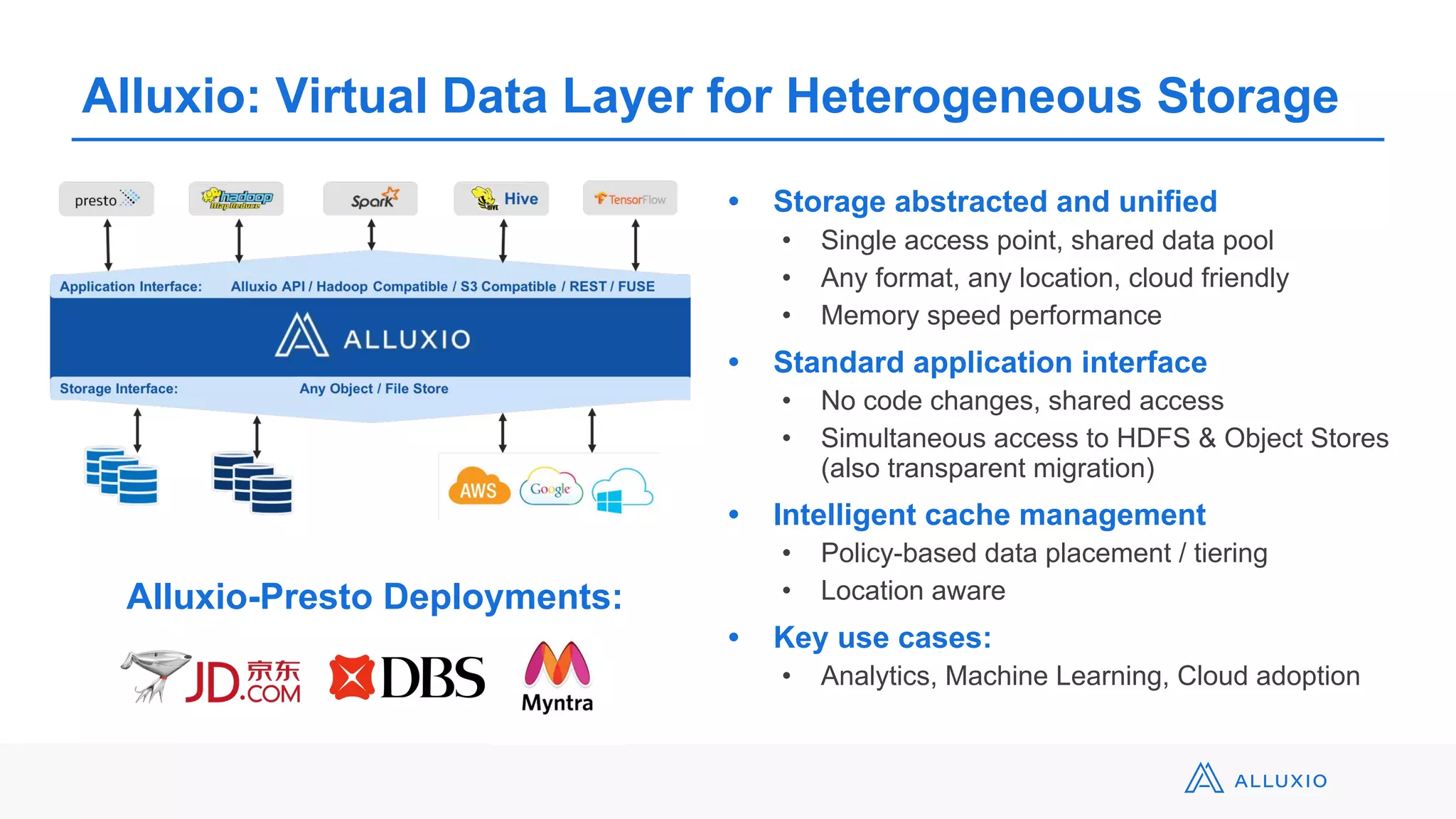
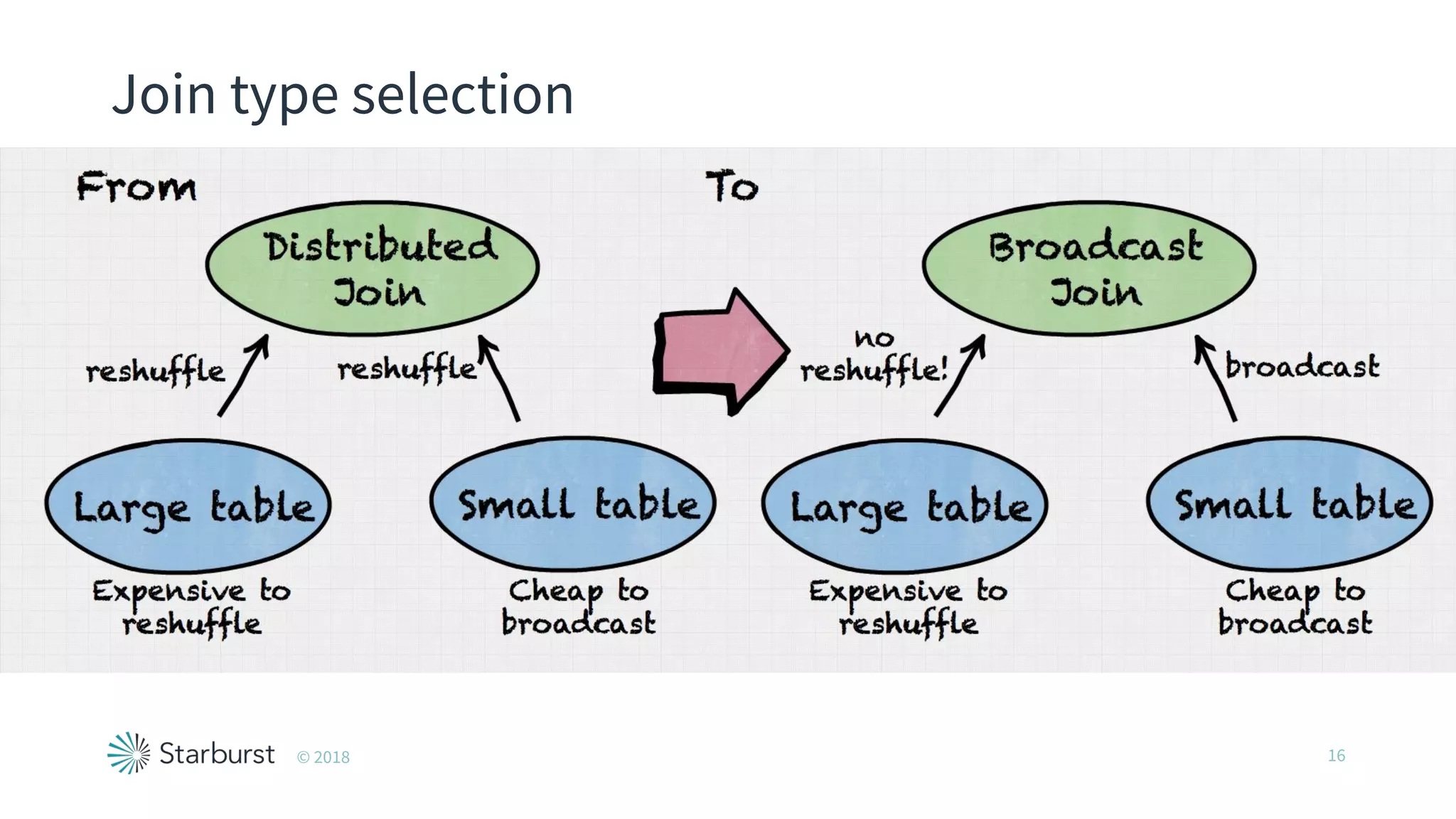
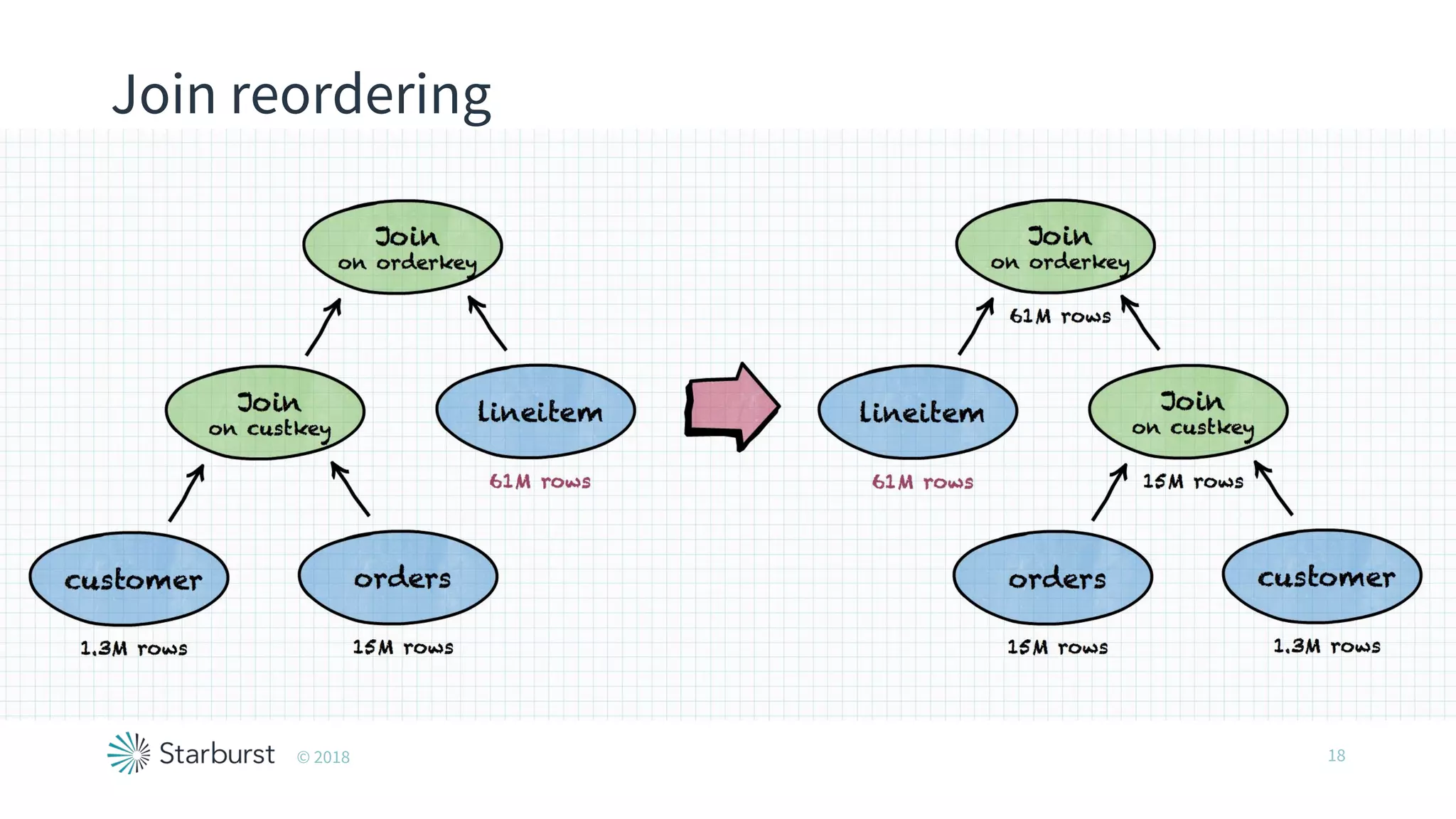
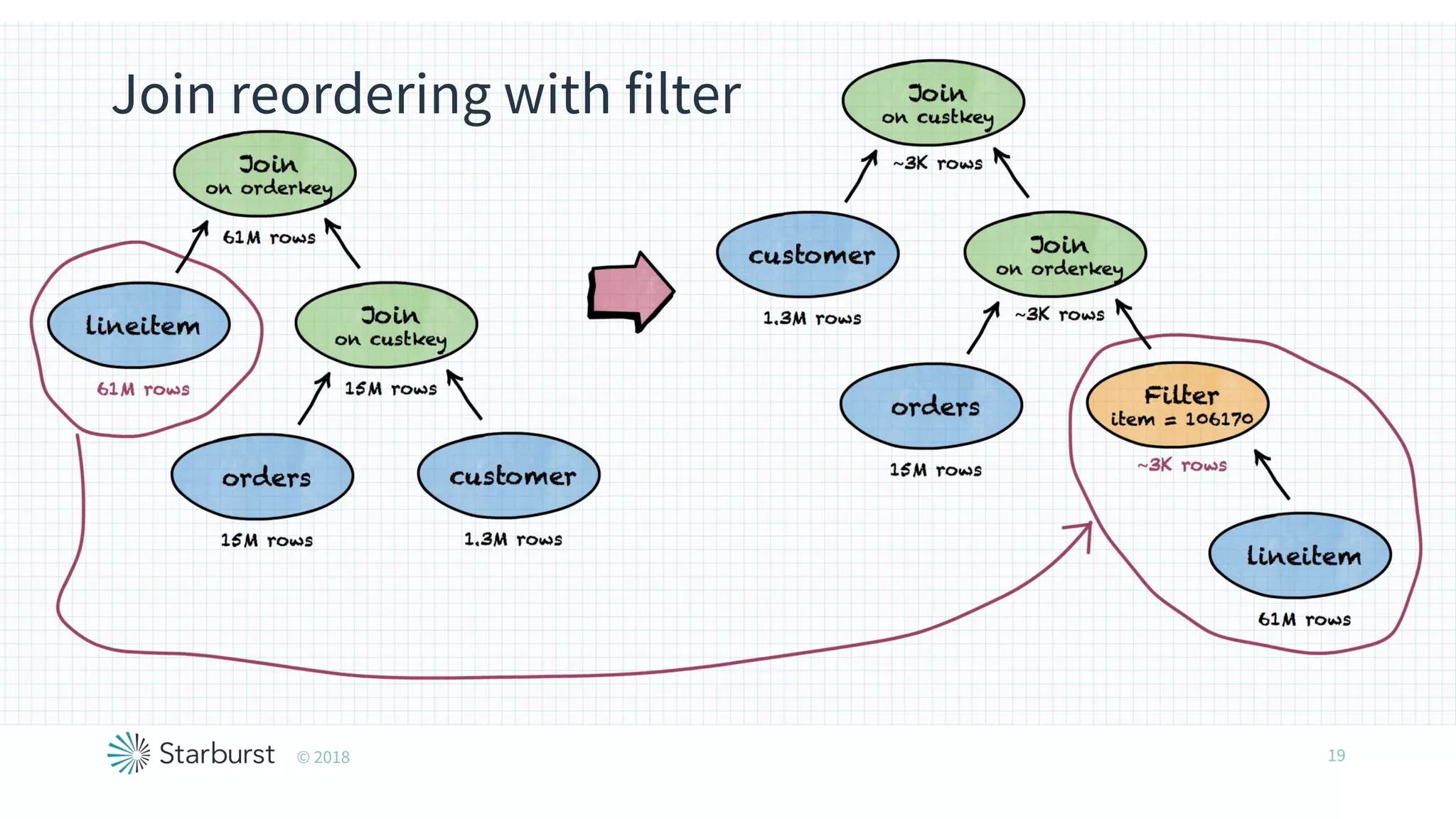
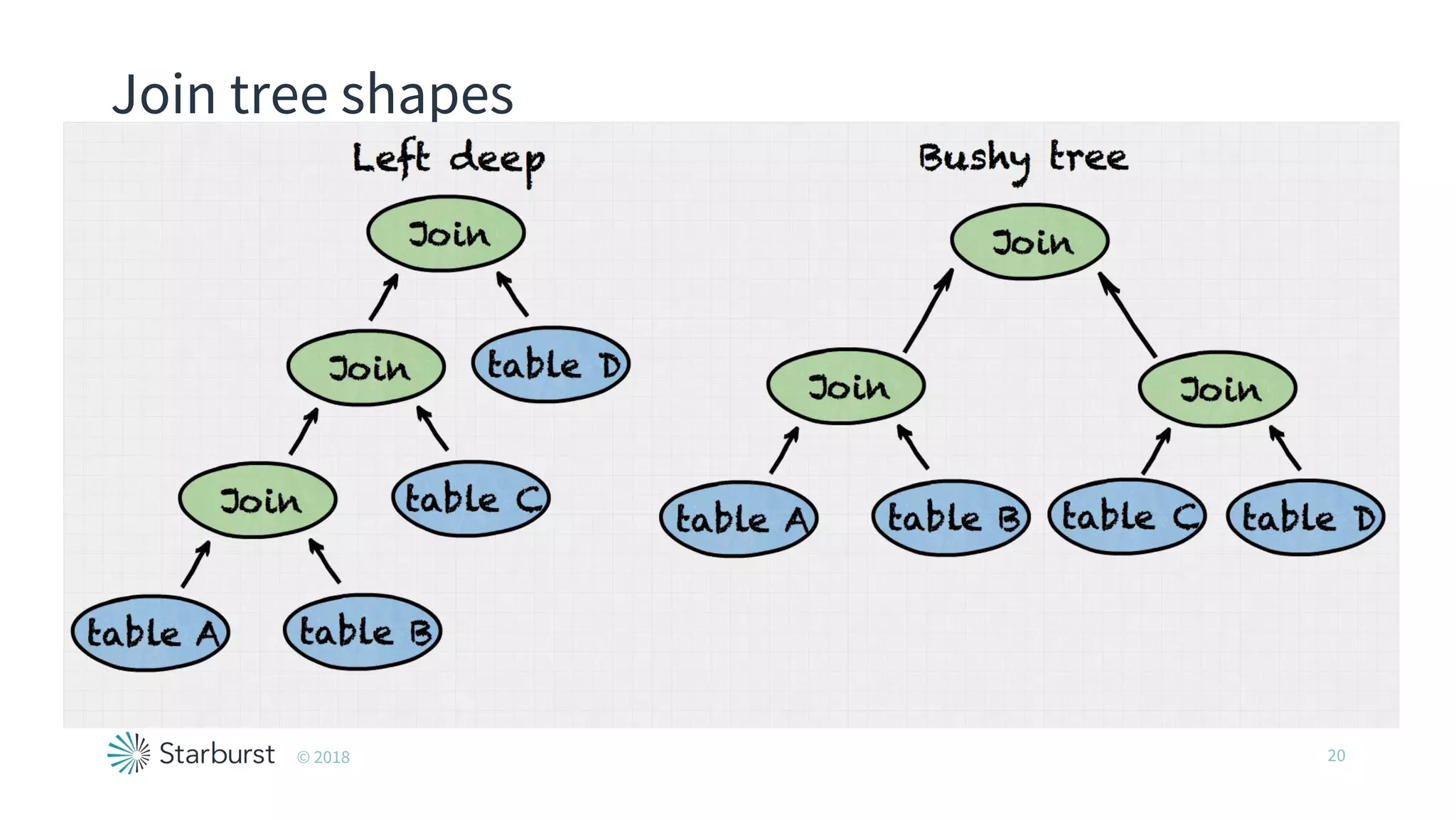
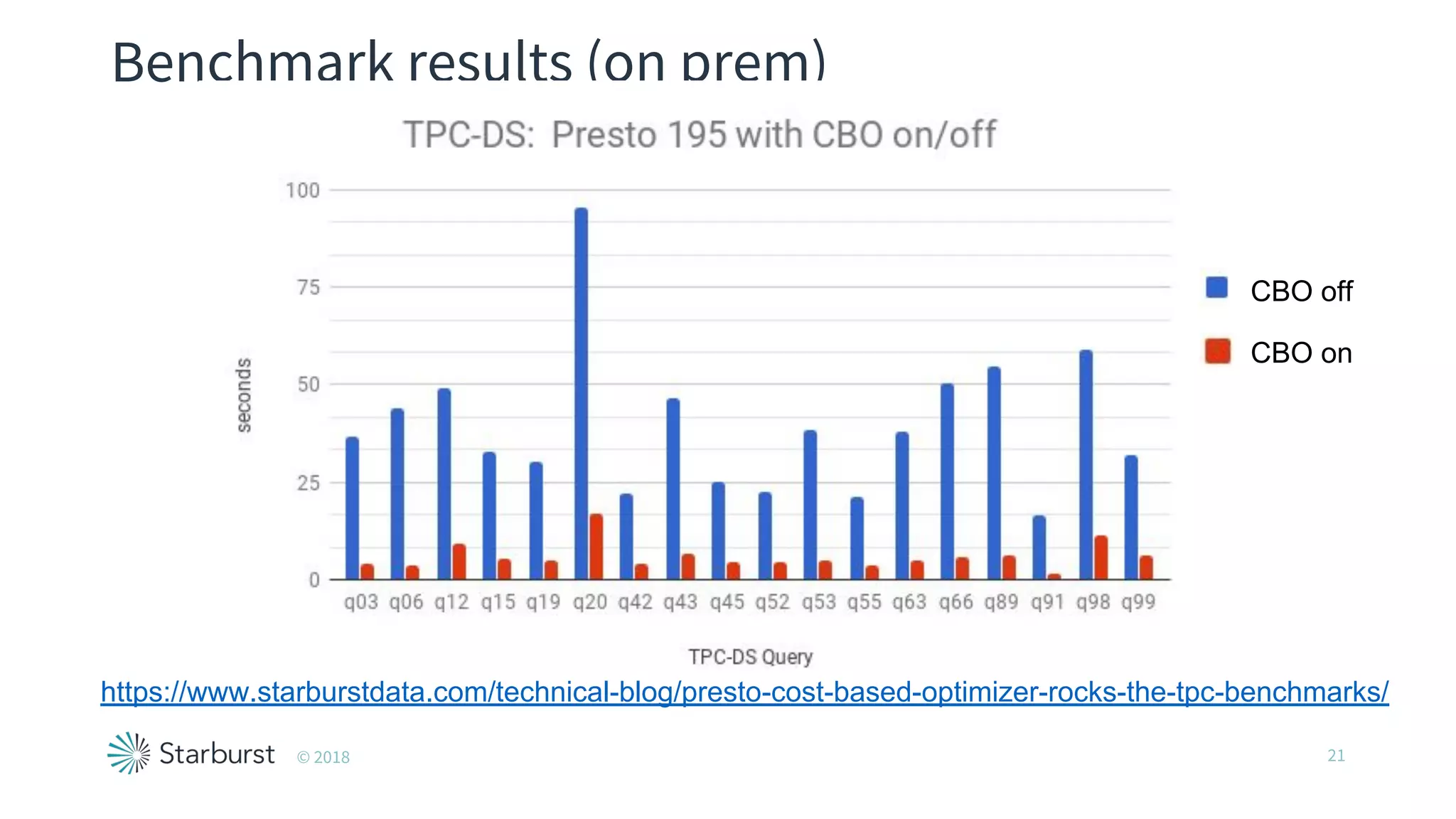
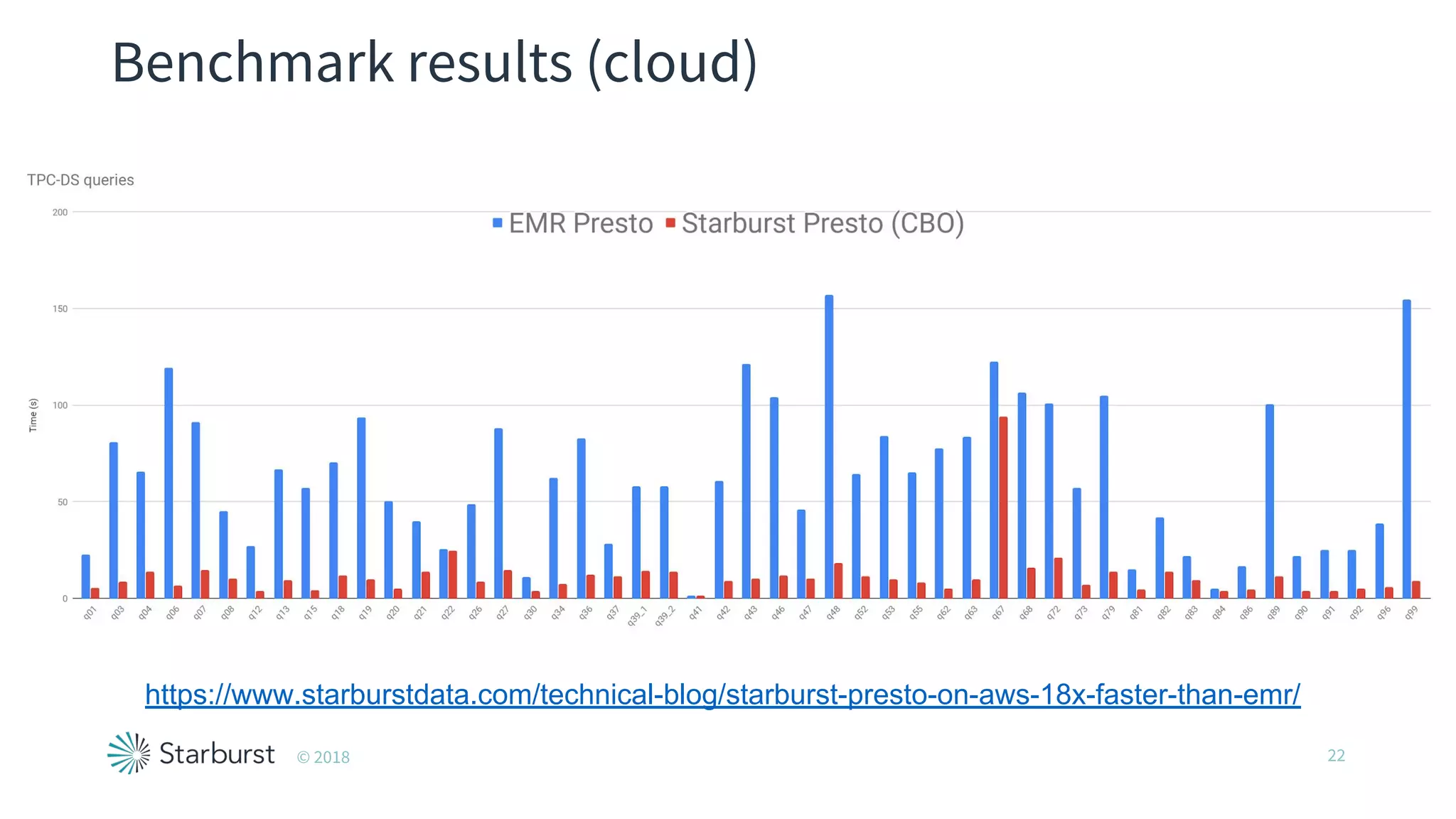
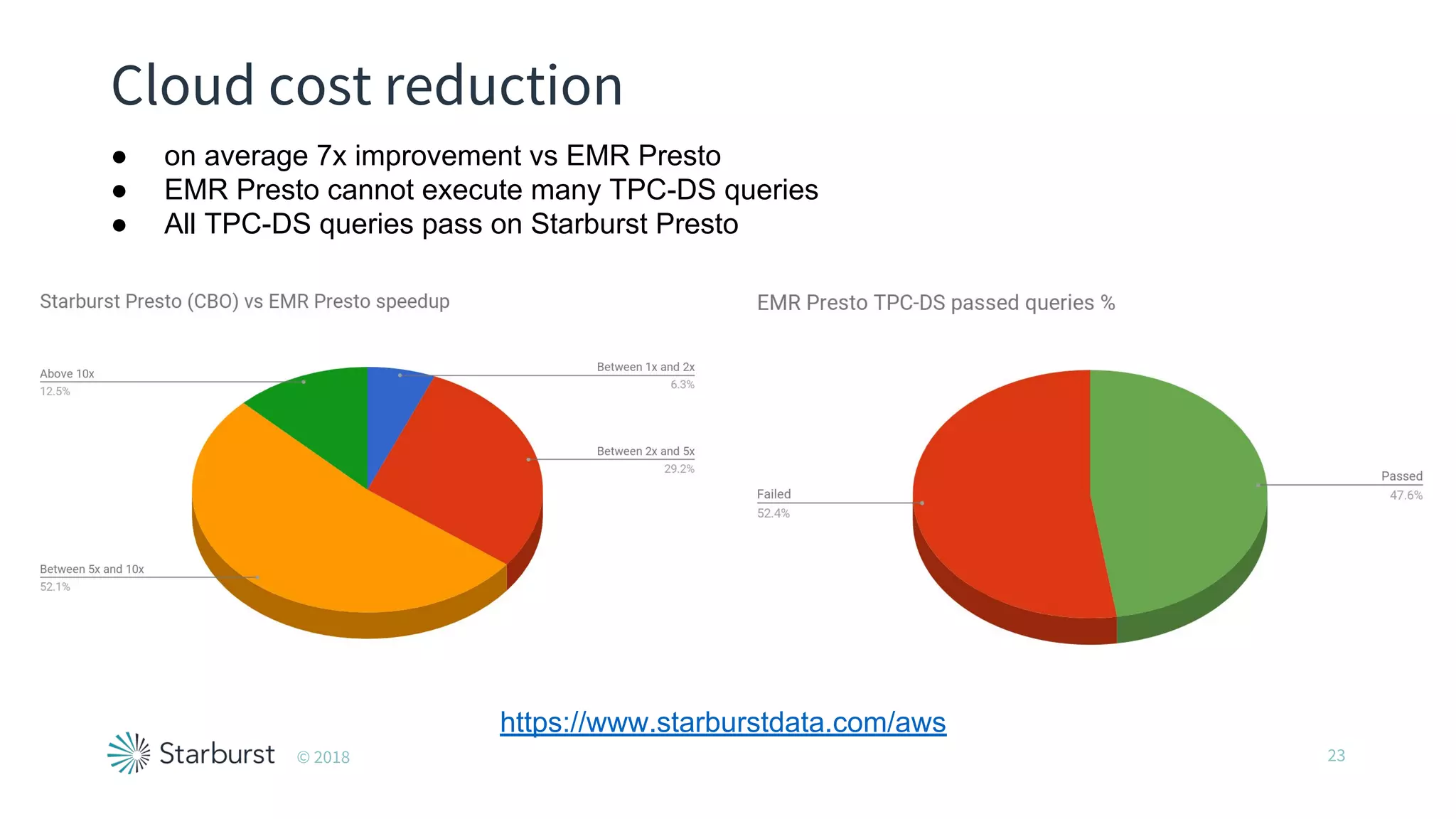
The document presents details about Starburst, a company specializing in the Presto cost-based optimizer, outlining its background, notable features, and product offerings such as enterprise support and a fully managed service. It discusses the integration of Presto with data storage solutions like Alluxio and Apache Pulsar for analytics and machine learning. Additionally, it highlights the performance improvements and cost reduction achieved with the Presto optimizer compared to traditional solutions.