Downloaded 62 times





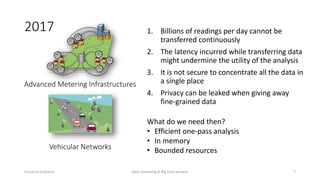

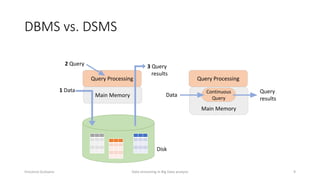

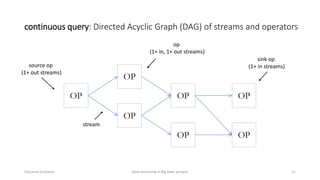

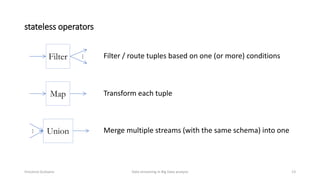


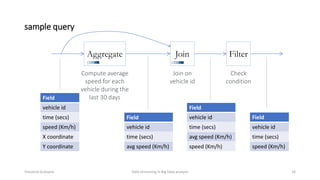


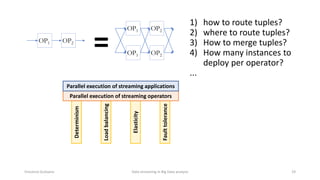

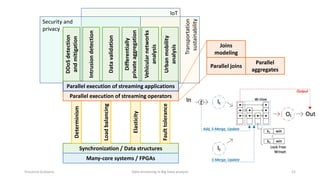
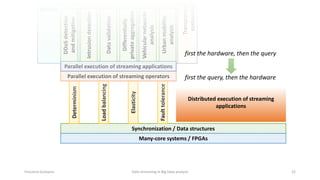










The document outlines key concepts and research related to data streaming in big data analysis, emphasizing its importance for real-time data processing. It discusses the evolution of data streaming technologies, highlighting challenges such as latency, security, and privacy, and introduces various data processing operators and techniques. The presentation also touches upon future research directions and applications in fields like vehicular networks and smart infrastructures.

















































![Human Reproduction [ Reproductive System ] Notes @irfanullah_mehar Irfanullah...](https://cdn.slidesharecdn.com/ss_thumbnails/humanreproductionreproductivesystemnotesirfanullahmeharirfanullahmeharjanantantra-260111172350-56e85778-thumbnail.jpg?width=640&height=640&fit=bounds)

















