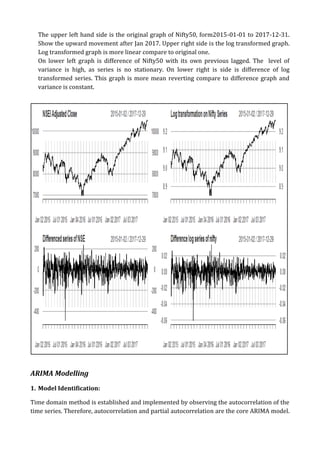
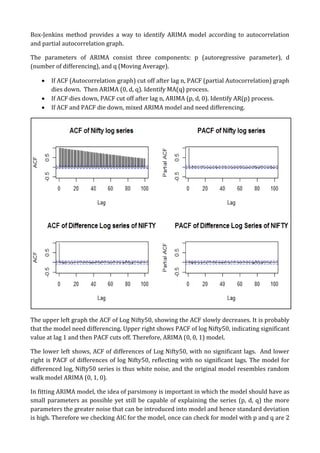
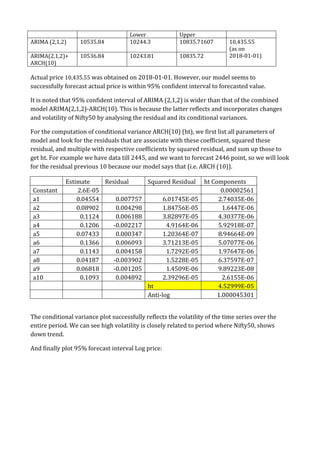
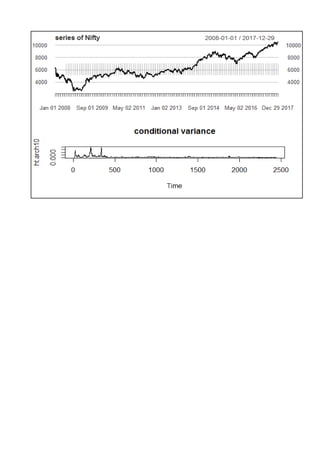
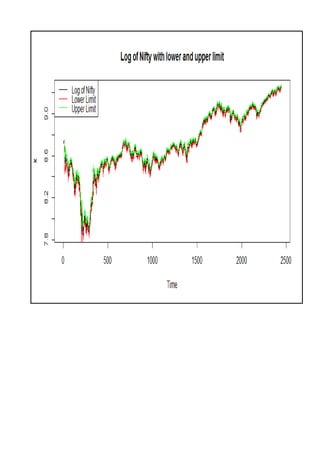
The document summarizes a project on time series modeling using ARIMA and ARCH/GARCH methods for forecasting the future price movements of the Nifty 50 index in India. It details the steps for data preparation, achieving stationarity, model identification, parameter estimation, and diagnostic checking. The analysis concludes with the selection of appropriate models based on Akaike Information Criterion (AIC) and residual analysis, ultimately recommending ARIMA (2,1,2) and ARCH(10) for modeling volatility.













![Shell sort[1]](https://cdn.slidesharecdn.com/ss_thumbnails/shellsort1-131120033842-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)