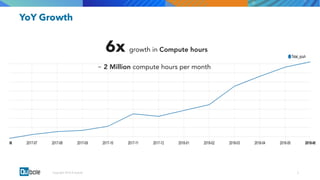
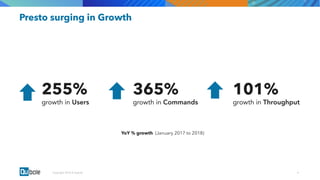
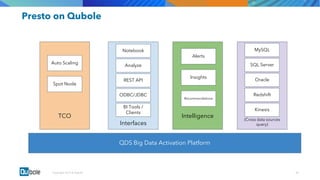
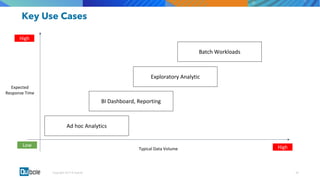
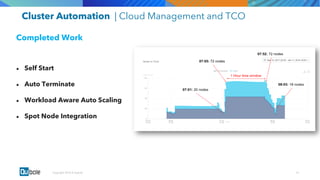
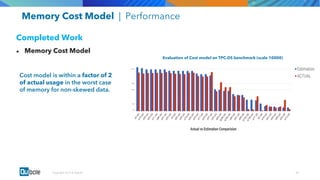
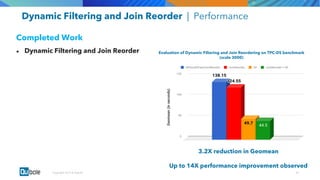
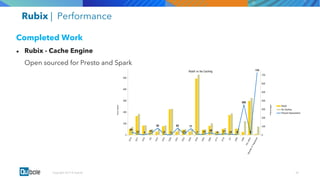
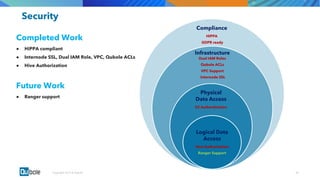
The document discusses the adoption and growth of Presto on the cloud from past to present, highlighting significant year-over-year increases in compute hours, users, commands, and throughput. It outlines current functionalities at Qubole, including cluster management, performance enhancements, and security measures, while also noting completed and future projects aimed at optimizing operations. Key areas of focus for future development include predictive autoscaling, improved performance metrics, and enhanced security compliance.



































![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)















































