Downloaded 90 times

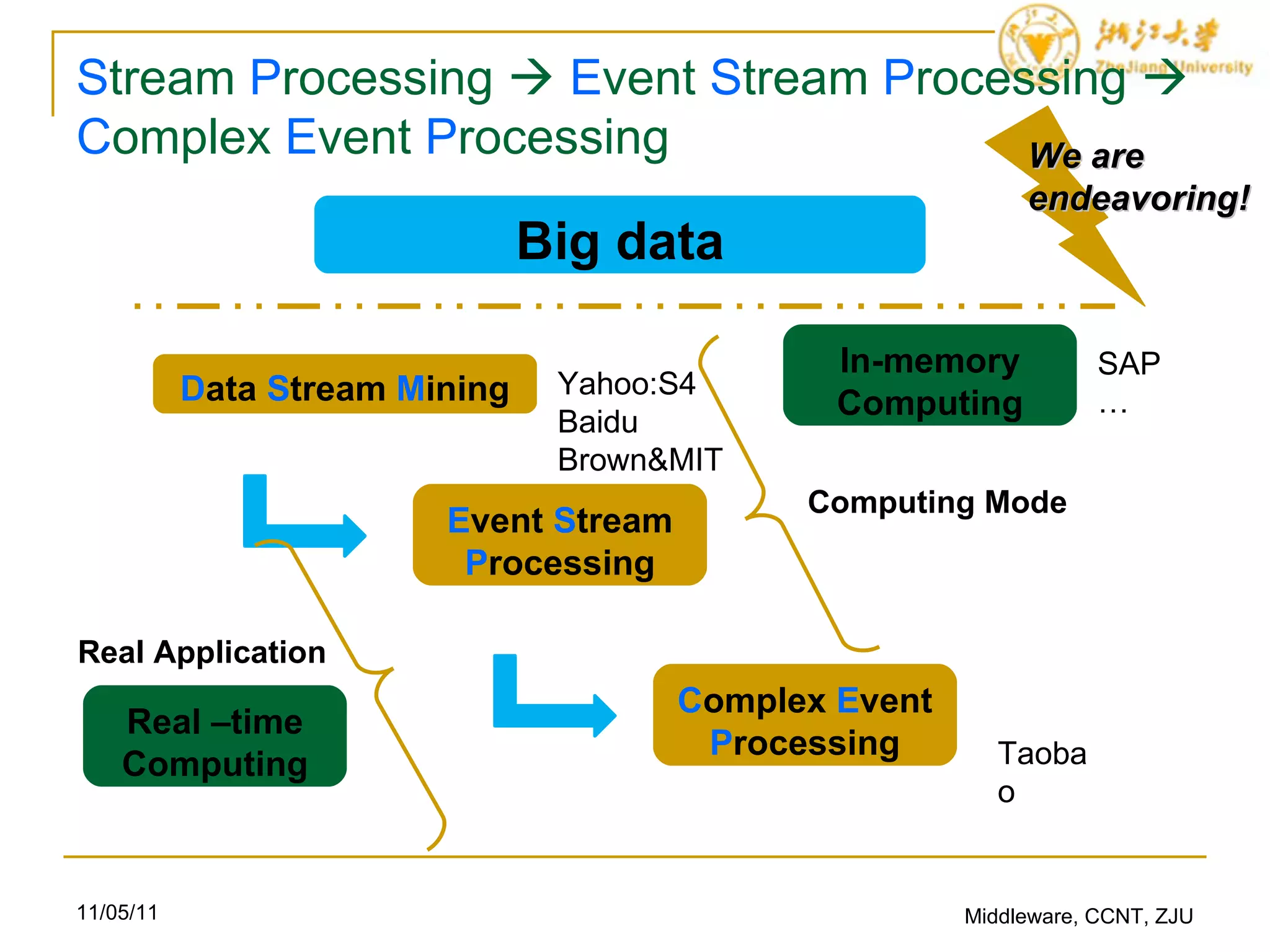














This document summarizes a framework for clustering evolving data streams. The framework uses micro-clusters to represent subsets of data points and clusters micro-clusters into macro-clusters over different time horizons. Micro-clusters are represented by cluster feature vectors (CFVs) and are updated when new data points arrive by joining, deleting, or merging micro-clusters. Macro-clusters are formed by applying a modified k-means algorithm that clusters micro-clusters represented by their CFVs over different time periods.











![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































































