This document discusses using the Box-Jenkins methodology to forecast unemployment rates in the US from January 2007 to July 2007 using past data from January 1948 to December 2006. It first provides an overview of the Box-Jenkins methodology and its key steps: identification, estimation, diagnostics, and forecasting. It then applies these steps using R: identifying an ARIMA(1,1) model as best fitting the deseasonalized data based on minimizing the AIC, estimating the parameters of this model, and selecting ARIMA(1,1) to forecast future unemployment rates.





![<Practical time series analysis using R program>
From now, we start analyze the data, using U.S monthly unemployment rate from January
1948 to July 2007. This data is from the Federal Reserve Bank of St. Louis.
<http://www.ams.sunysb.edu/˜xing/statfinbook/ BookData/Chap05/m us unem.txt> We will
analyze the data with the statistic program R.
Code:
>series<-read.table("m_us_unem.txt",skip=1,header=T)
>series
>unem<-ts(series[1:708,2], freq=12, start=c(1948, 1))
>unem
>ts.plot(unem)
Figure 1. U.S. monthly unemployment rates from January 1948 to July 2007
As we can see in the Figure 1, this time series data look it is not stationary. We can
see there is seasonal effect which the value fluctuate up and down repeatedly, and the trend
effect by there is no constant mean. In this condition (non-stationary), we cannot use this data
to forecast future value. We need to do differencing process to remove trend effect and
seasonal effect.
Time
unem
1950 1960 1970 1980 1990 2000
46810](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-5-320.jpg)
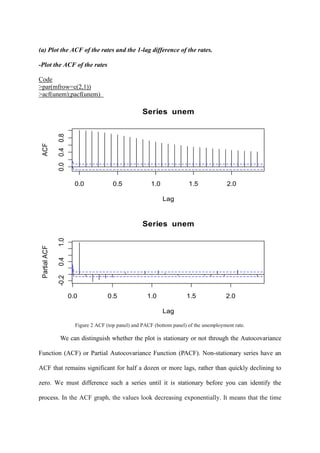
![series is not stationary. We will fix the time series model to the adaptable form in the next
procedure.
.
-Code for The 1-lag difference of the rates
>a<-diff(unem,lag=1)
>ts.plot(a)
>a
Figure 3. 1-lag difference of the rates
Comparing to Figure 1, Figure 3 which is 1-lag difference data looks stationary
which means that the mean of the data is constant, and the variance also looks more stable
than Figure 1. Now, it is acceptable data to use Box Jenkins procedure.
(b)Fit ARMA(1,1) model to the data from January 1948 to Dec. 2006
-Code for Seasonal, Trend, remainder
Unem.stl<-stl(unem, “periodic”)
Names(unem.stl)
Unem.stl$time
>par(mfrow=c(3,1))
>plot(unem.stl$time[,2]); # trend
>plot(unem.stl$time[,1]); # seasonal
Time
a
1950 1960 1970 1980 1990 2000
-1.5-1.0-0.50.00.51.0](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-7-320.jpg)
![> plot(unem.stl$time[,3]); # residual
Figure 4: trend, seasonal effect, and residual
Figure 4 is decomposed data of unemployment rate. The first plot is the trend of the time
series of unemployment rate, second is the seasonal effect, and the last one is the residuals.
Through these plots we can decide that this data has weak seasonal effect, but we cannot see
the trend effect. We will use the trend component value and residuals values for forecasting.
We fit an ARMA model to the deseasonalized series Xt, which consists of the trend and the
residuals.
-Code for deseasonalized time series from the training
>unem.series <-unem.stl$time[,2]+unem.stl$time[,3]
Time
unem.stl$time[,2]
1950 1960 1970 1980 1990 2000
46810
Time
unem.stl$time[,1]
1950 1960 1970 1980 1990 2000
-0.0100.005
Time
unem.stl$time[,3]
1950 1960 1970 1980 1990 2000
-0.50.5](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-8-320.jpg)
![> par(mfrow=c(2,1))
> acf(unem.series); pacf(unem.series)
Figure 5. ACF (top panel) and PACF (bottom panel) of the deseasonalized time series.
We draw the ACF and PACF graph again without the trend effect. Comparing to
figure 2, the values more exponentially, smoothly decrease as time goes by. These data will
be fitted in ARMA model through the result of checking ACF function. To find the order of
AR and MA, we can use the AIC criteria from (1, 1) to (5, 5).
Let us see the result by running two models. (ARMA (1, 1) and ARMA (5, 5))
-Code for ARMA (1, 1)
aic<-matrix(rep(0,25), 5, 5);
for(i in 1:5) for (j in 1:5){
fit.arima<-arima(unem.series, order=c(i,0,j))
aic[i,j]<-fit.arima$aic}](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-9-320.jpg)
![aic
> aic
[,1] [,2] [,3] [,4] [,5]
[1,] -166.6036 -207.9955 -219.1004 -230.7408 -247.3997
[2,] -225.4142 -257.7890 -214.1998 -221.8776 -257.1761
[3,] -254.9962 -256.2421 -261.3230 -274.9241 -259.6045
[4,] -254.4048 -261.5649 -259.3315 -255.3169 -256.1432
[5,] -252.8203 -258.3666 -265.0479 -254.8651 -259.9598
The ACF and PACF of the deseasonalized series are plotted in Figure 5, which shows
significant autocorrelations for lags. We fit an ARMA model to the deseasonalized series by
using the AIC to determine the order of the ARMA model. We select the model that gives us
the minimum AICs. Now, to predict standard error, it needs to be plugged into ARMA model.
ARMA (1, 1) model is minimum absolute value. Thus we take ARMA (1, 1) as fitted model.
Based on the AIC, we fit the ARMA (1, 1) model with the standard errors of the parameter
estimates. As you can see, after deseasonalizing the time series of unemployment rates,
finally it fully satisfies the stationary condition. Before we go onto next step, it needs a
hypothesis that if we select higher ARMA model such as ARMA (5, 5), the result (predicted
error) will be more accurate.
-Code
> unem.series.arma1<-arima(unem.series, order=c(1,0,1))
> unem.series.arma1
Call:
arima(x = unem.series, order = c(1, 0, 1))
Coefficients:
ar1 ma1 intercept
0.9889 0.0654 5.3256
s.e. 0.0053 0.0309 0.6906
sigma^2 estimated as 0.0455: log likelihood = 87.3, aic = -166.6
>tsdiag(unem.series.arma1)](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-10-320.jpg)

![(c) Use your fitted model to compute k-months-ahead forecasts (k = 1, 2, . . . , 6) and
their standard errors, choosing December 2006 as the forecast origin. Compare your
forecasts with the actual unemployment rates.
Finally, I predict the value of 2007 and compare with real observation data.
We found the most adequate function to predict future unemployment rate. We can use the
fitted ARMA (1, 1) model to know 6- months-ahead forecasts.
-Code
>unem.pred<-predict(unem.series.arma1, n.ahead=6)
>unem.pred
$pred
Jan Feb Mar Apr May Jun
2007 4.503905 4.513061 4.522115 4.531068 4.539922 4.548677
$se
Jan Feb Mar Apr May
2007 0.2133059 0.3099469 0.3814630 0.4403011 0.4910647
Jun
2007 0.5360747
> unem.pred$pre+ unem.stl$time[1:6,1]
Jan Feb Mar Apr May Jun
2007 4.499849 4.511939 4.527317 4.534397 4.536292 4.560540 -- Predicted Rate
> unem<-ts(series[1:715,2], freq=12, start=c(1948, 1))
>
> ts(series[709:714,2], freq=12, start=c(2007,1))](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-12-320.jpg)

![Figure7. Diagnostic plots for the fitted ARMA (5, 5) model.
Figure 7 shows us that diagnose residuals (observation-fitted value) are just noise
(random and close to zero) by checking ACF plot. Furthermore, P-value for Lung – Box
Statistics is placed almost around 1. P-value for Lung-Box statistic is also greater than
standard. It indicates that higher level of ARMA model such as ARMA(5, 5) represent more
accurate result. So, we can predict the future unemployment rates 6 month ahead.
-Code
> unem.pred<-predict(unem.series.arma5, n.ahead=6)
> unem.pred
$pred
Jan Feb Mar Apr May Jun
2007 4.468035 4.475790 4.468911 4.516420 4.511021 4.550652
$se
Jan Feb Mar Apr May Jun
2007 0.1972530 0.2776295 0.3643634 0.4499888 0.5339693 0.6232356
> unem.pred$pre+unem.stl$time[1:6,1]
Jan Feb Mar Apr May Jun
Standardized Residuals
Time
1950 1960 1970 1980 1990 2000
-606
0.0 0.5 1.0 1.5 2.0
0.00.8
Lag
ACF
ACF of Residuals
2 4 6 8 10
0.00.6
p valuesfor Ljung-Box statistic
lag
pvalue](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-14-320.jpg)
![2007 4.463979 4.474668 4.474114 4.519748 4.507390 4.562515-Predicted
Rate
> unem<-ts(series[1:715,2], freq=12, start=c(1948,1))
> ts(series[709:714,2], freq=12, start=c(2007,1))
Jan Feb Mar Apr May Jun
2007 4.6 4.5 4.4 4.5 4.5 4.5-- Actual Rate
The result above gives the forecast values of the time series from January to June
2007 based on the ARMA(5, 5) model of January 1948 to December 2006 unemployment
rate. Finally, we obtained the future value from analyzing past data. To check all the
procedures worked successfully, we compare the predicted value to real value. The Predicted
Rate is not much different with the Actual Rate in ARMA(5, 5), because both rates
differences are in the standard error boundary. Thus, I am able to conclude that my prediction
with ARMA (5, 5) is appropriate.
We can conclude that both ARMA (1, 1) and ARMA(5, 5) are acceptable, because the
differences are in the standard error boundary. However, higher ARMA model prediction will
be more accurate than lower ARMA model even though the ARMA(1, 1) is easier to deal
with data.](https://image.slidesharecdn.com/94b5389e-7dcc-4042-b8a8-f82e8a7f97a8-161223200114/85/Byungchul-Yea-Project-15-320.jpg)

![ARIMA Models - [Lab 3]](https://cdn.slidesharecdn.com/ss_thumbnails/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



























































