Download as PDF, PPTX

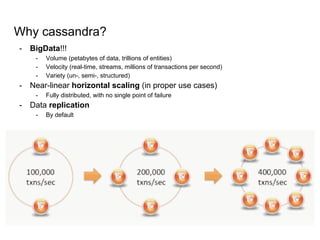
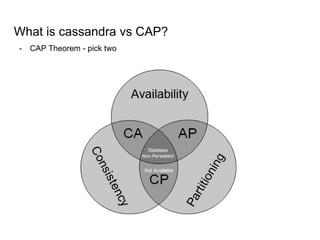
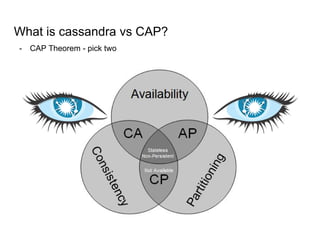


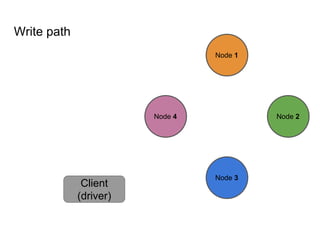
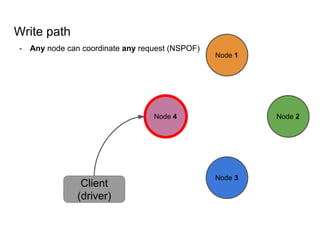
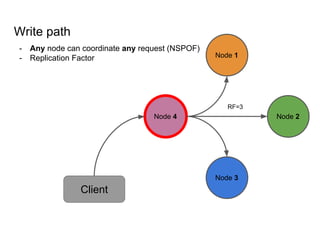
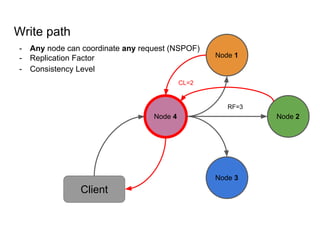
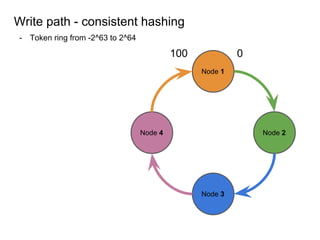
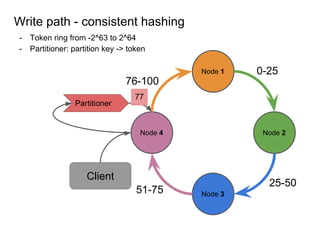
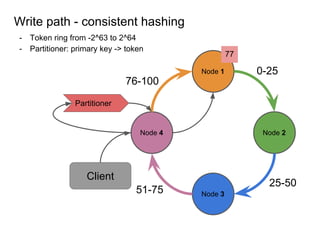
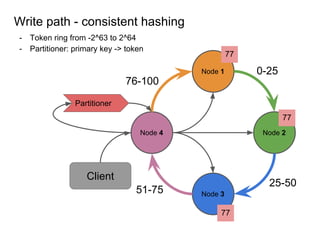
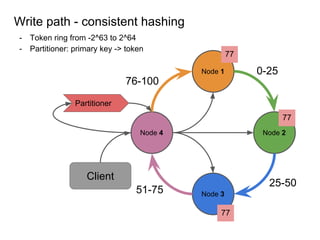

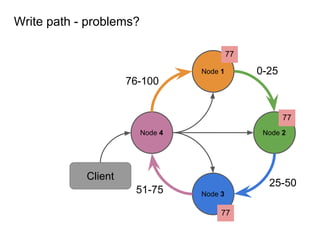
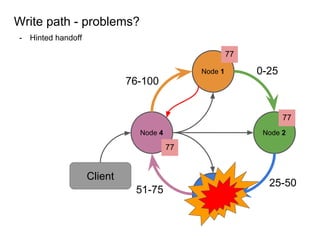
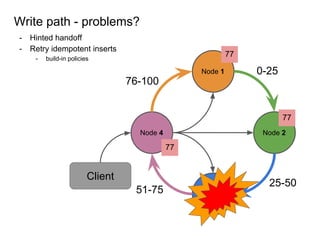
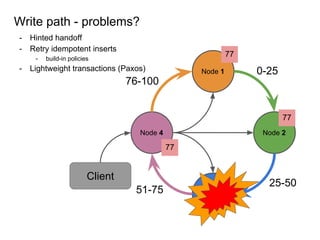
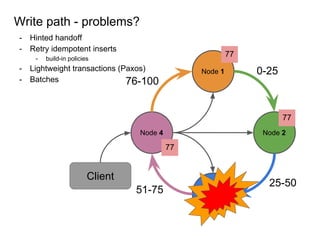
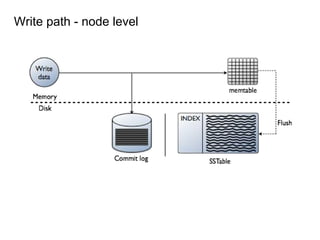

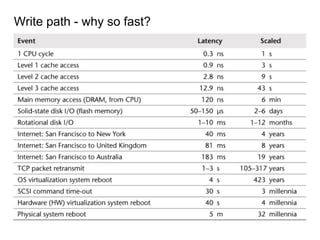

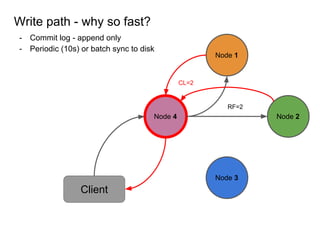
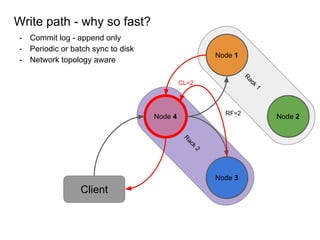
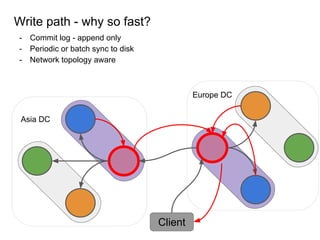
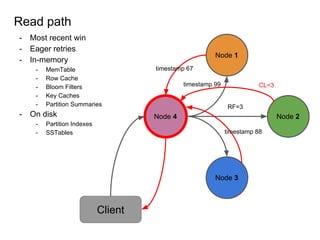
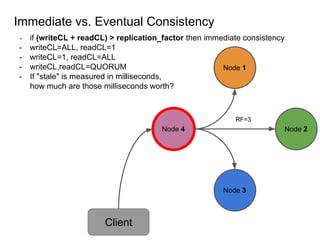
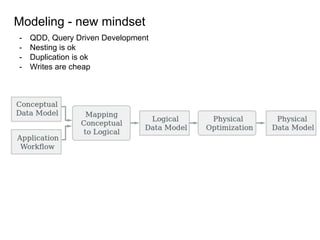
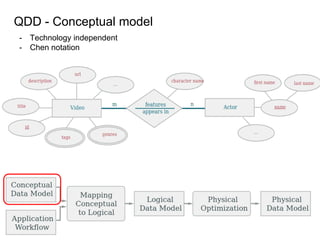
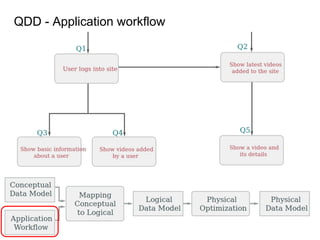
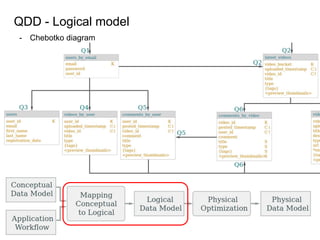
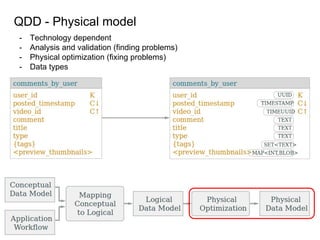

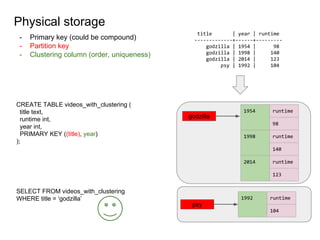
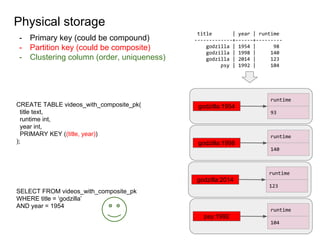
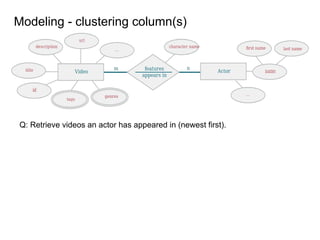
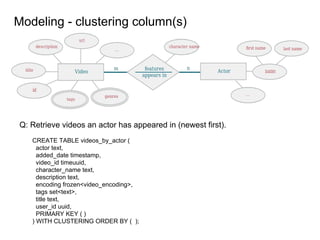
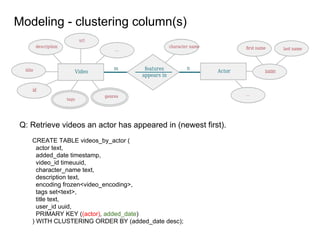
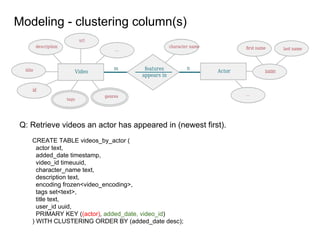
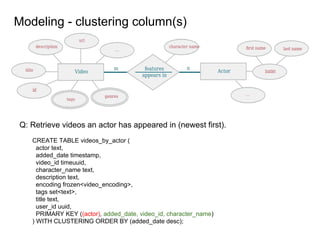






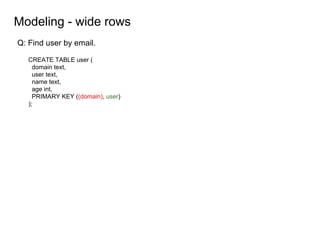

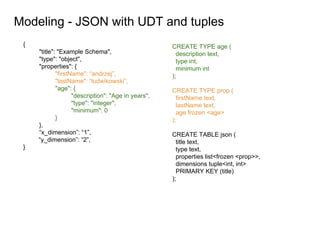





This document provides an overview of Cassandra, including: - Why Cassandra is used for big data applications handling large volumes of data. - How Cassandra's distributed architecture provides high availability and horizontal scalability. - Details of Cassandra's write path, including how writes are replicated across nodes and how consistency is ensured. - Examples of modeling data in Cassandra, including choices for primary keys, clustering columns, and other techniques. - Common use cases where Cassandra is applicable, such as sensor data, fraud detection, and personalization engines.
























































































