Downloaded 10 times





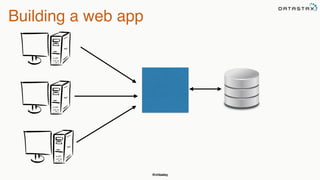
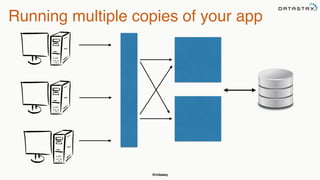

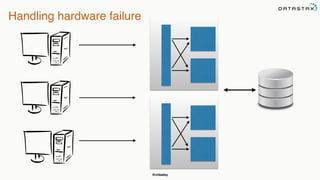
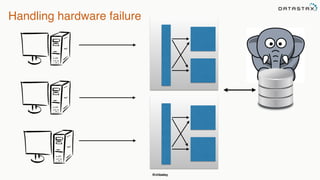
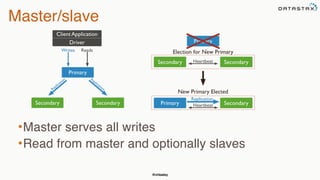
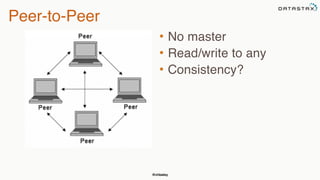
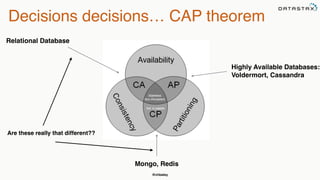






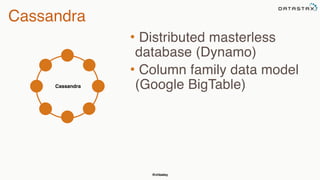
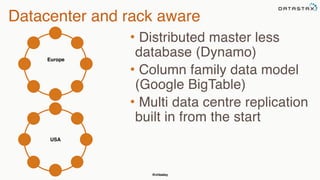
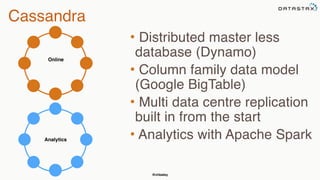






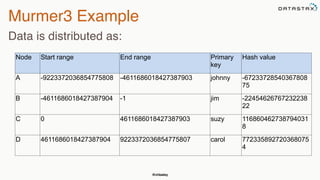


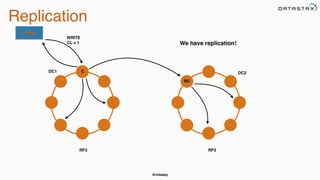



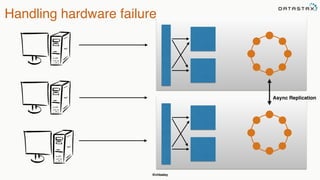
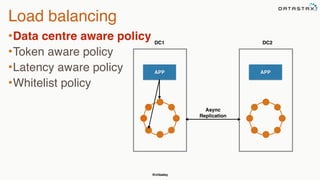
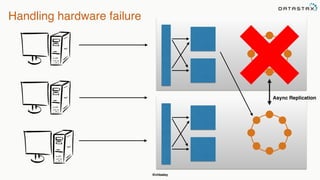
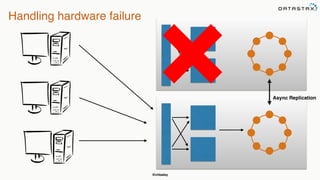
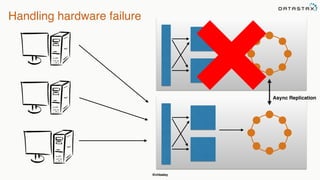

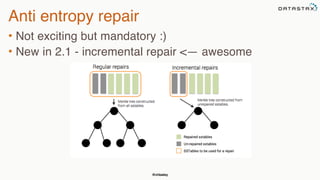






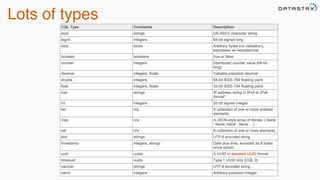












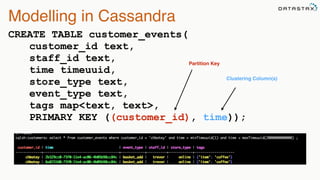





















This document provides an overview of Apache Cassandra presented by Christopher Batey, a Technical Evangelist for Apache Cassandra. It begins with introductions and background on Batey. It then covers key aspects of Cassandra including distributed databases, Cassandra use cases, replication, fault tolerance, data modeling with Cassandra Query Language (CQL) and the Java driver. Examples are provided around modeling customer event data in Cassandra and querying that data.





























































































