Download as PDF, PPTX



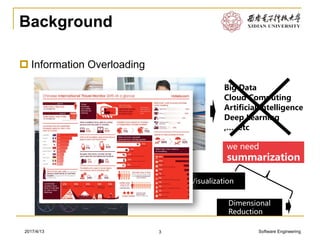
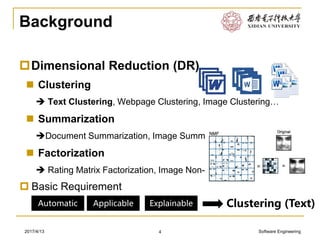


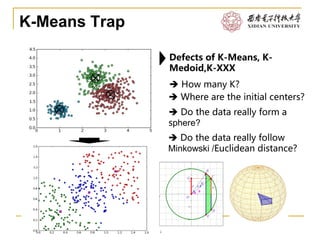

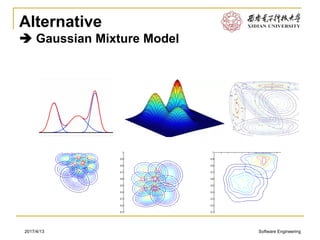


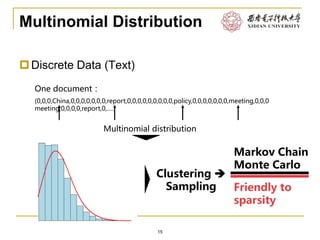




This document discusses various approaches to text clustering, including K-means clustering, Gaussian mixture models, and matrix factorization. It notes some of the limitations and assumptions of these approaches, such as the need to specify the number of clusters for K-means and the assumption of Gaussian distributions. The document also discusses other approaches like hierarchical clustering and methods that can handle sparse data like text. The goal is to provide an overview of clustering techniques for text without advanced mathematics.































![[PPT]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt1290-thumbnail.jpg?width=640&height=640&fit=bounds)

















































