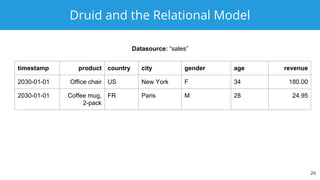
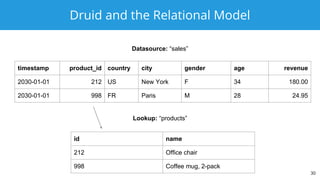
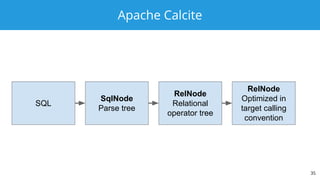
The document discusses Apache Druid, a high-performance, distributed data store designed for real-time analytics and interactive exploration of large datasets. It outlines the characteristics of NoSQL databases, the transition from NoSQL to SQL, and how Apache Calcite facilitates SQL support in Druid for optimized querying. Key features of Druid include low latency ingestion, ad-hoc queries, and flexible data schema management.






























![Relational operators
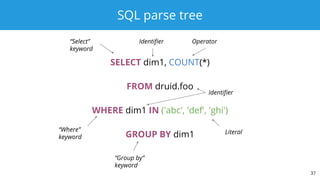
SELECT dim1, COUNT(*)
FROM druid.foo
WHERE dim1 IN ('abc', 'def', 'ghi')
GROUP BY dim1
38
LogicalAggregate(group=[{0}], EXPR$1=[COUNT()])
LogicalProject(dim1=[$2])
LogicalFilter(condition=[OR(=($2, 'abc'), =($2, 'def'), =($2, 'ghi'))])
LogicalTableScan(table=[[druid, foo]])](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-38-320.jpg)



![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
42](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-42-320.jpg)
![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
43](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-43-320.jpg)
![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
44](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-44-320.jpg)
![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
45](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-45-320.jpg)
![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
46](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-46-320.jpg)
![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
47](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-47-320.jpg)
![Native vs SQL
{
"queryType": "topN",
"dataSource": “wikipedia”,
"dimension": "countryName",
"metric": {
"type": "numeric",
"metric": "added"
},
"intervals": "2018-03-01/2018-03-06",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "channel",
"value": "#en.wikipedia",
"extractionFn": null
},
{
"type": "not",
"field": {
"type": "selector",
"dimension": "countryName",
"value": "",
"extractionFn": null
}
}
]
},
"granularity": "all",
"aggregations": [
{
"type": "longSum",
"name": "added",
"fieldName": "added"
}
],
"threshold": 5
}
SELECT
countryName,
SUM(added)
FROM wikipedia
WHERE
channel = '#en.wikipedia'
AND countryName IS NOT NULL
AND __time BETWEEN '2018-03-01' AND '2018-03-06'
GROUP BY countryName
ORDER BY SUM(added) DESC
LIMIT 5
48](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-48-320.jpg)
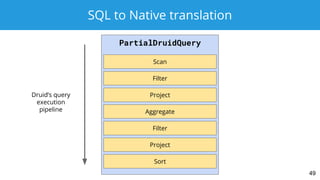
![SQL to Native translation
SELECT dim1, COUNT(*)
FROM druid.foo
WHERE dim1 IN ('abc', 'def', 'ghi')
GROUP BY dim1
50
LogicalAggregate(group=[{0}], EXPR$1=[COUNT()])
LogicalProject(dim1=[$2])
LogicalFilter(condition=[OR(=($2, 'abc'), =($2, 'def'), =($2, 'ghi'))])
LogicalTableScan(table=[[druid, foo]])](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-50-320.jpg)
![SQL to Native translation
51
PartialDruidQuery
Scan(table=[[druid, foo]])
Filter(condition=[OR(=($2,
'abc'), =($2, 'def'), =($2, 'ghi'))])
Project(dim1=[$2])
Aggregate(group=[{0}],EXPR$1=[COUNT()])
Filter
Project
Sort
LogicalTableScan(table=[[druid, foo]])
LogicalFilter(condition=[OR(=($2,
'abc'), =($2, 'def'), =($2, 'ghi'))])
LogicalProject(dim1=[$2])
LogicalAggregate(group=[{0}],EXPR$1=[COUNT()])](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-51-320.jpg)
![SQL to Native translation
52
PartialDruidQuery
Filter
Project
Sort
{
"queryType" : "groupBy",
"dataSource" : “foo”,
"filter" : {
"type" : "in",
"dimension" : "dim1",
"values" : [ "abc", "def", "ghi" ]
},
"dimensions" : [ “dim1” ],
"aggregations" : [ {
"type" : "count",
"name" : "a0"
} ],
}
Scan(table=[[druid, foo]])
Filter(condition=[OR(=($2,
'abc'), =($2, 'def'), =($2, 'ghi'))])
Project(dim1=[$2])
Aggregate(group=[{0}],EXPR$1=[COUNT()])
toDruidQuery()](https://image.slidesharecdn.com/gian-stratasanjose2018-180308035228/85/NoSQL-no-more-SQL-on-Druid-with-Apache-Calcite-52-320.jpg)







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



