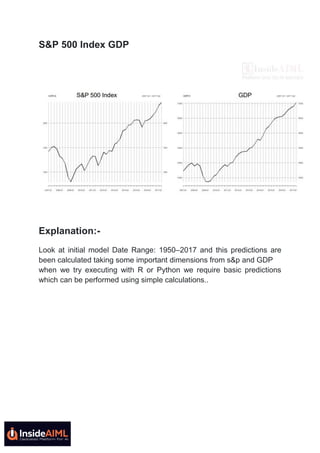
The document discusses various time series models such as AR, MA, ARMA, ARIMA, and ARIMAX, which are used to forecast sales for Godrej Nature's Basket from January 1 to January 15, 2019. It describes the methodologies, key observations, model identification, evaluation phases, and the importance of handling seasonality and trends in the data. Additionally, it highlights concepts like spurious regression and Granger causality, emphasizing the need for stationary data to improve predictive accuracy.





















![ARIMA Models - [Lab 3]](https://cdn.slidesharecdn.com/ss_thumbnails/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





































































