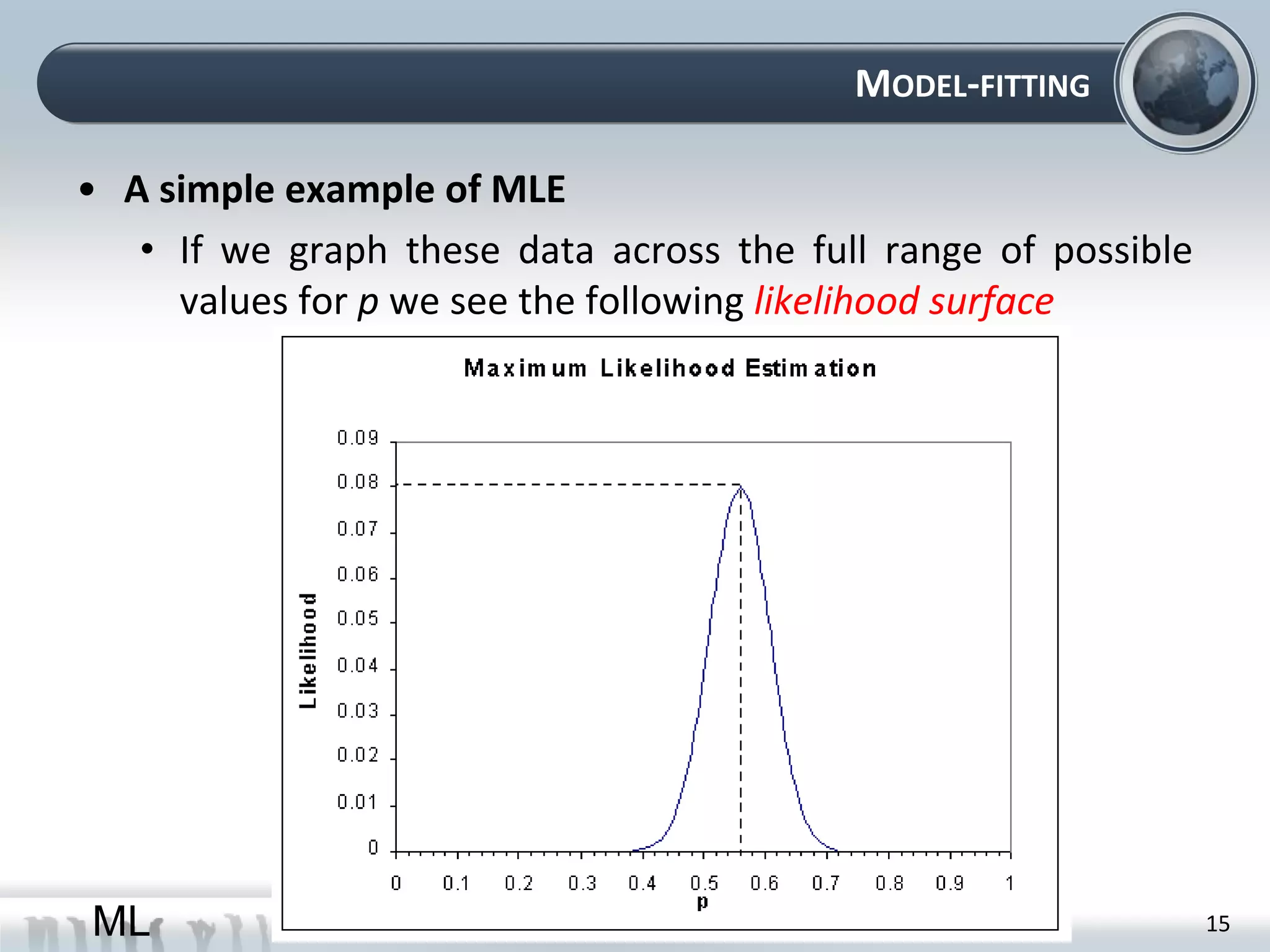







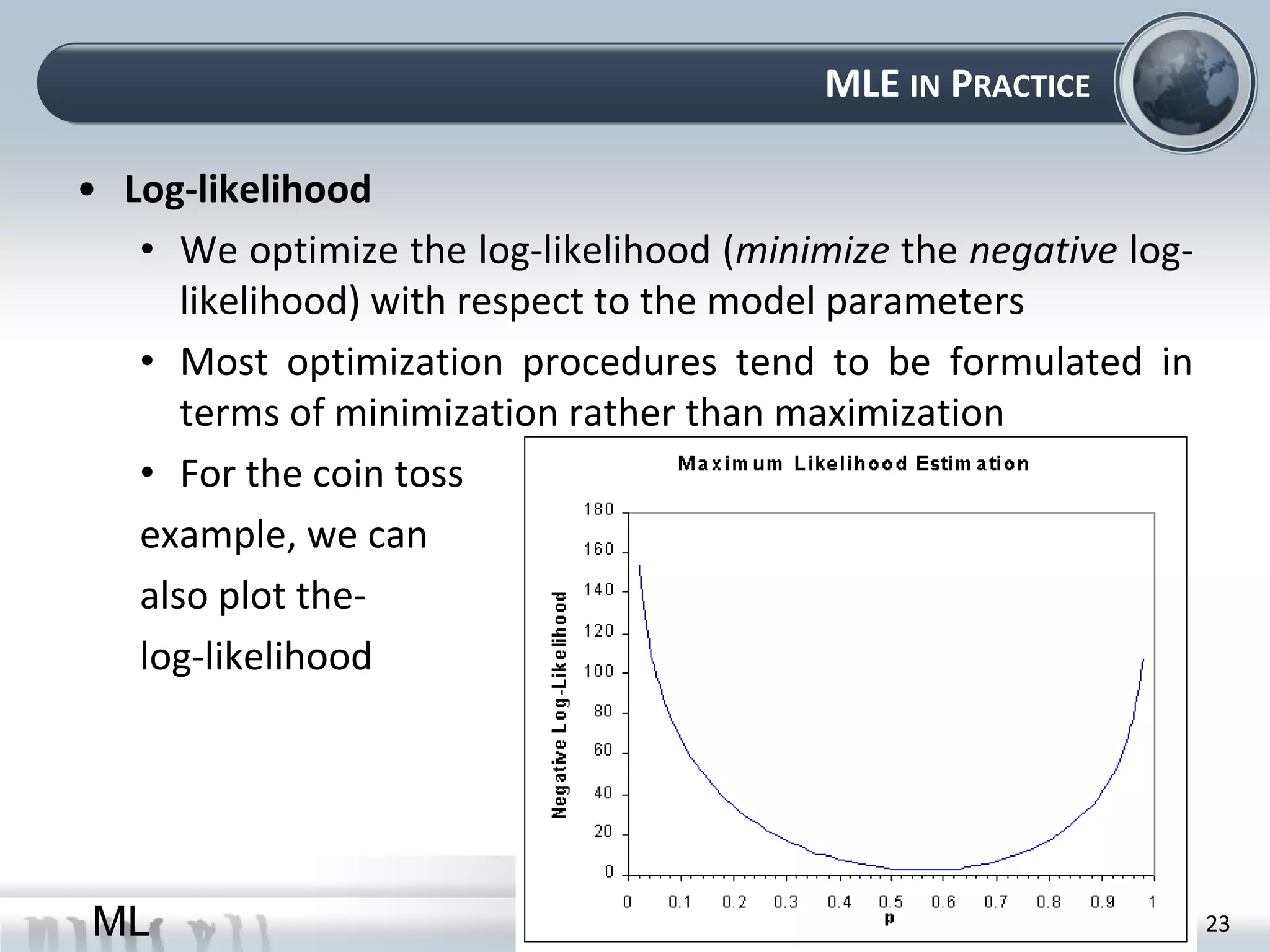

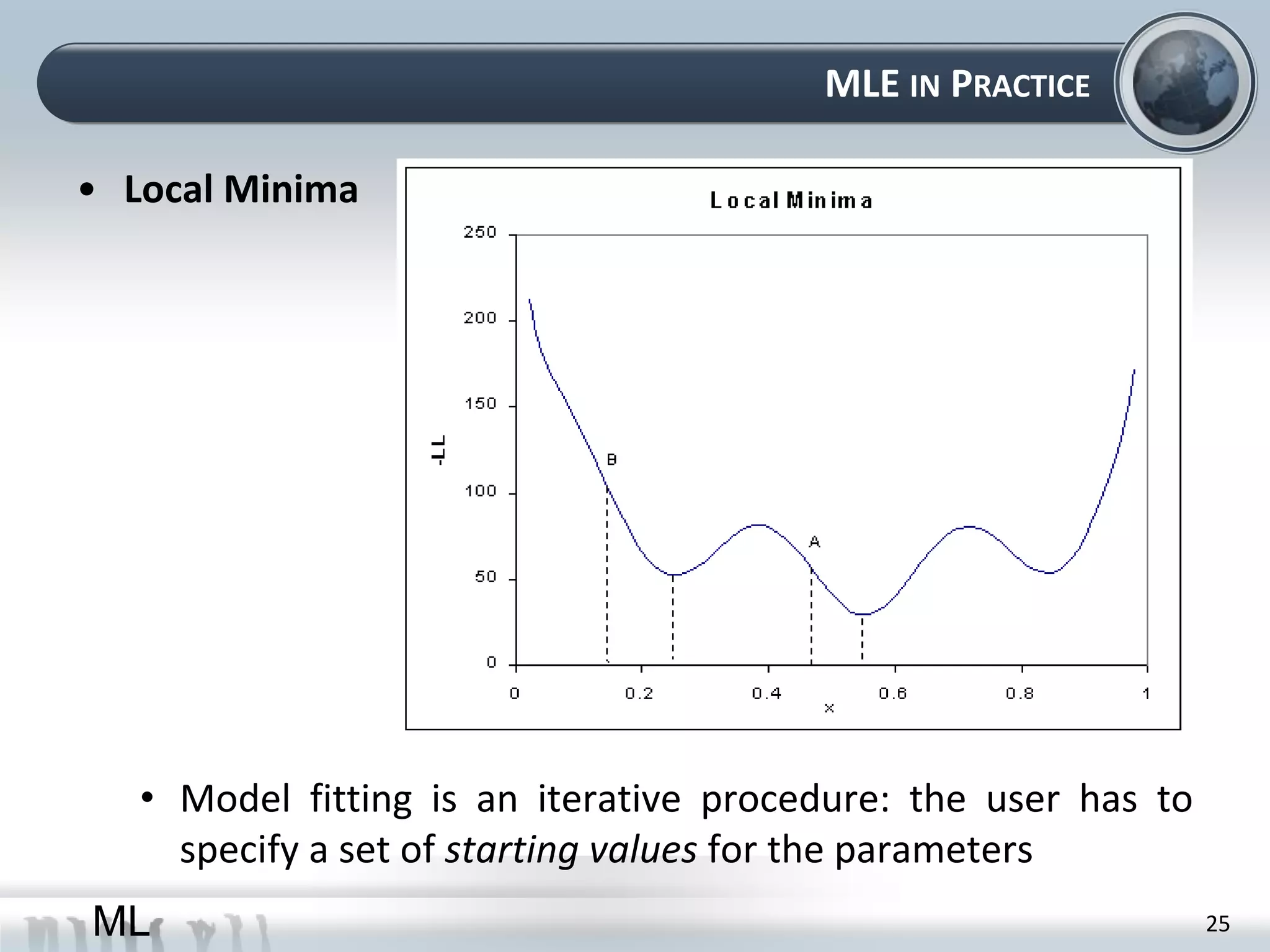





This document provides an overview of maximum likelihood estimation (MLE). It discusses key concepts like probability models, parameters, and the likelihood function. MLE aims to find the parameter values that make the observed data most likely. This can be done analytically by taking derivatives or numerically using optimization algorithms. Practical considerations like removing constants and using the log-likelihood are also covered. The document concludes by introducing the likelihood ratio test for comparing nested models.















































