Download as PDF, PPTX








![Attempt[0] Architecture
Operational
Analytics
Business
Analytics
Executive
Dashboards
Data
Discovery
Data
Science
3rd Party
System
Integration
Events
3rd Party
Other DBs
S3
Stream
Processing
Batch
Sources
Storage and Processing
Consumers
Data Access
Kafka
Streaming
Custom
Ingestion
Pipeline
ETL
Streaming
Sources
RESTful
Enqueue
service
SQL](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-8-320.jpg)
![Attempt[0] Data Model
CREATE TABLE events (
timebucket bigint,
timestamp bigint,
eventtype varchar,
eventid varchar,
platform varchar,
userid varchar,
version int,
appid varchar,
useragent varchar,
eventdata varchar,
tags set<varchar>,
devicedata map<varchar, varchar>,
PRIMARY KEY ((timebucket, eventtype), timestamp, eventid)
) WITH CACHING = 'none'
AND COMPACTION = { 'class' : 'DateTieredCompactionStrategy' };](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-9-320.jpg)
![Attempt[0] Data Model
CREATE TABLE events (
timebucket bigint,
timestamp bigint,
eventtype varchar,
eventid varchar,
platform varchar,
userid varchar,
version int,
appid varchar,
useragent varchar,
eventdata varchar,
tags set<varchar>,
devicedata map<varchar, varchar>,
PRIMARY KEY ((timebucket, eventtype), timestamp, eventid)
) WITH CACHING = 'none'
AND COMPACTION = { 'class' : 'DateTieredCompactionStrategy' };
Event payload == schema-less JSON](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-10-320.jpg)
![Attempt[0] Data Model
CREATE TABLE events (
timebucket bigint,
timestamp bigint,
eventtype varchar,
eventid varchar,
platform varchar,
userid varchar,
version int,
appid varchar,
useragent varchar,
eventdata varchar,
tags set<varchar>,
devicedata map<varchar, varchar>,
PRIMARY KEY ((timebucket, eventtype), timestamp, eventid)
) WITH CACHING = 'none'
AND COMPACTION = { 'class' : 'DateTieredCompactionStrategy' };
Partitioned by time bucket + type](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-11-320.jpg)
![Attempt[0] Data Model
CREATE TABLE events (
timebucket bigint,
timestamp bigint,
eventtype varchar,
eventid varchar,
platform varchar,
userid varchar,
version int,
appid varchar,
useragent varchar,
eventdata varchar,
tags set<varchar>,
devicedata map<varchar, varchar>,
PRIMARY KEY ((timebucket, eventtype), timestamp, eventid)
) WITH CACHING = 'none'
AND COMPACTION = { 'class' : 'DateTieredCompactionStrategy' };
Time-series data good fit for DTCS](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-12-320.jpg)
![Attempt[0] tl;dr
● C* everywhere
● Streaming data via custom ingest process
● Kafka backed by RESTful service
● Batch data via Informatica
● Spark SQL through ODBC
● Schema-less event payload
● Date-tiered compaction](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-13-320.jpg)
![Attempt[0] tl;dr
● C* everywhere
● Streaming data via custom ingest process
● Kafka backed by RESTful service
● Batch data via Informatica
● Spark SQL through ODBC
● Schema-less event payload
● Date-tiered compaction](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-14-320.jpg)
![Attempt[0] Lessons
● Batch loading large data sets into C* is silly
● … and expensive
● … and using Informatica to do it is SLOW
● Kafka + REST services == unnecessary
● No viable open source C* Hive driver
● DTCS is broken (see CASSANDRA-9666)](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-15-320.jpg)
![Attempt[0] Lessons
● Schema-less == bad:
○ Must parse JSON to extract key data
○ Expensive to analyze by event type
○ Cannot tune by event type](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-16-320.jpg)
![Attempt[1] Architecture
Data Lake
Operational
Analytics
Business
Analytics
Executive
Dashboards
Data
Discovery
Data
Science
3rd Party
System
Integration
Stream
Processing
Long Term Raw Storage
Short Term Storage and
Big Data Processing
Consumers
Amazon SQS
Streaming
Custom
Ingestion
Pipeline
Events
3rd Party
Other DBs
S3
Batch
Sources
Streaming
Sources
ETL
Data Access
SQL](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-17-320.jpg)
![Attempt[1] Data Model
● Each event type gets its own table
● Tables individually tuned based on workload
● Schema applied at ingestion:
○ We’re reading everything anyway
○ Makes subsequent analysis much easier
○ Allows us to filter junk early](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-18-320.jpg)
![Attempt[1] tl;dr
● Use C* for streaming data
○ Rolling time window (TTL depends on type)
○ Real-time access to events
○ Data locality makes Spark jobs faster](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-19-320.jpg)
![Attempt[1] tl;dr
● Everything else in S3
○ Batch data loads (mostly logs)
○ Daily C* backups
○ Stored as Parquet
○ Cheap, scalable long-term storage
○ Easy access from Spark
○ Easy to share internally & externally
○ Open source Hive support](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-20-320.jpg)
![Attempt[1] tl;dr
● Kafka replaced by SQS:
○ Scalable & reliable
○ Already fronted by a RESTful interface
○ Nearly free to operate (nothing to manage)
○ Robust security model
○ One queue per event type/platform
○ Built-in monitoring](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-21-320.jpg)
![Attempt[1] tl;dr
● STCS in lieu of DTCS (and LCS)
○ Because it’s bulletproof
○ Partitions spanning sstables is acceptable
○ Testing Time-Window compaction (thanks Jeff
Jirsa)](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-22-320.jpg)
![Attempt[1] tl;dr
● STCS in lieu of DTCS (and LCS)
○ Because it’s bulletproof
○ Partitions spanning sstables is acceptable
○ Testing Time-Window compaction (thanks Jeff
Jirsa)](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-23-320.jpg)





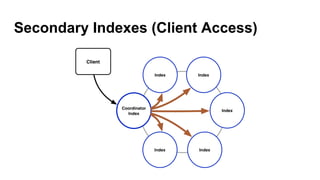
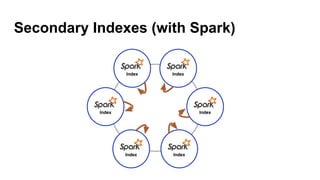


![Full-text Indexes
SELECT * FROM emails WHERE lucene='{
filter : {type:"range", field:"time", lower:"2015-05-26 20:29:59"},
query : {type:"phrase", field:"subject", values:["test"]}
}';
SELECT * FROM emails WHERE lucene='{
filter : {type:"range", field:"time", lower:"2015-05-26 18:29:59"},
query : {type:"fuzzy", field:"subject", value:"thingy", max_edits:1}
}';](https://image.slidesharecdn.com/lambdaweatherscalemin-150926122856-lva1-app6892/85/Lambda-at-Weather-Scale-Cassandra-Summit-2015-33-320.jpg)






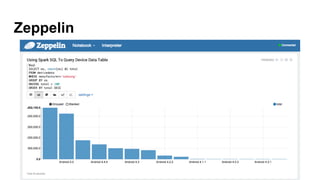
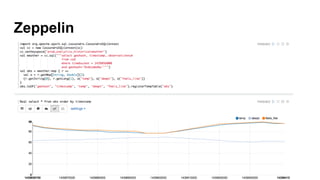





This document provides an overview of Weather.com's analytics architecture using Apache Cassandra and Spark. It summarizes Weather.com's initial attempts using Cassandra, lessons learned, and its improved architecture. The improved architecture uses Cassandra for streaming event data with time-window compaction, stores all other data in Amazon S3 for batch processing in Spark, and replaces Kafka with Amazon SQS for event ingestion. It discusses best practices for data modeling in Cassandra including partitioning, secondary indexes, and avoiding wide rows and nulls. The document also highlights how Weather.com uses Apache Zeppelin notebooks for data exploration and visualization.









































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











