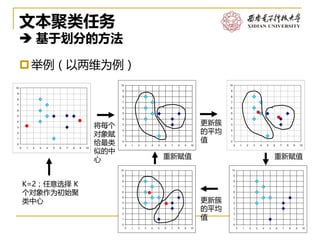
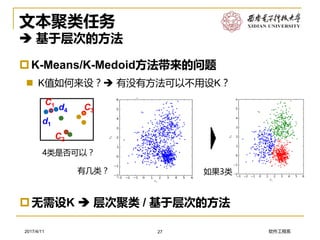
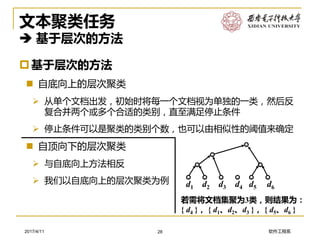
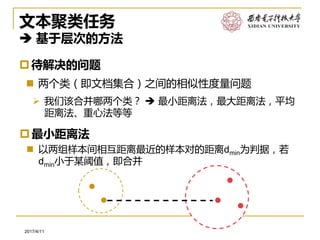
软件工程系2017/4/11
英文教材
C.D. Manning, P. Raghavan and H. Schütze. Introduction to Information
Retrieval, Cambridge University Press, 2008
B. Croft, D. Metzler, T. Strohman. Search Engines: Information Retrieval in
Practice, Addison-Wesley
中文教材
以上两本书的译版
资源(公开课等)
Chengxiang Zhai (顶级IR学者,有幸在电梯里碰到过):
https://www.coursera.org/learn/text-retrieval
C.D. Manning (顶级NLP学者):
http://web.stanford.edu/class/cs276/course_schedule.html
R. J. Mooney(顶级NLP学者):https://www.cs.utexas.edu/users/mooney/
推荐教材
5