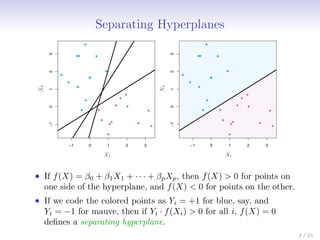
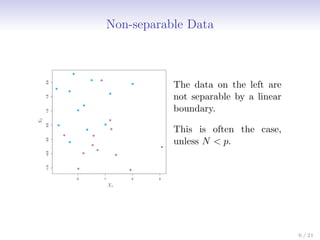
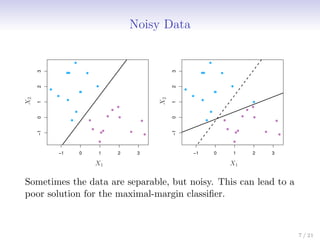
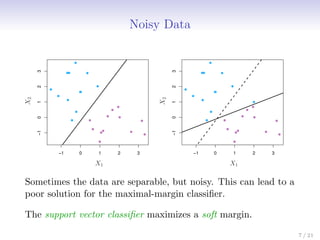
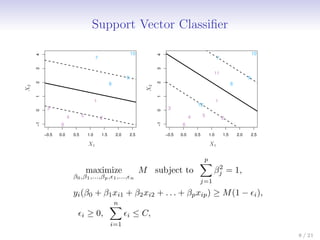
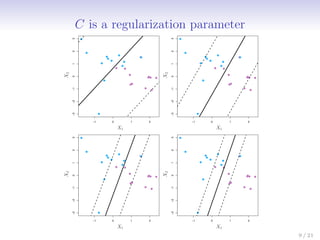
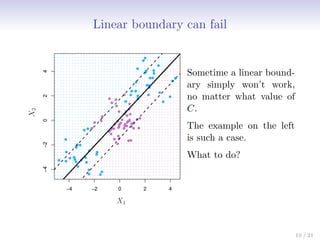
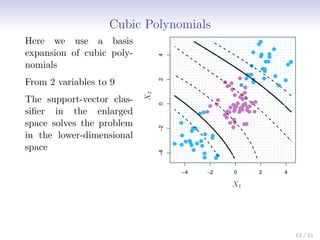
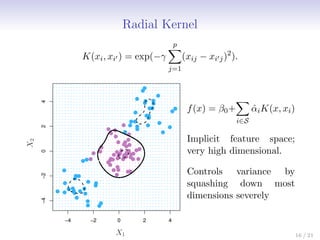
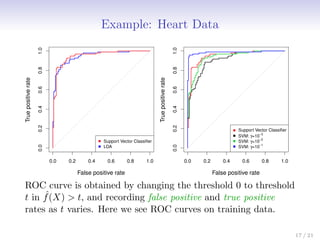
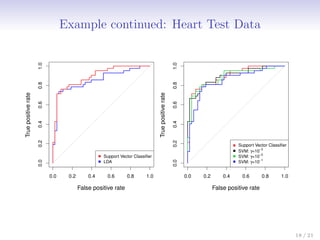
This document discusses support vector machines (SVMs), focusing on the two-class classification problem, hyperplanes, and the concept of maximal margin classifiers. It describes techniques for handling non-separable data, noisy data, and the use of feature expansions and kernels to achieve non-linear decision boundaries. Additionally, it covers how to extend SVMs to classify more than two classes using strategies like one-versus-all and one-versus-one methods.


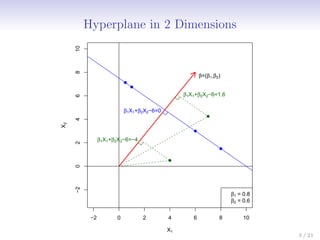









![Inner products and support vectors
hxi, xi0 i =
p
X
j=1
xijxi0j — inner product between vectors
• The linear support vector classifier can be represented as
f(x) = β0 +
n
X
i=1
αihx, xii — n parameters
• To estimate the parameters α1, . . . , αn and β0, all we need
are the n
2
inner products hxi, xi0 i between all pairs of
training observations.
It turns out that most of the α̂i can be zero:
f(x) = β0 +
X
i∈S
α̂ihx, xii
S is the support set of indices i such that α̂i 0. [see slide 8]
14 / 21](https://image.slidesharecdn.com/c9-support-vector-machine-240510100620-ebacfacb/85/course-slides-of-Support-Vector-Machine-pdf-21-320.jpg)








![Support Vector versus Logistic Regression?
With f(X) = β0 + β1X1 + . . . + βpXp can rephrase
support-vector classifier optimization as
minimize
β0,β1,...,βp
n
X
i=1
max [0, 1 − yif(xi)] + λ
p
X
j=1
β2
j
−6 −4 −2 0 2
0
2
4
6
8
Loss
SVM Loss
Logistic Regression Loss
yi(β0 + β1xi1 + . . . + βpxip)
This has the form
loss plus penalty.
The loss is known as the
hinge loss.
Very similar to “loss” in
logistic regression (negative
log-likelihood).
20 / 21](https://image.slidesharecdn.com/c9-support-vector-machine-240510100620-ebacfacb/85/course-slides-of-Support-Vector-Machine-pdf-33-320.jpg)






























![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)