





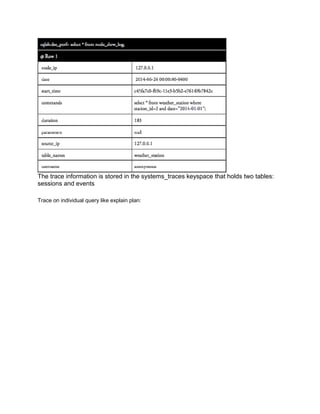
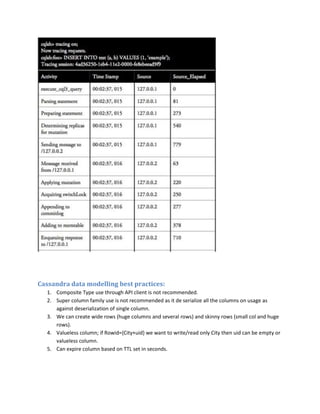

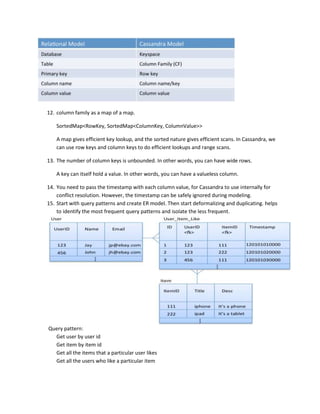
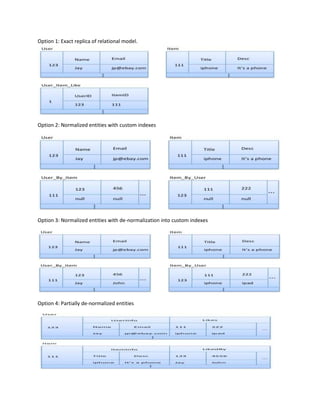



This document discusses how to implement operations like selection, joining, grouping, and sorting in Cassandra without SQL. It explains that Cassandra uses a nested data model to efficiently store and retrieve related data. Operations like selection can be performed by creating additional column families that index data by fields like birthdate and allow fast retrieval of records by those fields. Joining can be implemented by nesting related entity data within the same column family. Grouping and sorting are also achieved through additional indexing column families. While this requires duplicating data for different queries, it takes advantage of Cassandra's strengths in scalable updates.






















































































