Downloaded 42 times








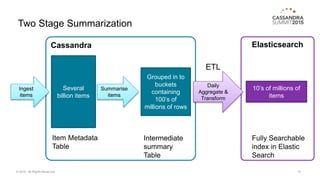
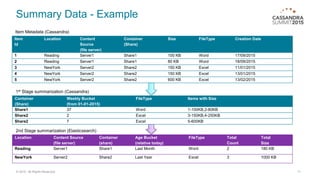



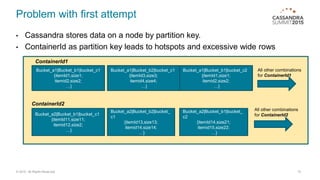
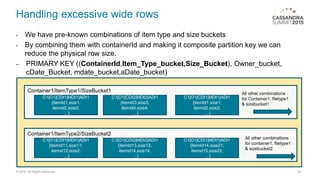







The document provides an overview of a multi-tenant, cloud-based data management service allowing users to efficiently analyze large data sets through a structured schema. It details a two-stage summarization process using Cassandra and Elasticsearch to enable interactive queries with a focus on performance and scalability. Challenges faced include managing wide rows and tombstone issues, which were addressed through schema adjustments and improved compaction strategies.






















































































