
![Pavlo Baron http://www.pbit.org [email_address] @pavlobaron](https://image.slidesharecdn.com/efs11baronbigdataandnosql2-110711132400-phpapp01/75/Big-Data-NoSQL-EFS-11-Pavlo-Baron-2-2048.jpg)








































































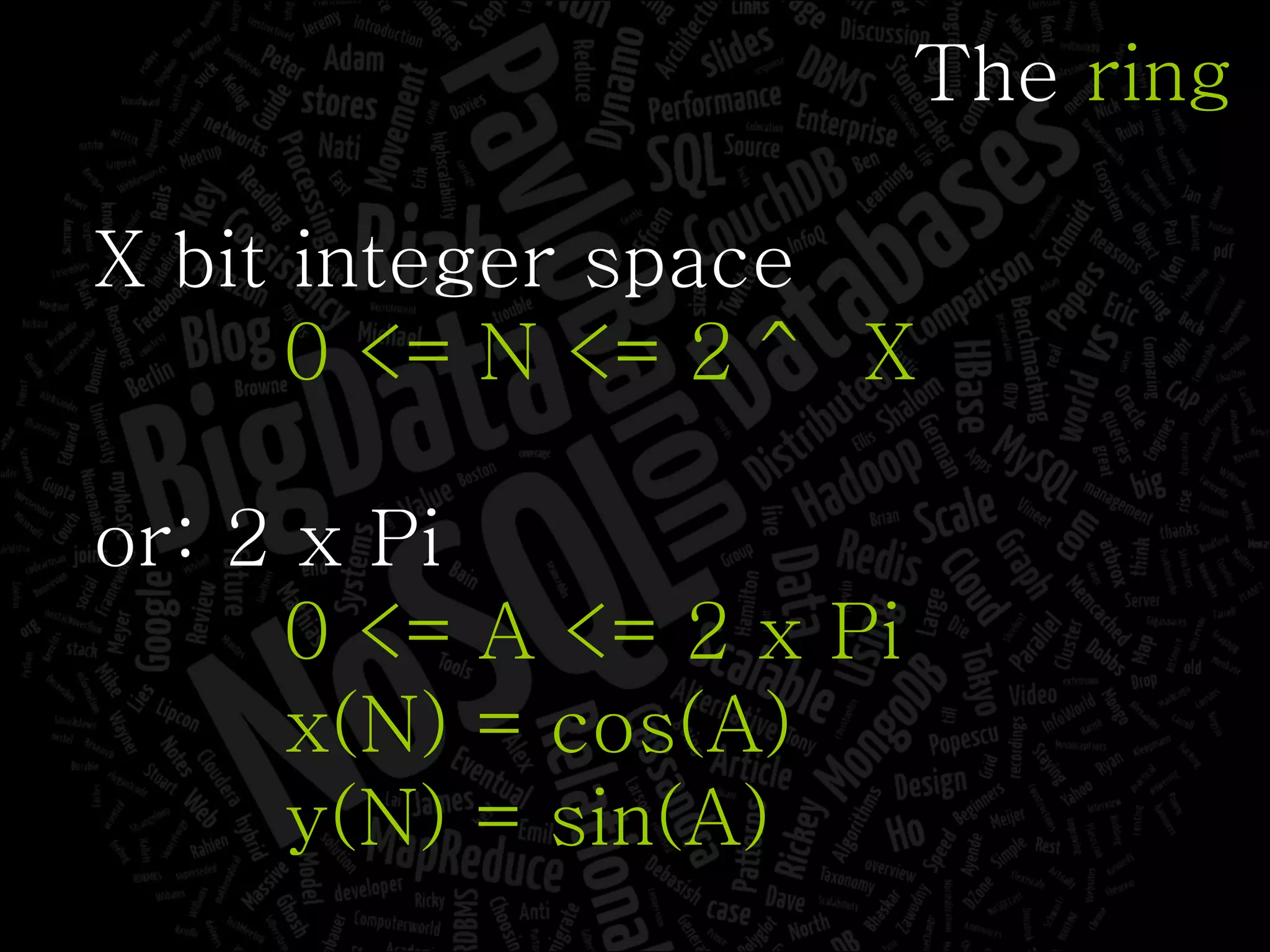


















![Value based storage 1:1, 3:Peter, 5:London, 2:2, 4:Anna, 6:Paris, 7:[1, 3, 5], 8:[2, 4, 6] data store ID Name City 1 Peter London 2 Anna Paris](https://image.slidesharecdn.com/efs11baronbigdataandnosql2-110711132400-phpapp01/75/Big-Data-NoSQL-EFS-11-Pavlo-Baron-142-2048.jpg)




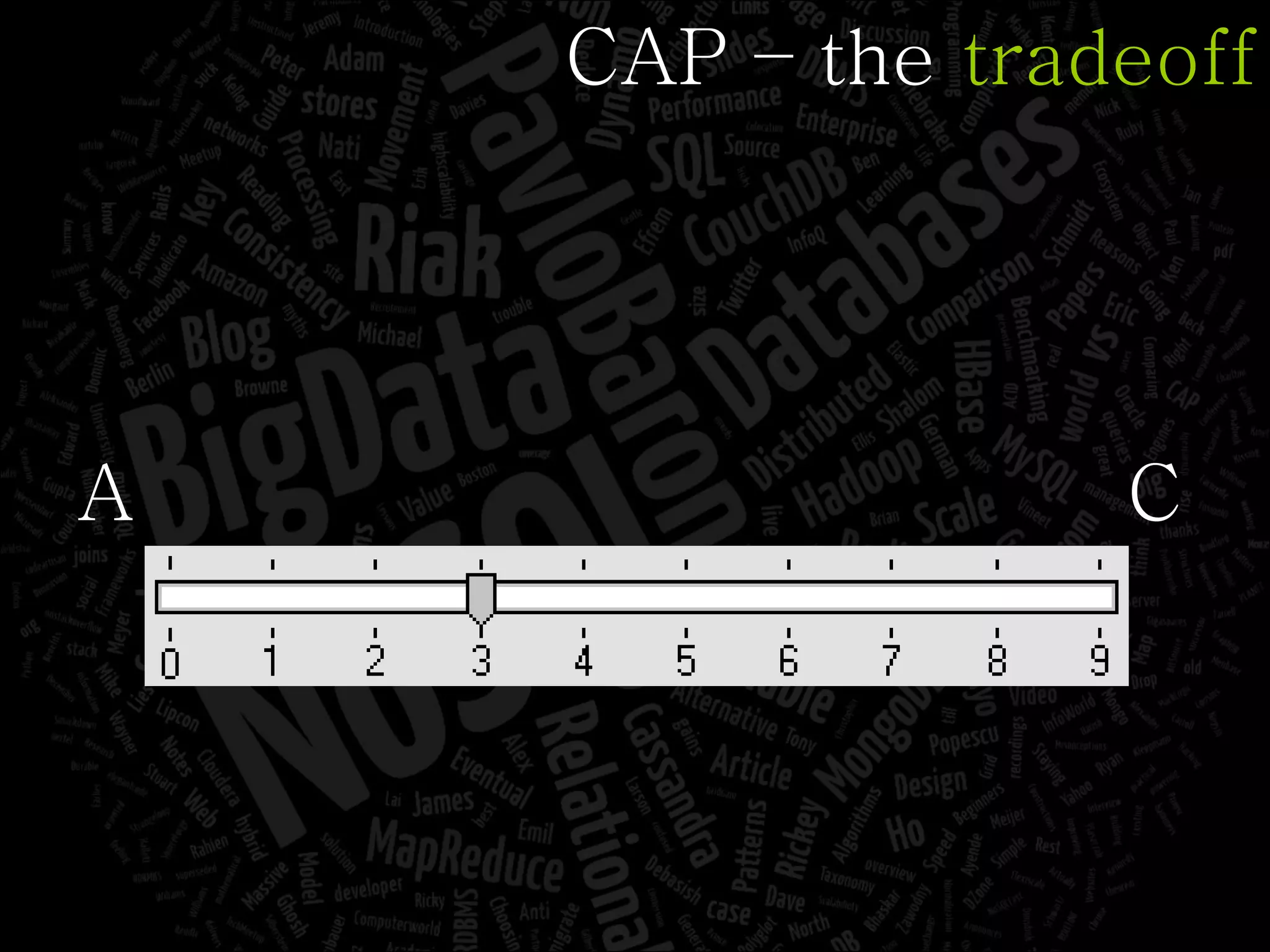
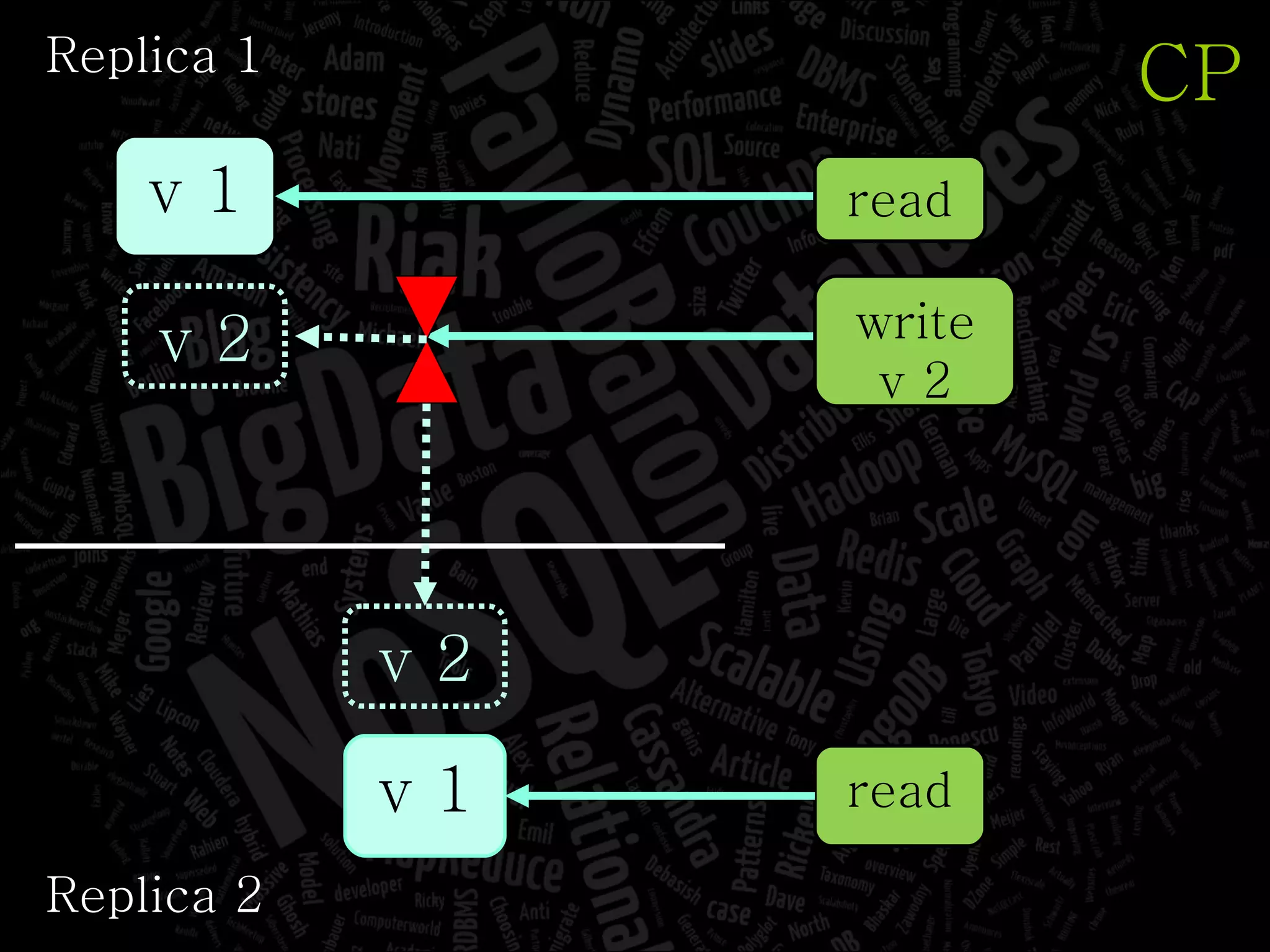
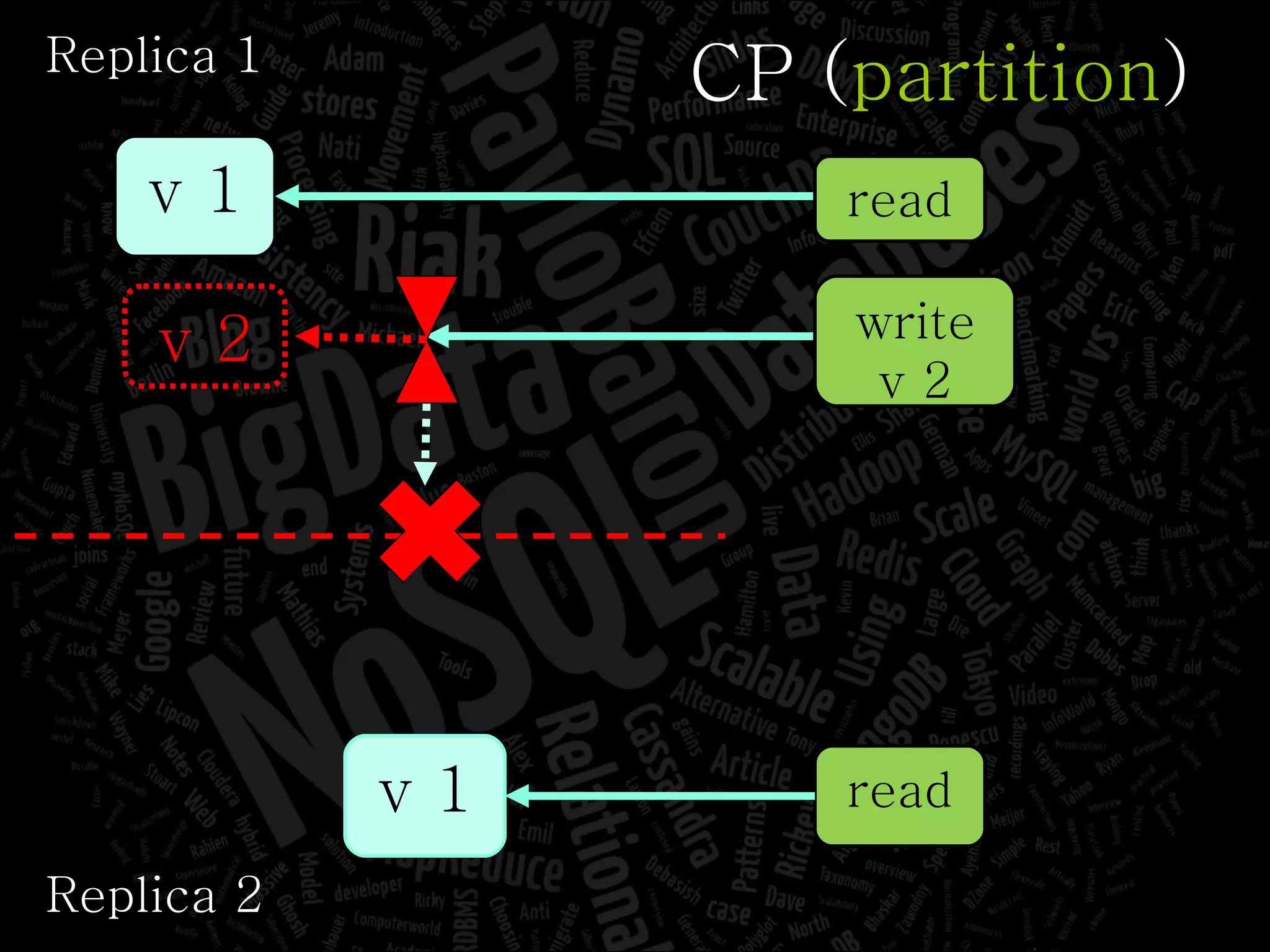
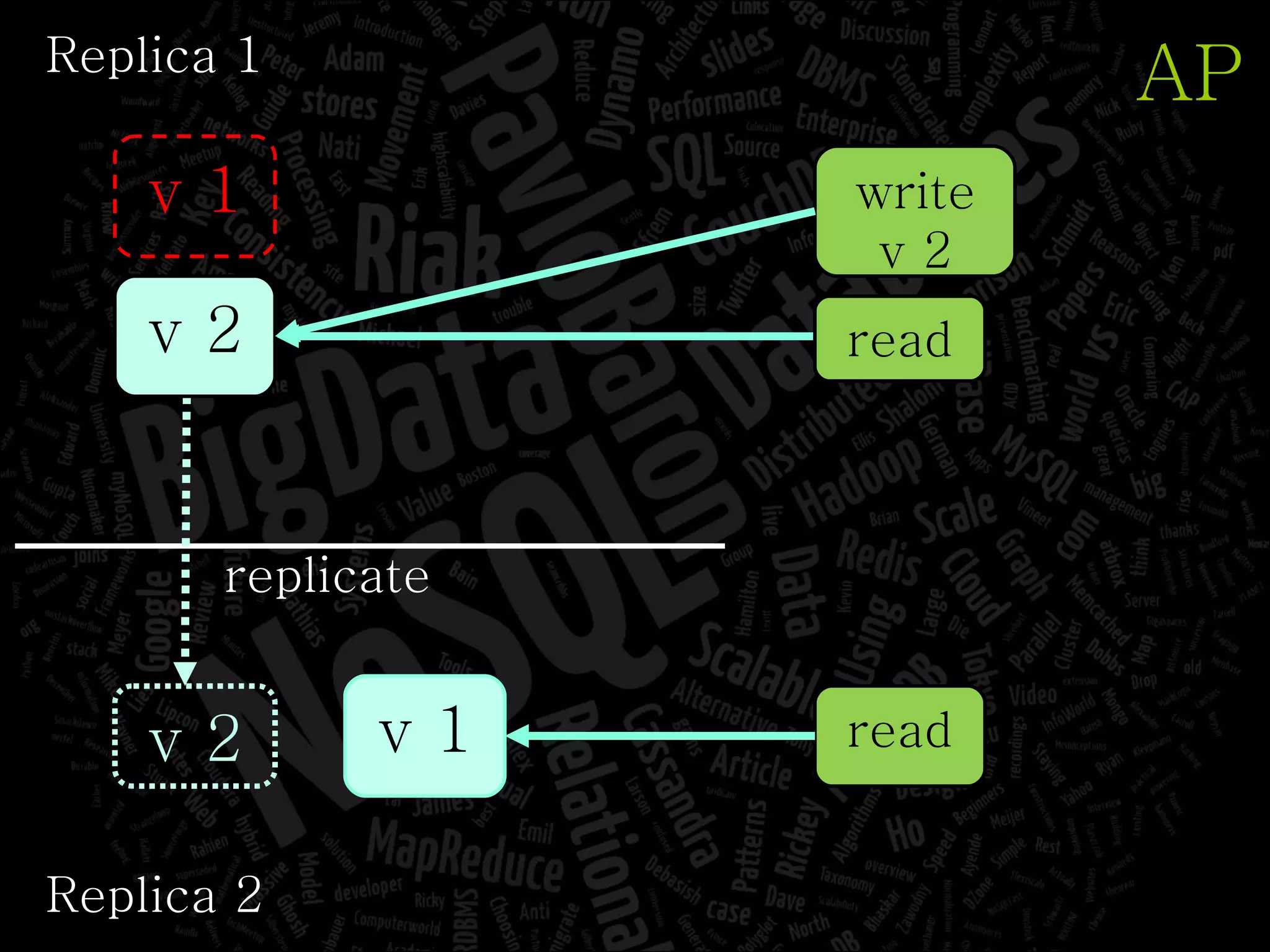
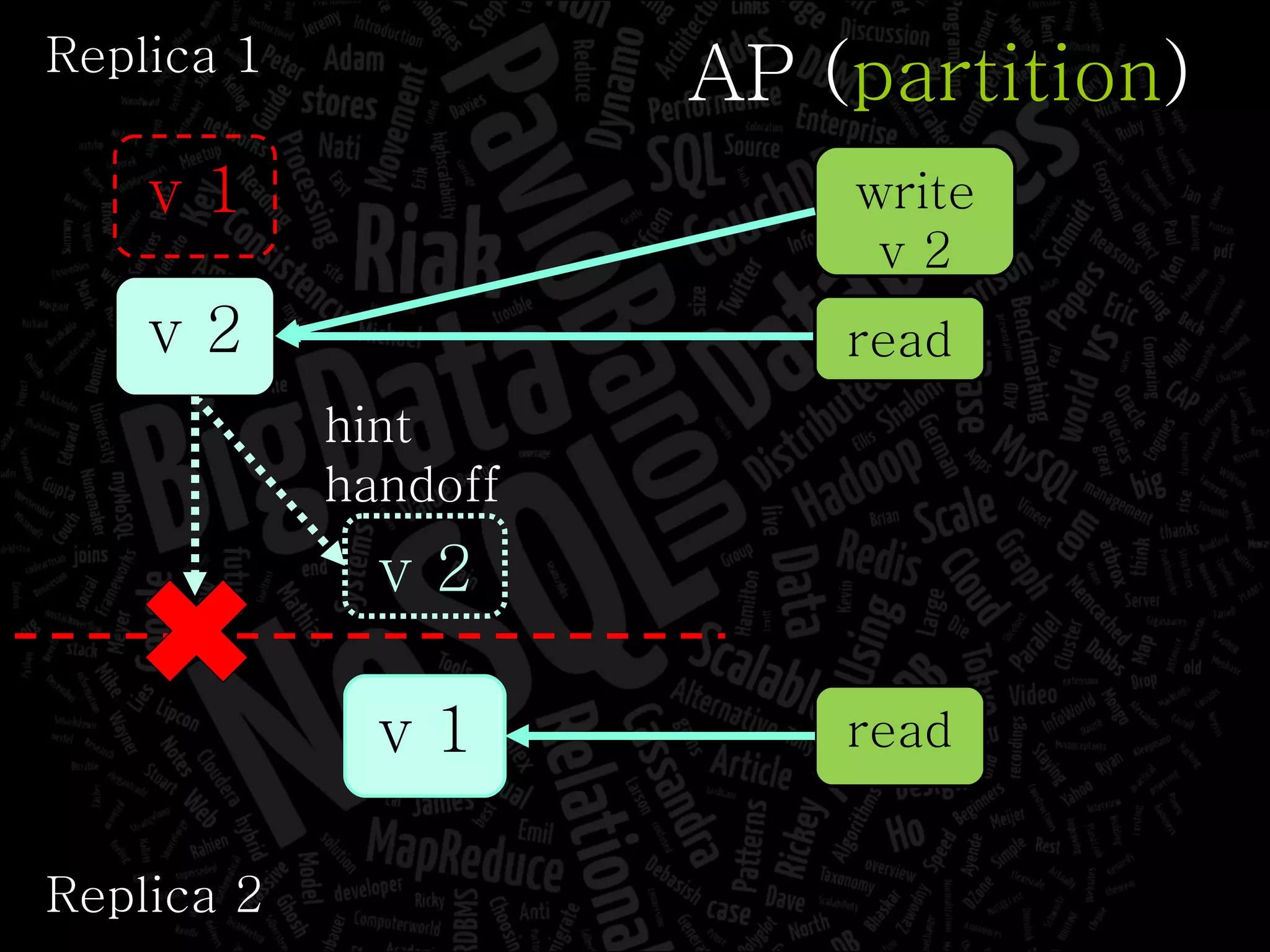
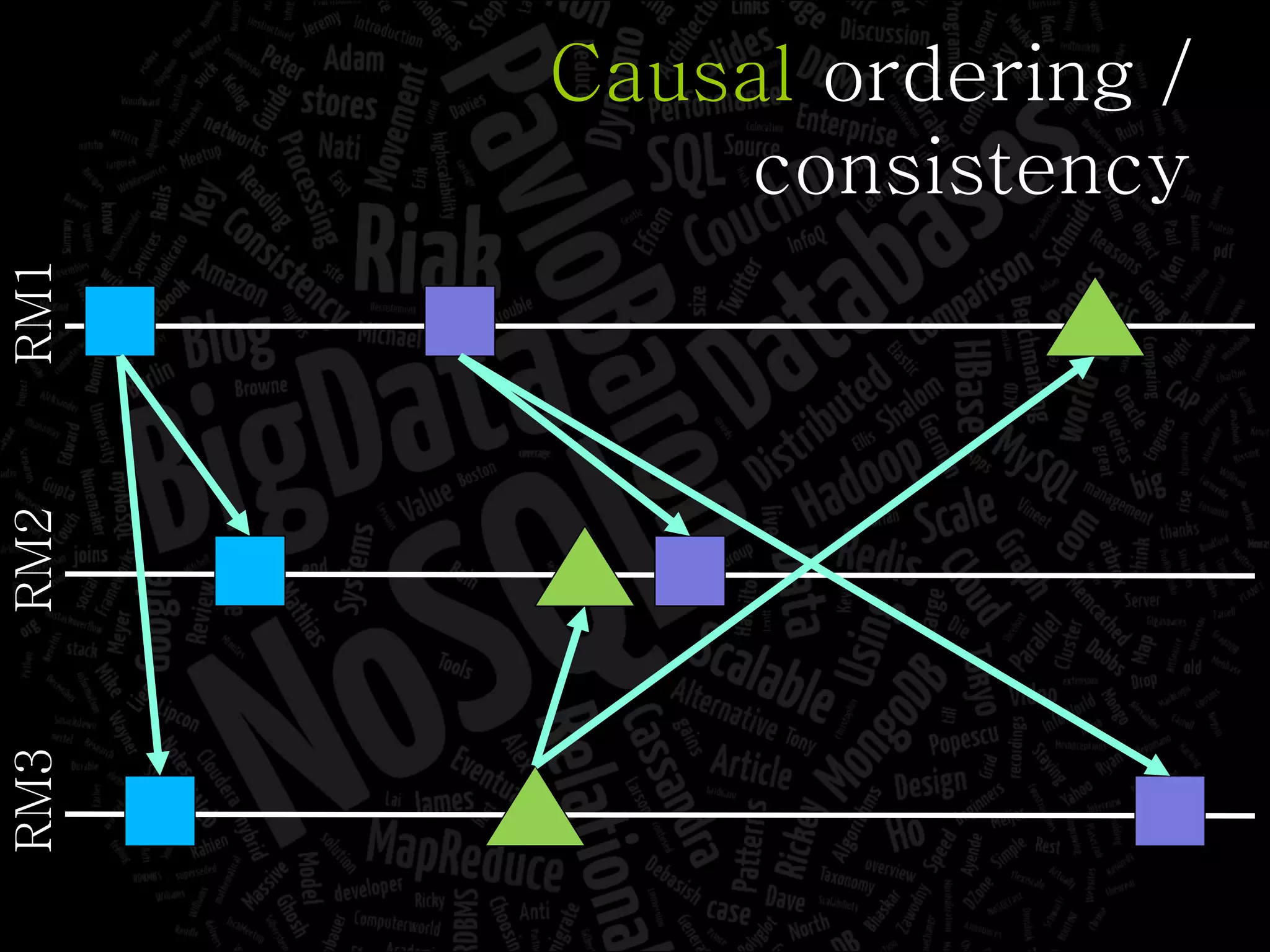
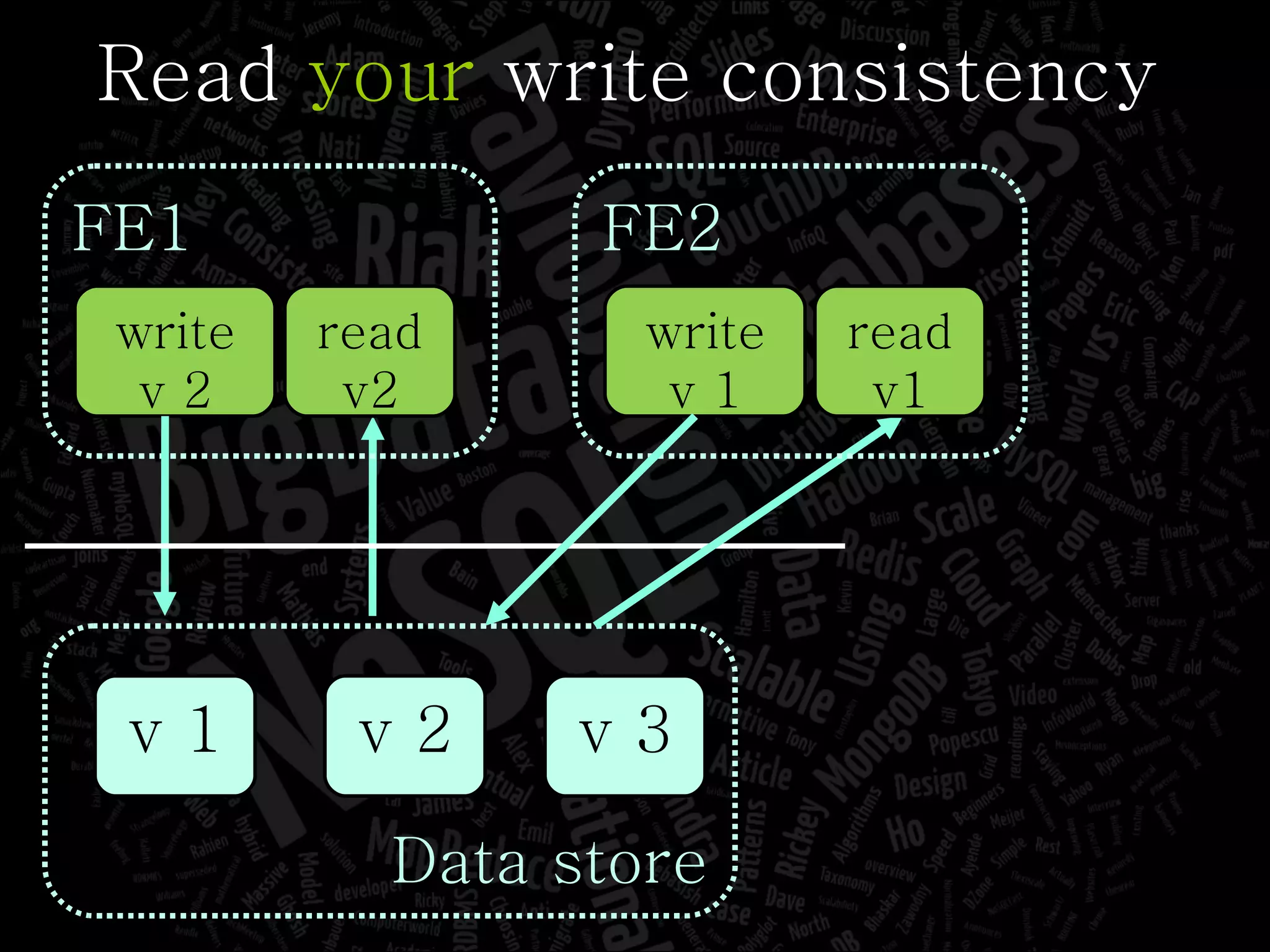
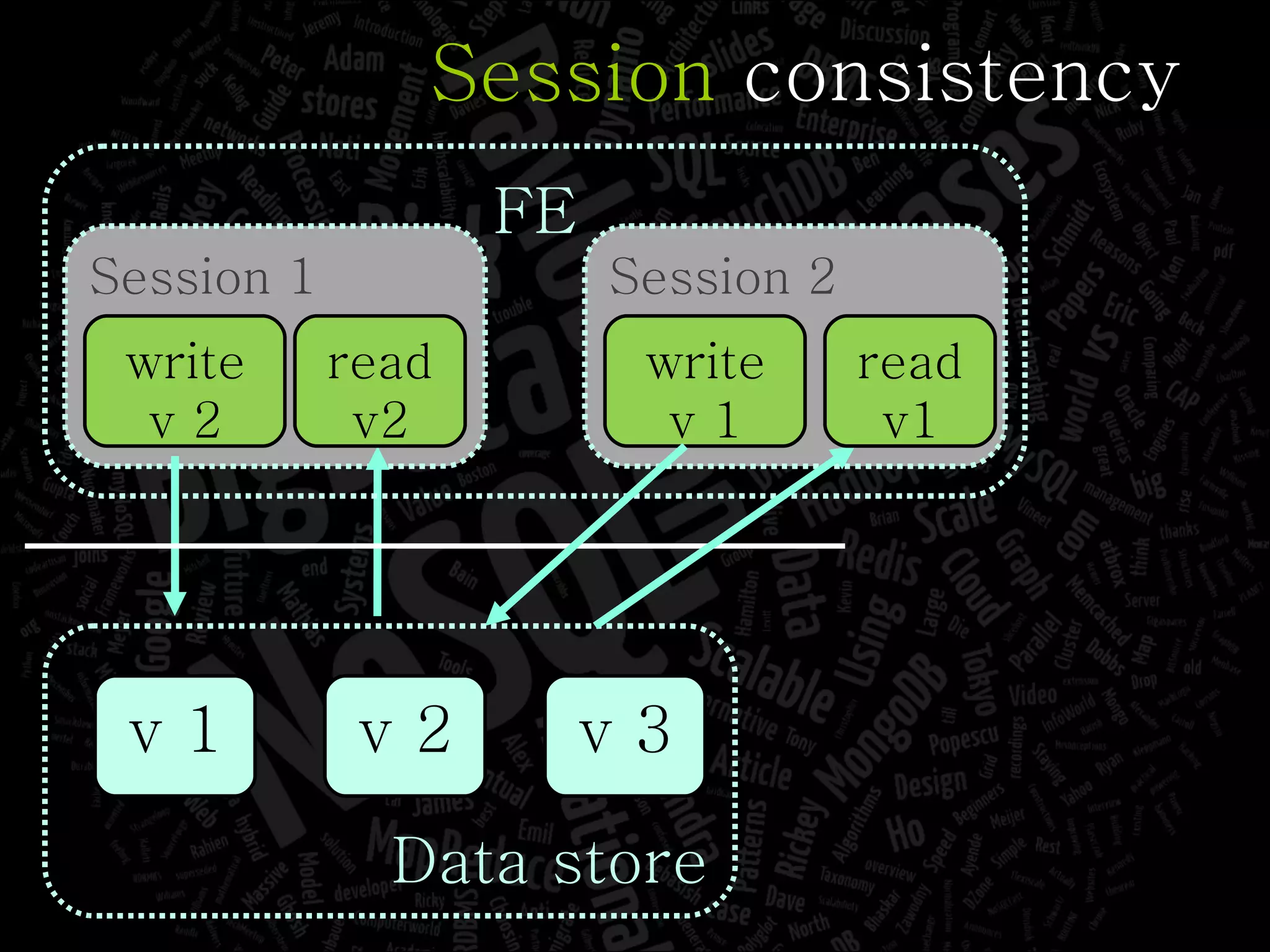
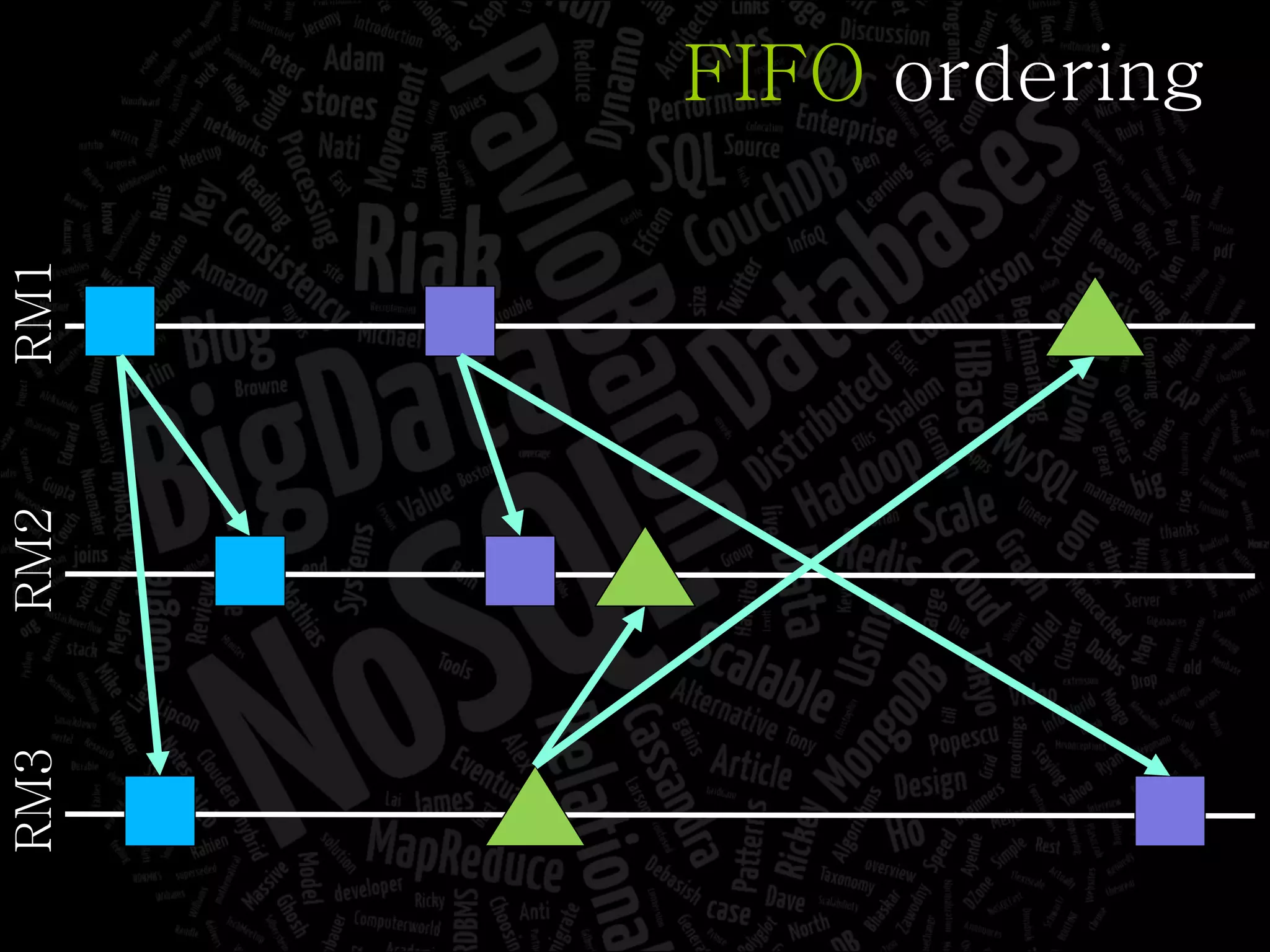
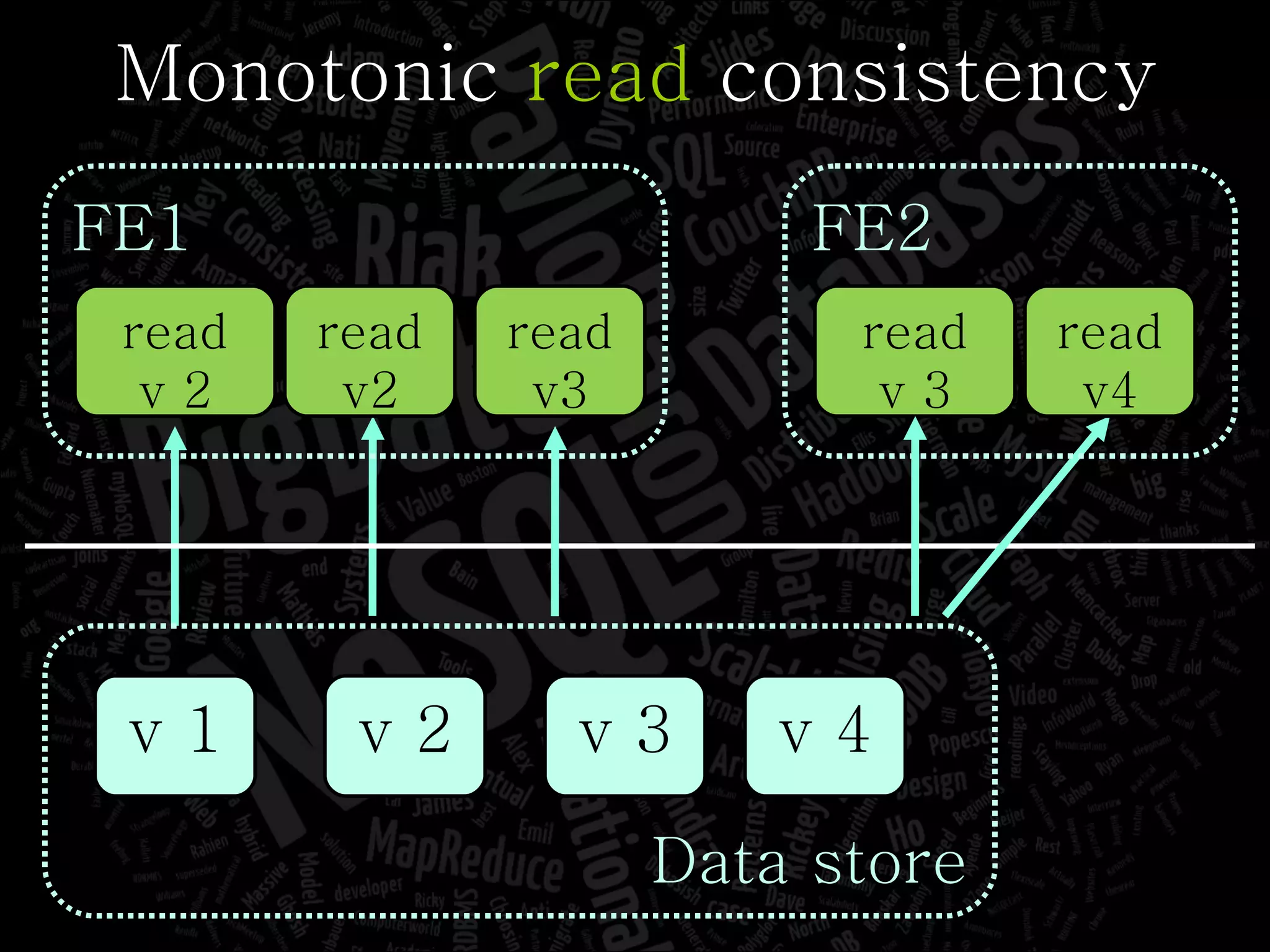
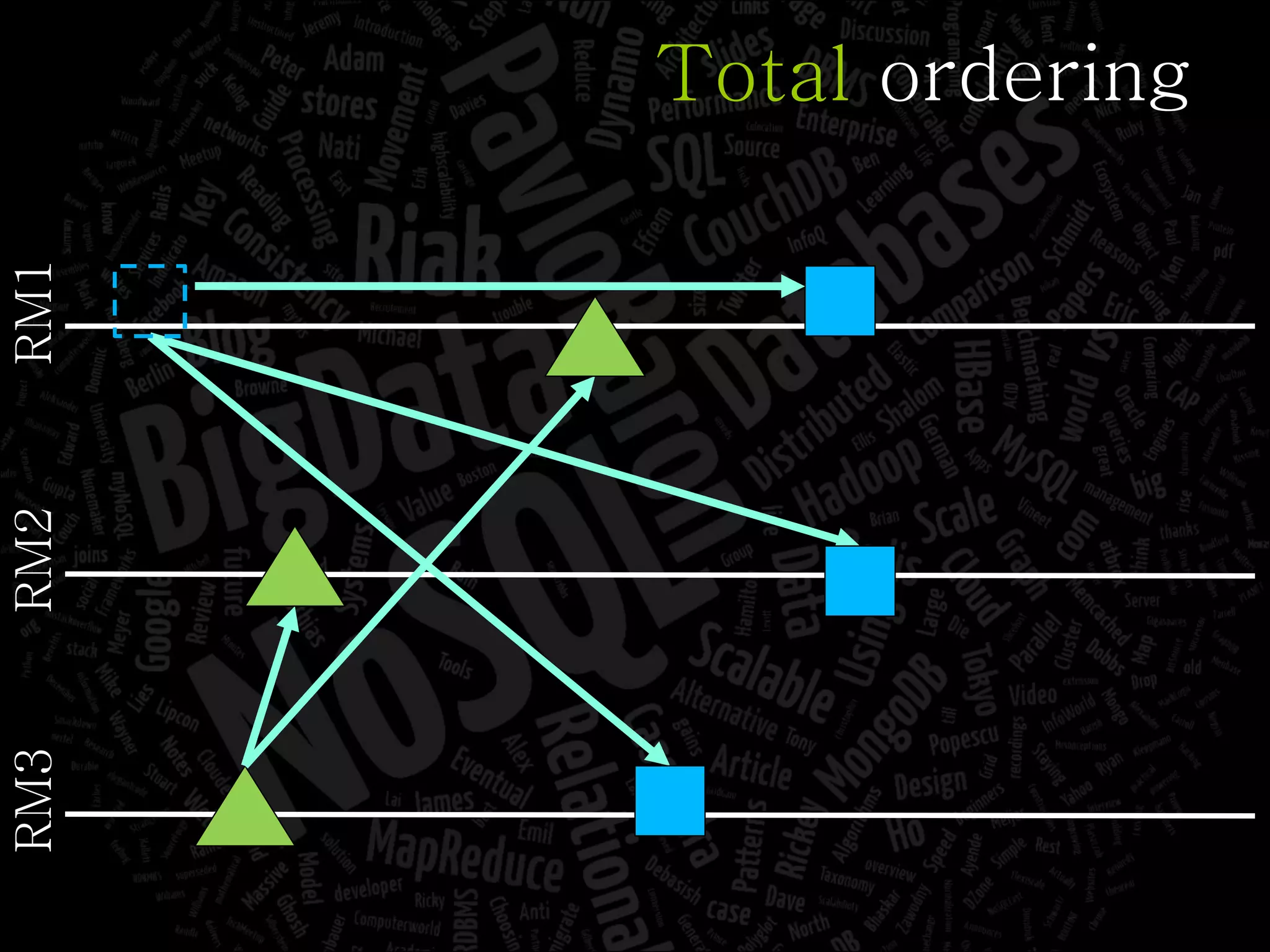
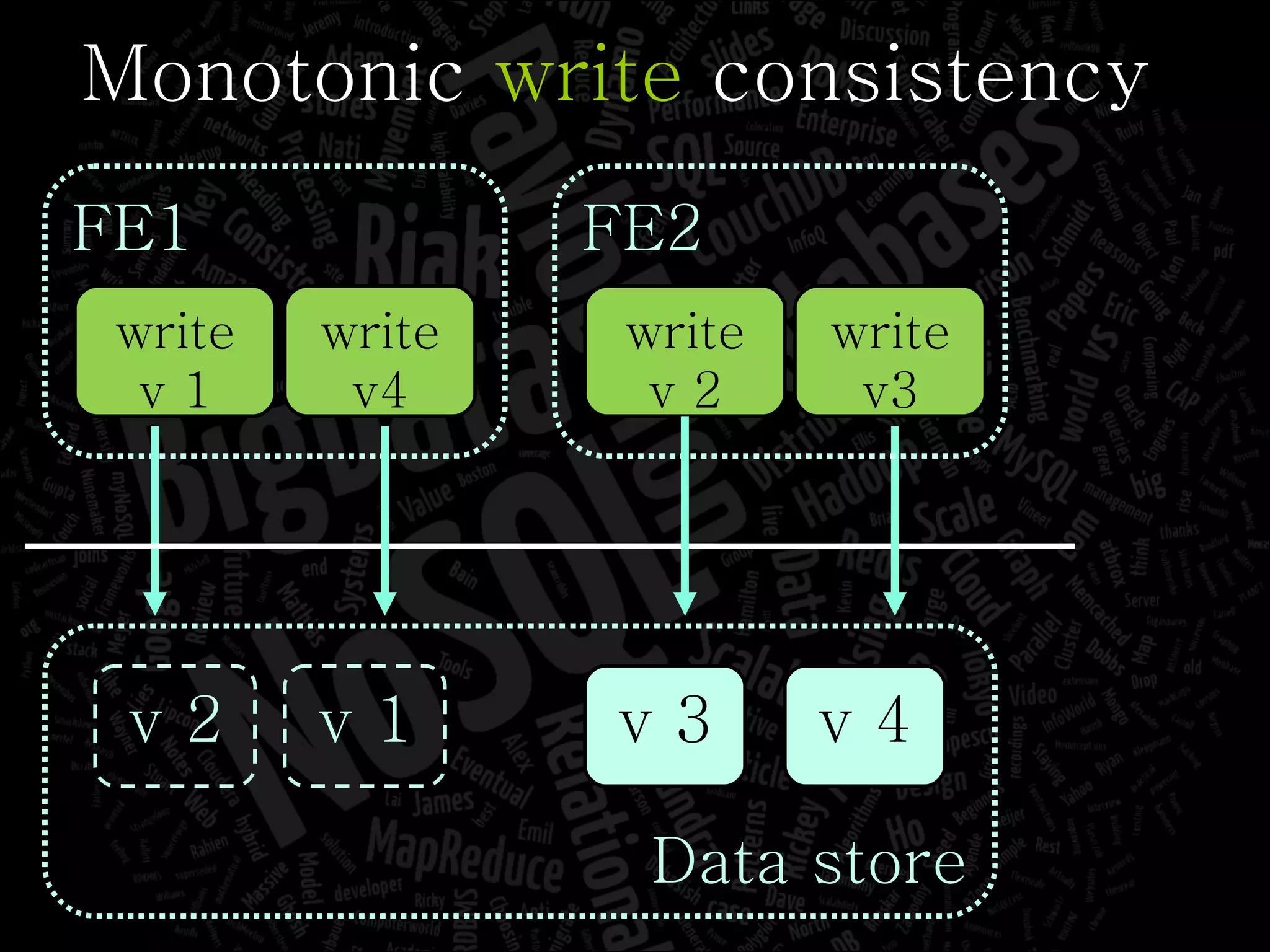
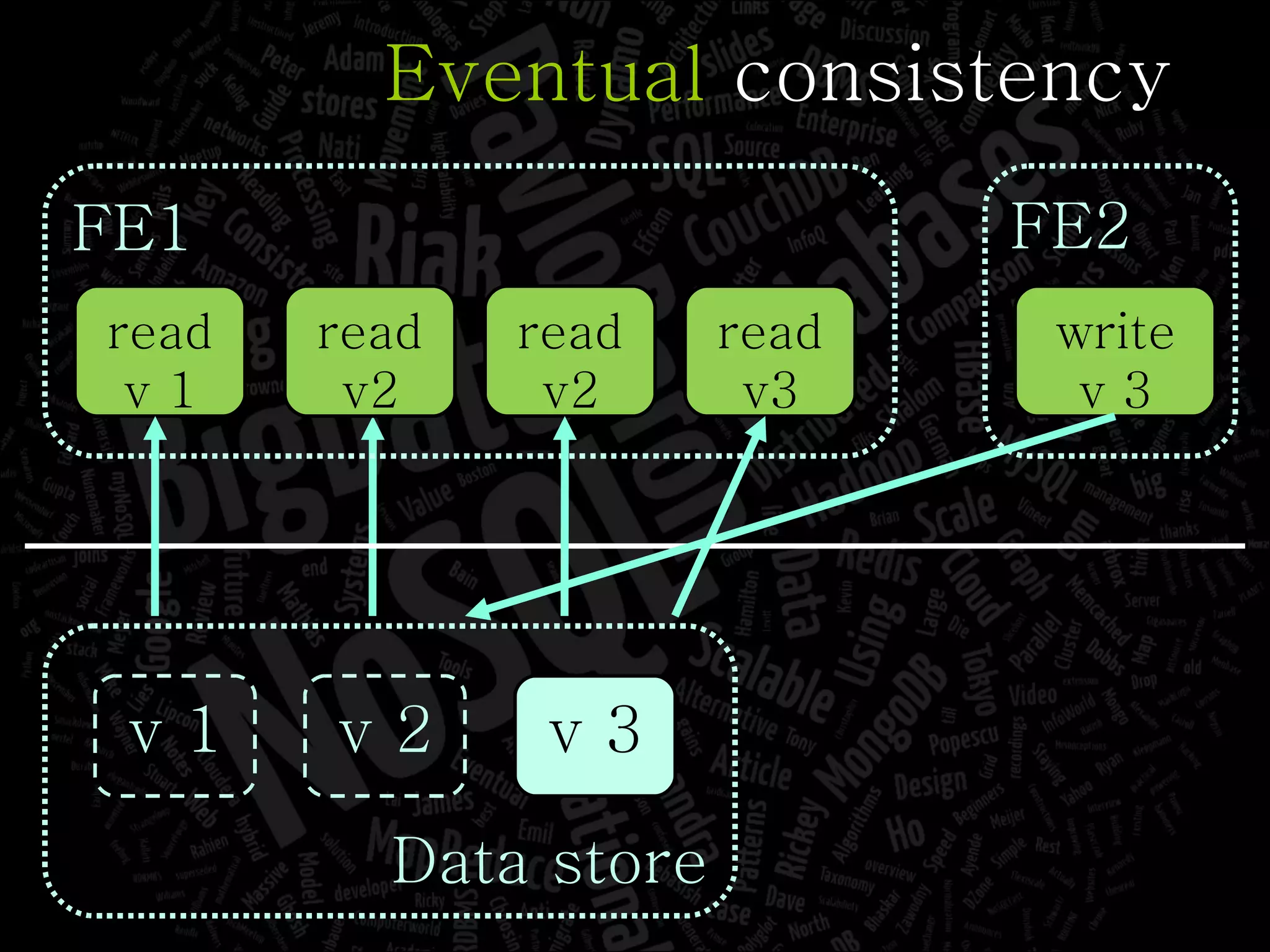
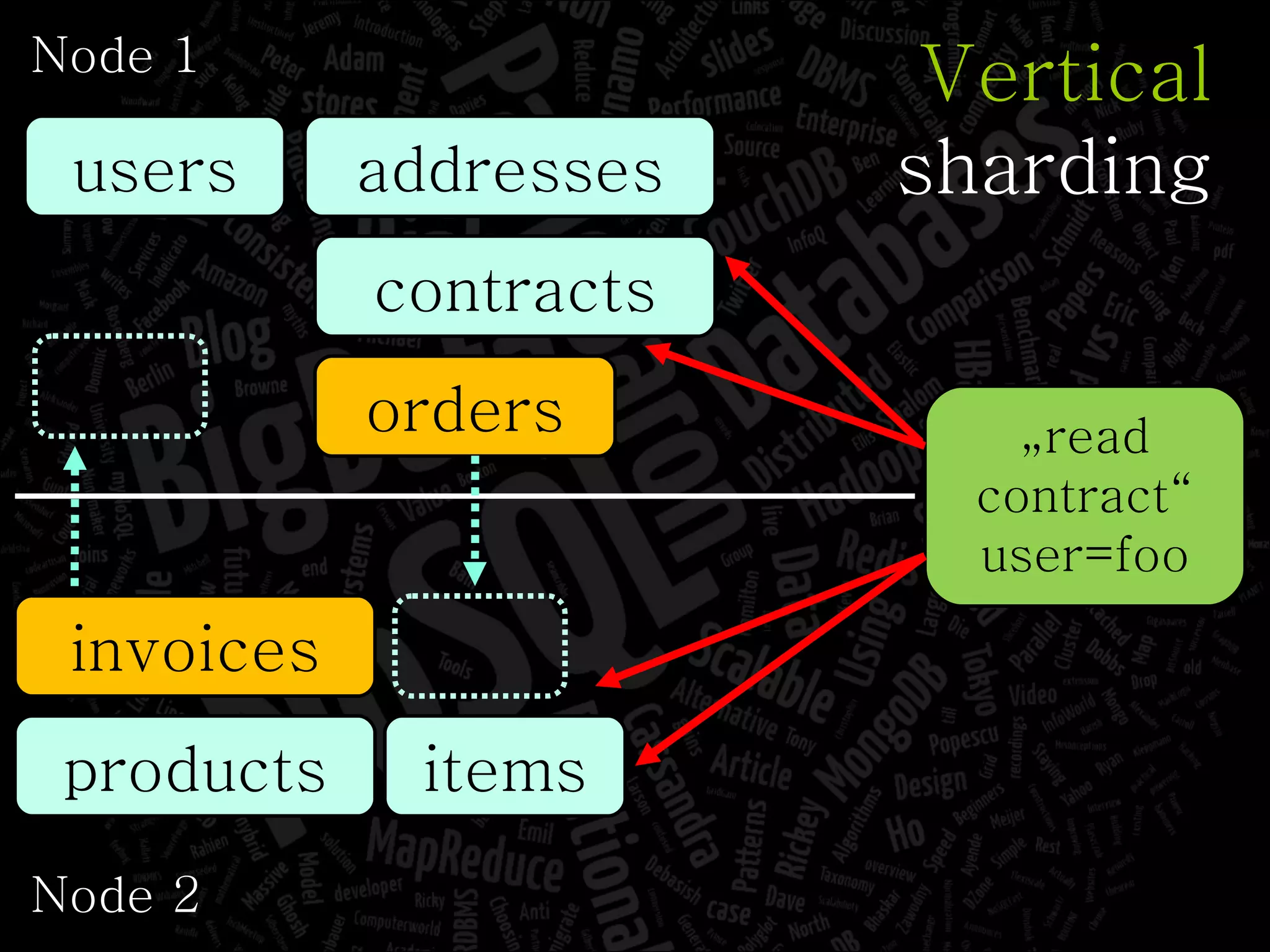
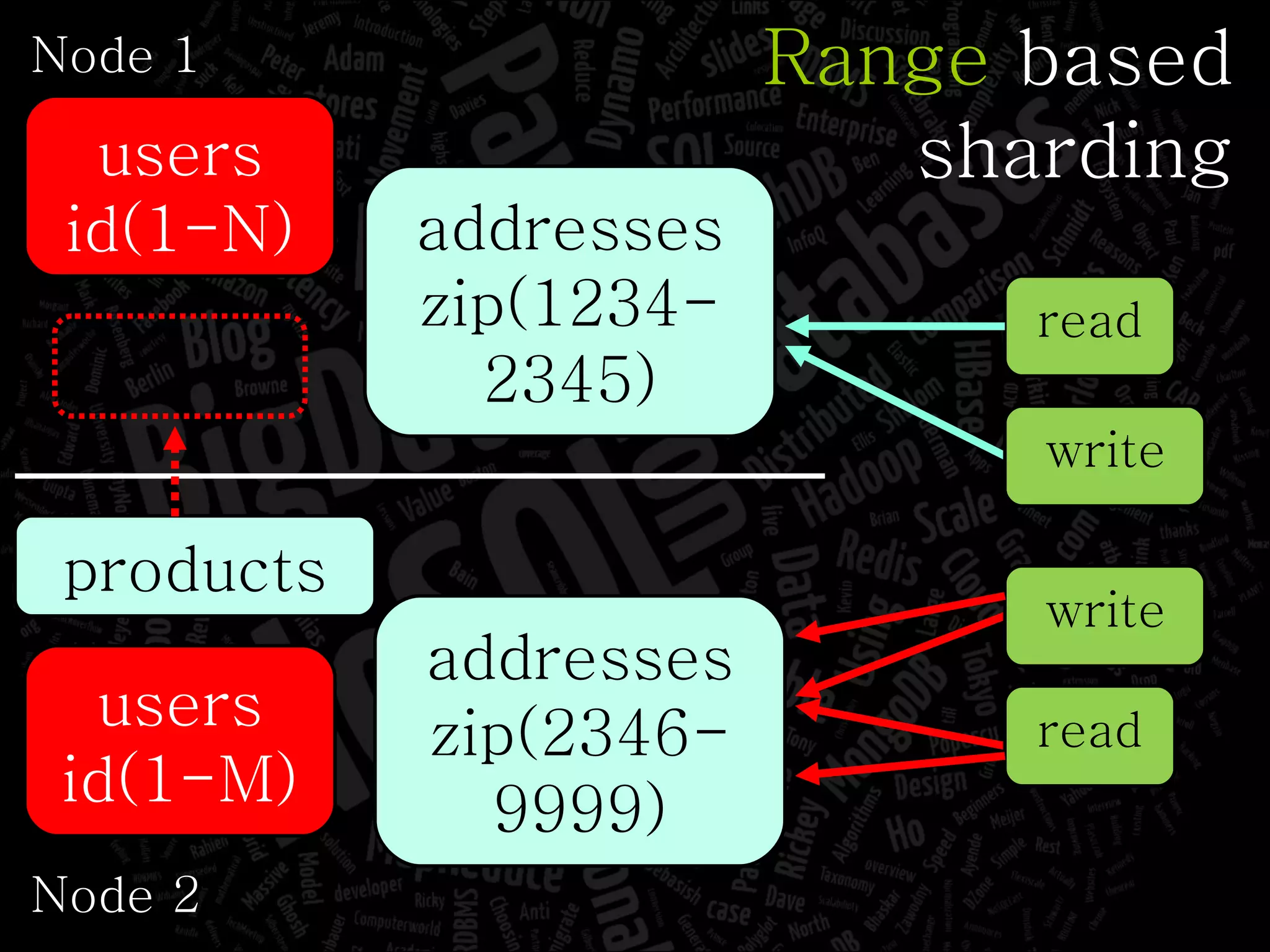
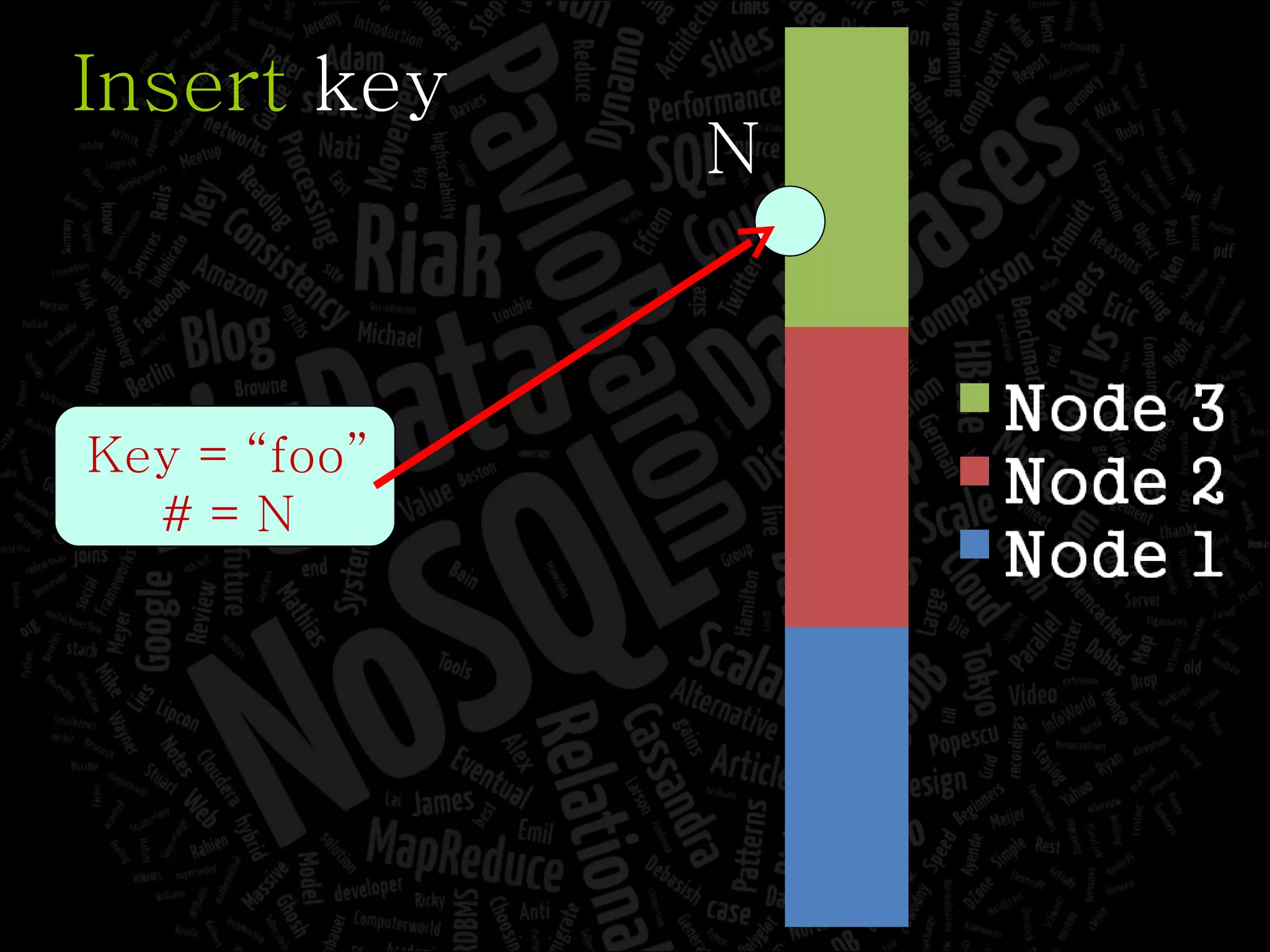
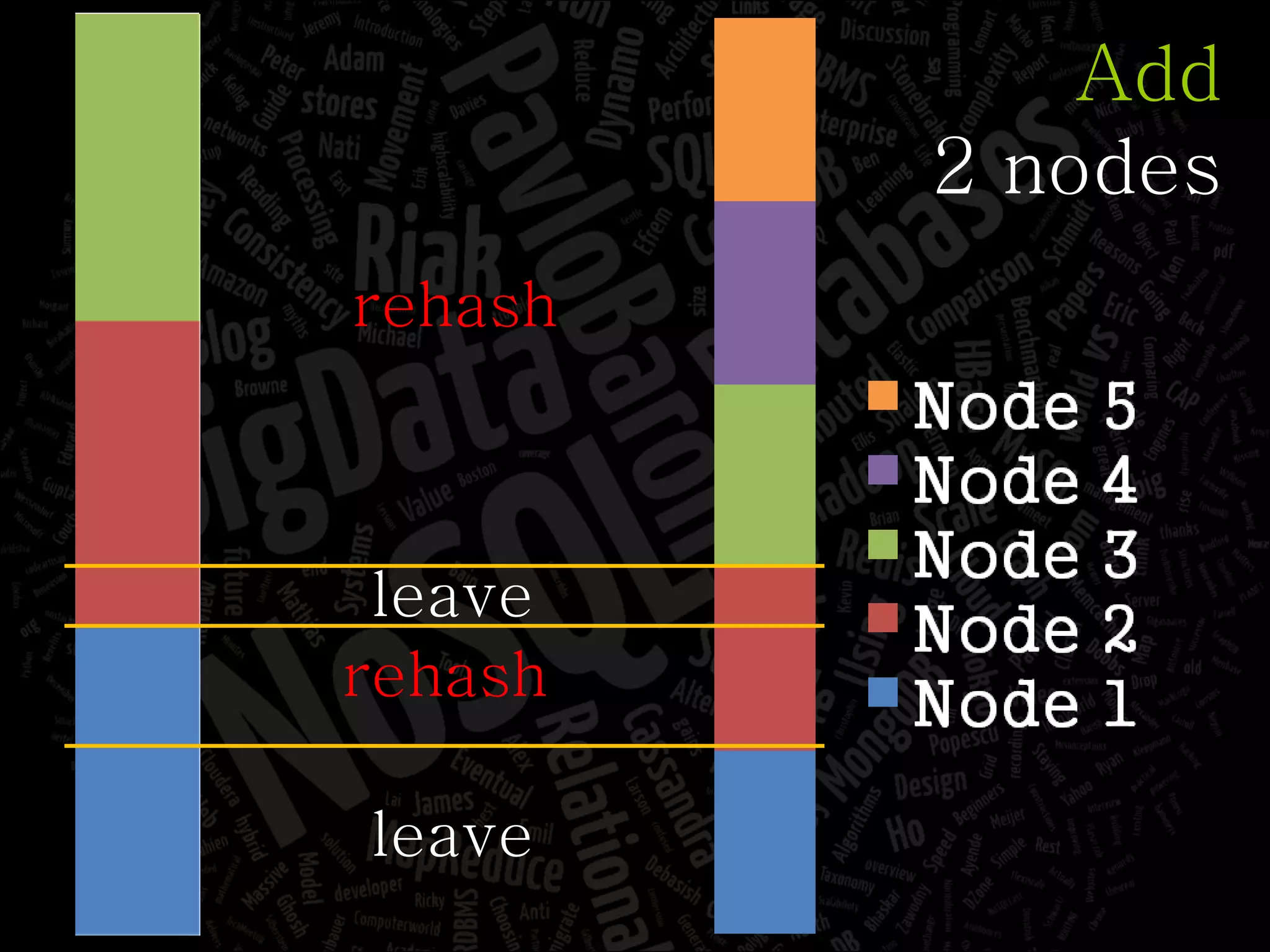
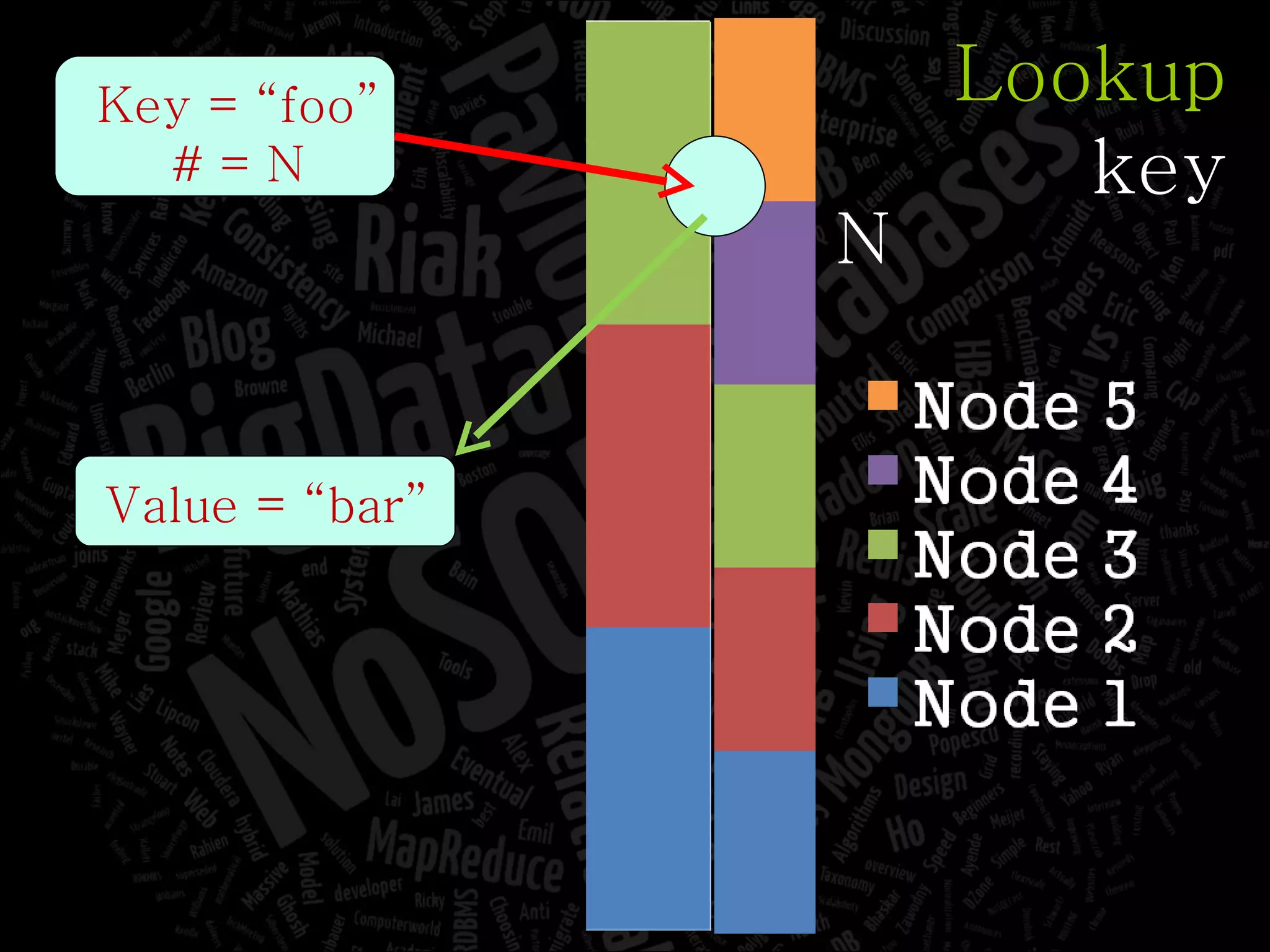
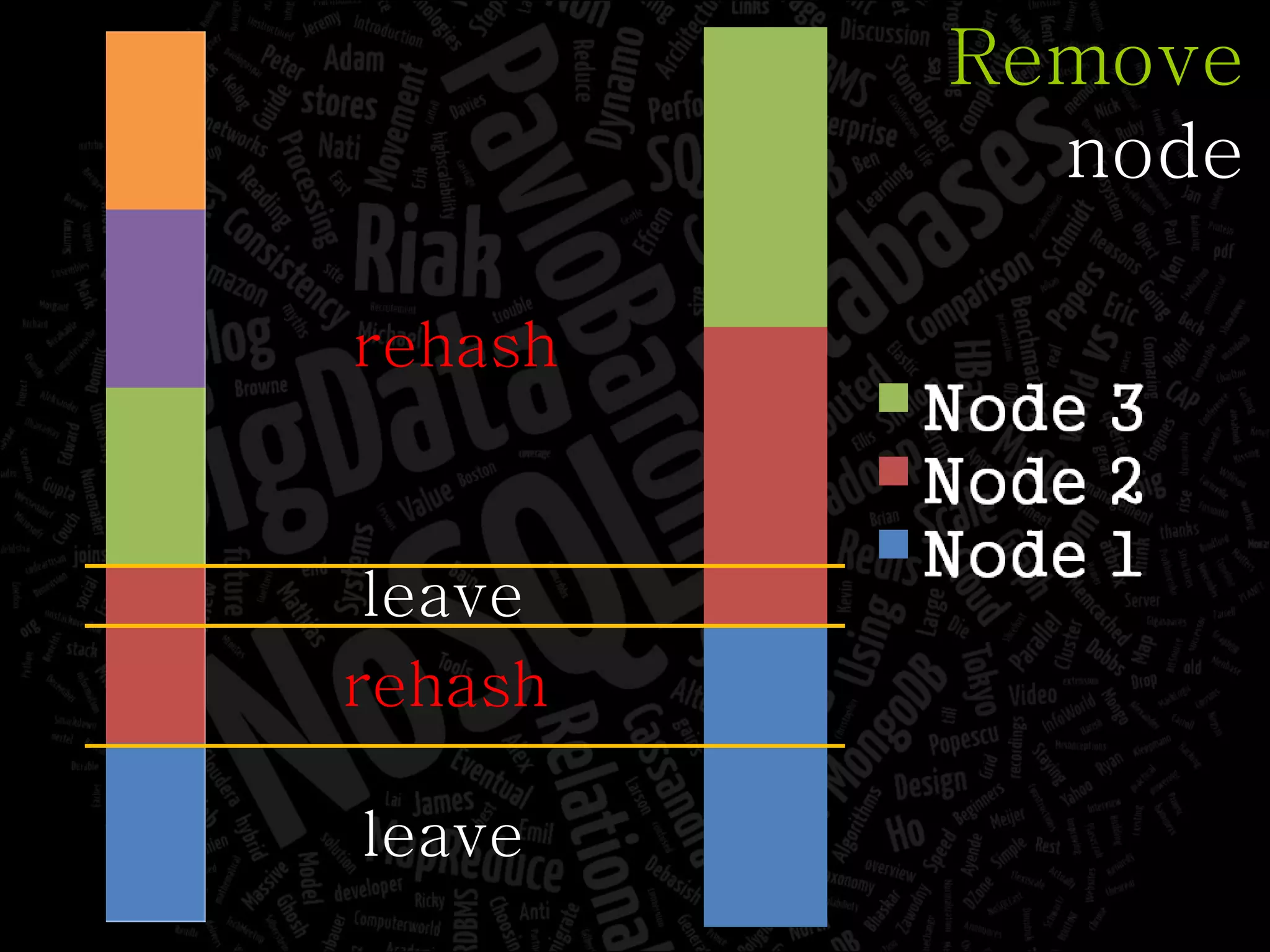
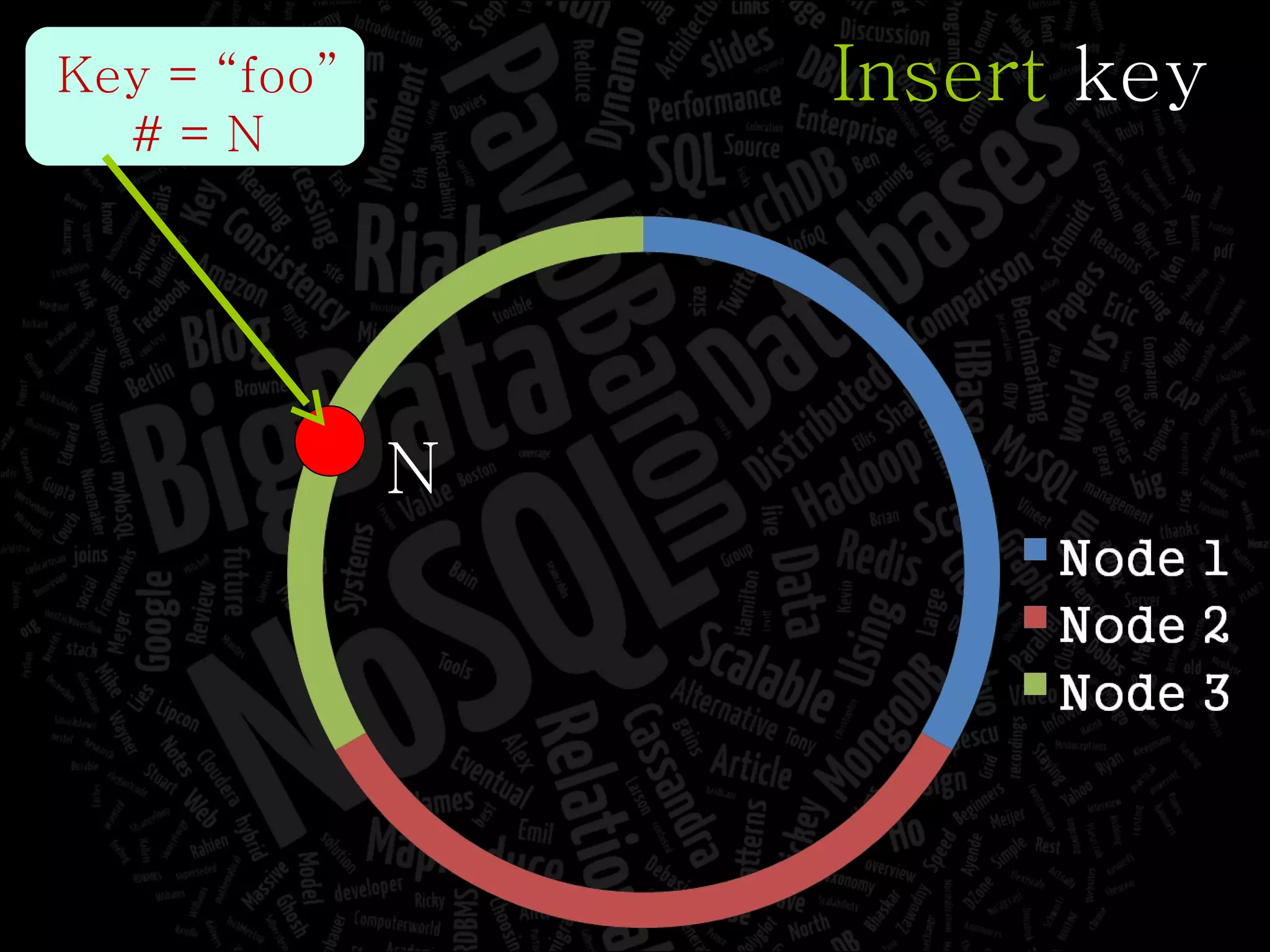
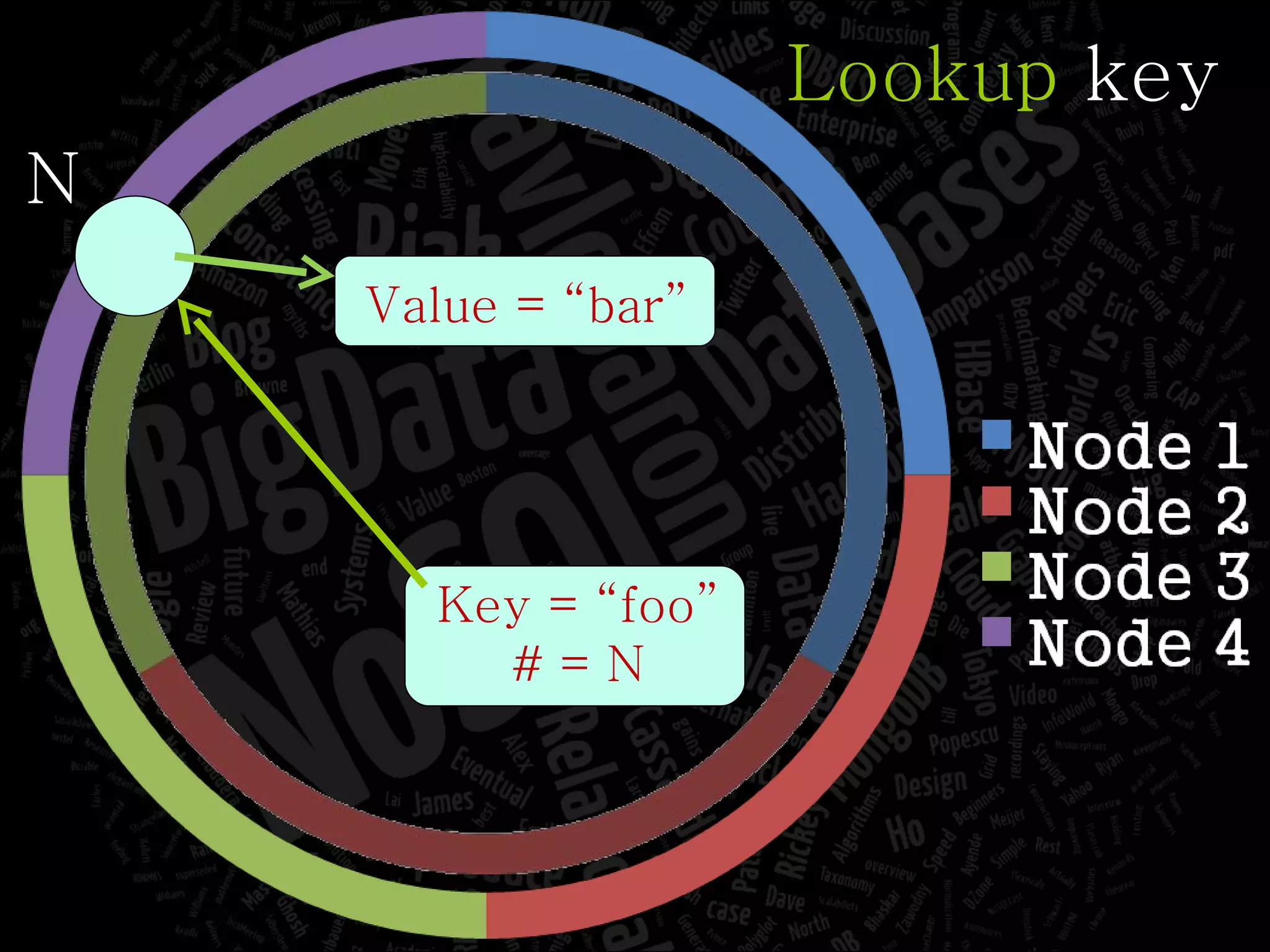
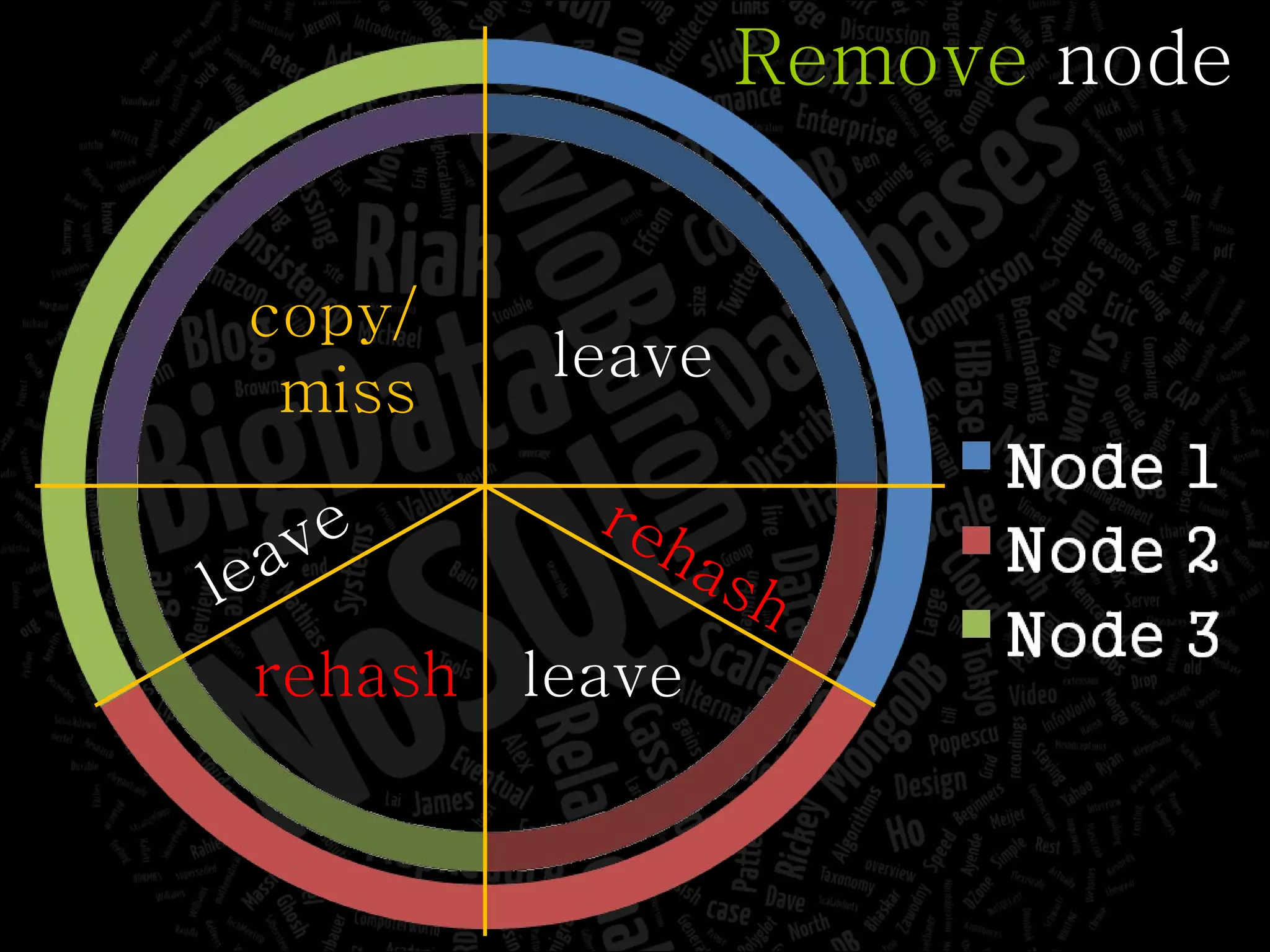
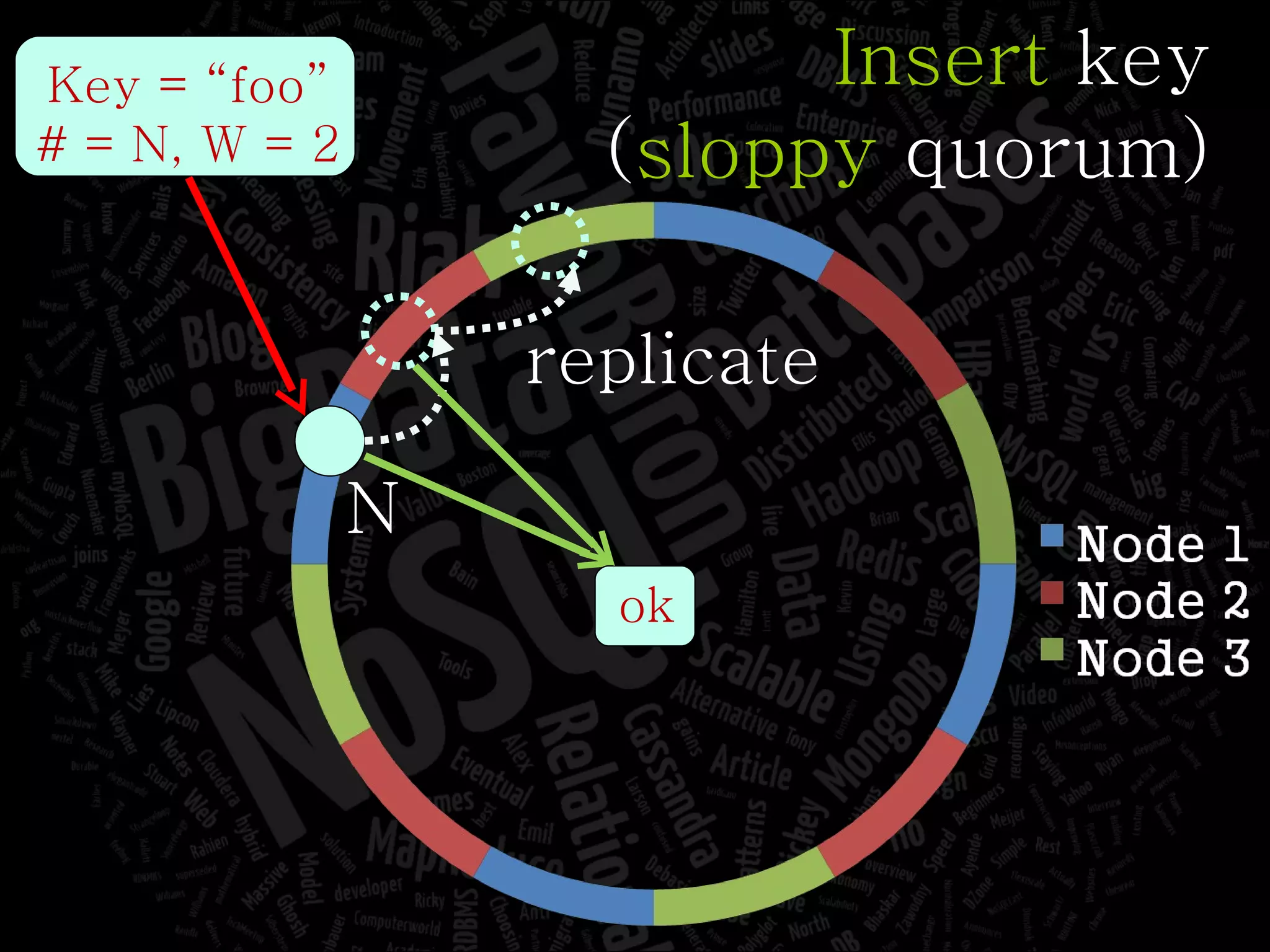
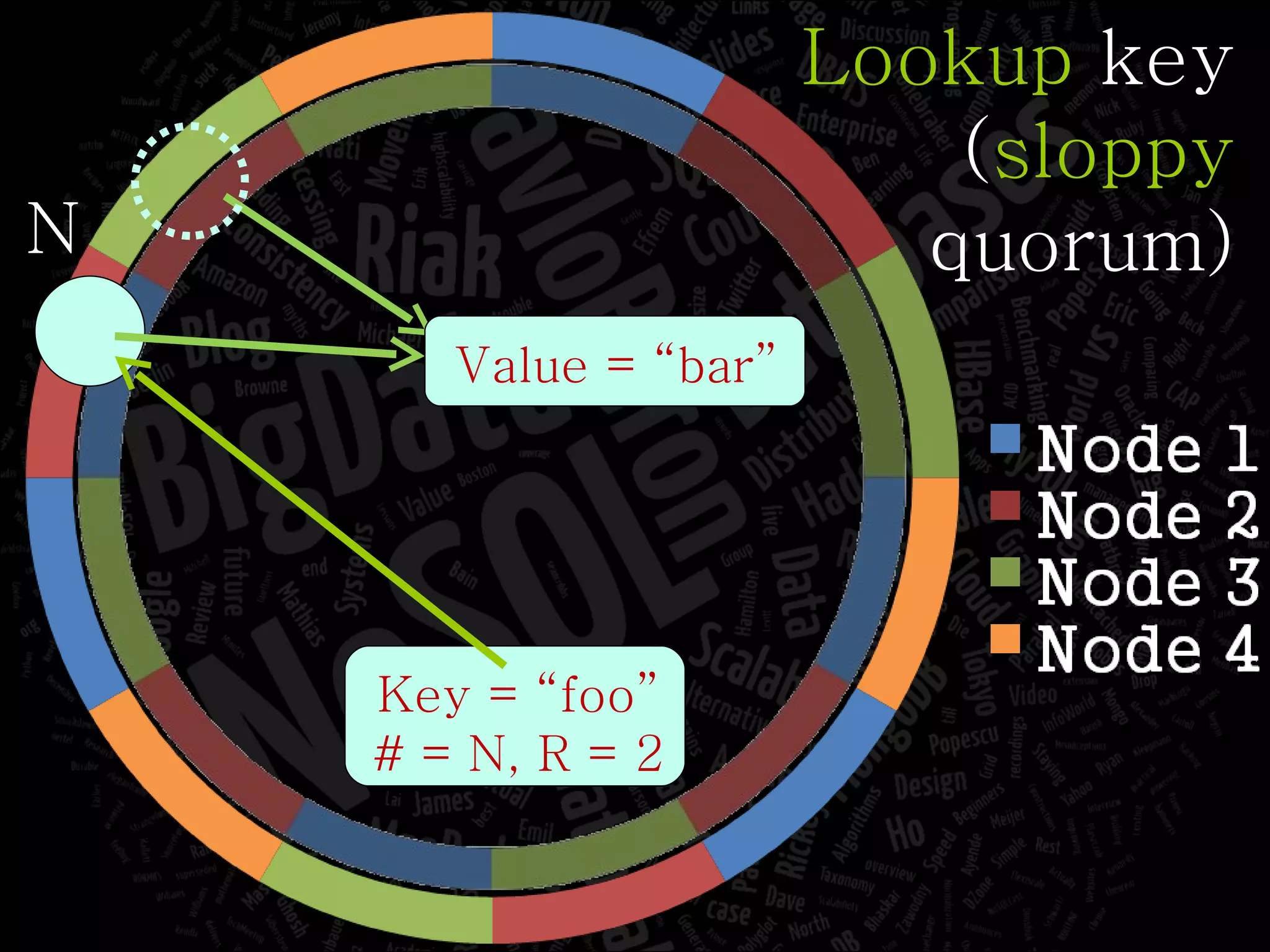
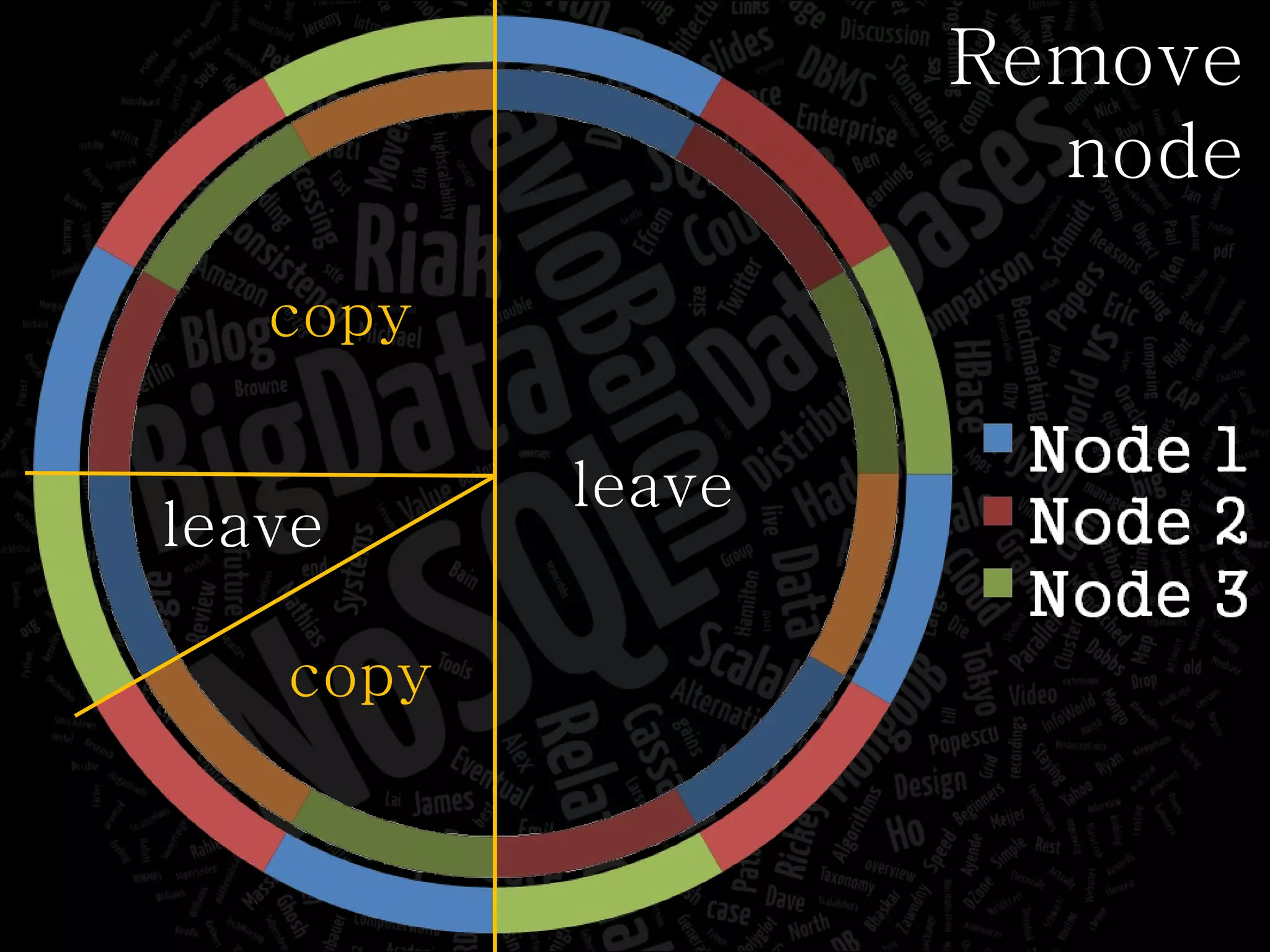
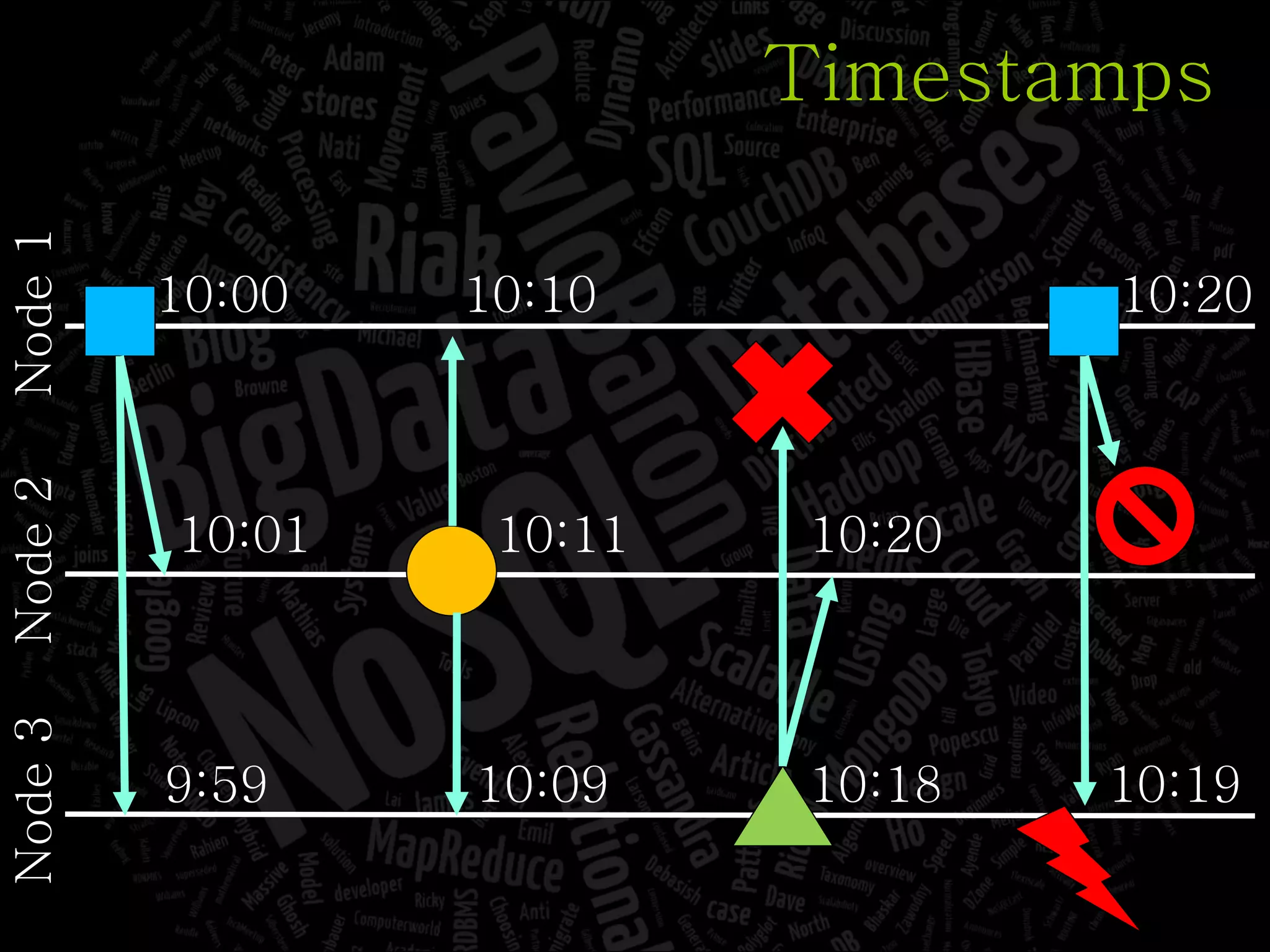
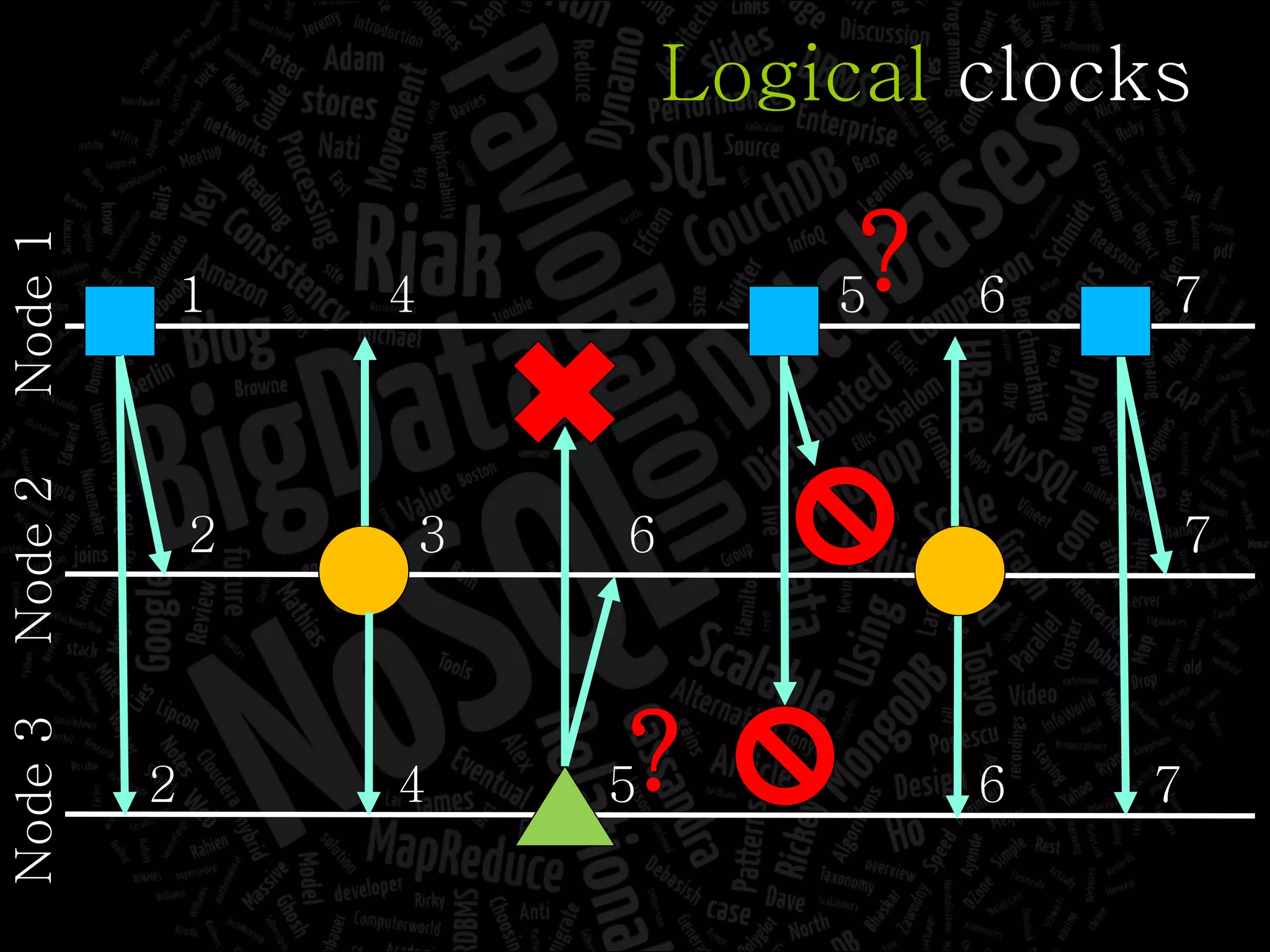
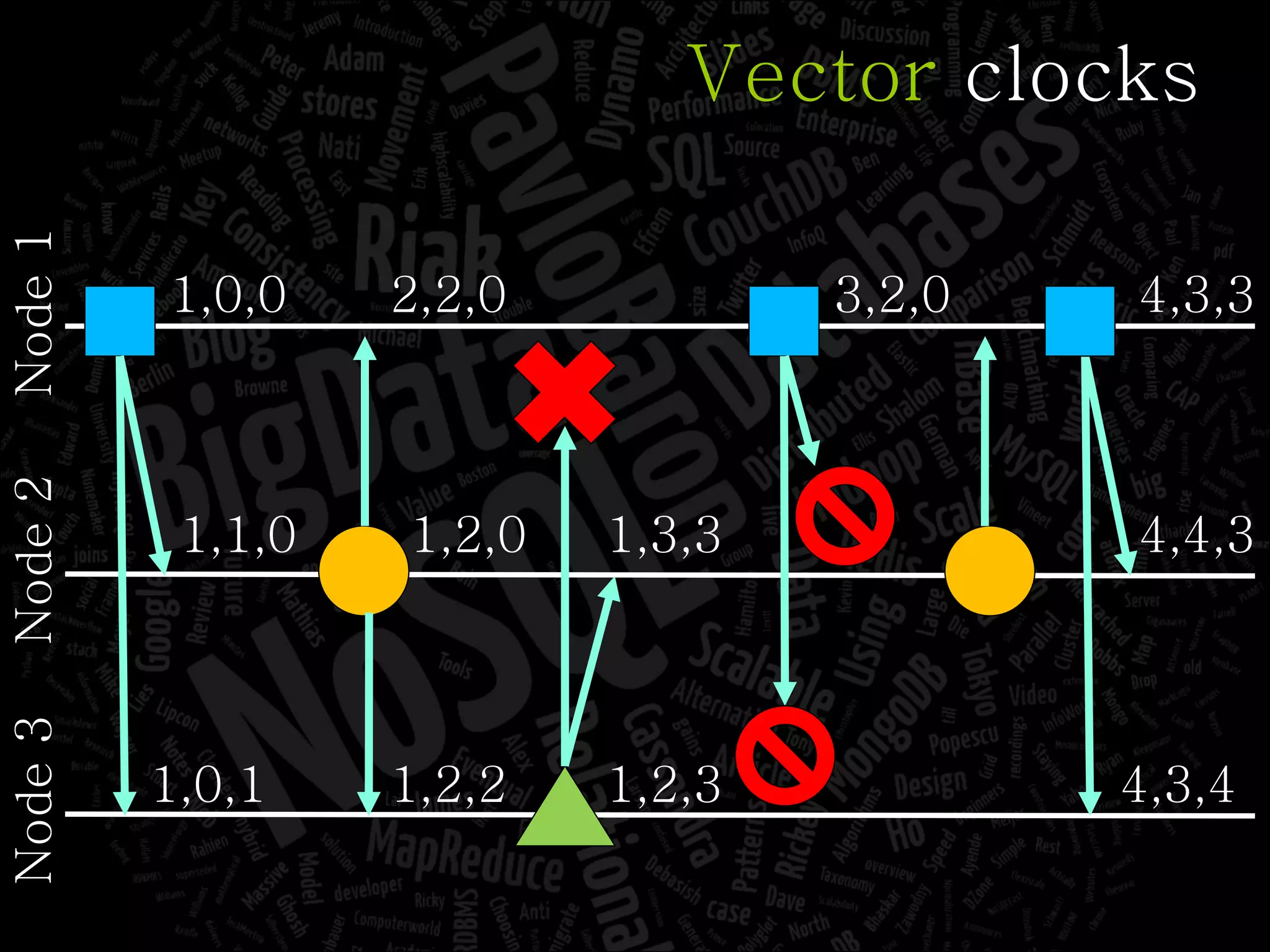
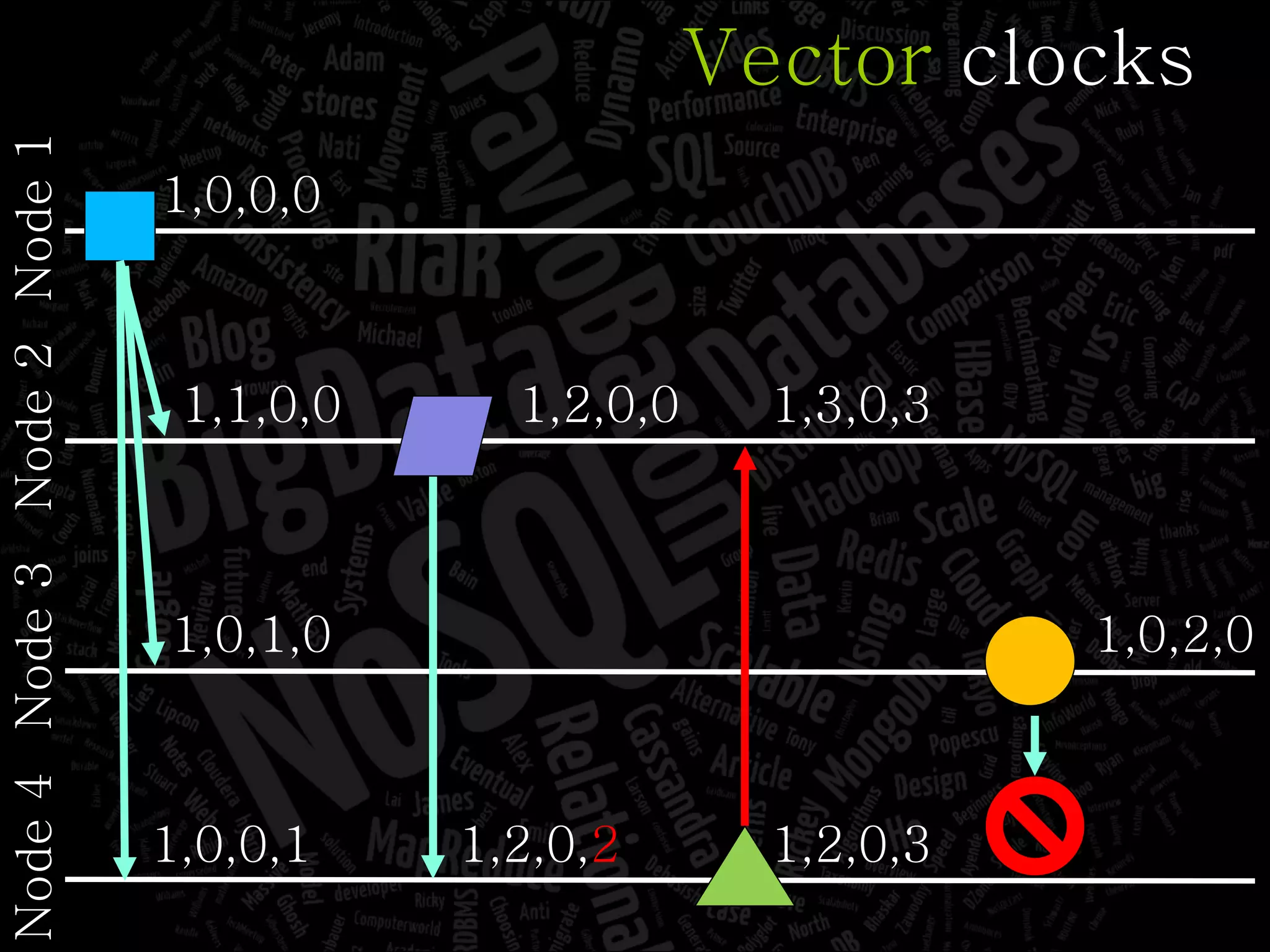
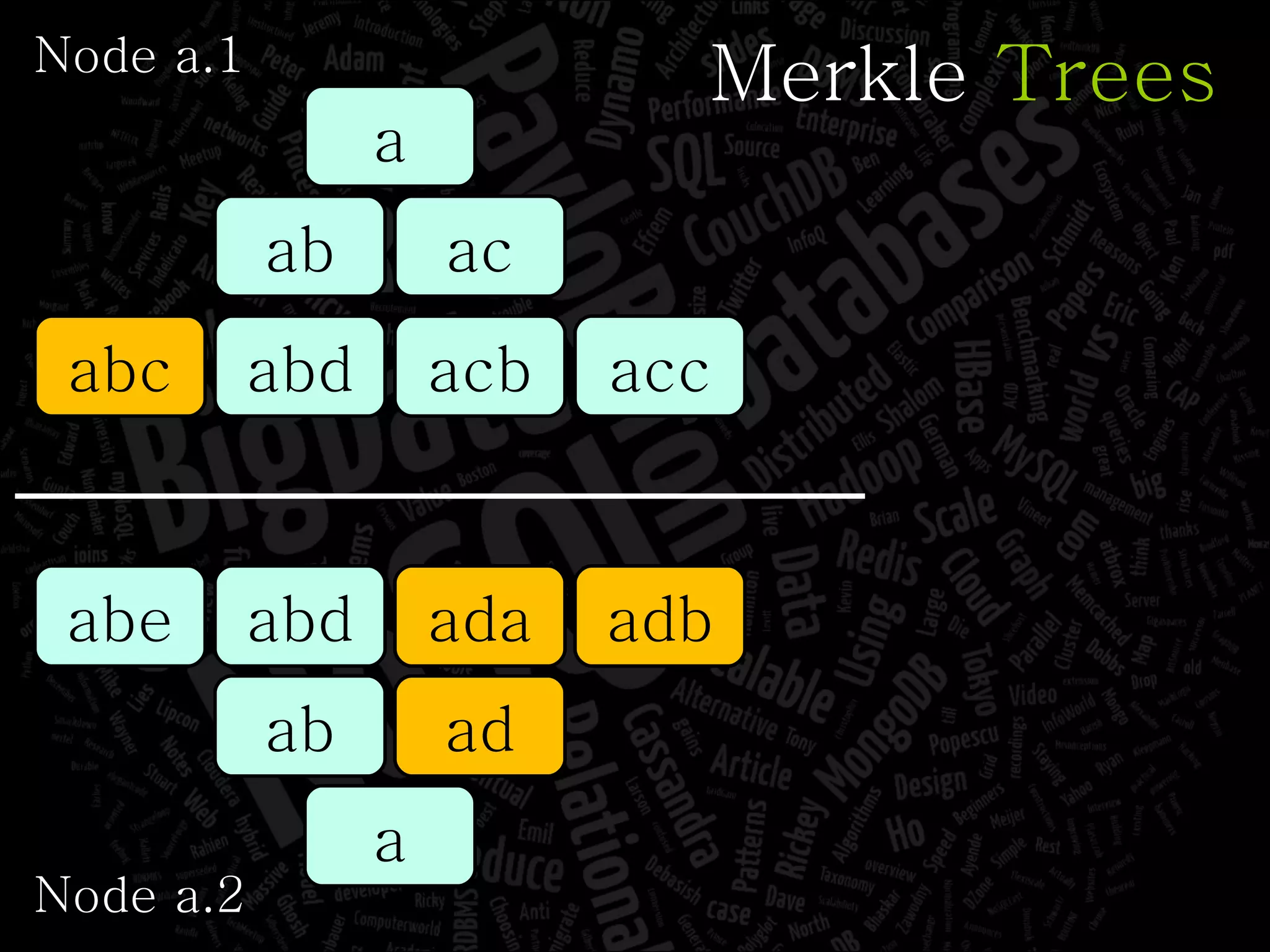
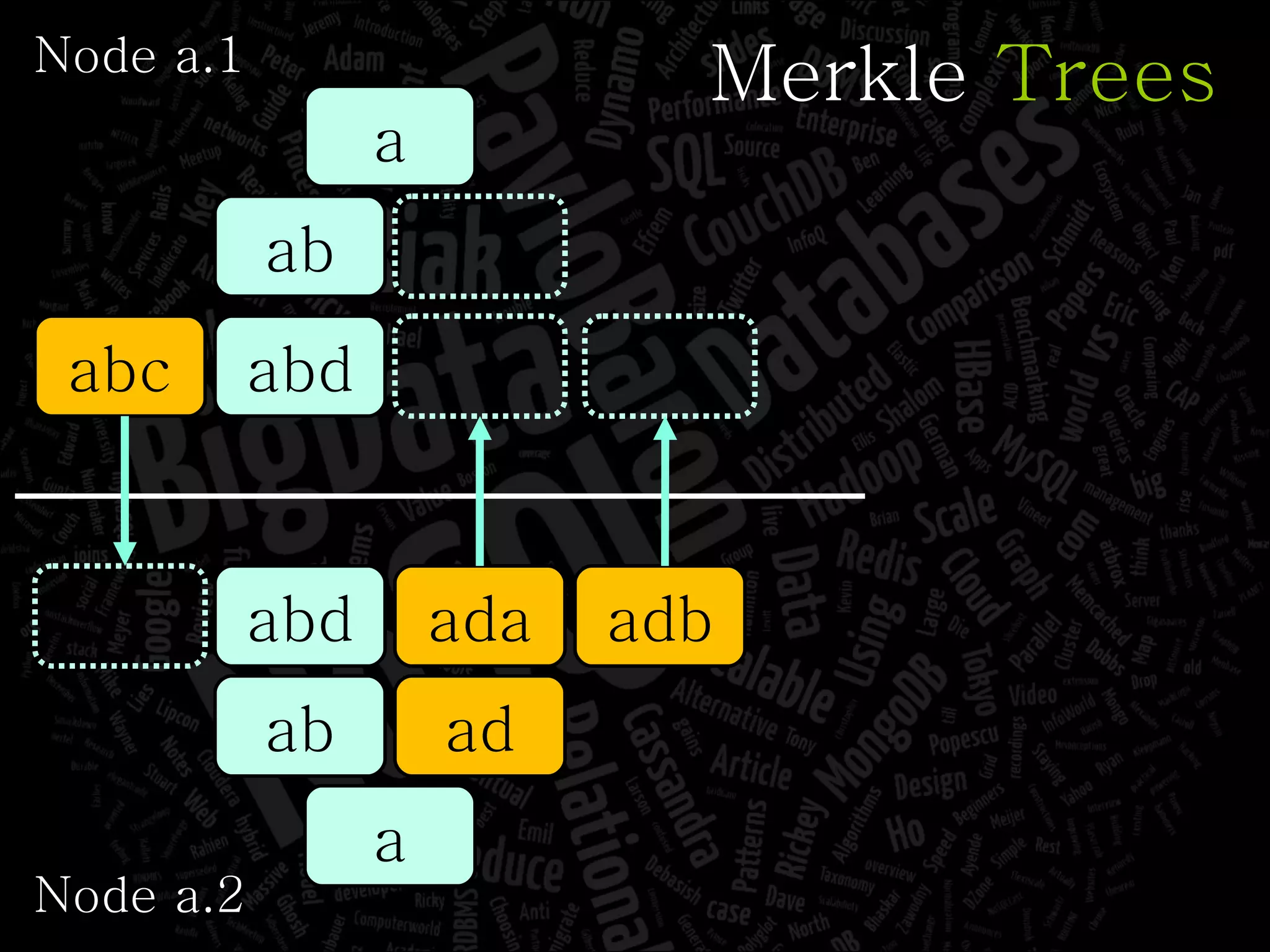
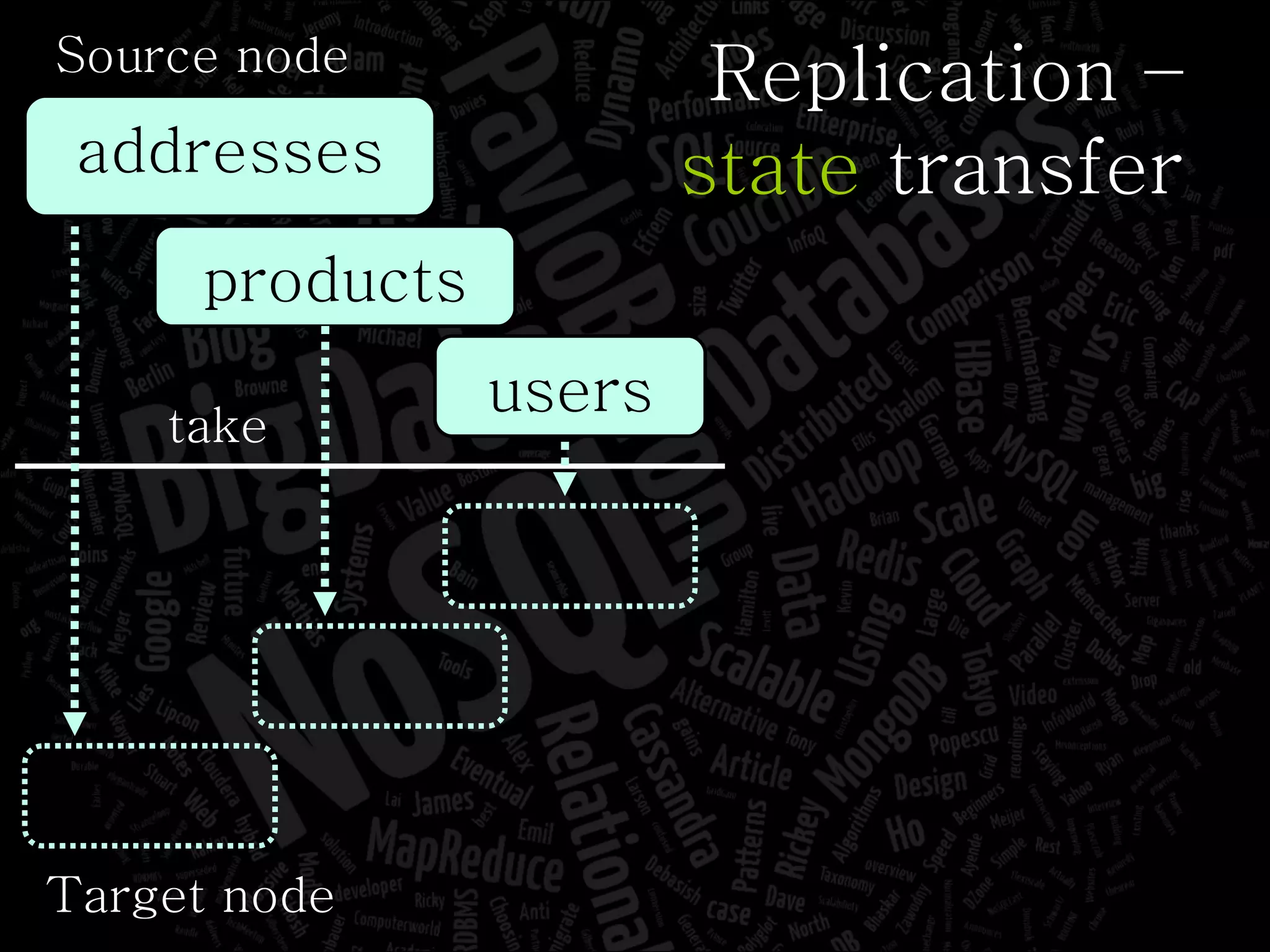
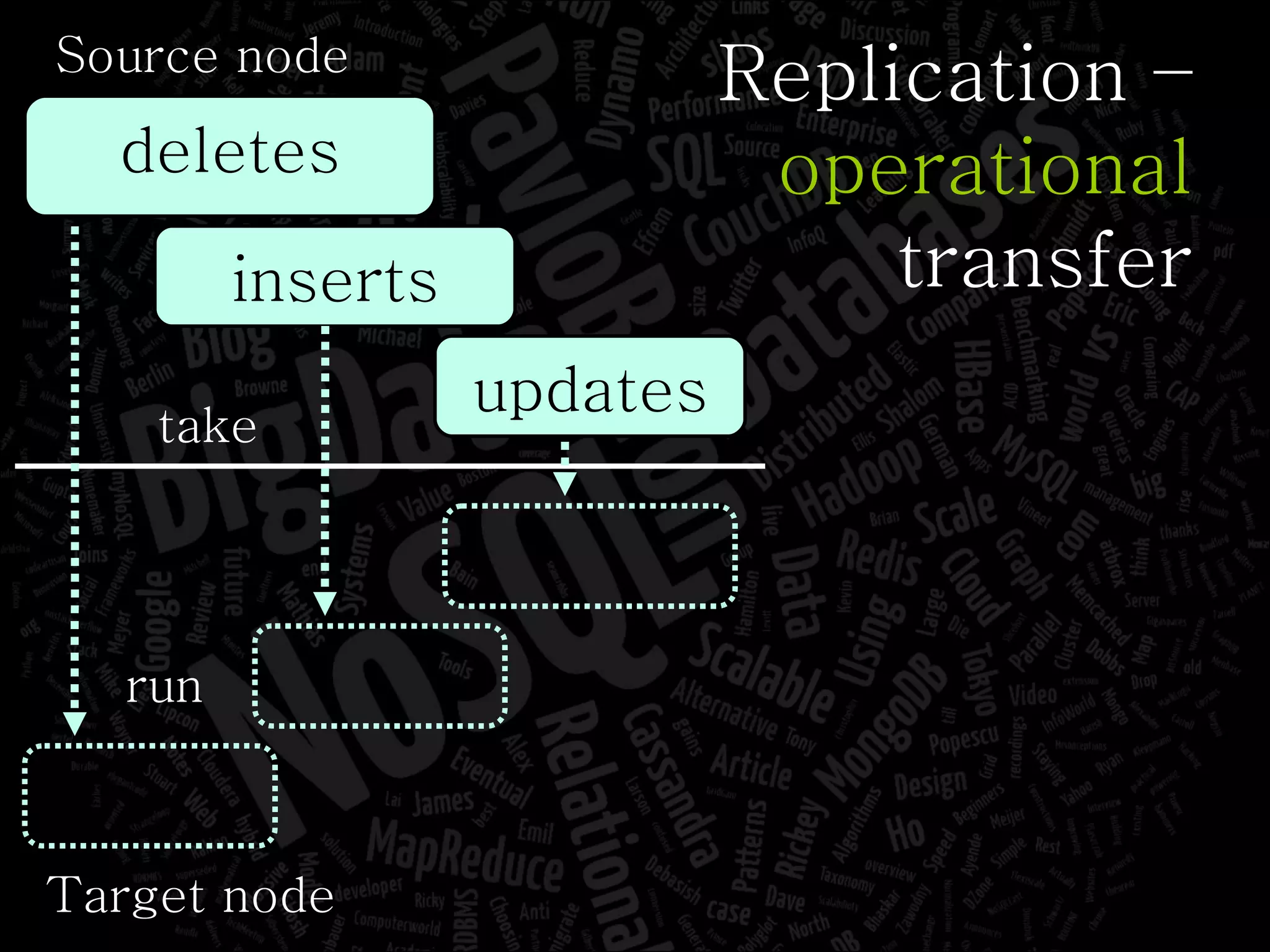
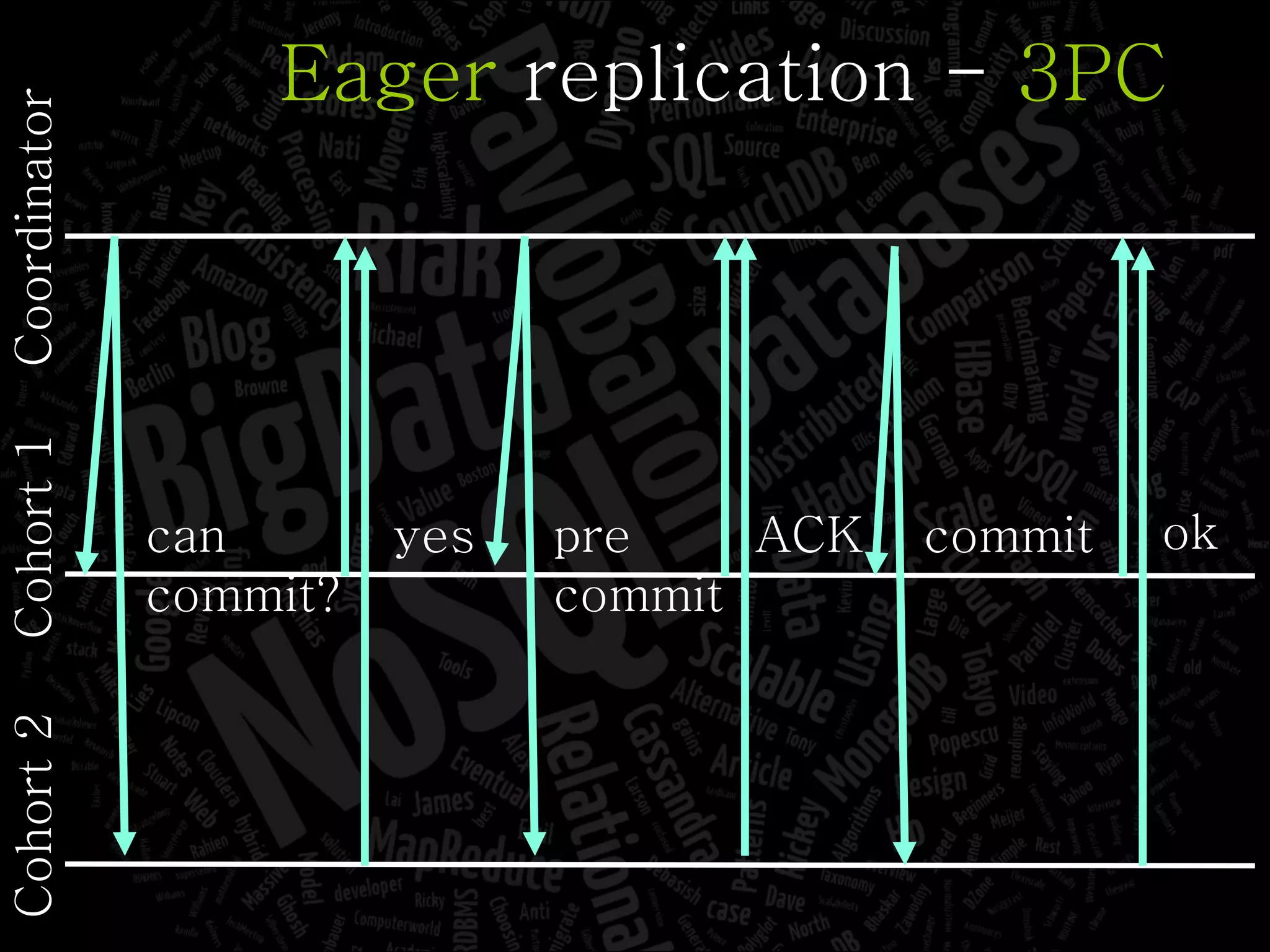
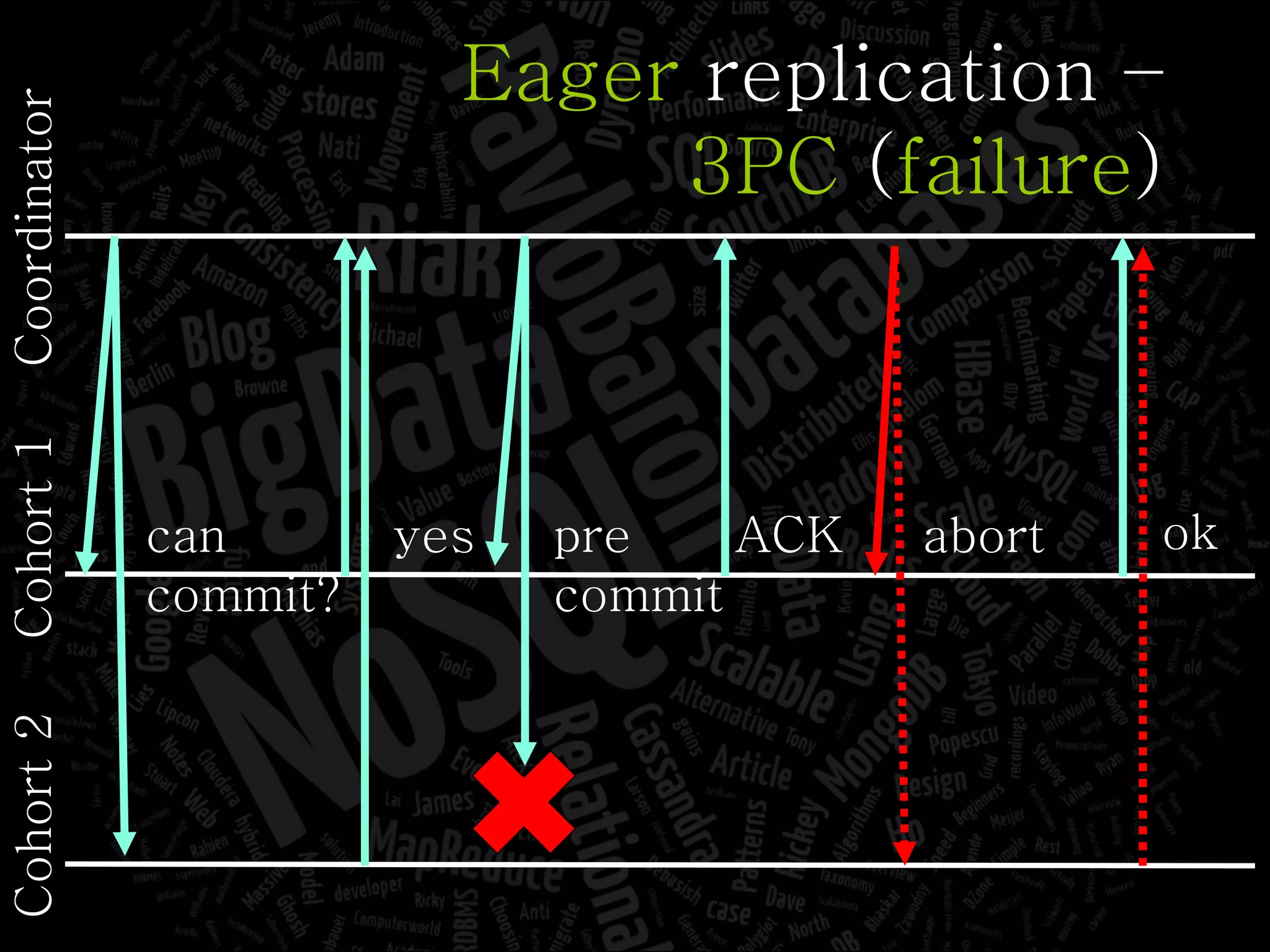
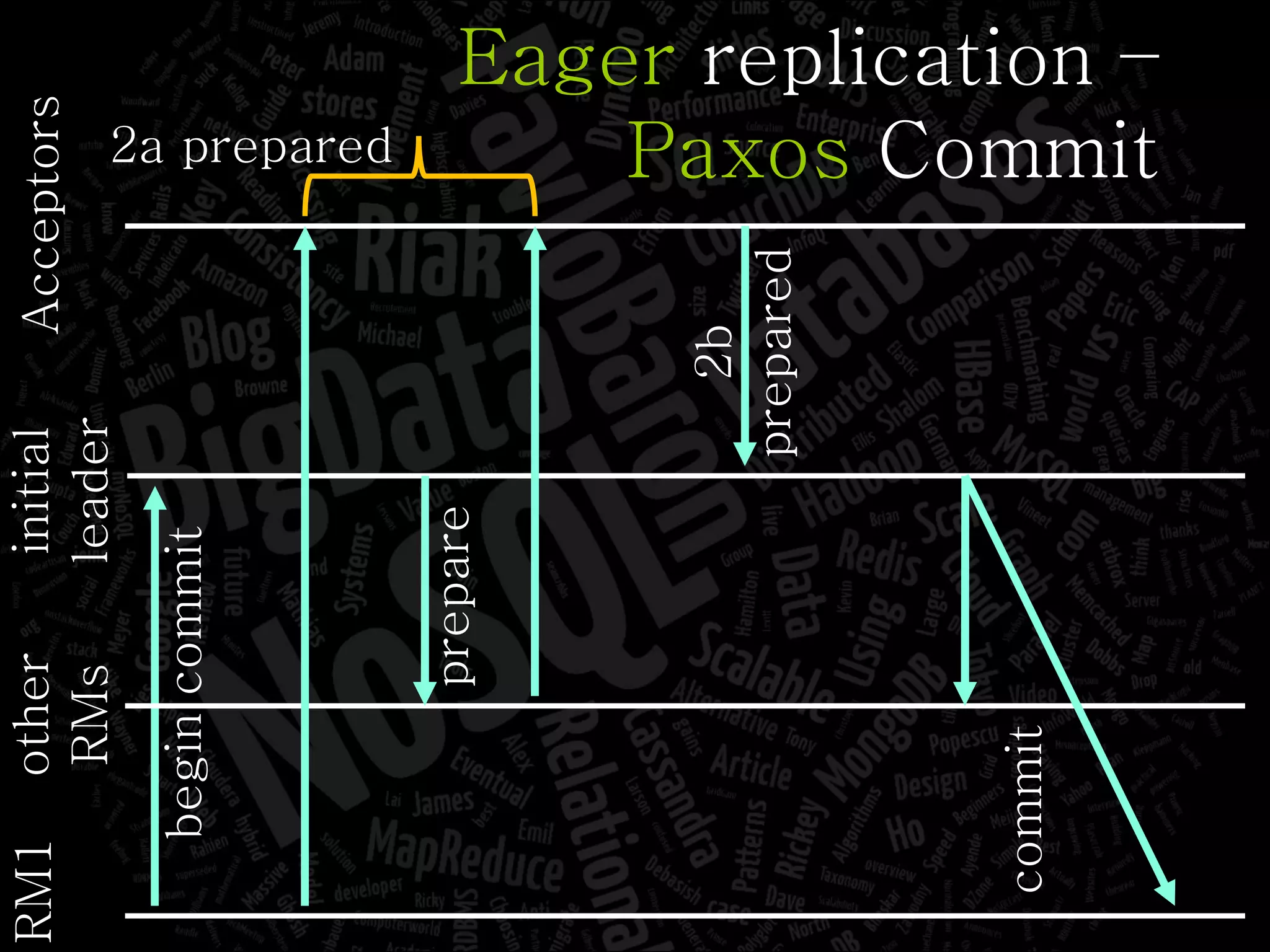
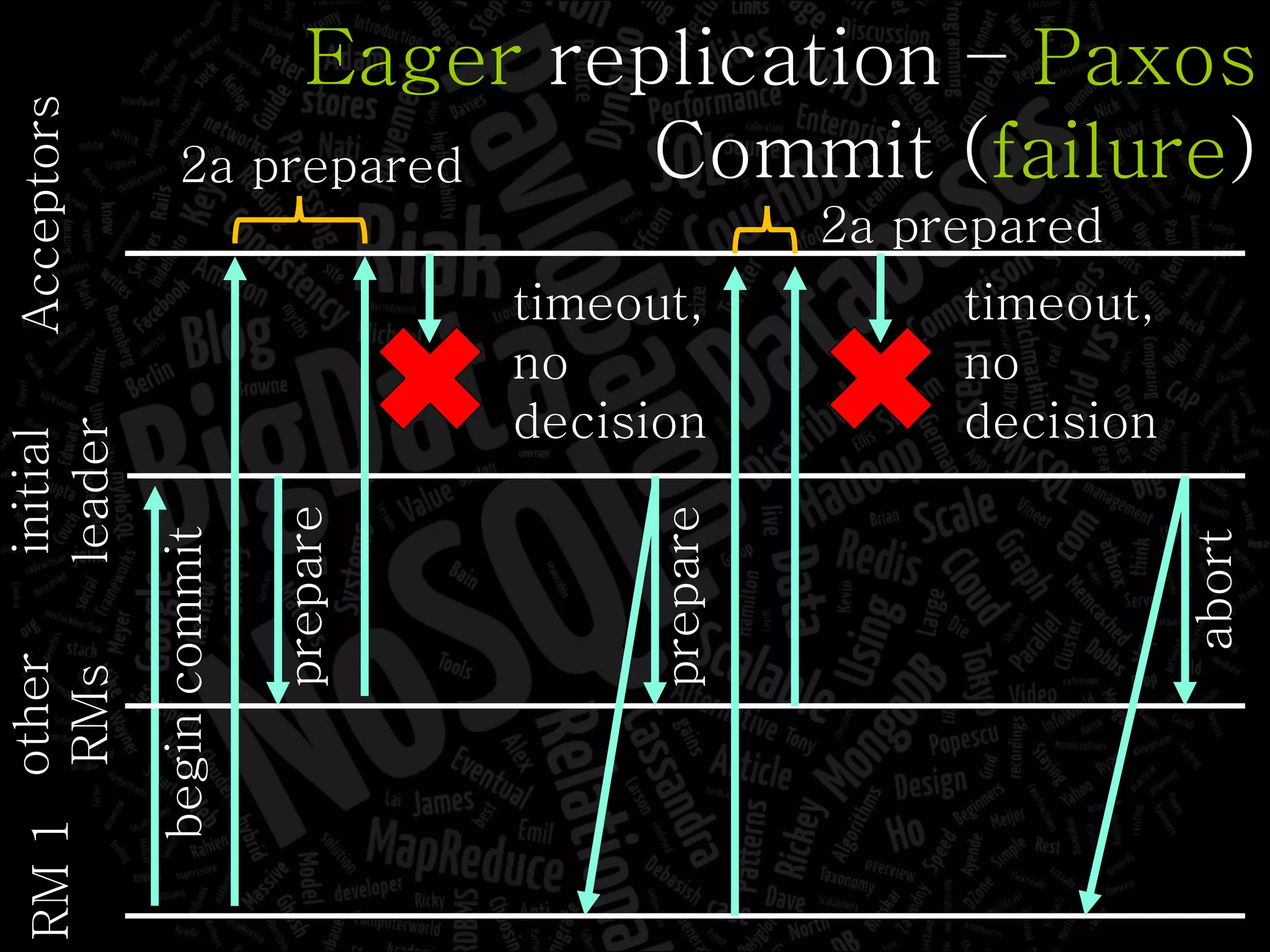
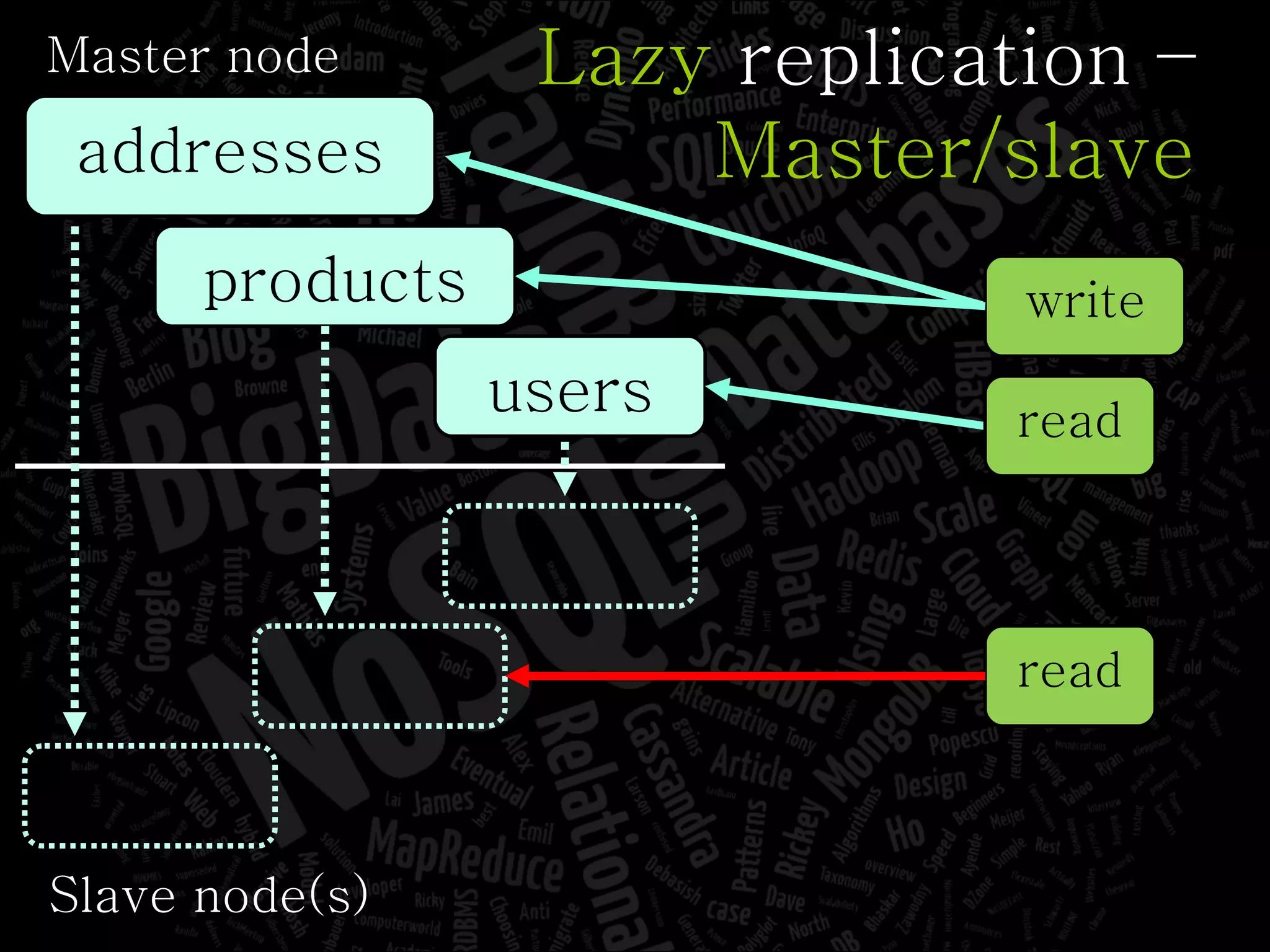
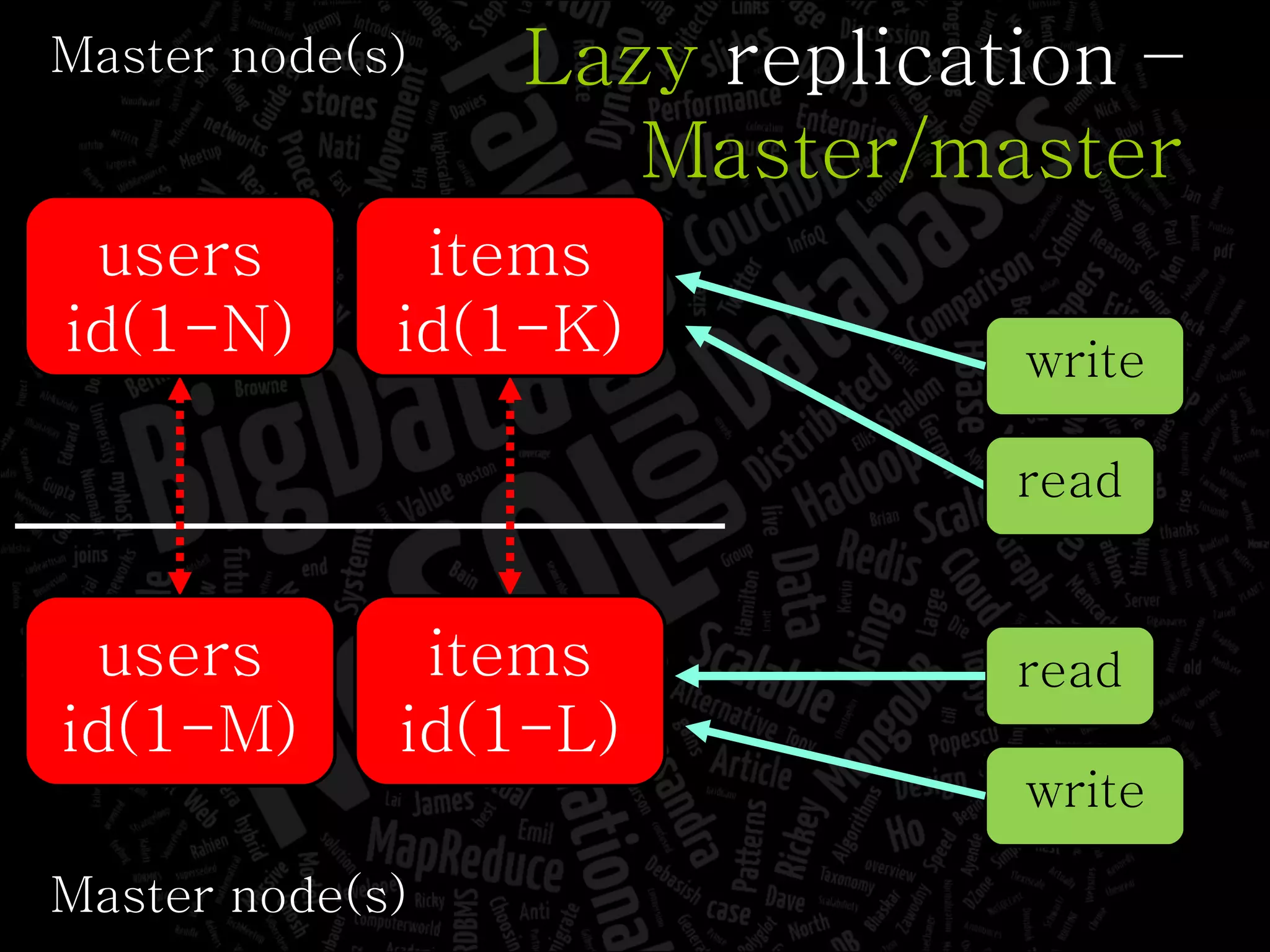
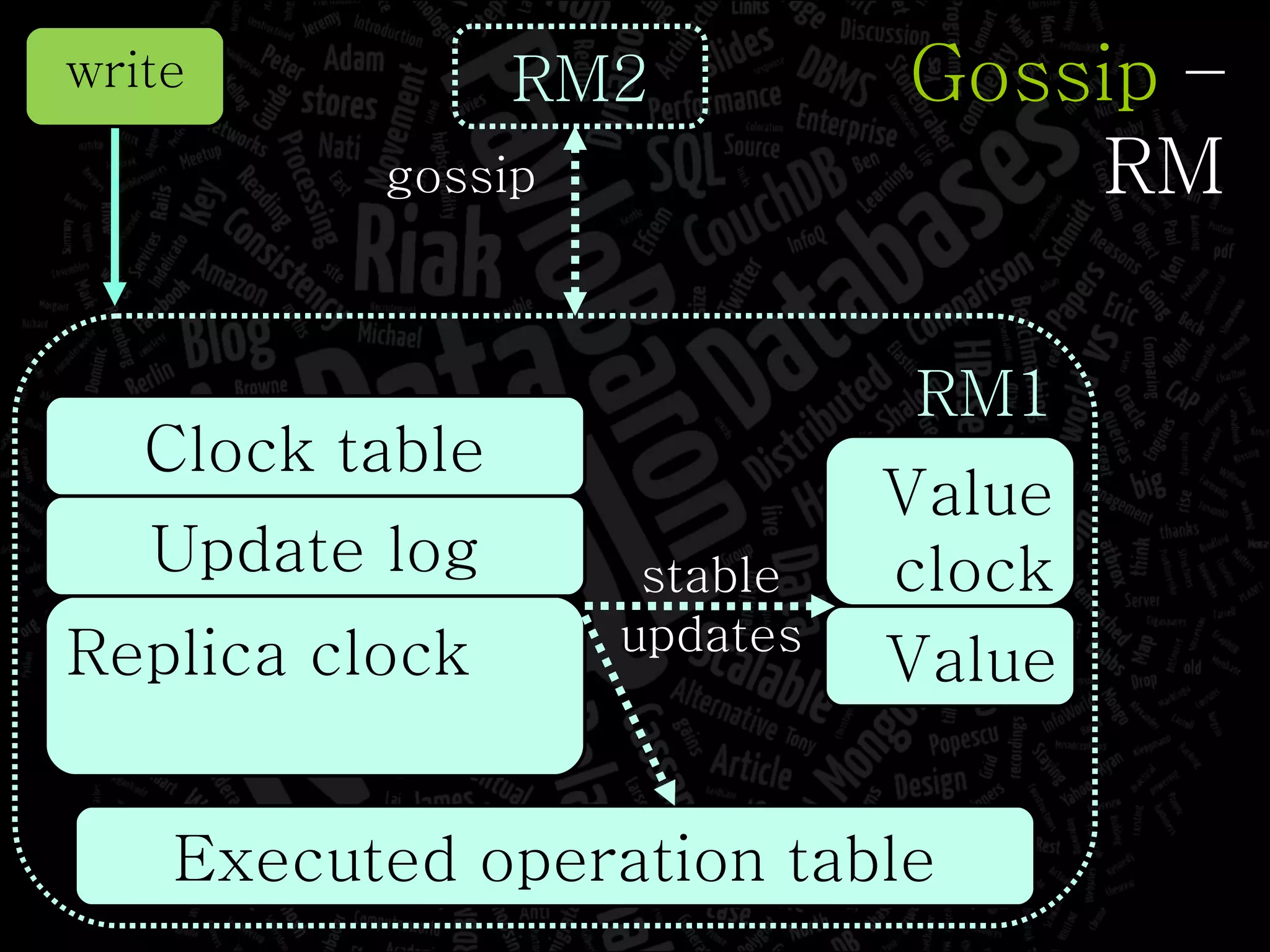
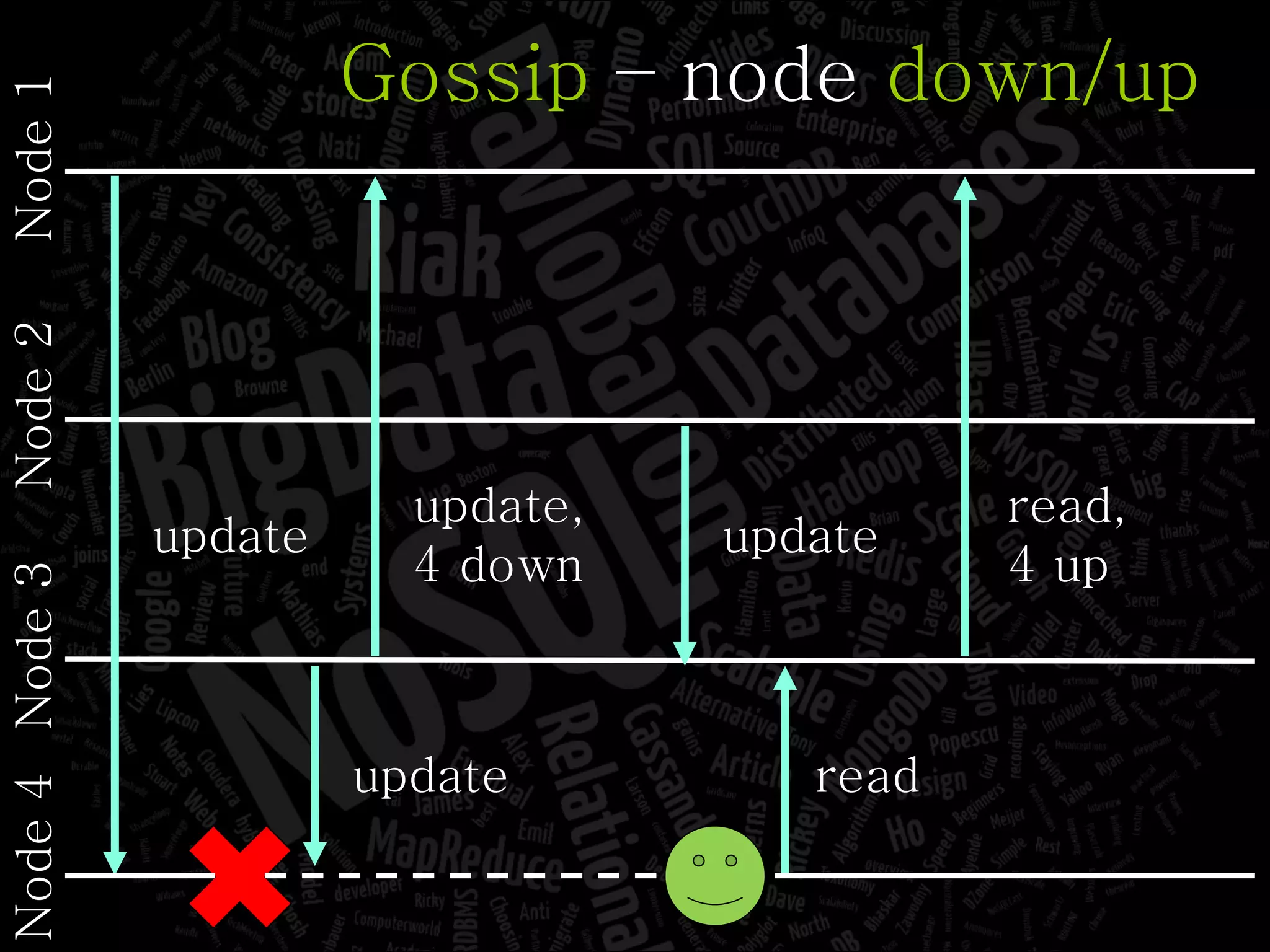
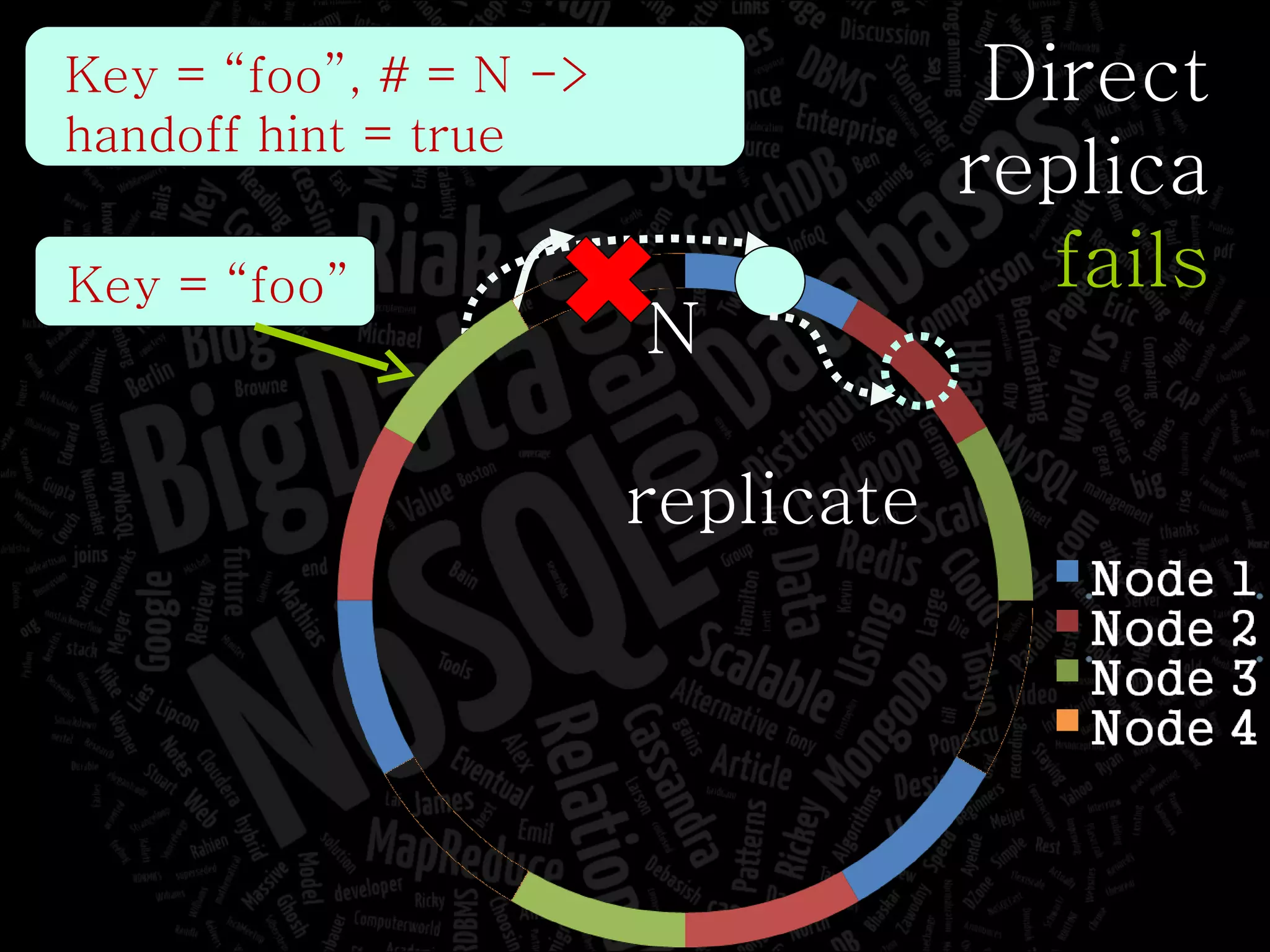
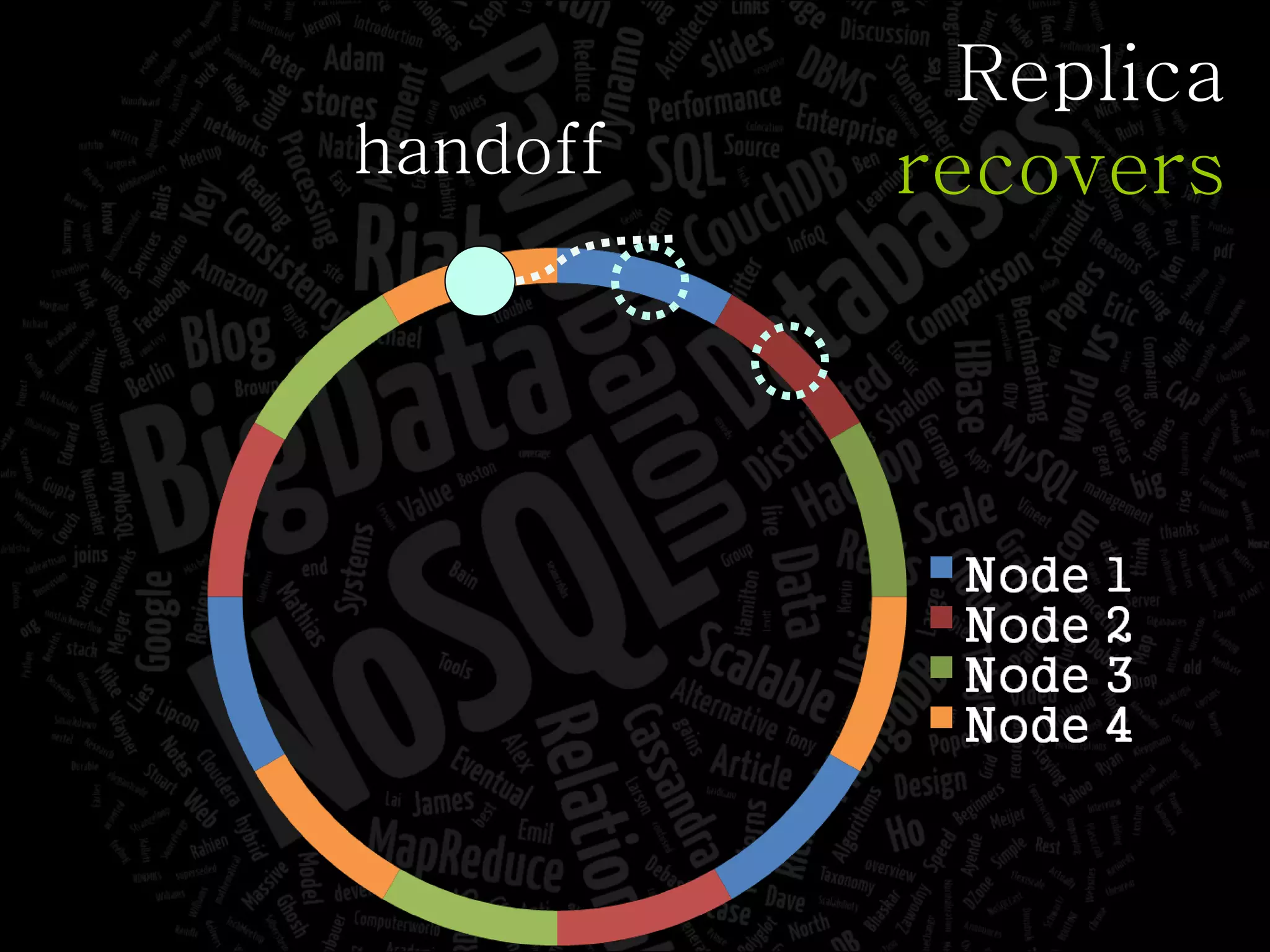
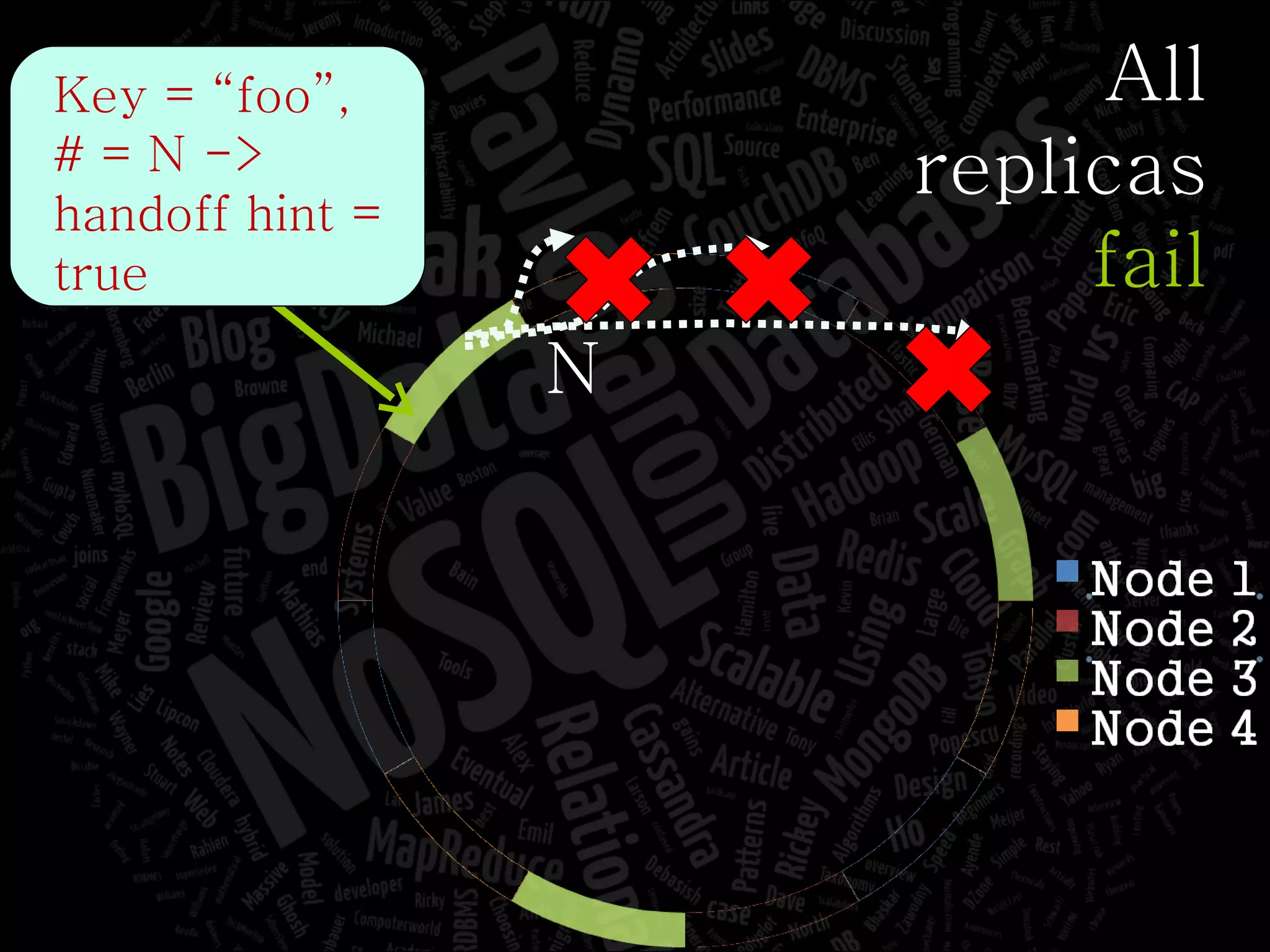
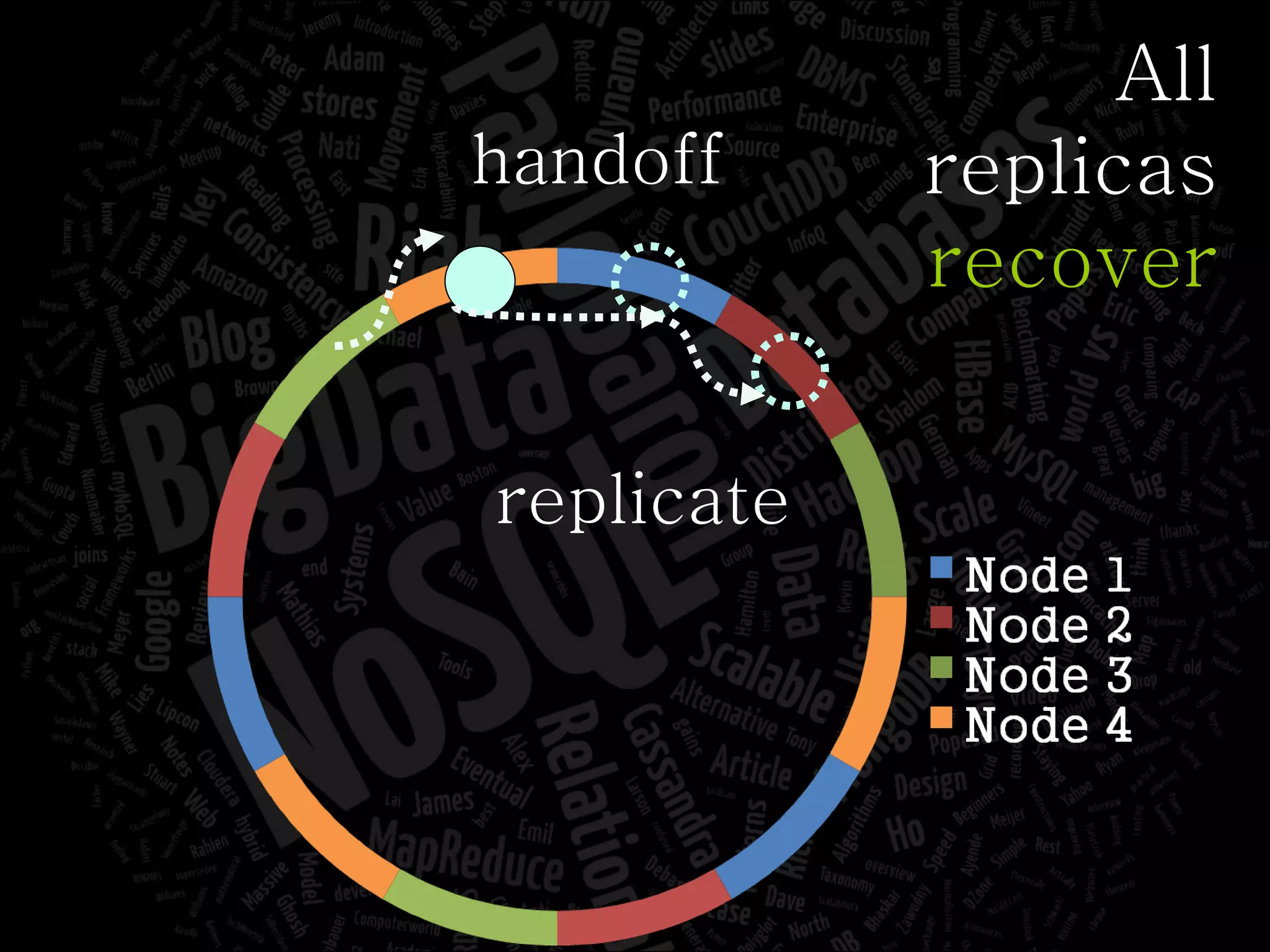
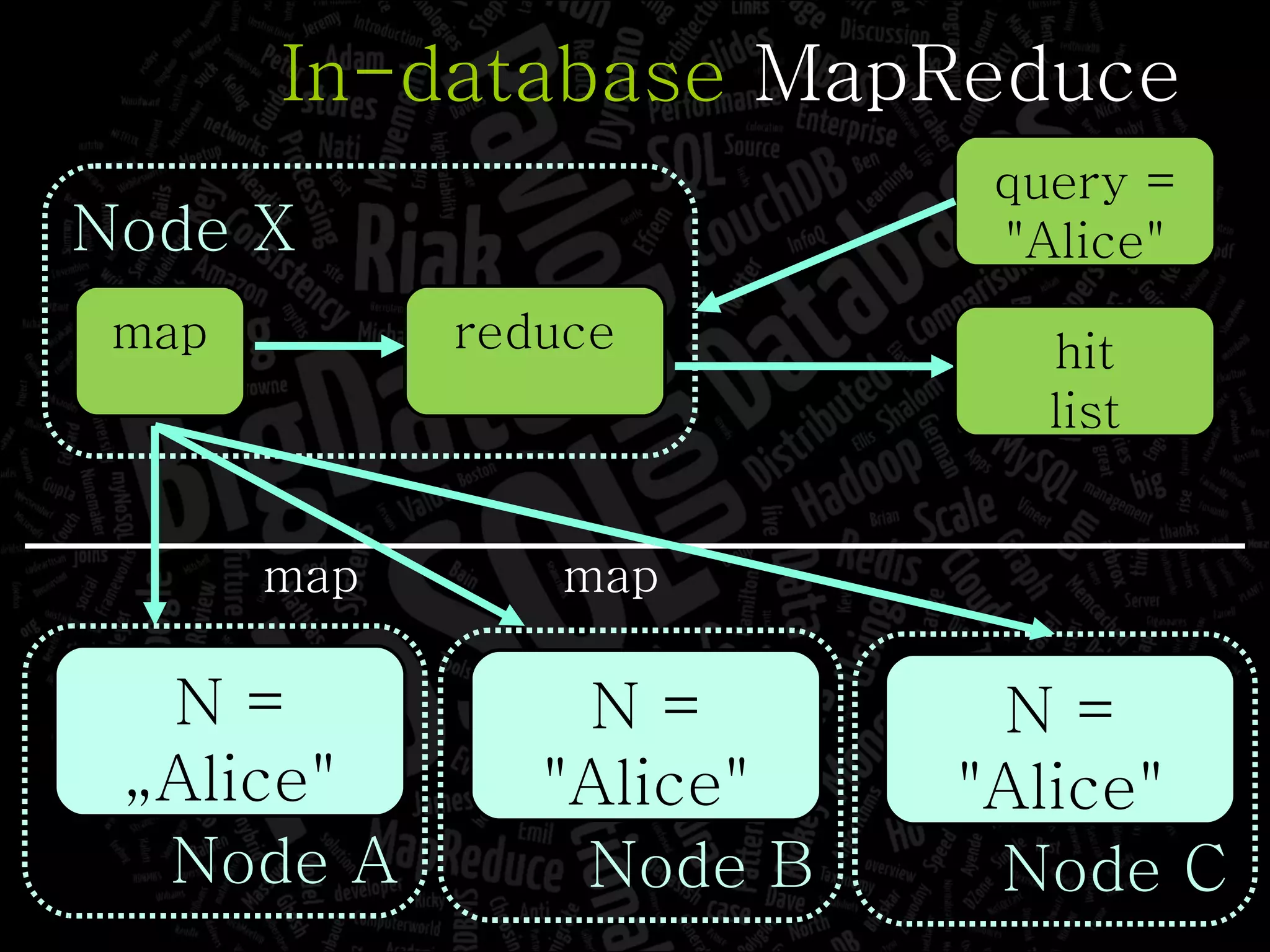
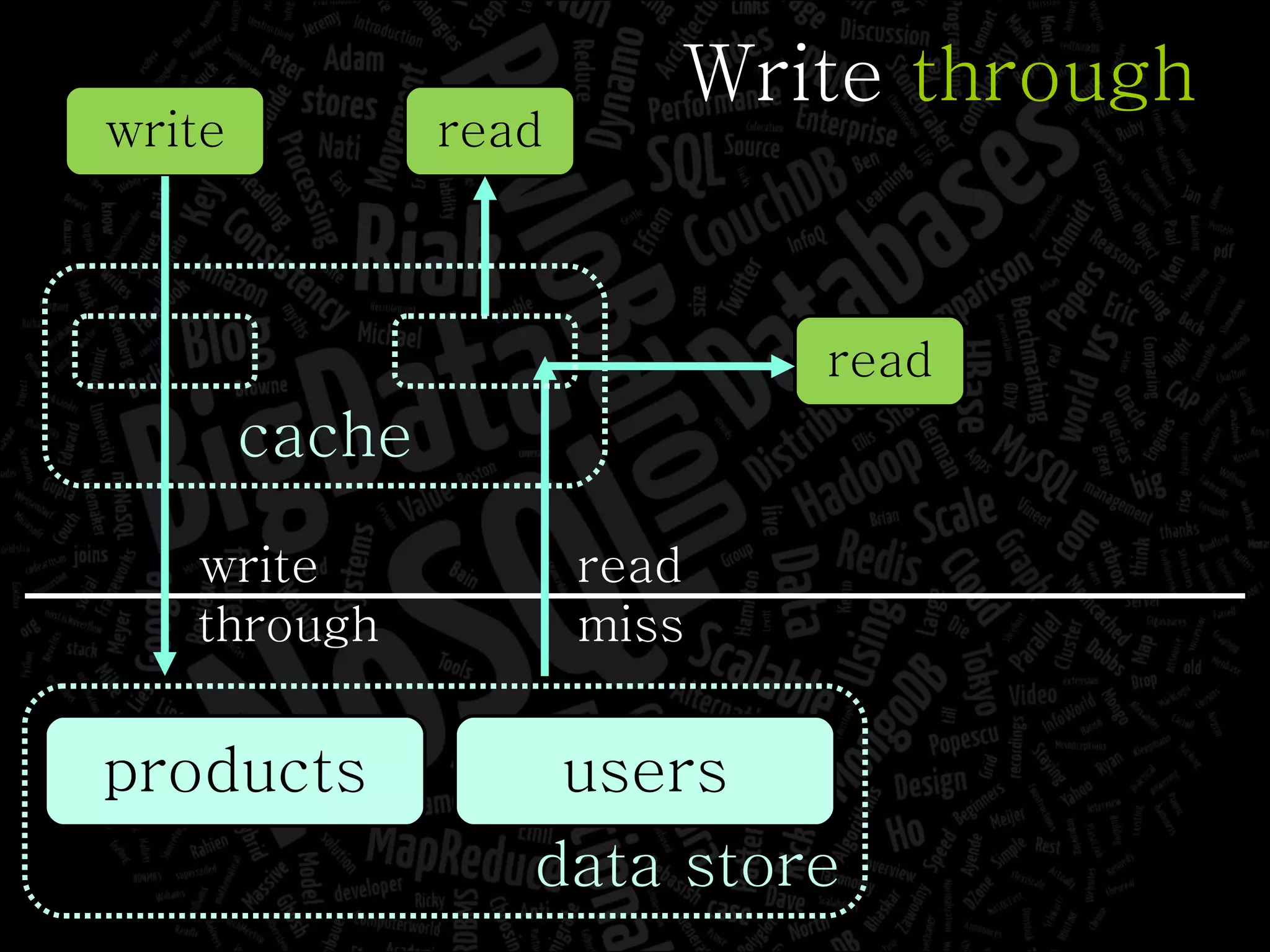
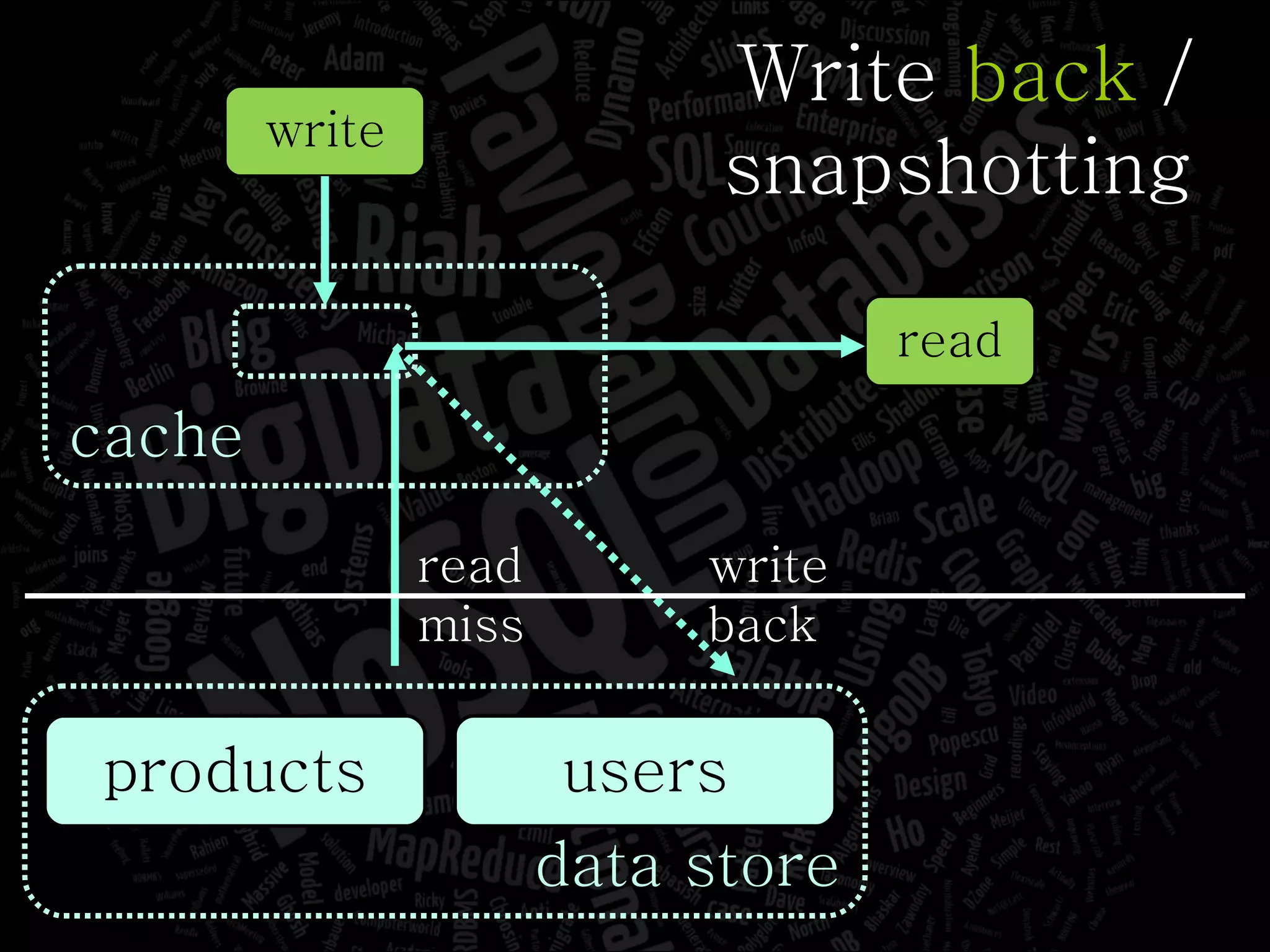
The document discusses the complexities of big data and the importance of appropriate data management strategies. It highlights various concepts relevant to data systems, including NoSQL, CAP theorem, and data replication techniques, while emphasizing the need for flexibility in data handling to accommodate growth and accessibility. It concludes by touching on different storage approaches and design considerations necessary for efficiently managing large datasets.

















































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)





