Download to read offline



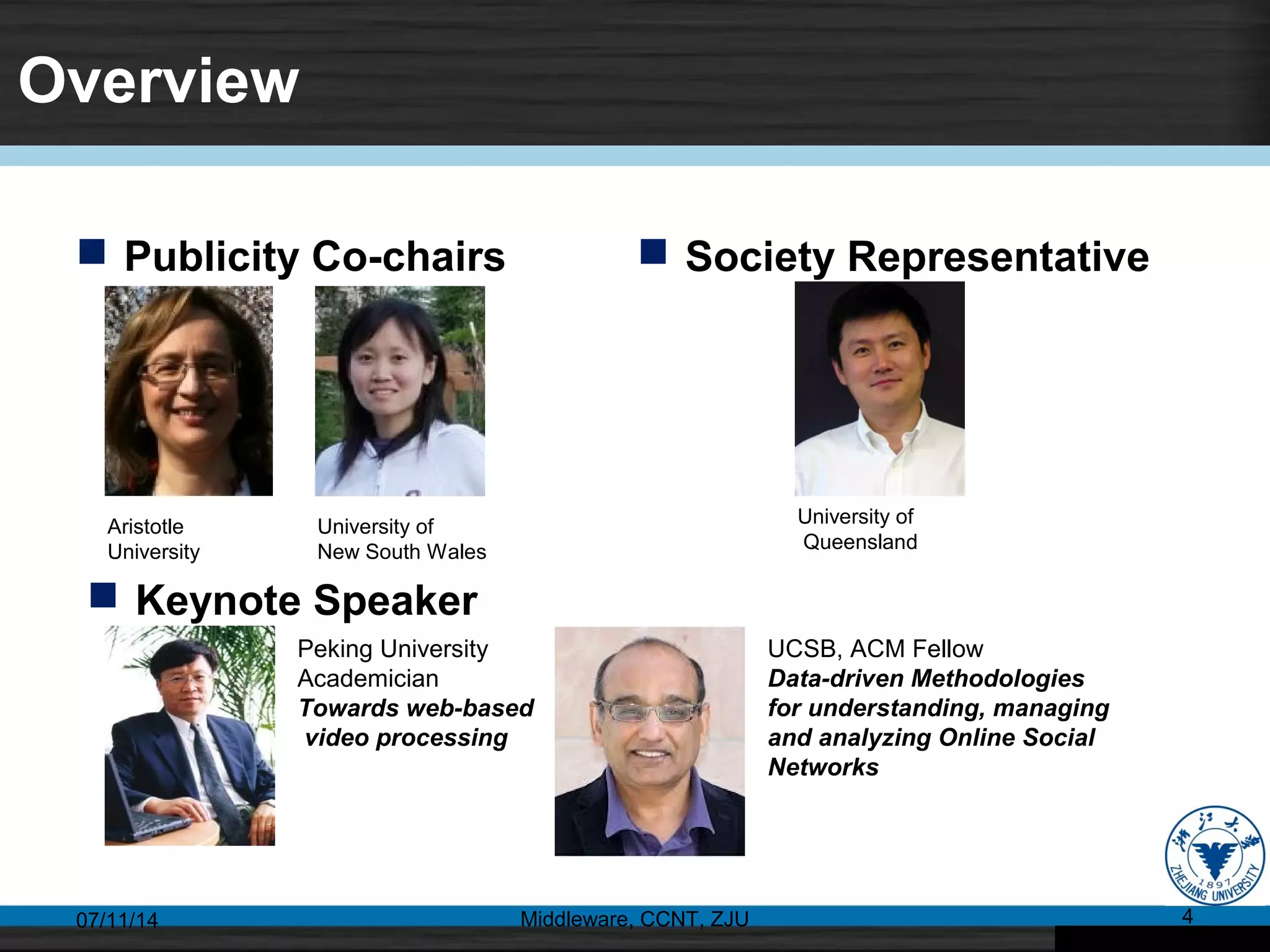












The 14th International Conference on Web Information System Engineering (WISE 2013) took place in Nanjing, China, from October 13 to 15, 2013, featuring 48 research papers with a 24% acceptance rate from 38 countries. Keynotes addressed topics from web-based video processing to big data security, while sessions included various areas such as web mining, recommendation systems, and social networks. The conference also showcased innovative algorithms and frameworks for improving web applications across multiple domains.


















![Community Finding with Applications on Phylogenetic Networks [Extended Abstract]](https://cdn.slidesharecdn.com/ss_thumbnails/extendedabstract-190703140727-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)












