
















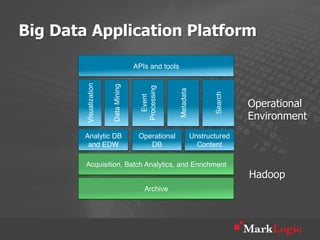
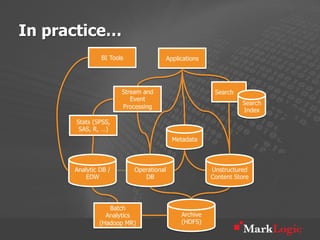
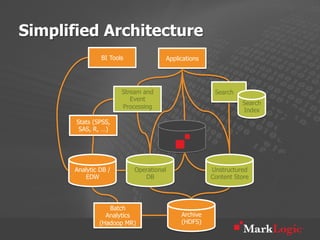
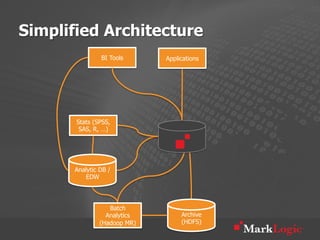
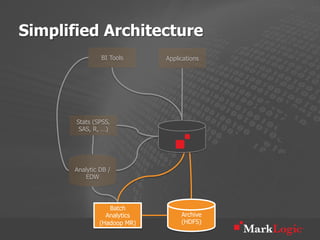

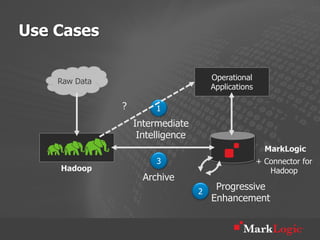




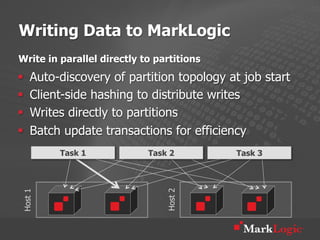










This document discusses real-time big data applications and provides a reference architecture for search, discovery, and analytics. It describes combining analytical and operational workloads using a unified data model and operational database. Examples are given of organizations using this approach for real-time search, analytics and continuous adaptation of large and diverse datasets.


































































































